Characterization and Effects of CS2 Learning with GenAI, Visualization, and Human Support
Pith reviewed 2026-06-28 12:20 UTC · model grok-4.3
The pith
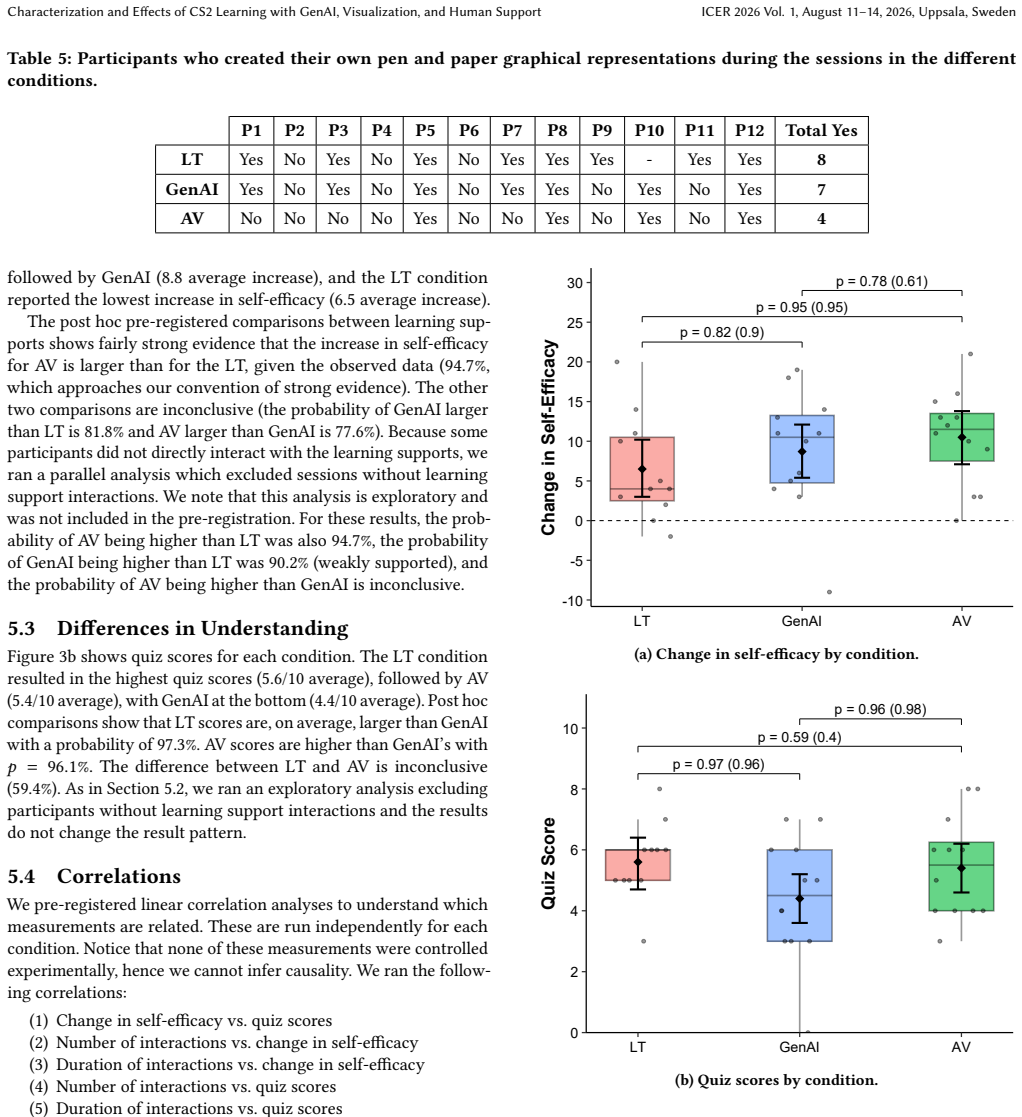
GenAI raised self-efficacy more than live tutoring but produced lower test scores on algorithms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
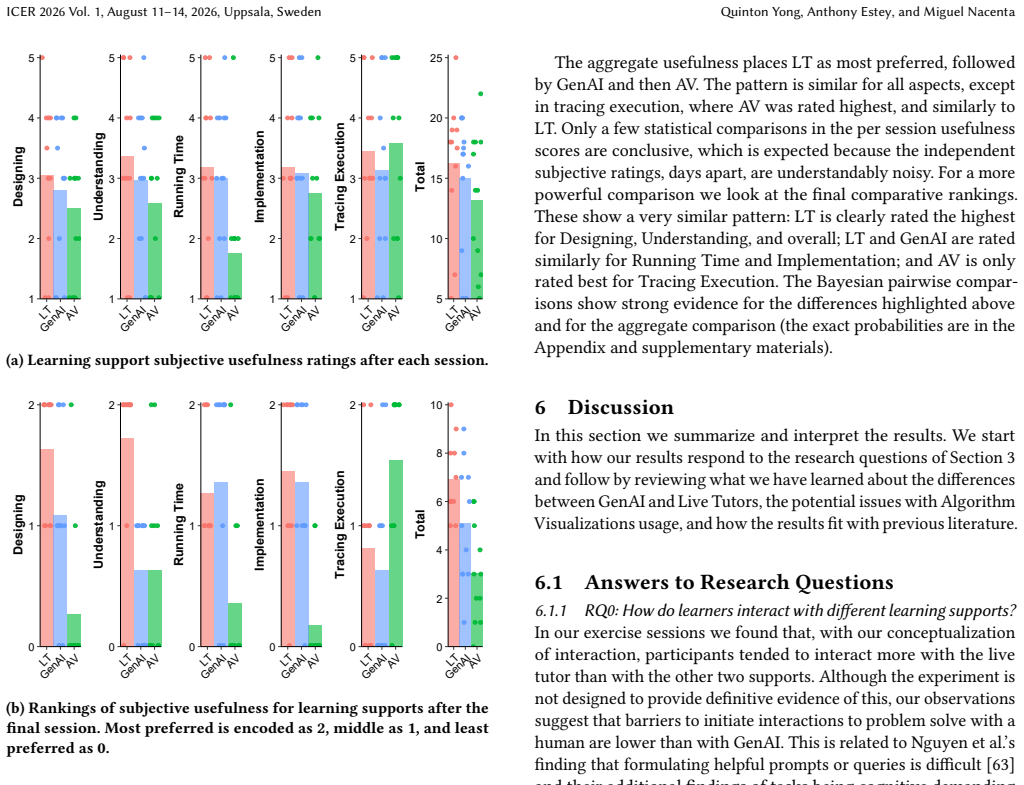
In sessions on sorting, tree, and graph algorithms, participants who interacted with GenAI exhibited greater increases in self-efficacy than those with live tutoring, yet achieved noticeably lower results on tests of conceptual understanding. Live tutoring yielded the highest learning outcomes, while algorithm visualizations were not used effectively and GenAI presented usage barriers for advanced concepts.
What carries the argument
Mixed-methods comparison of three learning-support conditions (GenAI, algorithm visualization, live tutoring) using gaze data, interaction logs, self-efficacy surveys, and post-session tests on conceptual understanding.
If this is right
- Live tutoring produces higher conceptual understanding than GenAI for these topics.
- GenAI interactions require additional scaffolding to prevent lower learning outcomes on advanced algorithms.
- Algorithm visualizations need design changes to overcome observed usage barriers.
- Self-efficacy gains from GenAI do not reliably predict improved test performance.
- Human tutoring supplies benefits in problem-solving guidance that current GenAI does not replicate.
Where Pith is reading between the lines
- Hybrid sessions that combine GenAI with brief human check-ins could retain confidence gains while improving outcomes.
- The observed barriers suggest GenAI interfaces may need explicit prompts for step-by-step reasoning on advanced CS material.
- Results from a single algorithms course invite testing whether the same pattern holds for other second-year CS topics such as data structures or operating systems.
Load-bearing premise
That the post-session test scores validly capture conceptual understanding of the algorithms and that the three 90-minute conditions are comparable in difficulty and student effort.
What would settle it
A follow-up experiment with the same three conditions but a larger sample or an alternate measure of conceptual understanding that shows no outcome difference between GenAI and live tutoring.
Figures

read the original abstract
Generative AI (GenAI) is becoming a widely adopted learning support tool for both students and instructors, as it offers benefits such as personalized tutoring and scaffolded learning. However, recent research highlights potential drawbacks such as overreliance and metacognitive issues, especially in novice programmers. Most prior work focuses on introductory programming courses, and important questions remain about the underlying mechanisms behind the negative effects of GenAI and if findings can be generalized when students learn more advanced computer science concepts. To address this gap, we conducted a mixed-methods study comparing student interactions with GenAI to two traditional learning supports in a second-year algorithms course: algorithm visualization (AV) and human live tutoring (LT). Twelve students participated in three 90-minute study sessions focusing on sorting, tree, and graph algorithms. We recorded gaze and interaction data, and each session concluded with a test assessing their conceptual understanding of the topic. Our analysis classifies when during the problem-solving process participants sought help, and compares the interaction patterns across the three learning supports. Although GenAI produced a larger increase in self-efficacy compared to live tutoring, it was associated with noticeably lower results in learning outcomes. We found that participants did not use algorithm visualizations effectively, faced usage barriers when using GenAI to learn advanced topics, and that live tutoring yielded the highest learning outcomes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a mixed-methods study with 12 second-year CS students comparing three 90-minute learning supports—GenAI, algorithm visualization (AV), and live tutoring (LT)—on distinct topics (sorting, trees, graphs). Each participant experienced all three supports in a within-subjects design. Data included gaze tracking, interaction logs, pre/post self-efficacy, and post-session tests of conceptual understanding. Key claims: GenAI produced a larger self-efficacy gain than LT but noticeably lower test scores; LT yielded the highest outcomes; students struggled to use AV effectively and encountered usage barriers with GenAI on advanced topics.
Significance. If the central attribution of outcome differences to support type rather than topic holds, the work supplies timely empirical data on GenAI's confidence-versus-competence trade-off in CS2 algorithms, extending prior intro-programming findings. The mixed-methods capture of help-seeking timing and interaction patterns is a methodological strength that could inform tool design. However, the small n and design features limit immediate generalizability to classroom practice.
major comments (3)
- [Methods / Experimental Procedure] Methods / Experimental Procedure: Each of the 12 participants was assigned a different support to a different topic (sorting, trees, graphs) with no mention of counterbalancing, Latin-square ordering, pre-session topic-difficulty ratings, or statistical modeling of topic effects. Because post-session test scores are the primary dependent variable for the claim that GenAI produced 'noticeably lower results in learning outcomes,' any unaccounted topic variance directly undermines attribution to support type.
- [Results] Results: No statistical details (p-values, effect sizes, confidence intervals, or error bars) are reported for the test-score comparisons despite n=12. The abstract's qualitative phrasing ('noticeably lower') therefore cannot be evaluated for reliability or practical significance.
- [Methods] Methods: The post-session tests are asserted to assess 'conceptual understanding,' yet no information is supplied on item construction, pilot testing, reliability, or alignment with the three algorithm topics. This measurement validity is load-bearing for all learning-outcome claims.
minor comments (2)
- [Abstract / Methods] Abstract and Methods: Clarify whether the three topics were presented in fixed or randomized order and whether any pre-test of prior knowledge was administered before the first session.
- [Analysis] The manuscript would benefit from explicit reporting of how gaze and interaction data were coded for 'when during the problem-solving process participants sought help.'
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, acknowledging limitations where the original manuscript is incomplete, and describe the revisions we will make to strengthen the work.
read point-by-point responses
-
Referee: [Methods / Experimental Procedure] Methods / Experimental Procedure: Each of the 12 participants was assigned a different support to a different topic (sorting, trees, graphs) with no mention of counterbalancing, Latin-square ordering, pre-session topic-difficulty ratings, or statistical modeling of topic effects. Because post-session test scores are the primary dependent variable for the claim that GenAI produced 'noticeably lower results in learning outcomes,' any unaccounted topic variance directly undermines attribution to support type.
Authors: We agree this is a substantive limitation. The within-subjects design had each participant experience all three supports across the three topics, but the manuscript does not describe any counterbalancing of support-topic assignments, pre-ratings of topic difficulty, or modeling of topic as a factor. This confounds attribution of test-score differences to support type alone. We will revise the Methods section to detail the exact assignment procedure used and add an explicit Limitations subsection discussing topic variance as a threat to internal validity, while noting that the gaze, interaction-log, and help-seeking timing data provide convergent evidence independent of the test scores. revision: yes
-
Referee: [Results] Results: No statistical details (p-values, effect sizes, confidence intervals, or error bars) are reported for the test-score comparisons despite n=12. The abstract's qualitative phrasing ('noticeably lower') therefore cannot be evaluated for reliability or practical significance.
Authors: The study was designed as an exploratory mixed-methods investigation with a small sample; we therefore reported only descriptive patterns rather than inferential tests. We will revise the Results section to report means, standard deviations, and effect sizes (Cohen's d) for the test-score comparisons between conditions, include error bars on any relevant figures, and qualify the abstract language to emphasize the descriptive nature of the observed differences. We will also add a sentence in the Limitations section noting the absence of statistical significance testing given the sample size. revision: yes
-
Referee: [Methods] Methods: The post-session tests are asserted to assess 'conceptual understanding,' yet no information is supplied on item construction, pilot testing, reliability, or alignment with the three algorithm topics. This measurement validity is load-bearing for all learning-outcome claims.
Authors: The manuscript is missing these details. The tests were constructed by the research team as short conceptual questions (multiple-choice and open-ended) targeting core ideas for each topic (e.g., asymptotic analysis for sorting, traversal properties for trees) and were reviewed by the course instructor for alignment with CS2 learning objectives. No formal pilot testing or reliability statistics were performed. We will expand the Methods section with this information, include one or two sample items per topic, and note the lack of psychometric validation as a limitation. revision: yes
Circularity Check
Empirical study with direct outcome measurements; no derivations or self-citational reductions present
full rationale
The paper reports results from a mixed-methods user study with 12 participants across three conditions, measuring self-efficacy changes and post-session test scores directly from collected data (gaze, interactions, and tests). No equations, fitted parameters, predictions derived from prior fits, or load-bearing self-citations appear in the provided abstract or description. The central claims rest on observed differences in measured outcomes rather than any chain that reduces to its own inputs by construction. This is a standard empirical design with no mathematical derivation to inspect for circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Post-session test scores validly measure conceptual understanding of sorting, tree, and graph algorithms
- domain assumption The three learning-support conditions are comparable in difficulty and student engagement
Reference graph
Works this paper leans on
-
[1]
Elmira Adeeb and Kasia Muldner. 2025. How Do Novice Programmers Solve Code-Tracing Problems When ChatGPT Is Available? A Qualitative Analysis.. In Proceedings of the 2025 ACM Conference on International Computing Education Characterization and Effects of CS2 Learning with GenAI, Visualization, and Human Support ICER 2026 Vol. 1, August 11–14, 2026, Uppsal...
-
[2]
Marc Alier, Francisco García-Peñalvo, and Jorge D. Camba. 2024. Generative Artificial Intelligence in Education: From Deceptive to Disruptive.International Journal of Interactive Multimedia and Artificial Intelligence8 (03 2024), 5–14. doi:10.9781/ijimai.2024.02.011
-
[3]
Matin Amoozadeh, Daye Nam, Daniel Prol, Ali Alfageeh, James Prather, Michael Hilton, Sruti Srinivasa Ragavan, and Amin Alipour. 2024. Student-AI Interaction: A Case Study of CS1 students. InProceedings of the 24th Koli Calling International Conference on Computing Education Research (Koli Calling ’24). Association for Computing Machinery, New York, NY, US...
arXiv 2024
-
[4]
2017.Understanding and Improving Blind Students’ Access to Visual Information in Computer Science Education
Catherine Marie Baker. 2017.Understanding and Improving Blind Students’ Access to Visual Information in Computer Science Education. Ph. D. Dissertation
2017
-
[5]
Albert Bandura. 1978. Self-efficacy: Toward a unifying theory of behavioral change.Advances in Behaviour Research and Therapy1, 4 (1978), 139–161. doi:10.1016/0146-6402(78)90002-4 Perceived Self-Efficacy: Analyses of Bandura’s Theory of Behavioural Change
-
[6]
Patrick Bassner, Eduard Frankford, and Stephan Krusche. 2024. Iris: An AI- Driven Virtual Tutor for Computer Science Education. InProceedings of the 2024 on Innovation and Technology in Computer Science Education V. 1(Milan, Italy)(ITiCSE 2024). Association for Computing Machinery, New York, NY, USA, 394–400. doi:10.1145/3649217.3653543
-
[7]
Brett A Becker, Michelle Craig, Paul Denny, Hieke Keuning, Natalie Kiesler, Juho Leinonen, Andrew Luxton-Reilly, James Prather, and Keith Quille. 2023. Generative AI in introductory programming.Computer Science Curricula(2023), 438–439
2023
-
[8]
Brett A. Becker, Paul Denny, James Finnie-Ansley, Andrew Luxton-Reilly, James Prather, and Eddie Antonio Santos. 2023. Programming Is Hard - Or at Least It Used to Be: Educational Opportunities and Challenges of AI Code Generation. In Proceedings of the 54th ACM Technical Symposium on Computer Science Education V. 1(Toronto ON, Canada)(SIGCSE 2023). Assoc...
-
[9]
Sassi Bentrad, Djamel Meslati, et al . 2011. Visual programming and program visualization towards an ideal visual software engineering system.ACEEE Inter- national Journal on Information Technology1, 3 (2011), 43–49
2011
-
[10]
Dennis J. Bouvier, Bruno Pereira Cipriano, Richard Glassey, Olga Petrovska, Emma Anderson, Anastasiia Birillo, Ryan Dougherty, Raymond Pettit, Nuno Pombo, Ebrahim Rahimi, Charanya Ramakrishnan, Alexander Steinmaurer, Shubbhi Taneja, Muhammad Usman, and Annapurna Vadaparty. 2026. The Rest of the Robots: Generative AI in Post-introductory Computing Educatio...
-
[11]
Marc H. Brown and Robert Sedgewick. 1984. A system for algorithm animation. SIGGRAPH Comput. Graph.18, 3 (Jan. 1984), 177–186. doi:10.1145/964965.808596
-
[12]
Doga Cambaz and Xiaoling Zhang. 2024. Use of AI-driven Code Generation Mod- els in Teaching and Learning Programming: a Systematic Literature Review. In Proceedings of the 55th ACM Technical Symposium on Computer Science Education V. 1(Portland, OR, USA)(SIGCSE 2024). Association for Computing Machinery, New York, NY, USA, 172–178. doi:10.1145/3626252.3630958
-
[13]
Lucky Christiawan and Oscar Karnalim. 2016. AP-ASD1: An Indonesian Desktop- based Educational Tool for Basic Data Structure Course.Jurnal Teknik Informatika dan Sistem Informasi2, 1 (2016)
2016
-
[14]
Victoria Clarke and Virginia Braun. 2017. Thematic analysis.The journal of positive psychology12, 3 (2017), 297–298
2017
-
[15]
April R Crockett and Gerald C Gannod. 2020. Improving understanding of data structures for the blind with tactile media and a user-centered iterative approach. In2020 IEEE Frontiers in Education Conference (FIE). IEEE, 1–8
2020
-
[16]
Geoff Cumming. 2014. The New Statistics Why and How.Psychological Science 25, 1 (Jan. 2014), 7–29. doi:10.1177/0956797613504966
-
[17]
Holger Danielsiek, Laura Toma, and Jan Vahrenhold. 2017. An Instrument to Assess Self-Efficacy in Introductory Algorithms Courses. InProceedings of the 2017 ACM Conference on International Computing Education Research(Tacoma, Washington, USA)(ICER ’17). Association for Computing Machinery, New York, NY, USA, 217–225. doi:10.1145/3105726.3106171
-
[18]
Paul Denny, Stephen MacNeil, Jaromir Savelka, Leo Porter, and Andrew Luxton- Reilly. 2024. Desirable Characteristics for AI Teaching Assistants in Programming Education. InProceedings of the 2024 on Innovation and Technology in Computer Science Education V. 1(Milan, Italy)(ITiCSE 2024). Association for Computing Machinery, New York, NY, USA, 408–414. doi:...
-
[19]
Becker, James Finnie-Ansley, Arto Hellas, Juho Leinonen, Andrew Luxton-Reilly, Brent N
Paul Denny, James Prather, Brett A. Becker, James Finnie-Ansley, Arto Hellas, Juho Leinonen, Andrew Luxton-Reilly, Brent N. Reeves, Eddie Antonio Santos, and Sami Sarsa. 2024. Computing Education in the Era of Generative AI.Commun. ACM67, 2 (Jan. 2024), 56–67. doi:10.1145/3624720
-
[20]
Fitsum Deriba, Ismaila Sanusi, Oladele Campbell, and Solomon Oyelere. 2024. Computer Programming Education in the Age of Generative AI: Insights from Empirical Research.SSRN Electronic Journal(01 2024). doi:10.2139/ssrn.4891302
-
[21]
Farghally, Kyu Han Koh, Hossameldin Shahin, and Clifford A
Mohammed F. Farghally, Kyu Han Koh, Hossameldin Shahin, and Clifford A. Shaffer. 2017. Evaluating the Effectiveness of Algorithm Analysis Visualizations. InProceedings of the 2017 ACM SIGCSE Technical Symposium on Computer Science Education(Seattle, Washington, USA)(SIGCSE ’17). Association for Computing Machinery, New York, NY, USA, 201–206. doi:10.1145/...
-
[22]
Razieh Fathi, James D Teresco, and Kenneth Regan. 2023. Measuring learners’ cognitive load when engaged with an algorithm visualization tool.Journal of Information Systems Applied Research16, 3 (2023)
2023
-
[23]
Becker, Andrew Luxton-Reilly, and James Prather
James Finnie-Ansley, Paul Denny, Brett A. Becker, Andrew Luxton-Reilly, and James Prather. 2022. The Robots Are Coming: Exploring the Implica- tions of OpenAI Codex on Introductory Programming. InProceedings of the 24th Australasian Computing Education Conference(Virtual Event, Australia) (ACE ’22). Association for Computing Machinery, New York, NY, USA, ...
-
[24]
James Finnie-Ansley, Paul Denny, Andrew Luxton-Reilly, Eddie Antonio Santos, James Prather, and Brett A. Becker. 2023. My AI Wants to Know if This Will Be on the Exam: Testing OpenAI’s Codex on CS2 Programming Exercises. In Proceedings of the 25th Australasian Computing Education Conference(Melbourne, VIC, Australia)(ACE ’23). Association for Computing Ma...
-
[25]
John H Flavell. 2024. Metacognitive aspects of problem solving. InThe nature of intelligence. Routledge, 231–236
2024
-
[26]
Ginés Gárcia-Mateos and José Luis Fernández-Alemán. 2009. A course on al- gorithms and data structures using on-line judging. InProceedings of the 14th annual ACM SIGCSE conference on innovation and technology in computer science education. 45–49
2009
-
[27]
Philip J Guo. 2013. Online python tutor: embeddable web-based program visual- ization for cs education. InProceeding of the 44th ACM technical symposium on Computer science education. 579–584
2013
-
[28]
Shishir Halaharvi, Gonzalo Gabriel Méndez, Hamid Mansoor, Quinton Yong, Alessandra Maciel Paz Milani, Margaret-Anne Storey, and Miguel A Nacenta. 2024. P-Inti: Interactive visual representation of programming concepts for learning and instruction. In2024 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC). IEEE, 199–210
2024
-
[29]
Steven Halim. 2015. Visualgo–visualising data structures and algorithms through animation.Olympiads in informatics9 (2015), 243–245
2015
-
[30]
Arto Hellas, Juho Leinonen, Sami Sarsa, Charles Koutcheme, Lilja Kujanpää, and Juha Sorva. 2023. Exploring the Responses of Large Language Models to Beginner Programmers’ Help Requests. InProceedings of the 2023 ACM Conference on International Computing Education Research - Volume 1(Chicago, IL, USA) (ICER ’23). Association for Computing Machinery, New Yo...
-
[31]
Sara Hooshangi, Margaret Ellis, and Stephen H. Edwards. 2022. Factors Influenc- ing Student Performance and Persistence in CS2. InProceedings of the 53rd ACM Technical Symposium on Computer Science Education - Volume 1(Providence, RI, USA)(SIGCSE 2022). Association for Computing Machinery, New York, NY, USA, 286–292. doi:10.1145/3478431.3499272
-
[32]
Diane Horton and Michelle Craig. 2015. Drop, Fail, Pass, Continue: Persistence in CS1 and Beyond in Traditional and Inverted Delivery. InProceedings of the 46th ACM Technical Symposium on Computer Science Education(Kansas City, Missouri, USA)(SIGCSE ’15). Association for Computing Machinery, New York, NY, USA, 235–240. doi:10.1145/2676723.2677273
-
[33]
Weidong Huang, Peter Eades, and Seok-Hee Hong. 2009. Measuring effectiveness of graph visualizations: A cognitive load perspective.Information Visualization 8, 3 (2009), 139–152
2009
-
[34]
Christopher D Hundhausen, Sarah A Douglas, and John T Stasko. 2002. A meta- study of algorithm visualization effectiveness.Journal of Visual Languages & Computing13, 3 (2002), 259–290
2002
-
[35]
Essi Isohanni and Hannu-Matti Järvinen. 2014. Are visualization tools used in programming education? by whom, how, why, and why not?. InProceedings of the 14th Koli Calling International Conference on Computing Education Research (Koli, Finland)(Koli Calling ’14). Association for Computing Machinery, New York, NY, USA, 35–40. doi:10.1145/2674683.2674688
-
[36]
Gregor Jošt, Viktor Taneski, and Sašo Karakatič. 2024. The Impact of Large Language Models on Programming Education and Student Learning Outcomes. Applied Sciences14 (05 2024), 4115. doi:10.3390/app14104115
-
[37]
Majeed Kazemitabaar, Xinying Hou, Austin Henley, Barbara Jane Ericson, David Weintrop, and Tovi Grossman. 2024. How Novices Use LLM-based Code Gen- erators to Solve CS1 Coding Tasks in a Self-Paced Learning Environment. In Proceedings of the 23rd Koli Calling International Conference on Computing Ed- ucation Research(Koli, Finland)(Koli Calling ’23). Asso...
-
[39]
Norbert L Kerr. 1998. HARKing: Hypothesizing after the results are known. Personality and social psychology review2, 3 (1998), 196–217
1998
-
[40]
Päivi Kinnunen and Beth Simon. 2011. CS majors’ self-efficacy perceptions in CS1: results in light of social cognitive theory. InProceedings of the Seventh International Workshop on Computing Education Research(Providence, Rhode Island, USA)(ICER ’11). Association for Computing Machinery, New York, NY, USA, 19–26. doi:10.1145/2016911.2016917
-
[41]
Rex B. Kline. 2013.Beyond significance testing: Statistics reform in the behavioral sciences, 2nd ed. American Psychological Association, Washington, DC, US. doi:10.1037/14136-000 Pages: xi, 349
-
[42]
Maria Knobelsdorf, Essi Isohanni, and Josh Tenenberg. 2012. The reasons might be different: why students and teachers do not use visualization tools. InProceedings of the 12th Koli Calling International Conference on Computing Education Research (Koli, Finland)(Koli Calling ’12). Association for Computing Machinery, New York, NY, USA, 1–10. doi:10.1145/24...
-
[43]
Ekaterina Kochmar, Dung Do Vu, Robert Belfer, Varun Gupta, Iulian Vlad Serban, and Joelle Pineau. 2020. Automated personalized feedback improves learning gains in an intelligent tutoring system. InInternational conference on artificial intelligence in education. Springer, 140–146
2020
-
[44]
David R Krathwohl. 2002. A revision of Bloom’s taxonomy: An overview.Theory into practice41, 4 (2002), 212–218
2002
-
[45]
John Kruschke. 2014. Doing Bayesian data analysis: A tutorial with R, JAGS, and Stan. (2014)
2014
-
[46]
John K. Kruschke. 2021. Bayesian Analysis Reporting Guidelines.Nature Human Behaviour5, 10 (Oct. 2021), 1282–1291. doi:10.1038/s41562-021-01177-7 Number: 10
-
[47]
Sam Lau and Philip Guo. 2023. From "Ban It Till We Understand It" to "Re- sistance is Futile": How University Programming Instructors Plan to Adapt as More Students Use AI Code Generation and Explanation Tools such as Chat- GPT and GitHub Copilot. InProceedings of the 2023 ACM Conference on Inter- national Computing Education Research - Volume 1(Chicago, ...
-
[48]
Lucas Layman, Yang Song, and Curry Guinn. 2020. Toward Predicting Success and Failure in CS2: A Mixed-Method Analysis. InProceedings of the 2020 ACM Southeast Conference(Tampa, FL, USA)(ACMSE ’20). Association for Computing Machinery, New York, NY, USA, 218–225. doi:10.1145/3374135.3385277
-
[49]
Vassilios Lazaridis, Nikolaos Samaras, and Angelo Sifaleras. 2013. An empir- ical study on factors influencing the effectiveness of algorithm visualization. Computer Applications in Engineering Education21, 3 (2013), 410–420
2013
-
[50]
Juho Leinonen, Paul Denny, Stephen MacNeil, Sami Sarsa, Seth Bernstein, Joanne Kim, Andrew Tran, and Arto Hellas. 2023. Comparing Code Explanations Created by Students and Large Language Models. InProceedings of the 2023 Conference on Innovation and Technology in Computer Science Education V. 1(Turku, Fin- land)(ITiCSE 2023). Association for Computing Mac...
-
[51]
Mark Liffiton, Brad E Sheese, Jaromir Savelka, and Paul Denny. 2024. Code- Help: Using Large Language Models with Guardrails for Scalable Support in Programming Classes. InProceedings of the 23rd Koli Calling International Con- ference on Computing Education Research(Koli, Finland)(Koli Calling ’23). As- sociation for Computing Machinery, New York, NY, US...
-
[52]
Alex Lishinski and Aman Yadav. 2021. Self-evaluation Interventions: Impact on Self-efficacy and Performance in Introductory Programming.ACM Trans. Comput. Educ.21, 3, Article 23 (June 2021), 28 pages. doi:10.1145/3447378
-
[53]
Rongxin Liu, Carter Zenke, Charlie Liu, Andrew Holmes, Patrick Thornton, and David J. Malan. 2024. Teaching CS50 with AI: Leveraging Generative Ar- tificial Intelligence in Computer Science Education. InProceedings of the 55th ACM Technical Symposium on Computer Science Education V. 1(Portland, OR, USA)(SIGCSE 2024). Association for Computing Machinery, N...
-
[54]
Rongxin Liu, Julianna Zhao, Benjamin Xu, Christopher Perez, Yuliia Zhukovets, and David J. Malan. 2025. Improving AI in CS50: Leveraging Human Feedback for Better Learning. InProceedings of the 56th ACM Technical Symposium on Computer Science Education V. 1(Pittsburgh, PA, USA)(SIGCSETS 2025). Association for Com- puting Machinery, New York, NY, USA, 715–...
-
[55]
Ko, Will Jernigan, Alannah Oleson, Christopher J
Dastyni Loksa, Amy J. Ko, Will Jernigan, Alannah Oleson, Christopher J. Mendez, and Margaret M. Burnett. 2016. Programming, Problem Solving, and Self- Awareness: Effects of Explicit Guidance. InProceedings of the 2016 CHI Con- ference on Human Factors in Computing Systems(San Jose, California, USA)(CHI ’16). Association for Computing Machinery, New York, ...
-
[56]
Malan, Brian Yu, and Doug Lloyd
David J. Malan, Brian Yu, and Doug Lloyd. 2020. Teaching Academic Honesty in CS50. InProceedings of the 51st ACM Technical Symposium on Computer Sci- ence Education(Portland, OR, USA)(SIGCSE ’20). Association for Computing Machinery, New York, NY, USA, 282–288. doi:10.1145/3328778.3366940
-
[57]
Margulieux, James Prather, Brent N
Lauren E. Margulieux, James Prather, Brent N. Reeves, Brett A. Becker, Gozde Cetin Uzun, Dastyni Loksa, Juho Leinonen, and Paul Denny. 2024. Self- Regulation, Self-Efficacy, and Fear of Failure Interactions with How Novices Use LLMs to Solve Programming Problems. InProceedings of the 2024 on Inno- vation and Technology in Computer Science Education V. 1(M...
-
[58]
Ismael Villegas Molina, Audria Montalvo, Benjamin Ochoa, Paul Denny, and Leo Porter. 2025. Leveraging LLM Tutoring Systems for Non-Native English Speakers in Introductory CS Courses. arXiv:2411.02725 [cs.HC] https://arxiv.org/abs/2411. 02725
arXiv 2025
-
[59]
Andrés Moreno, Niko Myller, Erkki Sutinen, and Mordechai Ben-Ari. 2004. Vi- sualizing programs with Jeliot 3. InProceedings of the working conference on Advanced visual interfaces. 373–376
2004
-
[60]
Adam Basigie Mtaho and Leonard James Mselle. 2024. Difficulties in learning the data structures course: Literature review.The Journal of Informatics4, 1 (2024), 26–55
2024
-
[61]
Thomas L Naps. 2005. Jhavé: Supporting algorithm visualization.IEEE Computer Graphics and Applications25, 5 (2005), 49–55
2005
-
[62]
Thomas L. Naps, Guido Rößling, Vicki Almstrum, Wanda Dann, Rudolf Fleischer, Chris Hundhausen, Ari Korhonen, Lauri Malmi, Myles McNally, Susan Rodger, and J. Ángel Velázquez-Iturbide. 2002. Exploring the role of visualization and engagement in computer science education. InWorking Group Reports from ITiCSE on Innovation and Technology in Computer Science ...
-
[63]
Sydney Nguyen, Hannah McLean Babe, Yangtian Zi, Arjun Guha, Carolyn Jane Anderson, and Molly Q Feldman. 2024. How Beginning Programmers and Code LLMs (Mis)read Each Other. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 651, 26 pages...
arXiv 2024
-
[64]
Ángel Velázquez-Iturbide, and Julio Guillén-García
Daniel Palacios-Alonso, Jaime Urquiza-Fuentes, J. Ángel Velázquez-Iturbide, and Julio Guillén-García. 2024. Experiences and Proposals of Use of Generative AI in Advanced Software Courses. In2024 IEEE Global Engineering Education Conference (EDUCON). 1–10. doi:10.1109/EDUCON60312.2024.10578869
-
[65]
Marian Petre. 1995. Why looking isn’t always seeing: readership skills and graphical programming.Commun. ACM38, 6 (June 1995), 33–44. doi:10.1145/ 203241.203251
arXiv 1995
-
[66]
Paul R Pintrich et al. 1991. A manual for the use of the Motivated Strategies for Learning Questionnaire (MSLQ). (1991)
1991
-
[67]
Martyn Plummer et al. 2003. JAGS: A program for analysis of Bayesian graphical models using Gibbs sampling. InProceedings of the 3rd international workshop on distributed statistical computing, Vol. 124. Vienna, Austria, 1–10
2003
-
[68]
Becker, Michelle Craig, Paul Denny, Dastyni Loksa, and Lauren Margulieux
James Prather, Brett A. Becker, Michelle Craig, Paul Denny, Dastyni Loksa, and Lauren Margulieux. 2020. What Do We Think We Think We Are Doing? Metacog- nition and Self-Regulation in Programming. InProceedings of the 2020 ACM Conference on International Computing Education Research(Virtual Event, New Zealand)(ICER ’20). Association for Computing Machinery...
-
[69]
Becker, Ibrahim Albluwi, et al
James Prather, Paul Denny, Juho Leinonen, Brett A. Becker, Ibrahim Albluwi, Michelle Craig, Hieke Keuning, Natalie Kiesler, Tobias Kohn, Andrew Luxton- Reilly, Stephen MacNeil, Andrew Petersen, Raymond Pettit, Brent N. Reeves, and Jaromir Savelka. 2023. The Robots Are Here: Navigating the Generative AI Revolution in Computing Education. InProceedings of t...
-
[70]
James Prather, Raymond Pettit, Kayla McMurry, Alani Peters, John Homer, and Maxine Cohen. 2018. Metacognitive Difficulties Faced by Novice Pro- grammers in Automated Assessment Tools. InProceedings of the 2018 ACM Conference on International Computing Education Research(Espoo, Finland) (ICER ’18). Association for Computing Machinery, New York, NY, USA, 41...
-
[71]
It’s Weird That it Knows What I Want
James Prather, Brent N. Reeves, Paul Denny, Brett A. Becker, Juho Leinonen, Andrew Luxton-Reilly, Garrett Powell, James Finnie-Ansley, and Eddie Antonio Santos. 2023. “It’s Weird That it Knows What I Want”: Usability and Interactions with Copilot for Novice Programmers.ACM Trans. Comput.-Hum. Interact.31, 1, Article 4 (Nov. 2023), 31 pages. doi:10.1145/3617367
-
[72]
Becker, Bailey Kimmel, Jared Wright, and Ben Briggs
James Prather, Brent N Reeves, Juho Leinonen, Stephen MacNeil, Arisoa S Randri- anasolo, Brett A. Becker, Bailey Kimmel, Jared Wright, and Ben Briggs. 2024. The Widening Gap: The Benefits and Harms of Generative AI for Novice Programmers. InProceedings of the 2024 ACM Conference on International Computing Education Research - Volume 1(Melbourne, VIC, Aust...
-
[73]
2025.R: A Language and Environment for Statistical Computing
R Core Team. 2025.R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project. Characterization and Effects of CS2 Learning with GenAI, Visualization, and Human Support ICER 2026 Vol. 1, August 11–14, 2026, Uppsala, Sweden org/
2025
-
[74]
Md Mostafizer Rahman and Yutaka Watanobe. 2023. ChatGPT for education and research: Opportunities, threats, and strategies.Applied sciences13, 9 (2023), 5783
2023
-
[75]
Teemu Rajala, Mikko-Jussi Laakso, Erkki Kaila, and Tapio Salakoski. 2007. VILLE: a language-independent program visualization tool. InProceedings of the Seventh Baltic Sea Conference on Computing Education Research-Volume 88. 151–159
2007
-
[76]
Vennila Ramalingam and Susan Wiedenbeck. 1998. Development and validation of scores on a computer programming self-efficacy scale and group analyses of novice programmer self-efficacy.Journal of Educational Computing Research19, 4 (1998), 367–381
1998
-
[77]
Sami Sarsa, Paul Denny, Arto Hellas, and Juho Leinonen. 2022. Automatic Generation of Programming Exercises and Code Explanations Using Large Lan- guage Models. InProceedings of the 2022 ACM Conference on International Com- puting Education Research - Volume 1(Lugano and Virtual Event, Switzerland) (ICER ’22). Association for Computing Machinery, New York...
-
[78]
Jaromir Savelka, Arav Agarwal, Marshall An, Chris Bogart, and Majd Sakr. 2023. Thrilled by Your Progress! Large Language Models (GPT-4) No Longer Struggle to Pass Assessments in Higher Education Programming Courses. InProceedings of the 2023 ACM Conference on International Computing Education Research - Volume 1(Chicago, IL, USA)(ICER ’23). Association fo...
-
[79]
Alexander Scarlatos, Naiming Liu, Jaewook Lee, Richard Baraniuk, and Andrew Lan. 2025. Training LLM-Based Tutors to Improve Student Learning Outcomes in Dialogues. InArtificial Intelligence in Education: 26th International Conference, AIED 2025, Palermo, Italy, July 22–26, 2025, Proceedings, Part I(Palermo, Italy). Springer-Verlag, Berlin, Heidelberg, 251...
-
[80]
Clifford A. Shaffer, Matthew L. Cooper, Alexander Joel D. Alon, Monika Akbar, Michael Stewart, Sean Ponce, and Stephen H. Edwards. 2010. Algorithm Visual- ization: The State of the Field.ACM Trans. Comput. Educ.10, 3, Article 9 (Aug. 2010), 22 pages. doi:10.1145/1821996.1821997
-
[81]
Clifford A Shaffer, Ville Karavirta, Ari Korhonen, and Thomas L Naps. 2011. OpenDSA: beginning a community active-ebook project. InProceedings of the 11th Koli Calling International Conference on computing education research. 112– 117
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.