ZK-Flex: A Flexible and Scalable Framework for Accelerating Zero-Knowledge Proofs
Pith reviewed 2026-06-28 08:26 UTC · model grok-4.3
The pith
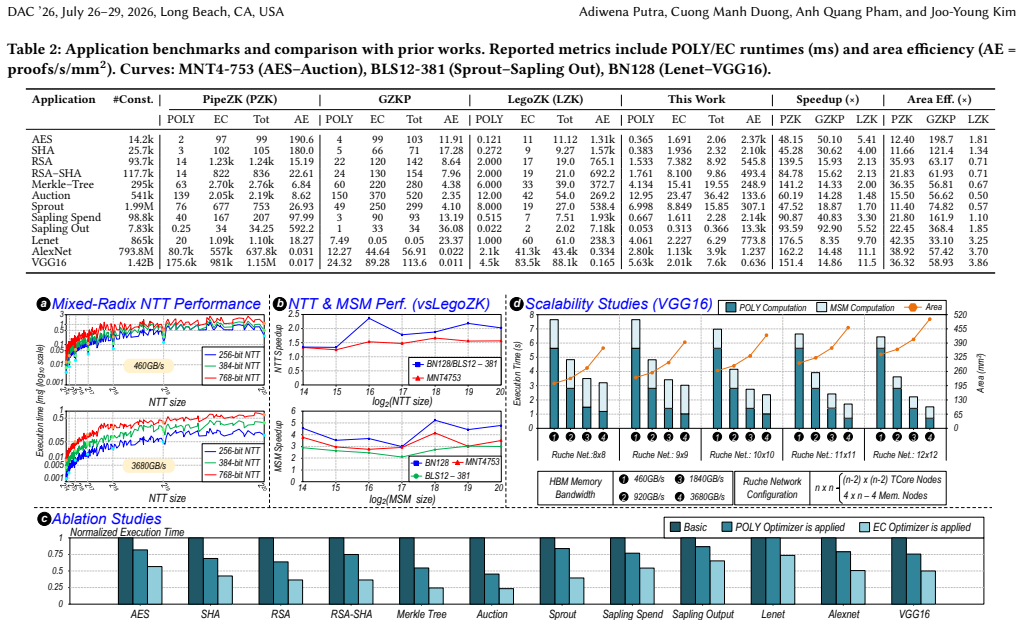
ZK-Flex accelerates ZKP generation 5 to 11 times with up to 3.8 times better area efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that a software-hardware co-designed framework called ZK-Flex, incorporating POLY and EC optimizers along with TCore—a Toom-Cook-based multi-precision core equipped with a flexible NoC and linked-list memory mechanism—can achieve 5 to 11 times speedup and up to 3.8 times higher area efficiency over the state of the art in representative ZKP benchmarks.
What carries the argument
TCore, the Toom-Cook-based multi-precision core with flexible NoC and linked-list memory mechanism, which supports diverse large-precision modular multiplications and maintains high utilization across shifting POLY and EC workloads.
If this is right
- Reconfigurable accelerators can maintain high utilization as ZKP workloads shift between POLY and EC stages.
- Software algorithmic choices tailored to hardware features can reduce overall computation in proof generation.
- Limited memory capacity no longer constrains parallelism when using linked-list mechanisms in multi-precision cores.
- Area efficiency gains make larger-scale ZKP deployments more feasible in resource-constrained settings.
Where Pith is reading between the lines
- The flexible NoC and linked-list approach could extend to accelerators for other cryptographic workloads with variable precision needs.
- Combining such hardware with emerging ZKP variants might require new optimizer layers but could preserve the reported efficiency ratios.
- The reported speedups suggest potential for real-time ZKP use in systems where current accelerators fall short on throughput.
Load-bearing premise
That the TCore with Toom-Cook multiplication, flexible NoC, and linked-list memory mechanism can be implemented in hardware while maintaining high utilization across dynamically shifting POLY and EC workloads without significant unforeseen overheads or bottlenecks.
What would settle it
A hardware implementation or cycle-accurate simulation of ZK-Flex on the representative ZKP benchmarks that measures less than 5 times speedup or lower than 3.8 times area efficiency over the state of the art would falsify the claims.
Figures

read the original abstract
Zero-knowledge proofs (ZKP) allows a prover to convince a verifier of computational correctness without revealing private data, ensuring both privacy and verifiability. However, proof generation is highly compute-intensive, dominated by polynomial (POLY) and elliptic-curve (EC) operations. These workloads pose two key challenges for hardware acceleration: (1) efficiently supporting diverse large-precision modular multiplications, and (2) maintaining high utilization across workloads that dynamically shift between POLY and EC stages. Existing reconfigurable accelerators address these issues only partially, remaining limited in precision scalability, algorithmic flexibility, and resource efficiency. To overcome these limitations, we propose ZK-Flex, a flexible and scalable software-hardware co-designed framework for accelerating ZKP proof generation. The software layer incorporates POLY and EC optimizers that reduce computation through hardware- and workload-aware algorithmic choices, while the hardware integrates TCore, a Toom-Cook-based multi-precision core with a flexible NoC and a linked-list memory mechanism that improves parallelism under limited memory capacity. Across representative ZKP benchmarks, ZK-Flex achieves 5 to 11 times speedup and up to 3.8 times higher area efficiency over the state of the art, establishing a new foundation for high-performance, reconfigurable ZKP acceleration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ZK-Flex, a software-hardware co-designed framework for accelerating zero-knowledge proof generation. The software layer includes POLY and EC optimizers that make hardware- and workload-aware algorithmic choices. The hardware integrates TCore, a Toom-Cook-based multi-precision core, together with a flexible NoC and linked-list memory mechanism intended to improve parallelism under limited memory capacity. The central claim is that, across representative ZKP benchmarks, ZK-Flex delivers 5–11× speedup and up to 3.8× higher area efficiency relative to prior accelerators.
Significance. If the performance and efficiency numbers are substantiated by detailed, reproducible benchmarks, the work would address two recognized bottlenecks in ZKP hardware acceleration—support for diverse large-precision modular multiplications and sustained utilization across dynamically shifting POLY/EC workloads—thereby providing a concrete foundation for reconfigurable accelerators in this domain.
major comments (1)
- Abstract: the central performance claims (5–11× speedup and up to 3.8× area efficiency) are stated without any accompanying benchmark data, methodology description, error bars, workload definitions, or implementation results, rendering the primary result impossible to assess from the manuscript as presented.
minor comments (1)
- Abstract: the phrase 'representative ZKP benchmarks' is used without enumerating the specific workloads or providing a reference to a table or section that lists them.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address the single major comment below and are prepared to revise the abstract accordingly to improve immediate assessability of the results.
read point-by-point responses
-
Referee: Abstract: the central performance claims (5–11× speedup and up to 3.8× area efficiency) are stated without any accompanying benchmark data, methodology description, error bars, workload definitions, or implementation results, rendering the primary result impossible to assess from the manuscript as presented.
Authors: We acknowledge that the abstract, constrained by length, states the headline performance numbers without methodology, workload definitions, or supporting data. The full manuscript contains these details in Section 5 (Evaluation), which defines the representative ZKP workloads (including specific POLY- and EC-dominated phases from protocols such as Groth16 and Plonk), describes the FPGA/ASIC implementation and baselines, reports the measured speedups and area efficiencies, and includes error bars from repeated runs. To address the concern, we will revise the abstract to briefly reference the evaluation methodology and workload characteristics while preserving conciseness. revision: yes
Circularity Check
No significant circularity; design claims rest on empirical benchmarks
full rationale
This is an architecture paper proposing a new hardware-software co-design (TCore with Toom-Cook, flexible NoC, linked-list memory) and reporting measured speedups/area gains on ZKP benchmarks. No mathematical derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the abstract or described content. The central claims are externally falsifiable via hardware implementation and workload measurements rather than reducing to inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
TCore
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Eli Ben Sasson, Alessandro Chiesa, Christina Garman, Matthew Green, Ian Miers, Eran Tromer, and Madars Virza. 2014. Zerocash: Decentralized Anonymous Payments from Bitcoin. In2014 IEEE Symposium on Security and Privacy. 459–474. doi:10.1109/SP.2014.36
-
[2]
Daniel Bernstein and Tanja Lange. [n. d.]. Elliptic Curve Formula Database (EFD). https://www.hyperelliptic.org/EFD/. Accessed: 2025-11-17
2025
-
[3]
Bernstein and Tanja Lange
Daniel J. Bernstein and Tanja Lange. 2007. Faster Addition and Doubling on Elliptic Curves. InAdvances in Cryptology – ASIACRYPT 2007, Kaoru Kurosawa (Ed.). Springer Berlin Heidelberg, Berlin, Heidelberg, 29–50
2007
-
[4]
Gautam Botrel, Thomas Piellard, Youssef El Housni, Ivo Kubjas, and Arya Tabaie. 2025.Consensys/gnark: v0.14.0. doi:10.5281/zenodo.5819104
-
[5]
Sean Bowe. 2017. BLS12-381: New zk-SNARK Elliptic Curve Construction. Blog post,Electric Coin CompanyBlog. https://electriccoin.co/blog/new-snark-curve/ Accessed: 2025-11-06
2017
-
[6]
Alhad Daftardar, Brandon Reagen, and Siddharth Garg. 2024. Szkp: A scalable accelerator architecture for zero-knowledge proofs. InProceedings of the 2024 International Conference on Parallel Architectures and Compilation Techniques. 271–283
2024
- [7]
-
[8]
S Goldwasser, S Micali, and C Rackoff. 1985. The knowledge complexity of interac- tive proof-systems. InProceedings of the Seventeenth Annual ACM Symposium on Theory of Computing(Providence, Rhode Island, USA)(STOC ’85). Association for Computing Machinery, New York, NY, USA, 291–304. doi:10.1145/22145.22178
-
[9]
Jens Groth. 2016. On the Size of Pairing-Based Non-interactive Arguments. In Proceedings, Part II, of the 35th Annual International Conference on Advances in Cryptology — EUROCRYPT 2016 - Volume 9666. Springer-Verlag, Berlin, Heidelberg, 305–326
2016
-
[10]
Zhen Gu and Shuguo Li. 2019. A Division-Free Toom–Cook Multiplication-Based Montgomery Modular Multiplication.IEEE Transactions on Circuits and Systems II: Express Briefs66, 8 (2019), 1401–1405. doi:10.1109/TCSII.2018.2886962
-
[11]
Youssef El Housni and Gautam Botrel. 2022. EdMSM: Multi-Scalar-Multiplication for SNARKs and Faster Montgomery multiplication. Cryptology ePrint Archive, Paper 2022/1400. https://eprint.iacr.org/2022/1400
2022
-
[12]
iden3. 2025. circom: zkSnark circuit compiler. GitHub repository. https://github. com/iden3/circom Accessed: 2025-11-06
2025
-
[13]
Dai Cheol Jung, Scott Davidson, Chun Zhao, Dustin Richmond, and Michael Bed- ford Taylor. 2020. Ruche Networks: Wire-Maximal, No-Fuss NoCs : Special Session Paper. In2020 14th IEEE/ACM International Symposium on Networks-on- Chip (NOCS). 1–8. doi:10.1109/NOCS50636.2020.9241586
-
[14]
Anatolii Karatsuba. 1963. Multiplication of multidigit numbers on automata. In Soviet physics doklady, Vol. 7. 595–596
1963
-
[15]
Jongmin Kim, Sangpyo Kim, Jaewan Choi, Jaiyoung Park, Donghwan Kim, and Jung Ho Ahn. 2023. SHARP: A short-word hierarchical accelerator for robust and practical fully homomorphic encryption. InProceedings of the 50th Annual International Symposium on Computer Architecture. 1–15
2023
-
[16]
Yoongu Kim, Weikun Yang, and Onur Mutlu. 2016. Ramulator: A Fast and Extensible DRAM Simulator.IEEE Computer Architecture Letters15, 1 (2016), 45–49. doi:10.1109/LCA.2015.2414456
-
[17]
Changxu Liu, Hao Zhou, Patrick Dai, Li Shang, and Fan Yang. 2024. PriorMSM: An Efficient Acceleration Architecture for Multi-Scalar Multiplication.ACM Trans. Des. Autom. Electron. Syst.29, 5, Article 77 (Aug. 2024), 26 pages. doi:10. 1145/3678006
2024
-
[18]
Weiliang Ma, Qian Xiong, Xuanhua Shi, Xiaosong Ma, Hai Jin, Haozhao Kuang, Mingyu Gao, Ye Zhang, Haichen Shen, and Weifang Hu. 2023. GZKP: A GPU Accelerated Zero-Knowledge Proof System. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Lan- guages and Operating Systems, Volume 2(Vancouver, BC, Canada)(ASPLOS 2...
-
[19]
Nicholas Pippenger. 1976. On the evaluation of powers and related problems. In17th Annual Symposium on Foundations of Computer Science (sfcs 1976). IEEE Computer Society, 258–263
1976
-
[20]
Prasetiyo, Adiwena Putra, Joo-Young Kim, et al. 2024. Morphling: A Throughput- Maximized TFHE-based Accelerator using Transform-domain Reuse. In2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 249–262
2024
-
[21]
Adiwena Putra, Prasetiyo, Yi Chen, John Kim, and Joo-Young Kim. 2023. Strix: An end-to-end streaming architecture with two-level ciphertext batching for fully homomorphic encryption with programmable bootstrapping. InProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture. 1319–1331
2023
-
[22]
Andy Ray, Benjamin Devlin, Fu Yong Quah, and Rahul Yesantharao. 2024. Hard- caml MSM: A High-Performance Split CPU-FPGA Multi-Scalar Multiplication Engine. InProceedings of the 2024 ACM/SIGDA International Symposium on Field Programmable Gate Arrays(Monterey, CA, USA)(FPGA ’24). Association for Computing Machinery, New York, NY, USA, 33–39. doi:10.1145/36...
-
[23]
Louis Tremblay Thibault, Tom Sarry, and Abdelhakim Senhaji Hafid. 2022. Blockchain Scaling Using Rollups: A Comprehensive Survey.IEEE Access10 (2022), 93039–93054. doi:10.1109/ACCESS.2022.3200051
-
[24]
Andrei L Toom. 1963. The complexity of a scheme of functional elements realizing the multiplication of integers, published in Soviet Math (translations of Dokl. Adad. Nauk. SSSR), 4
1963
-
[25]
Charles. F. Xavier. 2022. PipeMSM: Hardware Acceleration for Multi-Scalar Multiplication. Cryptology ePrint Archive, Paper 2022/999. https://eprint.iacr. org/2022/999
2022
-
[26]
Zhengbang Yang, Lutan Zhao, Peinan Li, Han Liu, Kai Li, Boyan Zhao, Dan Meng, and Rui Hou. 2025. LegoZK: A Dynamically Reconfigurable Accelerator for Zero- Knowledge Proof. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 113–126
2025
-
[27]
Sungwoong Yune, Hyojeong Lee, Adiwena Putra, Hyunjun Cho, Cuong Duong Manh, Jaeho Jeon, and Joo-Young Kim. 2025. ABC-FHE : A Resource-Efficient Accelerator Enabling Bootstrappable Parameters for Client-Side Fully Homomor- phic Encryption. arXiv:2506.08461 [cs.AR] https://arxiv.org/abs/2506.08461
-
[28]
Jiaheng Zhang, Zhiyong Fang, Yupeng Zhang, and Dawn Song. 2020. Zero Knowledge Proofs for Decision Tree Predictions and Accuracy. InProceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security (Virtual Event, USA)(CCS ’20). Association for Computing Machinery, New York, NY, USA, 2039–2053. doi:10.1145/3372297.3417278
-
[29]
Yupeng Zhang, Daniel Genkin, Jonathan Katz, Dimitrios Papadopoulos, and Charalampos Papamanthou. 2017. vSQL: Verifying Arbitrary SQL Queries over Dynamic Outsourced Databases. Cryptology ePrint Archive, Paper 2017/1145. doi:10.1109/SP.2017.43
-
[30]
Ye Zhang, Shuo Wang, Xian Zhang, Jiangbin Dong, Xingzhong Mao, Fan Long, Cong Wang, Dong Zhou, Mingyu Gao, and Guangyu Sun. 2021. Pipezk: Acceler- ating zero-knowledge proof with a pipelined architecture. In2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). IEEE, 416–428
2021
-
[31]
Hao Zhou, Changxu Liu, Lan Yang, Li Shang, and Fan Yang. 2024. ReZK: A Highly Reconfigurable Accelerator for Zero-Knowledge Proof.IEEE Transactions on Circuits and Systems I: Regular Papers(2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.