Benchmarking Speech-to-Speech Translation Models
Pith reviewed 2026-06-28 10:31 UTC · model grok-4.3
The pith
S2ST architectures differ by over 30% in naturalness and speaker preservation but only a few points in translation quality, so single-metric rankings misrepresent model performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
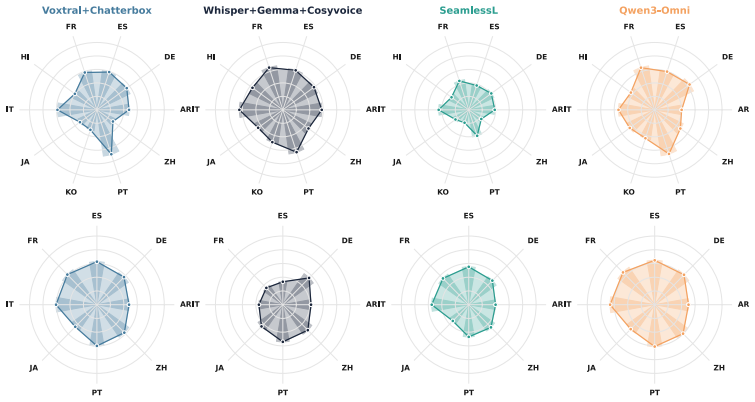
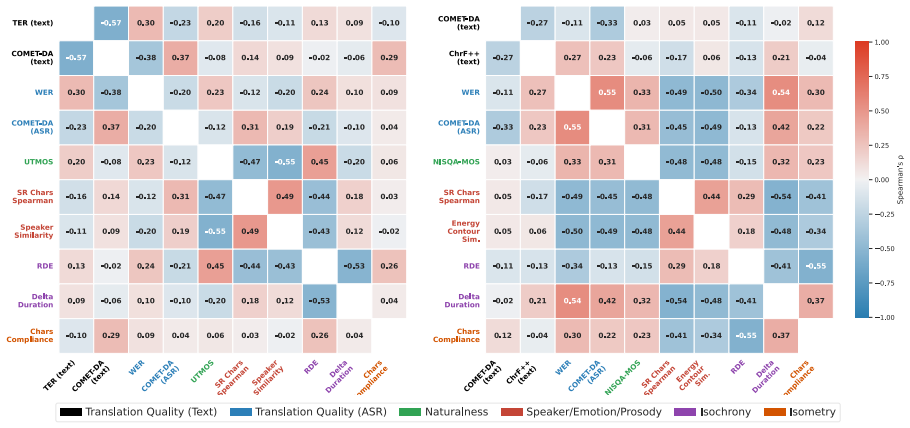
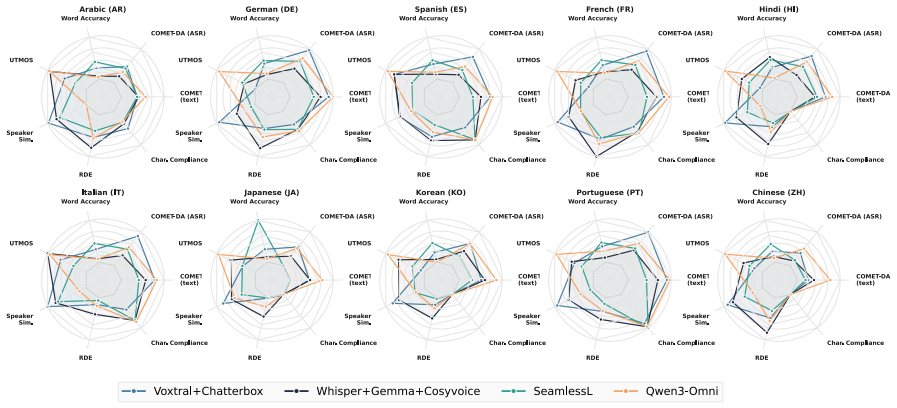
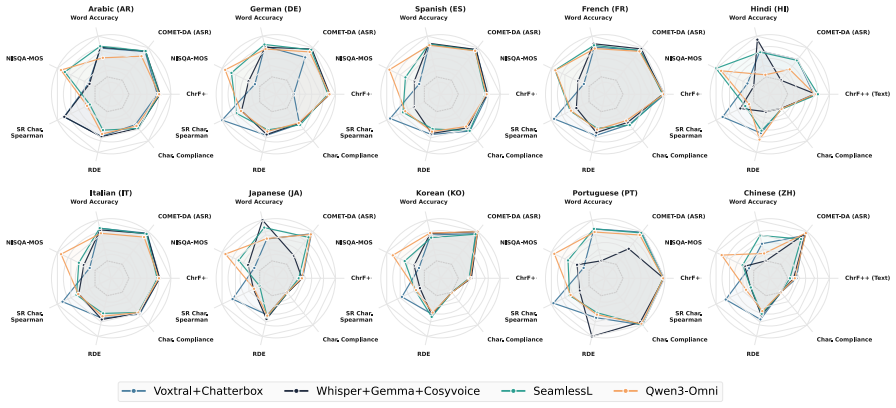
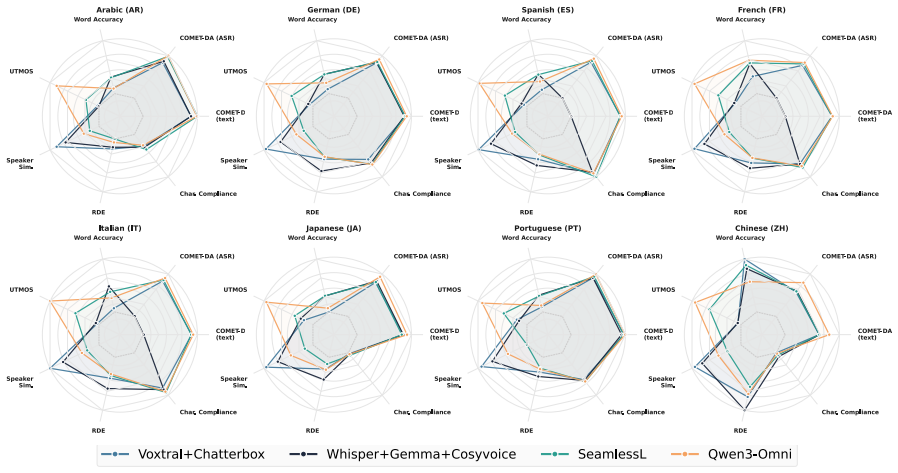
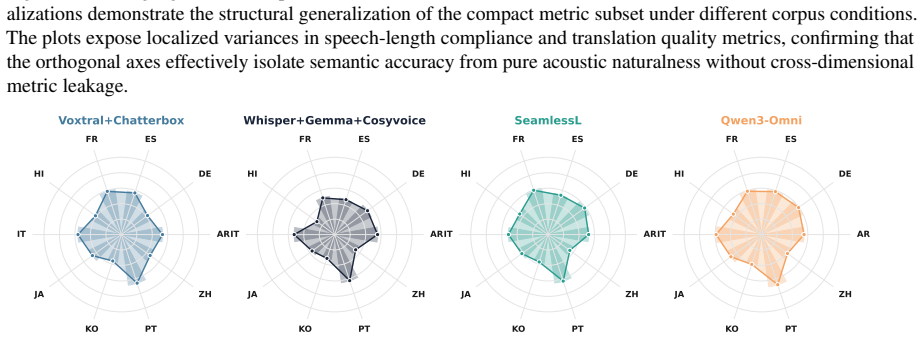
Applying the COMPASS suite to cascaded and end-to-end models shows complementary strengths: best-versus-worst gaps exceed 30 percent on naturalness and speaker preservation yet stay within a few points on translation quality. Correlation filtering yields ten metrics per direction that maintain Spearman's rank correlation above 0.80 with the full set and cut evaluation time by roughly 2.5 times. In human validation, standalone MOS predictors fail to predict preference, but the top domain-specific metrics reach correlation of at least 0.90 with listener judgments.
What carries the argument
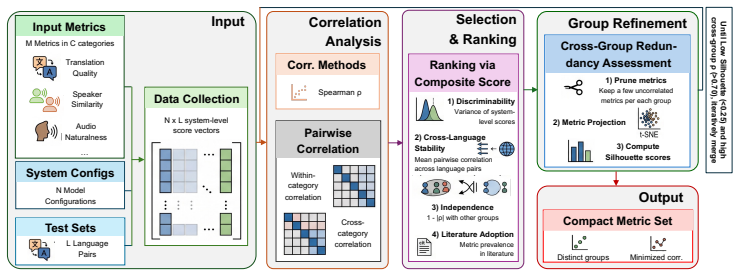
COMPASS, the unified benchmarking framework that integrates 46 metrics across eight dimensions and applies correlation filtering to produce compact direction-specific subsets.
If this is right
- Single-metric leaderboards will systematically misrepresent relative system quality across architectures.
- Translation direction determines which metrics are most informative, requiring separate subsets for X to English and English to X.
- Evaluation cost drops by a factor of about 2.5 while rank order is preserved when using the filtered metric sets.
- Domain-specific metrics, not generic MOS predictors, should be used for human-aligned assessment in dubbing, podcast, and medical settings.
Where Pith is reading between the lines
- Model development could shift toward reporting the reduced metric panel rather than any single score.
- The framework supplies a practical starting point for testing whether new domains require yet other metric combinations.
- Hybrid cascaded and end-to-end pipelines might combine the complementary strengths observed in the benchmark.
Load-bearing premise
The 46 chosen metrics and the correlation-filtering step are assumed to retain the essential quality distinctions without bias introduced by the particular datasets or model configurations tested.
What would settle it
A new collection of S2ST models evaluated with both the full 46-metric set and the reduced 10-metric subsets produces rankings that disagree on which systems are best, or human preference scores in a held-out domain diverge from the reported correlations.
Figures


read the original abstract
Speech-to-speech translation (S2ST) has advanced rapidly, but offline evaluation lacks a unified protocol: studies report non-overlapping metric subsets, preventing direct comparisons. We introduce COMPASS, a unified and reproducible benchmarking framework integrating 46 metrics across eight dimensions, and deploy it on 1,248 model-language configurations from FLEURS and CVSS, spanning cascaded and end-to-end architectures over ten language pairs. Architectures exhibit complementary strengths: best-vs-worst gaps exceed 30\% on naturalness and speaker preservation but remain within a few points on translation quality, so single-metric rankings systematically misrepresent system quality. Correlation filtering reduces 46 metrics to 10 per direction, with three axes requiring different metrics across X$\to$EN and EN$\to$X (e.g., TER/UTMOS vs. ChrF++/NISQA-MOS); these subsets preserve rankings (Spearman's $\rho>0.80$) while cutting evaluation time by $\approx 2.5\times$. Human validation across dubbing, podcasts, and medical domains shows standalone MOS predictors fail to predict listener preference, while top domain-specific metrics correlate with human judgment ($\rho \geq 0.90$). We release COMPASS as a foundation for domain-aware S2ST evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces COMPASS, a unified benchmarking framework integrating 46 metrics across eight dimensions for speech-to-speech translation (S2ST). It evaluates 1,248 model-language configurations from FLEURS and CVSS spanning cascaded and end-to-end architectures over ten language pairs. Key claims are that architectures show complementary strengths (best-vs-worst gaps >30% on naturalness/speaker preservation but small on translation quality, so single-metric rankings misrepresent quality), that correlation filtering reduces metrics to 10 per direction (with direction-specific choices like TER/UTMOS vs. ChrF++/NISQA-MOS) while preserving rankings (Spearman's ρ>0.80) and cutting evaluation time ~2.5×, and that human validation across domains shows standalone MOS predictors fail while top domain-specific metrics correlate with judgments (ρ≥0.90).
Significance. If the results hold, this establishes a reproducible, multi-metric protocol that directly addresses fragmentation in S2ST evaluation literature. The demonstration of architecture complementarity, the provision of reduced yet ranking-preserving metric subsets, and the domain-specific human validation could improve comparability, efficiency, and reliability of future S2ST assessments.
major comments (2)
- [correlation filtering procedure (abstract and methods)] The correlation filtering procedure that reduces 46 metrics to 10 per direction is applied to the same 1,248 configurations and FLEURS/CVSS datasets used for all architecture comparisons and ranking preservation checks. This in-sample selection risks producing dataset-specific subsets without held-out validation on new models, languages, or domains, directly weakening the claim that the reduced subsets preserve essential quality information (ρ>0.80) and support reliable domain-aware evaluation.
- [methods and abstract] No details are provided on the selection criteria for the initial 46 metrics across the eight dimensions, the exact correlation thresholds used for filtering, or the controls present in the 1,248 configurations. These omissions are load-bearing for the central claims on metric reduction and the superiority of the 10-metric subsets.
minor comments (1)
- [abstract] The abstract introduces X→EN and EN→X without prior definition of the language-pair conventions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that strengthen the manuscript without misrepresenting our results.
read point-by-point responses
-
Referee: [correlation filtering procedure (abstract and methods)] The correlation filtering procedure that reduces 46 metrics to 10 per direction is applied to the same 1,248 configurations and FLEURS/CVSS datasets used for all architecture comparisons and ranking preservation checks. This in-sample selection risks producing dataset-specific subsets without held-out validation on new models, languages, or domains, directly weakening the claim that the reduced subsets preserve essential quality information (ρ>0.80) and support reliable domain-aware evaluation.
Authors: We agree this is a valid methodological concern. The reduction was performed in-sample on the full set of 1,248 configurations without a separate held-out set of models or domains. While the configurations are diverse (spanning cascaded and end-to-end models, ten language pairs, and two source datasets), this does not fully substitute for out-of-sample validation. We will revise the manuscript to explicitly acknowledge this limitation in the Methods and Discussion sections and to recommend that users of the reduced subsets perform held-out checks when applying them to new data. revision: partial
-
Referee: [methods and abstract] No details are provided on the selection criteria for the initial 46 metrics across the eight dimensions, the exact correlation thresholds used for filtering, or the controls present in the 1,248 configurations. These omissions are load-bearing for the central claims on metric reduction and the superiority of the 10-metric subsets.
Authors: We agree that these details are necessary for reproducibility and for evaluating the claims. The current manuscript does not provide them. We will add a dedicated subsection (and appendix) that specifies: (i) the criteria used to compile the initial 46 metrics (standard coverage of the eight evaluation dimensions in the S2ST and related literature), (ii) the precise correlation thresholds and procedure (including the correlation measure and redundancy cutoff), and (iii) the configuration controls (model families, training regimes, and dataset handling). We will also include pseudocode for the filtering step. revision: yes
Circularity Check
No significant circularity: empirical benchmarking without derivations
full rationale
The paper is a purely empirical benchmarking study that applies 46 external metrics to 1248 model configurations and performs correlation-based filtering followed by rank-preservation checks. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-referential definitions appear in the work. The filtering procedure is a transparent data-driven reduction whose output is evaluated directly on the same corpus; this is standard empirical practice and does not reduce any claimed result to its inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked. The study is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The eight dimensions and 46 metrics together provide a comprehensive and non-redundant view of S2ST quality.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
1997 , organization=
Lavie, Alon and Waibel, Alex and Levin, Lori and Finke, Michael and Gates, Donna and Gavalda, Marsal and Zeppenfeld, Torsten and Zhan, Puming , booktitle=. 1997 , organization=
1997
-
[9]
Nakamura, Satoshi and Markov, Konstantin and Nakaiwa, Hiromi and Kikui, Gen-ichiro and Kawai, Hisashi and Jitsuhiro, Takatoshi and Zhang, J-S and Yamamoto, Hirofumi and Sumita, Eiichiro and Yamamoto, Seiichi , journal=. The. 2006 , publisher=
2006
-
[10]
Direct Speech-to-Speech Translation with a Sequence-to-Sequence Model , author=. Proc. Interspeech 2019 , pages=
2019
-
[11]
International conference on machine learning , pages=
Translatotron 2: High-quality direct speech-to-speech translation with voice preservation , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[12]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Translatotron 3: Speech to speech translation with monolingual data , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[13]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova
Seamlessm4t: Massively multilingual & multimodal machine translation , author=. arXiv preprint arXiv:2308.11596 , year=
-
[14]
Available: https://arxiv.org/abs/2312.05187
Seamless: Multilingual Expressive and Streaming Speech Translation , author=. arXiv preprint arXiv:2312.05187 , year=
-
[15]
2025 , journal=
Qwen2.5-Omni Technical Report , author=. 2025 , journal=
2025
-
[16]
Qwen3-omni technical report , author=. arXiv preprint arXiv:2509.17765 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
International conference on machine learning , pages=
Robust speech recognition via large-scale weak supervision , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[18]
No Language Left Behind: Scaling Human-Centered Machine Translation
No language left behind: Scaling human-centered machine translation , author=. arXiv preprint arXiv:2207.04672 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , volume=. 2025 , publisher=
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
2025 , howpublished =
2025
-
[21]
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training , author=. arXiv preprint arXiv:2505.17589 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[23]
A Study of Translation Edit Rate with Targeted Human Annotation
Snover, Matthew and Dorr, Bonnie and Schwartz, Rich and Micciulla, Linnea and Makhoul, John. A Study of Translation Edit Rate with Targeted Human Annotation. Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers. 2006
2006
-
[24]
Rei, Ricardo and Stewart, Craig and Farinha, Ana C and Lavie, Alon , booktitle=
-
[25]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Chen, Mingda and Duquenne, Paul-Ambroise and Andrews, Pierre and Kao, Justine and Mourachko, Alexandre and Schwenk, Holger and Costa-juss. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[26]
Saeki, Takaaki and Xin, Detai and Nakata, Wataru and Koriyama, Tomoki and Takamichi, Shinnosuke and Saruwatari, Hiroshi , booktitle=
-
[27]
Interspeech 2021 , year=
Mittag, Gabriel and Naderi, Babak and Chehadi, Assmaa and M. Interspeech 2021 , year=
2021
-
[28]
IEEE Journal of Selected Topics in Signal Processing , volume=
Wavlm: Large-scale self-supervised pre-training for full stack speech processing , author=. IEEE Journal of Selected Topics in Signal Processing , volume=. 2022 , publisher=
2022
-
[29]
Desplanques, Brecht and Thienpondt, Jenthe and Demuynck, Kris , booktitle=
-
[30]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
emotion2vec: Self-supervised pre-training for speech emotion representation , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[31]
Isometric
Lakew, Surafel M and Virkar, Yogesh and Mathur, Prashant and Federico, Marcello , booktitle=. Isometric. 2022 , organization=
2022
-
[32]
arXiv preprint arXiv:2302.12979 , year=
Jointly optimizing translations and speech timing to improve isochrony in automatic dubbing , author=. arXiv preprint arXiv:2302.12979 , year=
-
[33]
ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Duration modeling of neural tts for automatic dubbing , author=. ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2022 , organization=
2022
-
[34]
2022 IEEE Spoken Language Technology Workshop (SLT) , pages=
Fleurs: Few-shot learning evaluation of universal representations of speech , author=. 2022 IEEE Spoken Language Technology Workshop (SLT) , pages=. 2023 , organization=
2022
-
[35]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Unsupervised cross-lingual representation learning at scale , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[36]
Advances in neural information processing systems , volume=
wav2vec 2.0: A framework for self-supervised learning of speech representations , author=. Advances in neural information processing systems , volume=
-
[37]
IEEE Transactions on Information theory , volume=
Divergence measures based on the Shannon entropy , author=. IEEE Transactions on Information theory , volume=. 1991 , publisher=
1991
-
[38]
Communication methods and measures , volume=
Agreement and information in the reliability of coding , author=. Communication methods and measures , volume=. 2011 , publisher=
2011
-
[39]
Dingdong Wang, Jincenzi Wu, Junan Li, Dongchao Yang, Xueyuan Chen, Tianhua Zhang, and Helen Meng
Covost 2 and massively multilingual speech-to-text translation , author=. arXiv preprint arXiv:2007.10310 , year=
-
[40]
Jia, Ye and Ramanovich, Michelle Tadmor and Wang, Quan and Zen, Heiga , booktitle=
-
[41]
Europarl-
Iranzo-S. Europarl-. ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2020 , organization=
2020
-
[42]
2025 , organization=
Hu, Yuxuan and Wu, Haibin and Fan, Ruchao and Wang, Xiaofei and Lu, Heng and Qian, Yao and Li, Jinyu , booktitle=. 2025 , organization=
2025
-
[43]
Chen, Sirou and Yahata, Sakiko and Shimizu, Shuichiro and Yang, Zhengdong and Li, Yihang and Chu, Chenhui and Kurohashi, Sadao , booktitle=
-
[44]
Le-Duc, Khai and Tran, Tuyen and Tat, Bach Phan and Bui, Nguyen Kim Hai and Anh, Quan Dang and Tran, Hung-Phong and Nguyen, Thanh Thuy and Nguyen, Ly and Phan, Tuan Minh and Tran, Thi Thu Phuong and others , booktitle=
-
[45]
Simulstream: Open-Source Toolkit for Evaluation and Demonstration of Streaming Speech-to-Text Translation Systems , author=. arXiv preprint arXiv:2512.17648 , year=
-
[46]
2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , pages=
Assessing evaluation metrics for speech-to-speech translation , author=. 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , pages=. 2021 , organization=
2021
-
[47]
Transactions of the Association for Computational Linguistics , volume=
Experts, errors, and context: A large-scale study of human evaluation for machine translation , author=. Transactions of the Association for Computational Linguistics , volume=
-
[48]
Tangled up in
Mathur, Nitika and Baldwin, Timothy and Cohn, Trevor , booktitle=. Tangled up in
-
[49]
Proceedings of the 20th International Conference on Spoken Language Translation (IWSLT 2023) , pages=
Mach. Proceedings of the 20th International Conference on Spoken Language Translation (IWSLT 2023) , pages=
2023
-
[50]
Cheng, Sitong and Bian, Weizhen and Wang, Xinsheng and Yuan, Ruibin and Chen, Jianyi and Yin, Shunshun and Guo, Yike and Xue, Wei , journal=
-
[51]
arXiv preprint arXiv:2511.20974 , year=
RosettaSpeech: Zero-Shot Speech-to-Speech Translation from Monolingual Data , author=. arXiv preprint arXiv:2511.20974 , year=
-
[52]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Direct speech-to-speech translation with discrete units , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[53]
2023 , organization=
Karunya, S and Jalakandeshwaran, M and Uma, R and others , booktitle=. 2023 , organization=
2023
-
[54]
Cascade versus direct speech translation: Do the differences still make a difference? , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[55]
2026 , howpublished =
Gemma4 , author =. 2026 , howpublished =
2026
-
[56]
VoxPopuli: A large-scale multilingual speech corpus for representation learning, semi-supervised learning and interpretation , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[57]
ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Generalization ability of MOS prediction networks , author=. ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2022 , organization=
2022
- [58]
-
[59]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Proceedings of the tenth workshop on statistical machine translation , pages=
Popovi. Proceedings of the tenth workshop on statistical machine translation , pages=
-
[61]
Proceedings of the second conference on machine translation , pages=
Popovi. Proceedings of the second conference on machine translation , pages=
-
[62]
Rei, Ricardo and C. de Souza, Jos \'e G. and Alves, Duarte and Zerva, Chrysoula and Farinha, Ana C and Glushkova, Taisiya and Lavie, Alon and Coheur, Luisa and Martins, Andr \'e F. T. COMET -22: Unbabel- IST 2022 Submission for the Metrics Shared Task. Proceedings of the Seventh Conference on Machine Translation (WMT). 2022. doi:10.18653/v1/2022.wmt-1.52
-
[63]
doi:10.21437/Interspeech.2025-891 , issn =
Bornali Phukon and Xiuwen Zheng and Mark Hasegawa-Johnson , year =. doi:10.21437/Interspeech.2025-891 , issn =
-
[64]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[65]
A Call for Clarity in Reporting BLEU Scores
Post, Matt. A Call for Clarity in Reporting BLEU Scores. Proceedings of the Third Conference on Machine Translation: Research Papers. 2018
2018
-
[66]
Glot International , year =
Boersma, Paul , title =. Glot International , year =
-
[67]
Dubbing in Practice: A Large Scale Study of Human Localization With Insights for Automatic Dubbing
Brannon, William and Virkar, Yogesh and Thompson, Brian. Dubbing in Practice: A Large Scale Study of Human Localization With Insights for Automatic Dubbing. Transactions of the Association for Computational Linguistics. 2023. doi:10.1162/tacl_a_00551
-
[68]
Chenyang Le and Yao Qian and Dongmei Wang and Long Zhou and Shujie LIU and Xiaofei Wang and Midia Yousefi and Yanmin Qian and Jinyu Li and Michael Zeng , booktitle=. Trans. 2024 , url=
2024
-
[69]
Findings of the
Anastasopoulos, Antonios and Barrault, Lo. Findings of the. Proceedings of the 19th international conference on spoken language translation (IWSLT 2022) , pages=
2022
-
[70]
Journal of Machine Learning Research , volume=
Scaling speech technology to 1,000+ languages , author=. Journal of Machine Learning Research , volume=
-
[71]
Rozanov, Nikolai and Pankov, Vikentiy and Mukhutdinov, Dmitrii and Vypirailenko, Dima , booktitle=
-
[72]
Findings of the IWSLT 2025 Evaluation Campaign
Abdulmumin, Idris and Agostinelli, Victor and Alum. Findings of the IWSLT 2025 Evaluation Campaign. Proceedings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025). 2025. doi:10.18653/v1/2025.iwslt-1.44
-
[73]
FINDINGS OF THE IWSLT 2024 EVALUATION CAMPAIGN
Ahmad, Ibrahim Said and Anastasopoulos, Antonios and Bojar, Ond. FINDINGS OF THE IWSLT 2024 EVALUATION CAMPAIGN. Proceedings of the 21st International Conference on Spoken Language Translation (IWSLT 2024). 2024. doi:10.18653/v1/2024.iwslt-1.1
-
[74]
Ma, Mingbo and Huang, Liang and Xiong, Hao and Zheng, Renjie and Liu, Kaibo and Zheng, Baigong and Zhang, Chuanqiang and He, Zhongjun and Liu, Hairong and Li, Xing and others , booktitle=
-
[75]
Ma, Xutai and Dousti, Mohammad Javad and Wang, Changhan and Gu, Jiatao and Pino, Juan , booktitle=
-
[76]
Proceedings of the Third Workshop on Automatic Simultaneous Translation , pages=
Over-generation cannot be rewarded: Length-adaptive average lagging for simultaneous speech translation , author=. Proceedings of the Third Workshop on Automatic Simultaneous Translation , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.