Diffusion-Based Heart Sound Generation: Evaluation with Physiological Signal Metrics, Classifiers, and Expert Listening
Pith reviewed 2026-06-28 12:51 UTC · model grok-4.3
The pith
Diffusion model generates heart sound clips that retain cycle durations and allow 82.8 percent classification accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
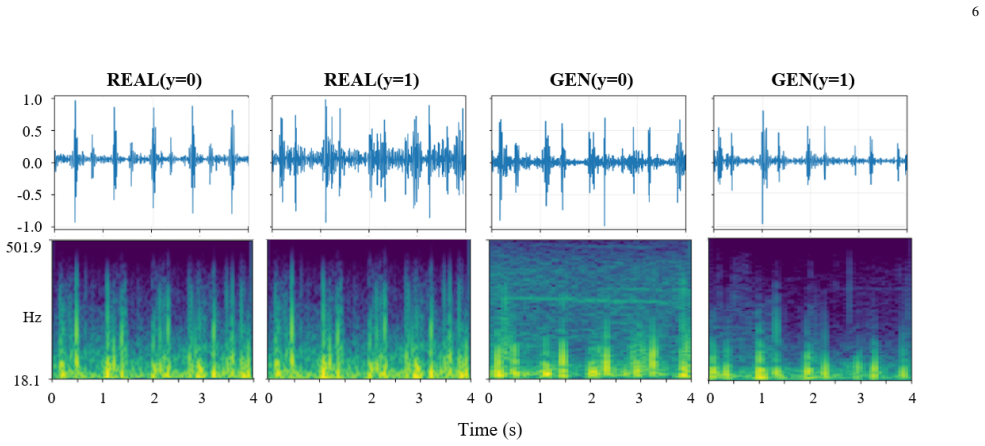
A class-conditional diffusion model operating in the log-mel domain produces 4 s PCG clips whose dominant cycle durations match those of real clips while reduced envelope periodicity and increased transient burstiness appear; a ResNet-50 classifier trained on real data then achieves 82.8 percent accuracy on class-balanced synthetic batches compared with 92.24 percent on the held-out real test set.
What carries the argument
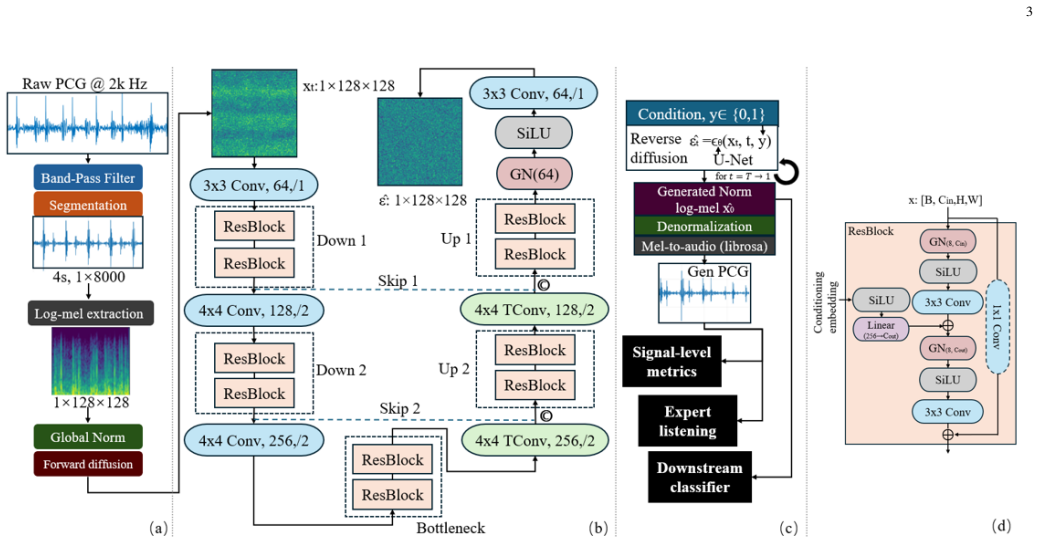
Class-conditional 2D U-Net denoiser with classifier-free guidance trained on normalized 1 x 128 x 128 log-mel representations derived from non-overlapping 4 s clips.
If this is right
- Synthetic clips can supplement limited real PCG datasets for training automated classifiers.
- Generated signals keep enough structure to support normal/abnormal discrimination even after changes in envelope periodicity.
- Expert listeners rate most synthetic 4 s excerpts as heart-sound-like, though abnormality detection remains difficult for both real and synthetic short clips.
- Reconstruction artefacts and reduced periodicity stand as open issues for improving generation fidelity.
Where Pith is reading between the lines
- The approach could generate rare pathological examples absent from current public datasets.
- Testing longer clips or alternative time-frequency representations might better preserve abnormal acoustic cues.
- Mixing synthetic and real clips during classifier training could improve performance on recordings from new patients.
Load-bearing premise
The preprocessing, quality control, recording-level splits, and conversion of 4 s clips into normalized log-mel spectrograms keep the acoustic features needed for both faithful generation and downstream abnormality classification.
What would settle it
Training a fresh classifier solely on the synthetic clips and finding that its accuracy on the held-out real test set falls below 70 percent would show that discriminative structure is not retained.
Figures

read the original abstract
Publicly available phonocardiogram (PCG) datasets remain limited in size and pathological diversity, constraining both auscultation training and the generalisation of automated heart-sound classifiers. A class-conditional diffusion model for PCG generation is developed in the log-mel domain and synthetic fidelity is assessed using complementary (i) physiology-inspired plausibility metrics, (ii) downstream label-consistency evaluation, and (iii) expert listening. Experiments use the Phy-sioNet/Computing in Cardiology Challenge 2016 dataset (3240 recordings) with recording-level splits. After preprocessing and quality control, 16,749 non-overlapping 4 s clips are mapped to a normalised 1 x 128 x 128 log-mel representation to train a conditional 2D U-Net denoiser with classifier-free guidance. Signal-level plausibility is quantified on reconstructed waveforms using three lightweight metrics: an envelope-autocorrelation rhythm score, an amplitude-based explosion score, and the dominant cycle lag. Synthetic clips preserve similar dominant cycle durations but exhibit reduced envelope periodicity and increased transient burstiness relative to real clips. For downstream evaluation, a ResNet-50 classifier achieves 92.24% accuracy on the held-out real test set and 82.8% accuracy on class-balanced synthetic batches, indicating that generated signals retain discriminative structure relevant to normal/abnormal classification. In a pilot expert listening study (60 clips, two clinicians), most synthetic clips are judged as heart-sound-like, while abnormality sensitivity is low for both real and synthetic 4 s excerpts. Overall, the results provide a practical baseline for diffusion-based PCG generation while highlighting remaining challenges in retaining abnormal acoustic cues and reducing reconstruction-induced artefacts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a class-conditional diffusion model for phonocardiogram (PCG) generation in the normalized 1x128x128 log-mel domain using a 2D U-Net denoiser with classifier-free guidance, trained on 16,749 non-overlapping 4 s clips from the PhysioNet/CinC 2016 dataset (3240 recordings) after recording-level splits and quality control. Fidelity is evaluated with three physiological metrics on reconstructed waveforms (envelope-autocorrelation rhythm score, amplitude-based explosion score, dominant cycle lag), a ResNet-50 classifier (92.24% accuracy on held-out real test set vs. 82.8% on class-balanced synthetic batches), and a pilot expert listening study (60 clips, two clinicians). The central claim is that synthetics preserve similar dominant cycle durations but show reduced envelope periodicity and increased transient burstiness while retaining discriminative structure for normal/abnormal classification.
Significance. If the results hold, the work supplies a practical baseline for diffusion-based PCG synthesis to mitigate data scarcity and limited pathological diversity in heart-sound datasets. The use of independent held-out real test data, separate physiological metrics, and external expert listeners provides a multi-metric assessment that credits retained cycle structure while identifying specific limitations; this is stronger than single-metric evaluations common in the area.
major comments (1)
- [Dataset and preprocessing] Dataset and preprocessing section: The mapping of 4 s clips to a normalized 1 x 128 x 128 log-mel representation after quality control and recording-level splits is load-bearing for both the diffusion training and the downstream claim that synthetics retain discriminative structure (evidenced by the 82.8% ResNet-50 accuracy); the manuscript provides insufficient detail on exact quality-control thresholds and validation that abnormal acoustic cues survive this pipeline, leaving open whether the observed metric differences and accuracy gap arise from generation or from preprocessing artifacts.
minor comments (2)
- [Expert listening study] The abstract states that 'most synthetic clips are judged as heart-sound-like' in the expert study but reports low abnormality sensitivity for both real and synthetic 4 s excerpts; the full manuscript should include per-class confusion counts or inter-rater agreement to support the claim that abnormality cues are harder to retain.
- The three physiological metrics are described as 'lightweight' but the manuscript should report their exact formulas or pseudocode (especially the envelope-autocorrelation rhythm score and amplitude-based explosion score) to enable direct reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the value of the multi-metric evaluation. We address the single major comment below and will incorporate the requested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Dataset and preprocessing] Dataset and preprocessing section: The mapping of 4 s clips to a normalized 1 x 128 x 128 log-mel representation after quality control and recording-level splits is load-bearing for both the diffusion training and the downstream claim that synthetics retain discriminative structure (evidenced by the 82.8% ResNet-50 accuracy); the manuscript provides insufficient detail on exact quality-control thresholds and validation that abnormal acoustic cues survive this pipeline, leaving open whether the observed metric differences and accuracy gap arise from generation or from preprocessing artifacts.
Authors: We agree that the manuscript currently provides insufficient detail on the quality-control thresholds and on explicit validation that abnormal acoustic cues survive the pipeline. This is a fair observation. In the revised version we will expand the Dataset and preprocessing section to report: (i) the precise quality-control criteria and thresholds applied after recording-level splits (including any SNR, artifact, or duration filters), (ii) the exact parameters of the 4 s non-overlapping clip extraction and the subsequent normalized 1×128×128 log-mel transformation, and (iii) any quantitative checks (e.g., class-wise feature statistics or classifier performance on pre- vs. post-QC real clips) confirming that abnormal cues are retained. These additions will allow readers to assess whether the reported metric differences and the 82.8 % synthetic accuracy are attributable to the diffusion model rather than preprocessing. We do not anticipate that the core experimental claims will change. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper trains a class-conditional diffusion model on preprocessed log-mel representations of PCG clips from the PhysioNet 2016 dataset using recording-level splits, then evaluates synthetic outputs via three independent channels: physiology-inspired waveform metrics (envelope autocorrelation, explosion score, dominant cycle lag), accuracy of a separately trained ResNet-50 classifier on held-out real test data versus class-balanced synthetic batches, and a small expert listening study. None of these reported quantities are obtained by fitting parameters inside the paper's own equations and then renaming the fit as a prediction; the central claim that generated signals retain discriminative structure is supported by direct comparison against external held-out real data rather than by any self-referential reduction. No load-bearing self-citation, uniqueness theorem, or ansatz smuggling appears in the provided text.
Axiom & Free-Parameter Ledger
free parameters (2)
- U-Net architecture hyperparameters and classifier-free guidance scale
- Exact preprocessing and quality-control thresholds
axioms (1)
- domain assumption Log-mel spectrogram representation of 4 s clips preserves acoustic cues needed for both diffusion generation and normal/abnormal discrimination.
Forward citations
Cited by 1 Pith paper
-
Generative Modeling for Physiological Signals
A literature review of generative models for physiological signals that organizes model families and proposes a hierarchical evaluation framework spanning signal similarity to task utility.
Reference graph
Works this paper leans on
-
[1]
Cardiovascular diseases (CVDs),
World Health Organization, “Cardiovascular diseases (CVDs),” Fact sheet, 31 Jul. 2025. [Online]. Available: https://www.who.int/news- room/fact-sheets/detail/cardiovascular-diseases-(cvds). Accessed: Dec. 17, 2025
2025
-
[2]
Diagnostic accuracy of heart auscultation for detecting valve disease: a systematic review,
A. H. Davidsen, K. Diederichsen, J. L. B. Andersen, H. Schirmer, E. Reierth, and H. Melbye, “Diagnostic accuracy of heart auscultation for detecting valve disease: a systematic review,”BMJ Open, vol. 13, no. 3, e068121, 2023, doi: 10.1136/bmjopen-2022-068121
-
[3]
M. Gunasekera, M. Moniruzzaman, A. Hooper, S. M. Shamsul Islam, G. Dwivedi, and A. Ihdayhid, “Evaluating diagnostic accuracy and clinician variability in auscultation-based identification of valvular heart disease,” Heart, Lung and Circulation, vol. 34, suppl. S4, pp. S418–S419, 2025, doi: 10.1016/j.hlc.2025.06.518
-
[4]
Deep learning algorithms to detect murmurs associated with valvular heart disease,
J. Prince, M. John, K. Spencer, C. Caroline, B. Daniel, H. Cody, Adam Saltman et al., “Deep learning algorithms to detect murmurs associated with valvular heart disease,”Journal of the American Heart Association, 2023, doi: 10.1161/JAHA.123.030377
-
[5]
G. D. Clifford, C. Liu, B. Moody, D. Springer, I. Silva, Q. Li, et al., “Classification of normal/abnormal heart sound recordings: the PhysioNet/Computing in Cardiology Challenge 2016,” inProc. Computing in Cardiology (CinC), vol. 43, pp. 609–612, 2016, doi: 10.22489/CinC.2016.179-154
-
[6]
The CirCor DigiScope dataset: from murmur detection to murmur classification,
J. Oliveira, F. Renna, P. D. Costa, M. Nogueira, C. Oliveira, C. Ferreira, et al., “The CirCor DigiScope dataset: from murmur detection to murmur classification,”IEEE J. Biomed. Health Inform., vol. 26, no. 6, pp. 2524– 2535, Jun. 2022, doi: 10.1109/JBHI.2021.3137048
-
[7]
P. Narv ´aez and W. Percybrooks, “Synthesis of normal heart sounds using generative adversarial networks and empirical wavelet trans- form,”Applied Sciences, vol. 10, no. 19, Art. no. 7003, 2020, doi: 10.3390/app10197003
-
[8]
L. Abbott, M. Marocchi, M. Fynn, Y . Rong, and S. Nordholm, “Genera- tive deep learning and signal processing for data augmentation of cardiac auscultation signals: improving model robustness using synthetic audio,” Biomed. Signal Process. Control, vol. 112, Art. no. 108469, 2026, doi: 10.1016/j.bspc.2025.108469
-
[9]
BioDiffusion: a ver- satile diffusion model for biomedical signal synthesis,
X. Li, M. Sakevych, G. Atkinson, and V . Metsis, “BioDiffusion: a ver- satile diffusion model for biomedical signal synthesis,”Bioengineering (Basel), vol. 11, no. 4, Art. no. 299, 2024, doi: 10.3390/bioengineer- ing11040299
-
[10]
DiffECG: a versatile probabilistic diffusion model for ECG signals synthesis,
N. Neifar, A. Ben-Hamadou, A. Mdhaffar, and M. Jmaiel, “DiffECG: a versatile probabilistic diffusion model for ECG signals synthesis,” arXiv:2306.01875, 2023, doi: 10.48550/arXiv.2306.01875
-
[11]
DiffECG: diffusion model- powered label-efficient and personalized arrhythmia diagnosis,
T. Zhou, Z. Jia, D. Yu, and Z. Shen, “DiffECG: diffusion model- powered label-efficient and personalized arrhythmia diagnosis,” inProc. Int. Joint Conf. Artificial Intelligence (IJCAI-25), pp. 8003–8011, 2025, doi: 10.24963/ijcai.2025/890
-
[12]
The effect of signal duration on the classification of heart sounds: a deep learning approach,
X. Bao, Y . Xu, and E. N. Kamavuako, “The effect of signal duration on the classification of heart sounds: a deep learning approach,”Sensors, vol. 22, no. 6, Art. no. 2261, 2022, doi: 10.3390/s22062261
-
[13]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” arXiv:2010.02502, 2020, doi: 10.48550/arXiv.2010.02502
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2010.02502 2010
-
[14]
X. Bao, Y . Xu, H.-K. Lam, M. Trabelsi, I. Chihi, L. Sidhom, et al., “Time-frequency distributions of heart sound signals: a comparative study using convolutional neural networks,”Biomedical Engineering Ad- vances, vol. 5, Art. no. 100093, 2023, doi: 10.1016/j.bea.2023.100093
-
[15]
Hierarchical multi- scale convolutional network for murmurs detection on PCG signals,
Y . Xu, X. Bao, H.-K. Lam, and E. N. Kamavuako, “Hierarchical multi- scale convolutional network for murmurs detection on PCG signals,” inProc. Computing in Cardiology (CinC), vol. 49, pp. 1–4, 2022, doi: 10.22489/CinC.2022.439
-
[16]
Dual Bayesian ResNet: a deep learning approach to heart murmur detection,
B. Walker, F. Krones, I. Kiskin, G. Parsons, T. Lyons, and A. Mahdi, “Dual Bayesian ResNet: a deep learning approach to heart murmur detection,” inProc. Computing in Cardiology (CinC), vol. 49, pp. 1–4, 2022, doi: 10.22489/CinC.2022.355
-
[17]
X. Bao, P. Lamata, and E. N. Kamavuako, “Signal statistics of heart sound recordings: a comparative study between smartphones and elec- tronic stethoscopes,” inProc. IEEE 22nd Mediterranean Electrotech- nical Conf. (MELECON), pp. 1089–1094, 2024, doi: 10.1109/MELE- CON56669.2024.10608494
-
[18]
Diffusion models beat GANs on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat GANs on image synthesis,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 34, pp. 8780–8794, 2021
2021
-
[19]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” arXiv:2207.12598, 2022, doi: 10.48550/arXiv.2207.12598
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2207.12598 2022
-
[20]
M. A. Reyna, S. K. Sadr, A. W. B. Silva, et al., “Heart murmur detection from phonocardiogram recordings: the George B. Moody PhysioNet Challenge 2022,”PLOS Digital Health, vol. 2, no. 9, e0000324, 2023, doi: 10.1371/journal.pdig.0000324
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.