AgentPLM: Agentic Protein Language Models with Reasoning-Augmented Decoding for Protein Sequence Design
Pith reviewed 2026-06-28 14:15 UTC · model grok-4.3
The pith
Protein language models can interleave generation with oracle calls to correct sequence violations during decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
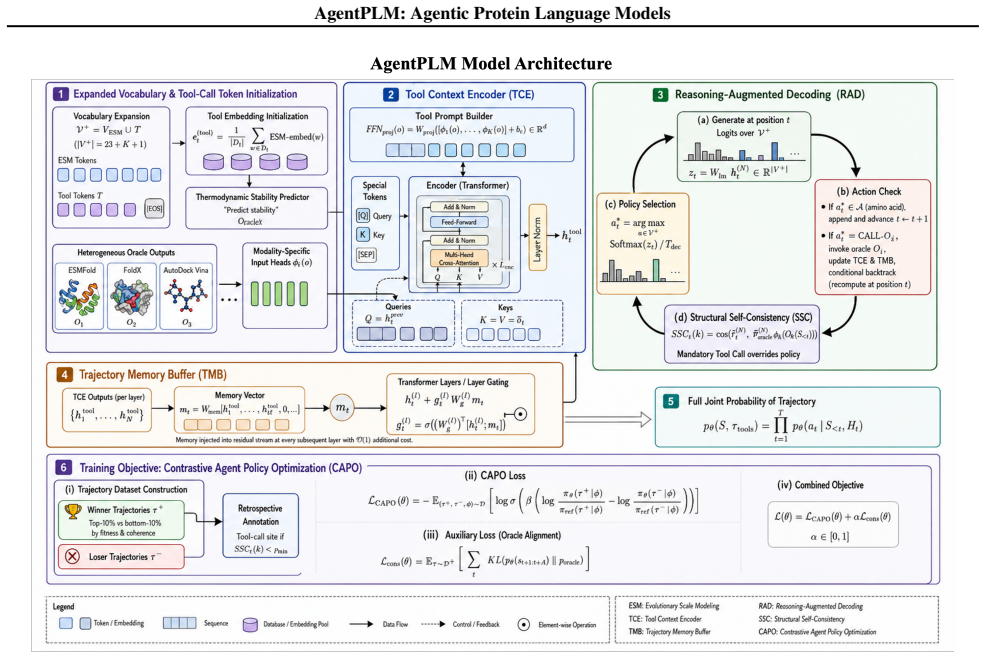
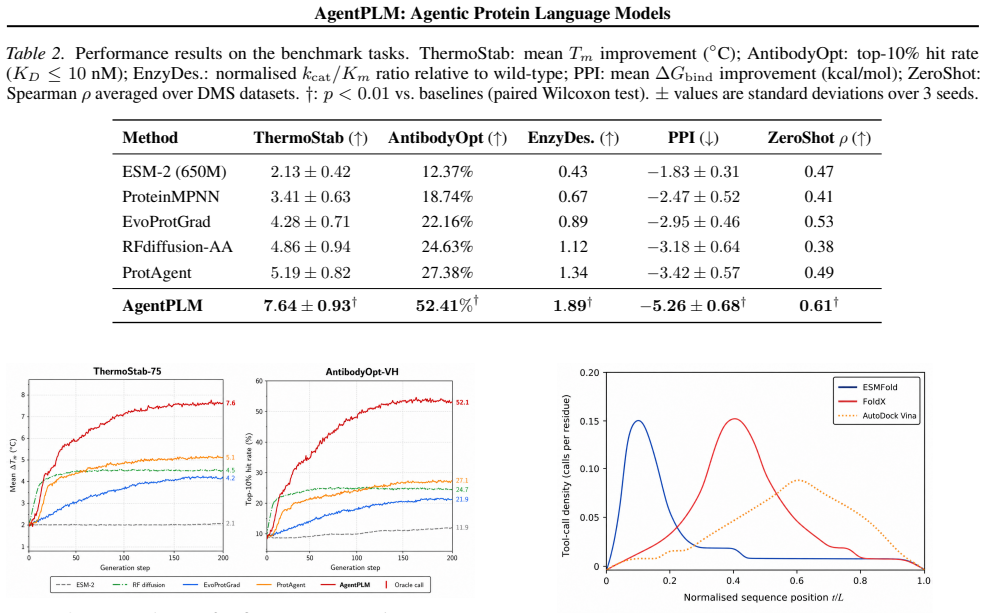
AgentPLM equips a pre-trained protein language model with Reasoning-Augmented Decoding that interleaves autoregressive token generation with tool calls to oracles and with Contrastive Agent Policy Optimisation that performs trajectory-level preference optimisation so the policy learns when oracle feedback is informative. Evaluated under standardised oracle APIs and sequence-identity splits, this yields state-of-the-art results including an improved antibody top-10% hit rate over the strongest passive baseline while providing mechanistic evidence of online error correction.
What carries the argument
Reasoning-Augmented Decoding (RAD) interleaved with oracle tool calls, trained via Contrastive Agent Policy Optimisation (CAPO) at the trajectory level.
If this is right
- AgentPLM improves performance on de novo enzyme design, antibody optimisation, thermostability, PPI interface design, and zero-shot fitness prediction under controlled splits.
- The model learns to redirect generation when candidates violate constraints, producing online error correction without explicit backtracking.
- Contrastive Agent Policy Optimisation enables the policy to distinguish informative oracle signals from uninformative ones rather than simply imitating high-fitness sequences.
- Standardised oracle APIs allow consistent comparison across tasks and baselines.
Where Pith is reading between the lines
- The same interleaving pattern could be applied to other sequence-design settings where simulators supply mid-generation feedback.
- Reducing post-generation filtering steps may become feasible once the policy reliably steers away from low-quality trajectories.
- Extending the set of callable oracles could support longer-horizon design tasks that require repeated corrections.
Load-bearing premise
The external oracles supply sufficiently accurate and unbiased feedback that the policy can reliably learn to use.
What would settle it
Re-train and re-evaluate the identical AgentPLM pipeline after replacing all oracle outputs with random values drawn from the same distribution; the reported hit-rate gains disappear.
Figures

read the original abstract
Protein language models (PLMs) are passive oracles: they generate sequences in a single forward pass with no mechanism to consult external biophysical feedback or redirect generation when a candidate violates thermodynamic or structural constraints. We introduce AgentPLM, which addresses this by equipping a pre-trained PLM with i) Reasoning-Augmented Decoding (RAD), which interleaves autoregressive generation with tool calls (ESMFold, FoldX, AutoDock Vina), and ii) Contrastive Agent Policy Optimisation (CAPO), a trajectory-level extension of direct preference optimisation that trains the policy end-to-end to learn when oracle feedback is informative rather than merely imitating high-fitness sequences. We evaluate AgentPLM on benchmark tasks spanning de novo enzyme design, antibody optimisation, thermostability, PPI interface design, and zero-shot fitness prediction with standardised oracle APIs and controlled sequence-identity splits. AgentPLM achieves state-of-the-art results with a gain in antibody top-10% hit rate over the strongest passive baseline, providing mechanistic evidence of online error correction without explicit backtracking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentPLM, an extension of pre-trained protein language models that adds Reasoning-Augmented Decoding (RAD) to interleave autoregressive generation with calls to external oracles (ESMFold, FoldX, AutoDock Vina) and Contrastive Agent Policy Optimisation (CAPO), a trajectory-level preference optimization method. It evaluates the approach on de novo enzyme design, antibody optimisation, thermostability, PPI interface design, and zero-shot fitness prediction using standardised oracle APIs and controlled sequence-identity splits, claiming state-of-the-art results including a gain in antibody top-10% hit rate over the strongest passive baseline along with mechanistic evidence of online error correction without explicit backtracking.
Significance. If the results hold after proper validation, this could represent a meaningful advance in computational protein design by showing how agentic integration of biophysical oracles during generation can outperform passive PLM sampling. The trajectory-level optimization and tool-use framing are technically interesting contributions. Credit is given for the attempt to use controlled splits and standardised APIs. However, the significance cannot be assessed without evidence that gains reflect genuine improvements rather than oracle artifacts.
major comments (2)
- [Evaluation (antibody optimisation results)] The central SOTA claim and 'mechanistic evidence of online error correction' rest on the oracles supplying accurate, unbiased feedback that the policy learns to use productively. No section, table, or figure provides controls for oracle noise, systematic biases, robustness tests, or oracle-free ablations, which is load-bearing for interpreting the antibody hit-rate gains as biophysical rather than artifact-driven.
- [Abstract and Results] The abstract reports a gain in top-10% hit rate but supplies no details on experimental setup, number of independent runs, statistical tests, baseline definitions, or variance; without these, the performance claim cannot be evaluated as sound.
minor comments (2)
- [Methods] The description of CAPO as a 'trajectory-level extension of direct preference optimisation' would benefit from explicit equations or pseudocode showing how preferences are constructed from oracle signals.
- [Evaluation] Clarify whether the 'standardised oracle APIs' are publicly available or custom; a reference or repository link would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and for acknowledging the technical interest of the agentic framing and trajectory-level optimization. We address each major comment below and will revise the manuscript accordingly to strengthen the evaluation.
read point-by-point responses
-
Referee: [Evaluation (antibody optimisation results)] The central SOTA claim and 'mechanistic evidence of online error correction' rest on the oracles supplying accurate, unbiased feedback that the policy learns to use productively. No section, table, or figure provides controls for oracle noise, systematic biases, robustness tests, or oracle-free ablations, which is load-bearing for interpreting the antibody hit-rate gains as biophysical rather than artifact-driven.
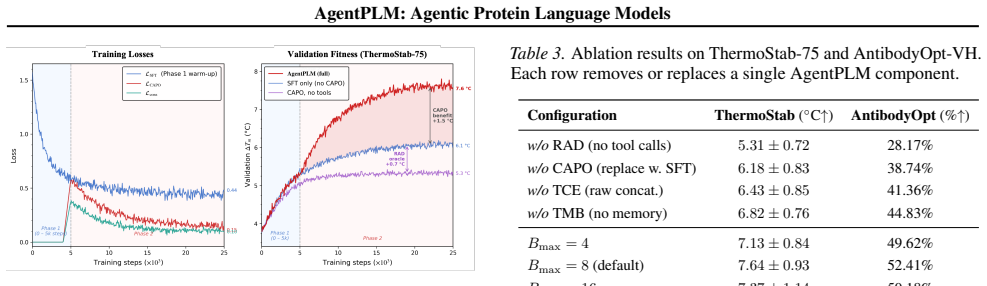
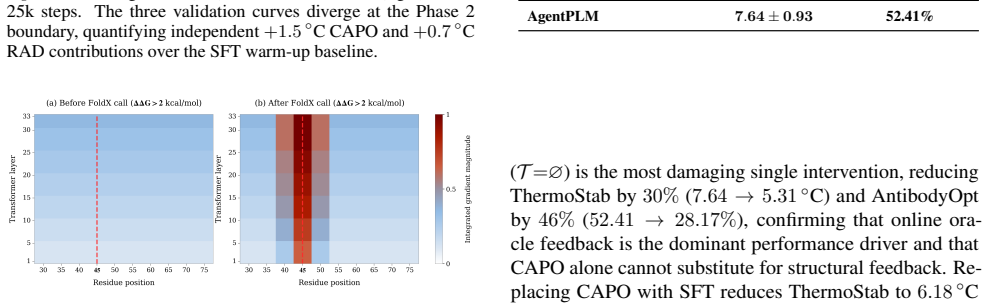
Authors: We agree that the absence of explicit oracle-noise controls, bias analyses, and oracle-free ablations limits the strength of the current claims. The manuscript uses standardised oracle APIs and controlled sequence-identity splits, but these do not substitute for dedicated robustness checks. In the revision we will add (i) oracle-free ablations that replace tool feedback with random or constant signals, (ii) experiments injecting controlled noise into FoldX and ESMFold outputs, and (iii) trajectory-level statistics showing when the policy elects to ignore versus act on oracle feedback. These additions will allow readers to assess whether the reported antibody hit-rate gains and online error-correction behaviour are biophysical or artifact-driven. revision: yes
-
Referee: [Abstract and Results] The abstract reports a gain in top-10% hit rate but supplies no details on experimental setup, number of independent runs, statistical tests, baseline definitions, or variance; without these, the performance claim cannot be evaluated as sound.
Authors: We accept that the abstract is insufficiently detailed. The revised abstract will explicitly state the number of independent runs, the statistical tests used, the precise definition of the strongest passive baseline, and the reported variance or confidence intervals for the top-10% hit-rate metric. Corresponding details will also be added to the results section and figure captions. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper's central claims are empirical performance results on benchmark tasks using external oracles (ESMFold, FoldX, AutoDock Vina) and a training method (CAPO) evaluated with controlled sequence-identity splits. The abstract and provided text contain no equations, self-definitional steps, fitted inputs presented as predictions, or load-bearing self-citations that reduce the SOTA hit-rate gains or 'mechanistic evidence' to the inputs by construction. The method is presented as an extension of existing PLMs with tool-use and preference optimization, with results compared to passive baselines. This is self-contained against external benchmarks and matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Tinn, R
Gu, Y. and Tinn, R. and Cheng, H. and others , title =. ACM Transactions on Computing for Healthcare , volume =
-
[2]
Kulandaisamy and K
Rahul Nikam and A. Kulandaisamy and K. Harini and Divya Sharma and M. Michael Gromiha , title =. Nucleic Acids Research , volume =. 2021 , doi =
2021
-
[3]
Bernaerts and Jean Marc Kwasigroch and Marianne Rooman , title =
Fabrizio Pucci and Katrien V. Bernaerts and Jean Marc Kwasigroch and Marianne Rooman , title =. Bioinformatics , volume =. 2018 , doi =
2018
-
[4]
Nucleic Acids Research , volume =
Jan Stourac and Juraj Dubrava and Milos Musil and Jana Horackova and Jiri Damborsky and Stanislav Mazurenko and David Bednar , title =. Nucleic Acids Research , volume =. 2021 , doi =
2021
-
[5]
Deane , title =
James Dunbar and Konrad Krawczyk and Jinwoo Leem and Terry Baker and Angelika Fuchs and Guy Georges and Jiye Shi and Charlotte M. Deane , title =. Nucleic Acids Research , volume =. 2014 , doi =
2014
-
[6]
Deane and Konrad Krawczyk , title =
Aleksandr Kovaltsuk and Jinwoo Leem and Sebastian Kelm and James Snowden and Charlotte M. Deane and Konrad Krawczyk , title =. The Journal of Immunology , volume =. 2018 , doi =
2018
-
[7]
Matthew I. J. Raybould and Claire Marks and Konrad Krawczyk and Bruck Taddese and Jaroslaw Nowak and Alan P. Lewis and Alexander Bujotzek and Jiye Shi and Charlotte M. Deane , title =. Proceedings of the National Academy of Sciences , volume =. 2019 , doi =
2019
-
[8]
Nucleic Acids Research , volume =
Marie-Paule Lefranc , title =. Nucleic Acids Research , volume =. 2003 , doi =
2003
-
[9]
Nucleic Acids Research , volume =
Antje Chang and Lisa Jeske and Sandra Ulbrich and Julia Hofmann and Julia Koblitz and Ida Schomburg and Meina Neumann-Schaal and Dieter Jahn and Dietmar Schomburg , title =. Nucleic Acids Research , volume =. 2021 , doi =
2021
-
[10]
Nucleic Acids Research , volume =
Ulrike Wittig and Renate Kania and Martin Golebiewski and Maja Rey and Lei Shi and Lenneke Jong and Enkhjargal Algaa and Andreas Weidemann and Heidrun Sauer-Danzwith and Saqib Mir and Olga Krebs and Meik Bittkowski and Elina Wetsch and Isabel Rojas and Wolfgang M. Nucleic Acids Research , volume =. 2012 , doi =
2012
-
[11]
Bioinformatics , volume =
Weizhong Li and Adam Godzik , title =. Bioinformatics , volume =. 2006 , doi =
2006
-
[12]
William P. Russ and Matteo Figliuzzi and Christian Stocker and Pierre Barrat-Charlaix and Michael Socolich and Peter Kast and Donald Hilvert and Remi Monasson and Simona Cocco and Martin Weigt and Rama Ranganathan , title =. Science , volume =. 2020 , doi =
2020
-
[13]
Boyken and David Baker , title =
Po-Ssu Huang and Scott E. Boyken and David Baker , title =. Nature , volume =. 2016 , doi =
2016
-
[14]
Journal of Medicinal Chemistry , volume =
Renxiao Wang and Xueliang Fang and Yipin Lu and Shaomeng Wang , title =. Journal of Medicinal Chemistry , volume =. 2004 , doi =
2004
-
[15]
Bioinformatics , volume =
Justina Jankauskait. Bioinformatics , volume =. 2019 , doi =
2019
-
[16]
Advances in Neural Information Processing Systems , volume =
Pascal Notin and Aaron Kollasch and Daniel Ritter and Lood. Advances in Neural Information Processing Systems , volume =. 2023 , note =
2023
-
[17]
Gomez and Debora S
Pascal Notin and Mafalda Dias and Jonathan Frazer and Javier Marchena-Hurtado and Aidan N. Gomez and Debora S. Marks and Yarin Gal , title =. Proceedings of the 39th International Conference on Machine Learning , series =. 2022 , publisher =
2022
-
[18]
Evolutionary-scale prediction of atomic-level protein structure with a language model , journal =
Zeming Lin and Halil Akin and Roshan Rao and Brian Hie and Zhongkai Zhu and Wenting Lu and Nikita Smetanin and Robert Verkuil and Ori Kabeli and Yaniv Shmueli and Allan. Evolutionary-scale prediction of atomic-level protein structure with a language model , journal =. 2023 , doi =
2023
-
[19]
Ragotte and Lukas F
Justas Dauparas and Ivan Anishchenko and Nathaniel Bennett and Hua Bai and Robert J. Ragotte and Lukas F. Milles and Basile I. M. Wicky and Alexis Courbet and Rob J. Robust deep learning-based protein sequence design using. Science , volume =. 2022 , doi =
2022
-
[20]
John, Peter , title =
Emami, Patrick and Perreault, Alexandre and Law, James and Biagioni, David and St. John, Peter , title =. Machine Learning: Science and Technology , year =
-
[21]
Morey-Burrows and Ivan Anishchenko and Ian R
Rohith Krishna and Jue Wang and Woody Ahern and Pascal Sturmfels and Preetham Venkatesh and Indrek Kalvet and Gyu Rie Lee and Felix S. Morey-Burrows and Ivan Anishchenko and Ian R. Humphreys and Ryan McHugh and Dionne Vafeados and Xinting Li and George A. Sutherland and Andrew Hitchcock and C. Neil Hunter and Alex Kang and Evans Brackenbrough and Asim K. ...
2024
-
[22]
Watson and David Juergens and Nathaniel R
Joseph L. Watson and David Juergens and Nathaniel R. Bennett and Brian L. Trippe and Jason Yim and Helen E. Eisenach and Woody Ahern and Andrew J. Borst and Robert J. Ragotte and Lukas F. Milles and Basile I. M. Wicky and Nikita Hanikel and Samuel J. Pellock and Alexis Courbet and William Sheffler and Jue Wang and Preetham Venkatesh and Isaac Sappington a...
2023
-
[23]
Ghafarollahi, Ali and Buehler, Markus J. , title =. Digital Discovery , year =. doi:10.1039/D4DD00013G , pmid =
-
[24]
7th International Conference on Learning Representations (
Ilya Loshchilov and Frank Hutter , title =. 7th International Conference on Learning Representations (. 2019 , publisher =
2019
-
[25]
8th International Conference on Learning Representations (
Ari Holtzman and Jan Buys and Li Du and Maxwell Forbes and Yejin Choi , title =. 8th International Conference on Learning Representations (. 2020 , publisher =
2020
-
[26]
Jiang and Samuel Daulton and Benjamin Letham and Andrew Gordon Wilson and Eytan Bakshy , title =
Maximilian Balandat and Brian Karrer and Daniel R. Jiang and Samuel Daulton and Benjamin Letham and Andrew Gordon Wilson and Eytan Bakshy , title =. Advances in Neural Information Processing Systems , volume =. 2020 , url =
2020
-
[27]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
Ahmed Elnaggar and Michael Heinzinger and Christian Dallago and Ghalia Rehawi and Yu Wang and Llion Jones and Tom Gibbs and Tamas Feher and Christoph Angerer and Martin Steinegger and Debsindhu Bhowmik and Burkhard Rost , title =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2022 , doi =
2022
-
[28]
arXiv preprint arXiv:2301.06568 , year =
Ahmed Elnaggar and Hazem Essam and Wafaa Salah-Eldin and Walid Moustafa and Mohamed Elkerdawy and Charlotte Rochereau and Burkhard Rost , title =. arXiv preprint arXiv:2301.06568 , year =
-
[29]
Highly accurate protein structure prediction with
John Jumper and Richard Evans and Alexander Pritzel and Tim Green and Michael Figurnov and Olaf Ronneberger and Kathryn Tunyasuvunakool and Russ Bates and Augustin. Highly accurate protein structure prediction with. Nature , volume =. 2021 , doi =
2021
-
[30]
Arnold , title =
Frances H. Arnold , title =. Angewandte Chemie International Edition , volume =. 2018 , doi =
2018
-
[31]
Yang and Zachary Wu and Frances H
Kevin K. Yang and Zachary Wu and Frances H. Arnold , title =. Nature Methods , volume =. 2019 , doi =
2019
-
[32]
Le and Denny Zhou , title =
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed Chi and Quoc V. Le and Denny Zhou , title =. Advances in Neural Information Processing Systems , volume =
-
[33]
Toolformer: Language models can teach themselves to use tools , booktitle =
Timo Schick and Jane Dwivedi-Yu and Roberto Dess. Toolformer: Language models can teach themselves to use tools , booktitle =
-
[34]
12th International Conference on Learning Representations (
Yujia Qin and Shihao Liang and Yining Ye and Kunlun Zhu and Lan Yan and Yaxi Lu and Yankai Lin and Xin Cong and Xiangru Tang and Bill Qian and Sihan Zhao and Lauren Hong and Runchu Tian and Ruobing Xie and Jie Zhou and Mark Gerstein and Dahai Li and Zhiyuan Liu and Maosong Sun , title =. 12th International Conference on Learning Representations (. 2024 , url =
2024
-
[35]
11th International Conference on Learning Representations (
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik Narasimhan and Yuan Cao , title =. 11th International Conference on Learning Representations (. 2023 , url =
2023
-
[36]
Bran and Sam Cox and Oliver Schilter and Carlo Baldassari and Andrew D
Andres M. Bran and Sam Cox and Oliver Schilter and Carlo Baldassari and Andrew D. White and Philippe Schwaller , title =. Nature Machine Intelligence , volume =. 2024 , doi =
2024
-
[37]
Odhran O'Donoghue and Aleksandar Shtedritski and John Ginger and Ralph Abboud and Ali Essa Ghareeb and Justin Booth and Samuel G. Rodriques , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (. 2023 , publisher =. doi:10.18653/v1/2023.emnlp-main.162 , url =
-
[38]
Ingraham and Max Baranov and Zak Costello and Karl W
John B. Ingraham and Max Baranov and Zak Costello and Karl W. Barber and Wujie Wang and Ahmed Ismail and Vincent Frappier and Dana M. Lord and Christopher Ng-Thow-Hing and Erik R. Illuminating protein space with a programmable generative model , journal =. 2023 , doi =
2023
-
[39]
Manning and Chelsea Finn , title =
Rafael Rafailov and Archit Sharma and Eric Mitchell and Stefano Ermon and Christopher D. Manning and Chelsea Finn , title =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[40]
Proceedings of the 39th International Conference on Machine Learning , series =
Samuel Stanton and Wesley Maddox and Nate Gruver and Phillip Maffettone and Emily Delaney and Peyton Greenside and Andrew Gordon Wilson , title =. Proceedings of the 39th International Conference on Machine Learning , series =. 2022 , publisher =
2022
-
[41]
Amir Shanehsazzadeh and Sharrol Bachas and Matt McPartlon and George Kasun and Andrea K. Steiger and John M. Sutton and Edriss Yassine and Cailen McCloskey and Robel Haile and Richard Shuai and Julian Alverio and Goran Rakocevic and Simon Levine and Jovan Cejovic and Jahir M. Gutierrez and Alex Morehead and Oleksii Dubrovskyi and Chelsea Chung and Breanna...
-
[42]
arXiv preprint arXiv:2207.10080 , year =
Ningyu Zhang and Zhen Bi and Xiaozhuan Liang and Siyuan Cheng and Haosen Hong and Shumin Deng and Qiang Zhang and Jiazhang Lian and Huajun Chen , title =. arXiv preprint arXiv:2207.10080 , year =
-
[43]
Hie and Varun R
Brian L. Hie and Varun R. Shanker and Duo Xu and Theodora U. J. Bruun and Payton A. Weidenbacher and Shaogeng Tang and Wesley Wu and John E. Pak and Peter S. Kim , title =. Nature Biotechnology , volume =. 2024 , doi =
2024
-
[44]
2022 , eprint=
AI-based approach for improving the detection of blood doping in sports , author=. 2022 , eprint=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.