Principled Reflection Separation via Nonlinear Superposition and Feature Interaction
Pith reviewed 2026-06-28 15:00 UTC · model grok-4.3
The pith
Reflection separation requires a learnable nonlinear superposition model because linear mixing in sRGB fails to capture camera pipeline effects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
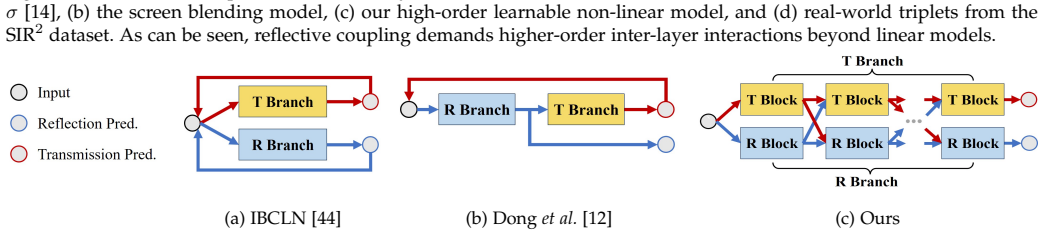
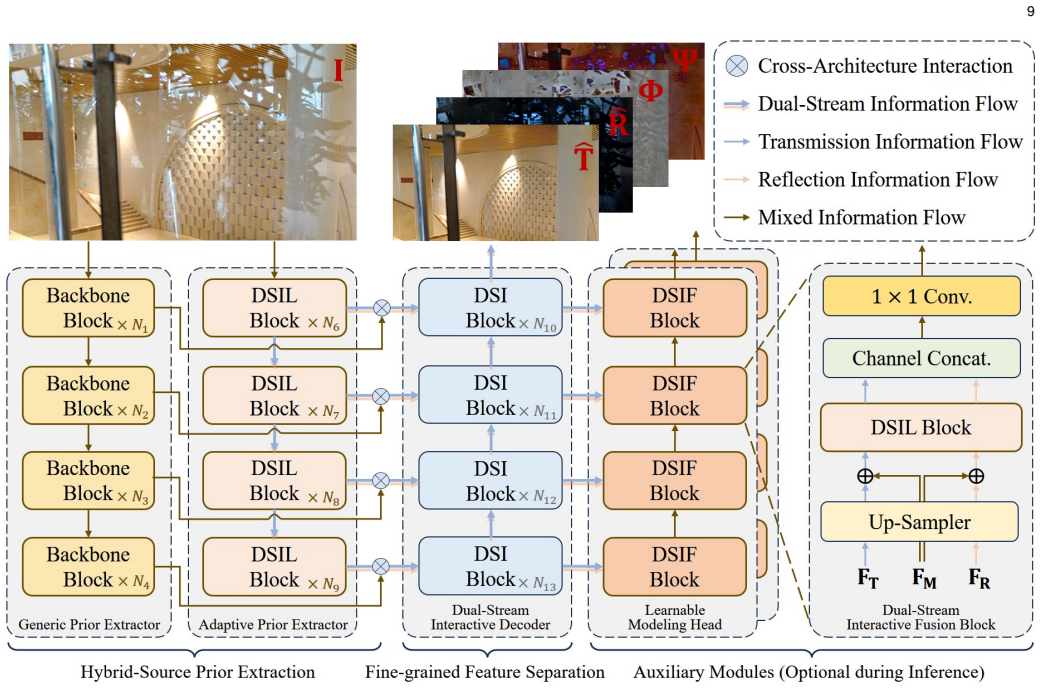
The linear composition model in the sRGB domain fails to capture the nonlinear coupling introduced by real-world image signal processing pipelines; a learnable nonlinear superposition model that more faithfully characterizes layer interactions, together with a generalized dual-stream interactive framework that explicitly models bidirectional dependencies through feature exchange, achieves superior decomposition performance with strong generalization, showing that reflection separation is about learning nonlinear formation and interaction rather than undoing a linear mixture.
What carries the argument
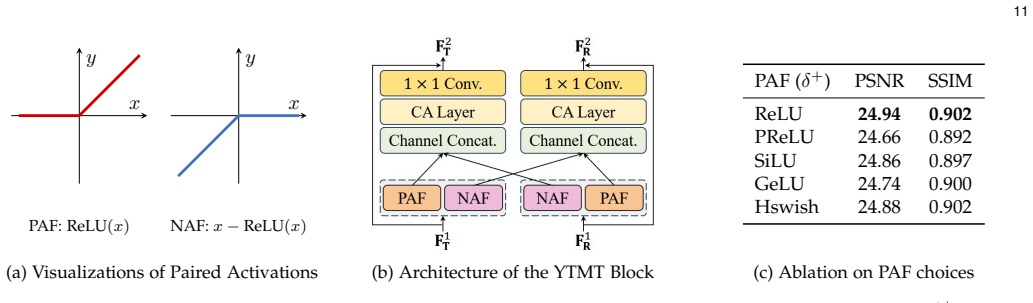
The learnable nonlinear superposition model that characterizes layer interactions, together with the dual-stream interactive framework that models bidirectional dependencies via feature exchange and unifies activation-, gating-, and attention-based mechanisms.
If this is right
- Superior performance on diverse real-world benchmarks for reflection separation
- Strong generalization across different scene conditions and camera pipelines
- Unification of activation-, gating-, and attention-based interaction mechanisms within one framework
- Compatibility with both CNN and Transformer backbones
- New design principle for image decomposition tasks that treats layer formation as nonlinear
Where Pith is reading between the lines
- The same nonlinear superposition idea could be tested on related decomposition tasks such as shadow removal or haze removal where camera pipelines also introduce nonlinearities.
- Collecting training data that explicitly varies ISP parameters across more camera brands would directly test and potentially strengthen the generalization claim.
- The bidirectional feature exchange pattern might transfer to multi-frame or video reflection removal by adding temporal consistency constraints.
Load-bearing premise
A learnable nonlinear superposition function trained on the available benchmarks will generalize to the full range of real-world camera pipelines and scene conditions not represented in those benchmarks.
What would settle it
Quantitative separation accuracy measured on images captured from camera models and pipelines absent from the training benchmarks, compared directly against linear-mixing baselines.
Figures














read the original abstract
Single-image reflection separation is fundamentally challenged by the entanglement of transmission and reflection layers under complex image formation processes. Existing approaches largely rely on simplified assumptions or independent modeling, limiting their ability to handle real-world scenarios. In this work, we revisit the problem from a unified perspective and identify a key issue of existing approaches, i.e., the widely adopted linear composition model in the sRGB domain fails to capture the nonlinear coupling introduced by real-world image signal processing pipelines. To address this, we introduce a learnable nonlinear superposition model that more faithfully characterizes layer interactions and improves decomposition fidelity. Building upon this formulation, we propose a generalized dual-stream interactive framework that explicitly models bidirectional dependencies between transmission and reflection through feature exchange. This framework unifies activation-, gating-, and attention-based interaction mechanisms, and is compatible with both CNN and Transformer backbones. Extensive experiments on diverse real-world benchmarks demonstrate that the proposed approach achieves superior performance with strong generalization capability. More importantly, our study reveals that reflection separation is not about undoing a linear mixture, but about learning nonlinear formation and interaction}, offering new insights into the design of principled image decomposition models. Code and models are publicly available at https://mingcv.github.io/DIRS-Page.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that the standard linear composition model for single-image reflection separation in the sRGB domain fails to capture nonlinear coupling from real ISP pipelines. It introduces a learnable nonlinear superposition model to characterize layer interactions more faithfully, paired with a generalized dual-stream interactive framework that models bidirectional feature dependencies via exchange mechanisms (unifying activation, gating, and attention). The framework is backbone-agnostic (CNN/Transformer) and is shown to yield superior performance and generalization on diverse real-world benchmarks, with the broader claim that reflection separation requires learning nonlinear formation rather than undoing linear mixtures.
Significance. If the empirical gains hold and the learned nonlinearity demonstrably encodes ISP-induced effects rather than benchmark-specific statistics, the work would provide a principled shift away from linear assumptions in image decomposition, with potential impact on related tasks such as intrinsic image decomposition and low-level vision pipelines. The public code release is a positive factor for reproducibility.
major comments (2)
- [Abstract / Experiments] The central generalization claim (strong performance on unseen ISP pipelines and scene conditions) rests on finite real-world benchmarks whose coverage of tone curves, sensor responses, and processing pipelines is necessarily limited; without explicit ISP simulation or parameter-free anchoring of the nonlinearity, it is unclear whether the learnable superposition encodes the claimed physical coupling or merely fits dataset statistics. This directly affects the interpretive claim that 'reflection separation is not about undoing a linear mixture'.
- [Method / Experiments] The dual-stream interactive framework is described as unifying multiple interaction mechanisms, but the load-bearing question is whether the performance lift is attributable to the nonlinear superposition itself or to the added capacity of the interaction modules; an ablation isolating the superposition function (holding the backbone and interaction fixed) is required to support the modeling contribution.
minor comments (2)
- [Method] Notation for the nonlinear superposition function (e.g., how it is parameterized and initialized) should be introduced with an explicit equation early in the method section for clarity.
- [Experiments] The abstract states 'extensive experiments on diverse real-world benchmarks' but does not list the specific datasets or their ISP diversity; this should be stated explicitly in the experiments section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope of our claims. We provide point-by-point responses below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract / Experiments] The central generalization claim (strong performance on unseen ISP pipelines and scene conditions) rests on finite real-world benchmarks whose coverage of tone curves, sensor responses, and processing pipelines is necessarily limited; without explicit ISP simulation or parameter-free anchoring of the nonlinearity, it is unclear whether the learnable superposition encodes the claimed physical coupling or merely fits dataset statistics. This directly affects the interpretive claim that 'reflection separation is not about undoing a linear mixture'.
Authors: We agree that finite benchmarks limit definitive claims about physical ISP coupling. Our experiments show consistent gains across diverse real-world datasets with varying capture conditions, supporting the value of nonlinear modeling. However, without explicit ISP simulation, the learned function remains data-driven. In revision we will add analysis of the learned nonlinearity (e.g., its response to synthetic tone curves) and temper the interpretive claim to emphasize empirical superiority of nonlinear over linear formation rather than direct physical encoding. revision: partial
-
Referee: [Method / Experiments] The dual-stream interactive framework is described as unifying multiple interaction mechanisms, but the load-bearing question is whether the performance lift is attributable to the nonlinear superposition itself or to the added capacity of the interaction modules; an ablation isolating the superposition function (holding the backbone and interaction fixed) is required to support the modeling contribution.
Authors: We concur that isolating the superposition contribution is essential. We will add an ablation that replaces the nonlinear superposition with its linear counterpart while freezing the dual-stream interaction modules and backbone, directly quantifying the modeling gain attributable to nonlinearity. revision: yes
Circularity Check
No circularity; claims rest on empirical benchmarks without self-referential reduction
full rationale
The paper advances a learnable nonlinear superposition model and dual-stream interactive framework after observing that linear sRGB composition fails to capture ISP-induced nonlinearities. No equations, derivations, or parameter-fitting steps are supplied that would reduce any claimed prediction or uniqueness result to the inputs by construction. Central assertions of superior performance and generalization are supported by experimental comparisons on real-world benchmarks rather than self-citations, ansatzes smuggled via prior work, or definitional equivalences. The absence of any load-bearing mathematical chain that collapses to fitted values or author-specific uniqueness theorems keeps the derivation self-contained against external validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Agrawal, Ramesh Raskar, Shree K
Amit K. Agrawal, Ramesh Raskar, Shree K. Nayar, and Yuanzhen Li. Removing photography artifacts using gradient projection and flash-exposure sampling.TOG, 24(3):828–835, 2005
2005
-
[2]
The visual centrifuge: Model-free layered video representations
Jean-Baptiste Alayrac, Jo ˜ao Carreira, and Andrew Zisserman. The visual centrifuge: Model-free layered video representations. In CVPR, pages 2457–2466, 2019
2019
-
[3]
Neural machine translation by jointly learning to align and translate
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. In ICLR, 2015
2015
-
[4]
Bergen, Peter J
James R. Bergen, Peter J. Burt, Rajesh Hingorani, and Shmuel Peleg. Transparent-motion analysis. InECCV, volume 427, pages 566–569, 1990
1990
-
[5]
Bergen, Peter J
James R. Bergen, Peter J. Burt, Rajesh Hingorani, and Shmuel Peleg. A three-frame algorithm for estimating two-component image motion.TP AMI, 14(9):886–896, 1992
1992
-
[6]
Principles of optics, 1965
Max Born and Emil Wolf. Principles of optics, 1965
1965
-
[7]
Topiq: A top- down approach from semantics to distortions for image quality assessment.TIP, 33:2404–2418, 2024
Chaofeng Chen, Jiadi Mo, Jingwen Hou, Haoning Wu, Liang Liao, Wenxiu Sun, Qiong Yan, and Weisi Lin. Topiq: A top- down approach from semantics to distortions for image quality assessment.TIP, 33:2404–2418, 2024
2024
-
[8]
Firm: Flexible interactive reflection removal
Xiao Chen, Xudong Jiang, Yunkang Tao, Zhen Lei, Qing Li, Chenyang Lei, and Zhaoxiang Zhang. Firm: Flexible interactive reflection removal. InAAAI, volume 39, pages 2230–2238, 2025
2025
-
[9]
A closer look at the reflection formulation in single image reflection removal.TIP, 2024
Zhikai Chen, Fuchen Long, Zhaofan Qiu, Juyong Zhang, Zheng- Jun Zha, Ting Yao, and Jiebo Luo. A closer look at the reflection formulation in single image reflection removal.TIP, 2024
2024
-
[10]
Interference reflection separation from a single image
Yun-Chung Chung, Shyang-Lih Chang, Jung Ming Wang, and Sei- Wang Chen. Interference reflection separation from a single image. InWACV, pages 1–6, 2009
2009
-
[11]
Language modeling with gated convolutional networks
Yann N Dauphin, Angela Fan, Michael Auli, and David Grangier. Language modeling with gated convolutional networks. InICML, pages 933–941, 2017
2017
-
[12]
Zheng Dong, Ke Xu, Yin Yang, Hujun Bao, Weiwei Xu, and Rynson W. H. Lau. Location-aware single image reflection removal. In ICCV, pages 4997–5006, 2021
2021
-
[13]
Mark Everingham, Luc Van Gool, Christopher K. I. Williams, John M. Winn, and Andrew Zisserman. The pascal visual object classes (VOC) challenge.IJCV, 88(2):303–338, 2010
2010
-
[14]
Qingnan Fan, Jiaolong Yang, Gang Hua, Baoquan Chen, and David P . Wipf. A generic deep architecture for single image reflection removal and image smoothing. InICCV, pages 3258– 3267, 2017
2017
-
[15]
Hany Farid and Edward H. Adelson. Separating reflections and lighting using independent components analysis. InCVPR, pages 1262–1267, 1999
1999
-
[16]
Contrastive feature decomposition for image reflection removal
Xin Feng, Haobo Ji, Bo Jiang, Wenjie Pei, Fanglin Chen, and Guangming Lu. Contrastive feature decomposition for image reflection removal. InICME, pages 1–6, 2021
2021
-
[17]
Deep-masking generative network: A unified framework for background restoration from superimposed im- ages.TIP, 30:4867–4882, 2021
Xin Feng, Wenjie Pei, Zihui Jia, Fanglin Chen, David Zhang, and Guangming Lu. Deep-masking generative network: A unified framework for background restoration from superimposed im- ages.TIP, 30:4867–4882, 2021
2021
-
[18]
Blindly separating mixtures of multiple layers with spatial shifts
Kun Gai, Zhenwei Shi, and Changshui Zhang. Blindly separating mixtures of multiple layers with spatial shifts. InCVPR, 2008
2008
-
[19]
Blind separation of superimposed moving images using image statistics.TP AMI, 34:19–32, 2012
Kun Gai, Zhenwei Shi, and Changshui Zhang. Blind separation of superimposed moving images using image statistics.TP AMI, 34:19–32, 2012
2012
-
[20]
Robust separation of reflection from multiple images
Xiaojie Guo, Xiaochun Cao, and Yi Ma. Robust separation of reflection from multiple images. InCVPR, pages 2195–2202, 2014
2014
-
[21]
Reflection removal using low- rank matrix completion
Byeong-Ju Han and Jae-Young Sim. Reflection removal using low- rank matrix completion. InCVPR, pages 3872–3880, 2017
2017
-
[22]
Glass reflection removal using co-saliency-based image alignment and low-rank matrix completion in gradient domain.TIP, 27(10):4873–4888, 2018
Byeong-Ju Han and Jae-Young Sim. Glass reflection removal using co-saliency-based image alignment and low-rank matrix completion in gradient domain.TIP, 27(10):4873–4888, 2018
2018
-
[23]
Light flickering guided reflection removal.IJCV, 132(9):3933–3953, 2024
Yuchen Hong, Yakun Chang, Jinxiu Liang, Lei Ma, Tiejun Huang, and Boxin Shi. Light flickering guided reflection removal.IJCV, 132(9):3933–3953, 2024
2024
-
[24]
Kot, and Boxin Shi
Yuchen Hong, Qian Zheng, Lingran Zhao, Xudong Jiang, Alex C. Kot, and Boxin Shi. Panoramic image reflection removal. InCVPR, pages 7762–7771, 2021
2021
-
[25]
Kot, and Boxin Shi
Yuchen Hong, Qian Zheng, Lingran Zhao, Xudong Jiang, Alex C. Kot, and Boxin Shi. Par 2net: End-to-end panoramic image reflec- tion removal.TP AMI, 45(10):12192–12205, 2023
2023
-
[26]
L-differ: Single image reflection removal with language- based diffusion model
Yuchen Hong, Haofeng Zhong, Shuchen Weng, Jinxiu Liang, and Boxin Shi. L-differ: Single image reflection removal with language- based diffusion model. InECCV, pages 58–76, 2024
2024
-
[27]
Mobilenets: Efficient convolutional neural networks for mobile vision applications.arXiv preprint, 2017
Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications.arXiv preprint, 2017
2017
-
[28]
Dereflection any image with diffusion priors and diversified data
Jichen Hu, Chen Yang, Zanwei Zhou, Jiemin Fang, Qi Tian, and Wei Shen. Dereflection any image with diffusion priors and diversified data. InAAAI, volume 40, pages 4860–4868, 2026
2026
-
[29]
Trash or treasure? an interactive dual-stream strategy for single image reflection separation
Qiming Hu and Xiaojie Guo. Trash or treasure? an interactive dual-stream strategy for single image reflection separation. In NeurIPS, pages 24683–24694, 2021. 22
2021
-
[30]
Single image reflection separation via component synergy
Qiming Hu and Xiaojie Guo. Single image reflection separation via component synergy. InICCV, pages 13138–13147, 2023
2023
-
[31]
Single image reflec- tion separation via dual-stream interactive transformers.NeurIPS, 37:55228–55248, 2024
Qiming Hu, Hainuo Wang, and Xiaojie Guo. Single image reflec- tion separation via dual-stream interactive transformers.NeurIPS, 37:55228–55248, 2024
2024
-
[32]
A lightweight deep exclusion unfolding network for single image reflection removal.TP AMI, 47(6):4957–4973, 2025
Jun-Jie Huang, Tianrui Liu, Zihan Chen, Xinwang Liu, Meng Wang, and Pier Luigi Dragotti. A lightweight deep exclusion unfolding network for single image reflection removal.TP AMI, 47(6):4957–4973, 2025
2025
-
[33]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InICCV, pages 5148–5157, 2021
2021
-
[34]
Removing reflections from raw photos
Eric Kee, Adam Pikielny, Kevin Blackburn-Matzen, and Marc Levoy. Removing reflections from raw photos. InCVPR, pages 161–171, 2025
2025
-
[35]
Naejin Kong, Yu-Wing Tai, and Joseph S. Shin. A physically- based approach to reflection separation: From physical modeling to constrained optimization.TP AMI, 36(2):209–221, 2014
2014
-
[36]
High-quality reflection separation using polarized images.TIP, 20(12):3393– 3405, 2011
Naejin Kong, Yu-Wing Tai, and Sung Yong Shin. High-quality reflection separation using polarized images.TIP, 20(12):3393– 3405, 2011
2011
-
[37]
Robust reflection removal with reflection-free flash-only cues
Chenyang Lei and Qifeng Chen. Robust reflection removal with reflection-free flash-only cues. InCVPR, pages 14811–14820, 2021
2021
-
[38]
Polarized reflection removal with perfect alignment in the wild
Chenyang Lei, Xuhua Huang, Mengdi Zhang, Qiong Yan, Wenxiu Sun, and Qifeng Chen. Polarized reflection removal with perfect alignment in the wild. InCVPR, pages 1747–1755, 2020
2020
-
[39]
Robust reflection removal with flash-only cues in the wild.TP AMI, 45(12):15530– 15545, 2023
Chenyang Lei, Xudong Jiang, and Qifeng Chen. Robust reflection removal with flash-only cues in the wild.TP AMI, 45(12):15530– 15545, 2023
2023
-
[40]
User assisted separation of reflections from a single image using a sparsity prior
Anat Levin and Yair Weiss. User assisted separation of reflections from a single image using a sparsity prior. InECCV, pages 602– 613, 2004
2004
-
[41]
User assisted separation of reflections from a single image using a sparsity prior.TP AMI, 29(9):1647– 1654, 2007
Anat Levin and Yair Weiss. User assisted separation of reflections from a single image using a sparsity prior.TP AMI, 29(9):1647– 1654, 2007
2007
-
[42]
Learning to perceive transparency from the statistics of natural scenes
Anat Levin, Assaf Zomet, and Yair Weiss. Learning to perceive transparency from the statistics of natural scenes. InNeurIPS, pages 1247–1254, 2002
2002
-
[43]
Separating reflections from a single image using local features
Anat Levin, Assaf Zomet, and Yair Weiss. Separating reflections from a single image using local features. InCVPR, pages 306–313, 2004
2004
-
[44]
Hopcroft
Chao Li, Yixiao Yang, Kun He, Stephen Lin, and John E. Hopcroft. Single image reflection removal through cascaded refinement. In CVPR, pages 3562–3571, 2020
2020
-
[45]
Reflection separation via multi-bounce polarization state tracing
Rui Li, Simeng Qiu, Guangming Zang, and Wolfgang Heidrich. Reflection separation via multi-bounce polarization state tracing. InECCV, pages 781–796, 2020
2020
-
[46]
Yu Li and Michael S. Brown. Exploiting reflection change for automatic reflection removal. InICCV, pages 2432–2439, 2013
2013
-
[47]
Yu Li and Michael S. Brown. Single image layer separation using relative smoothness. InCVPR, pages 2752–2759, 2014
2014
-
[48]
Two-stage single image reflection removal with reflection- aware guidance.Applied Intelligence, 53(16):19433–19448, 2023
Yu Li, Ming Liu, Yaling Yi, Qince Li, Dongwei Ren, and Wangmeng Zuo. Two-stage single image reflection removal with reflection- aware guidance.Applied Intelligence, 53(16):19433–19448, 2023
2023
-
[49]
Learning to see through obstructions
Yu-Lun Liu, Wei-Sheng Lai, Ming-Hsuan Yang, Yung-Yu Chuang, and Jia-Bin Huang. Learning to see through obstructions. In CVPR, pages 14203–14212, 2020
2020
-
[50]
Learning to see through obstructions with layered decomposition.TP AMI, 44(11):8387–8402, 2022
Yu-Lun Liu, Wei-Sheng Lai, Ming-Hsuan Yang, Yung-Yu Chuang, and Jia-Bin Huang. Learning to see through obstructions with layered decomposition.TP AMI, 44(11):8387–8402, 2022
2022
-
[51]
Swin transformer v2: Scaling up capacity and resolution
Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, and Baining Guo. Swin transformer v2: Scaling up capacity and resolution. InCVPR, pages 11999–12009, 2022
2022
-
[52]
Reflection separation using a pair of unpolarized and polarized images
Youwei Lyu, Zhaopeng Cui, Si Li, Marc Pollefeys, and Boxin Shi. Reflection separation using a pair of unpolarized and polarized images. InNeurIPS, pages 14532–14542, 2019
2019
-
[53]
Rectifier nonlinearities improve neural network acoustic models
Andrew L Maas, Awni Y Hannun, Andrew Y Ng, et al. Rectifier nonlinearities improve neural network acoustic models. InICML Workshop, volume 30, page 3, 2013
2013
-
[54]
Nayar, Xi-Sheng Fang, and Terrance E
Shree K. Nayar, Xi-Sheng Fang, and Terrance E. Boult. Separation of reflection components using color and polarization.IJCV, 21(3):163–186, 1997
1997
-
[55]
Abhijith Punnappurath and Michael S. Brown. Reflection removal using a dual-pixel sensor. InCVPR, pages 1556–1565, 2019
2019
-
[56]
Looking through the glass: Neural surface reconstruction against high specular reflections
Jiaxiong Qiu, Peng-Tao Jiang, Yifan Zhu, Ze-Xin Yin, Ming-Ming Cheng, and Bo Ren. Looking through the glass: Neural surface reconstruction against high specular reflections. InCVPR, pages 20823–20833, 2023
2023
-
[57]
Separating transparent layers through layer information exchange
Bernard Sarel and Michal Irani. Separating transparent layers through layer information exchange. InECCV, pages 328–341, 2004
2004
-
[58]
Separating transparent layers of repetitive dynamic behaviors
Bernard Sarel and Michal Irani. Separating transparent layers of repetitive dynamic behaviors. InICCV, pages 26–32, 2005
2005
-
[59]
Schechner, Nahum Kiryati, and Ronen Basri
Yoav Y. Schechner, Nahum Kiryati, and Ronen Basri. Separation of transparent layers using focus. InICCV, pages 1061–1066, 1998
1998
-
[60]
Polarization-based decorrelation of transparent layers: The incli- nation angle of an invisible surface
Yoav Y Schechner, Joseph Shamir, and Nahum Kiryati. Polarization-based decorrelation of transparent layers: The incli- nation angle of an invisible surface. InICCV, pages 814–819, 1999
1999
-
[61]
Polariza- tion and statistical analysis of scenes containing a semireflector
Yoav Y Schechner, Joseph Shamir, and Nahum Kiryati. Polariza- tion and statistical analysis of scenes containing a semireflector. JOSA A, 17(2):276–284, 2000
2000
-
[62]
A model-guided unfolding network for single image reflection removal
Dongliang Shao, Yunhui Shi, Jin Wang, Nam Ling, and Baocai Yin. A model-guided unfolding network for single image reflection removal. InACM MM Asia, pages 1–7, 2021
2021
-
[63]
Objects365: A large-scale, high-quality dataset for object detection
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. InICCV, pages 8430– 8439, 2019
2019
-
[64]
Yichang Shih, Dilip Krishnan, Fr ´edo Durand, and William T. Freeman. Reflection removal using ghosting cues. InCVPR, pages 3193–3201, 2015
2015
-
[65]
On visual ambiguities due to transparency in motion and stereo
Masahiko Shizawa. On visual ambiguities due to transparency in motion and stereo. InECCV, pages 411–419, 1992
1992
-
[66]
Reflection removal for in- vehicle black box videos
Christian Simon and In Kyu Park. Reflection removal for in- vehicle black box videos. InCVPR, pages 4231–4239, 2015
2015
-
[67]
Sinha, Johannes Kopf, Michael Goesele, Daniel Scharstein, and Richard Szeliski
Sudipta N. Sinha, Johannes Kopf, Michael Goesele, Daniel Scharstein, and Richard Szeliski. Image-based rendering for scenes with reflections.TOG, 31(4):100:1–100:10, 2012
2012
-
[68]
Robust single image reflection removal against adversarial attacks
Zhenbo Song, Zhenyuan Zhang, Kaihao Zhang, Wenhan Luo, Zhaoxin Fan, Wenqi Ren, and Jianfeng Lu. Robust single image reflection removal against adversarial attacks. InCVPR, pages 24688–24698, 2023
2023
-
[69]
Automatic reflection removal using gradient intensity and motion cues
Chao Sun, Shuaicheng Liu, Taotao Yang, Bing Zeng, Zhengning Wang, and Guanghui Liu. Automatic reflection removal using gradient intensity and motion cues. InACM MM, pages 466–470, 2016
2016
-
[70]
Richard Szeliski, Shai Avidan, and P . Anandan. Layer extraction from multiple images containing reflections and transparency. In CVPR, page 1246, 2000
2000
-
[71]
Stereo match- ing with reflections and translucency
Yanghai Tsin, Sing Bing Kang, and Richard Szeliski. Stereo match- ing with reflections and translucency. InCVPR, pages 702–709, 2003
2003
-
[72]
Renjie Wan, Boxin Shi, Ling-Yu Duan, Ah-Hwee Tan, and Alex C. Kot. Benchmarking single-image reflection removal algorithms. In ICCV, pages 3942–3950, 2017
2017
-
[73]
Renjie Wan, Boxin Shi, Ling-Yu Duan, Ah-Hwee Tan, and Alex C. Kot. Crrn: Multi-scale guided concurrent reflection removal net- work. InCVPR, pages 4777–4785, 2018
2018
-
[74]
Renjie Wan, Boxin Shi, Haoliang Li, Ling-Yu Duan, and Alex C. Kot. Reflection scene separation from a single image. InCVPR, pages 2395–2403, 2020
2020
-
[75]
Renjie Wan, Boxin Shi, Ah-Hwee Tan, and Alex C. Kot. Depth of field guided reflection removal. InICIP, pages 21–25, 2016
2016
-
[76]
Exploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Exploring clip for assessing the look and feel of images. InAAAI, volume 37, pages 2555–2563, 2023
2023
-
[77]
Personalized single image reflection removal network through adaptive cascade refinement
Mengyi Wang, Xinxin Zhang, Yongshun Gong, and Yilong Yin. Personalized single image reflection removal network through adaptive cascade refinement. InACM MM, pages 8204–8213, 2023
2023
-
[78]
Wipf, and Hua Huang
Kaixuan Wei, Jiaolong Yang, Ying Fu, David P . Wipf, and Hua Huang. Single image reflection removal exploiting misaligned training data and network enhancements. InCVPR, pages 8178– 8187, 2019
2019
-
[79]
Single image reflection removal beyond linearity
Qiang Wen, Yinjie Tan, Jing Qin, Wenxi Liu, Guoqiang Han, and Shengfeng He. Single image reflection removal beyond linearity. InCVPR, pages 3771–3779, 2019
2019
-
[80]
Separating reflection and transmission images in the wild
Patrick Wieschollek, Orazio Gallo, Jinwei Gu, and Jan Kautz. Separating reflection and transmission images in the wild. In ECCV, pages 90–105, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.