Let There Be Light: Reflection, Refraction and Scattering for Neural Operators
Pith reviewed 2026-06-28 10:57 UTC · model grok-4.3
The pith
A neural operator decomposes latent evolution into reflection, refraction, and scattering to separate local modulation from global communication.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an operator-learning architecture whose latent evolution decomposes into reflection and refraction as adaptive pointwise transformations together with scattering as input-dependent nonlocal propagation yields a structured neural operator that cleanly separates local feature modulation from global spatial communication while supporting an efficient linear-complexity implementation.
What carries the argument
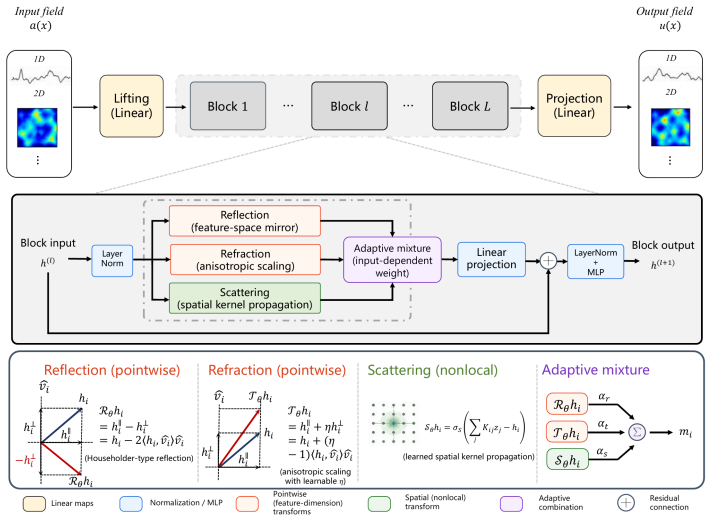
The LiNO architecture whose latent evolution decomposes into reflection and refraction (pointwise adaptive transformations) and scattering (normalized pairwise kernel or its efficient linear variant).
If this is right
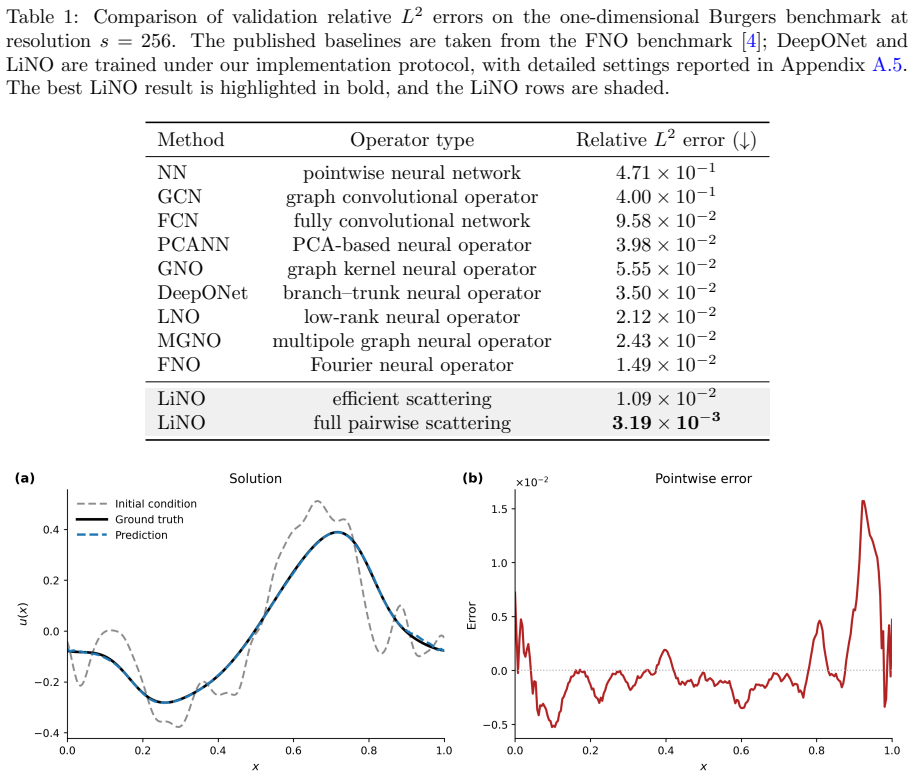
- The efficient scattering variant reduces dominant spatial complexity from quadratic to linear while preserving nonlocal propagation.
- Local feature reorientation and anisotropic modulation remain cleanly separated from global spatial communication.
- The architecture supplies a modular, physically motivated latent evolution that can be inspected component-wise.
- Mesh scalability improves because the linear-complexity scattering variant does not require explicit pairwise computation over all points.
Where Pith is reading between the lines
- Similar light-transport decompositions could be tested in other operator-learning backbones to check whether the separation of local and nonlocal operations generalizes beyond the proposed design.
- The normalized pairwise kernel formulation might be reusable in attention-style models that already employ relative positional biases.
- Wave or transport-dominated PDEs could serve as natural test cases where the physical analogy is strongest.
Load-bearing premise
That the specific decomposition into reflection, refraction, and scattering mechanisms will produce measurable gains in interpretability, nonlocal communication, mesh scalability, and cost without post-hoc tuning that undermines the claimed modular structure.
What would settle it
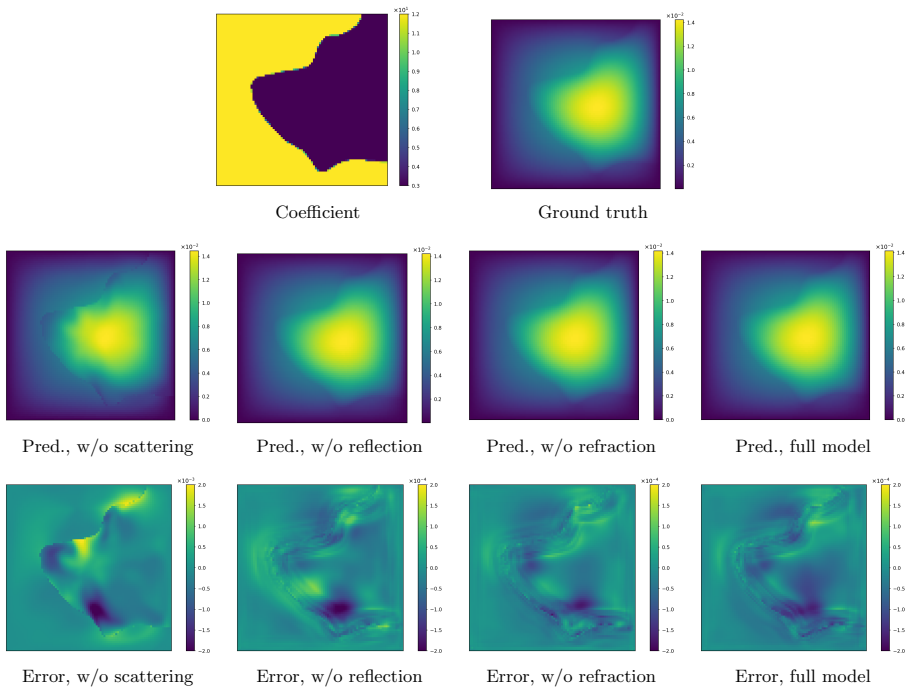
Benchmark experiments on parametric PDE tasks in which the full LiNO model shows no accuracy or efficiency advantage over existing neural operators, or in which ablating the scattering component produces no measurable degradation.
Figures

read the original abstract
Neural operators learn mappings between infinite-dimensional function spaces and provide a data-driven surrogate modeling paradigm for parametric partial differential equations (PDEs). Existing architectures typically obtain expressivity by parameterizing integral kernels in prescribed transform domains or by applying attention-like interactions over discretized spatial points. While these approaches have achieved substantial progress, they often face a persistent trade-off among physical interpretability, nonlocal spatial communication, mesh scalability, and computational cost. We propose a Light-inspired neural operator(LiNO), an operator-learning architecture whose latent evolution is decomposed into three mechanisms motivated by elementary light transport: reflection, refraction, and scattering. Reflection and refraction act as adaptive pointwise transformations in latent feature space, enabling local feature reorientation and anisotropic modulation, whereas scattering performs input-dependent nonlocal propagation over the physical domain. We first formulate scattering as a normalized pairwise kernel with relative positional bias, and then develop an efficient scattering variant that replaces explicit pairwise interactions with positive-feature global propagation and a local diffusion branch, reducing the dominant spatial complexity from quadratic to linear. This yields a structured neural operator that separates local feature modulation from global spatial communication while retaining a modular and interpretable latent evolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LiNO, a neural operator architecture for learning mappings between function spaces that decomposes latent evolution into three mechanisms inspired by light transport: reflection and refraction as adaptive pointwise transformations enabling local feature reorientation and anisotropic modulation, and scattering as input-dependent nonlocal propagation over the physical domain. Scattering is first formulated as a normalized pairwise kernel with relative positional bias and then approximated by an efficient variant using positive-feature global propagation plus a local diffusion branch, reducing spatial complexity from quadratic to linear. The architecture is presented as separating local modulation from global communication while retaining modular interpretability.
Significance. If the decomposition delivers the claimed separation of local and nonlocal operations along with the stated gains in interpretability, scalability, and cost without post-hoc adjustments that erode the structure, the work could supply a physically motivated alternative to kernel- or attention-based neural operators, with the linear-complexity scattering variant offering a concrete route to mesh-independent scaling.
minor comments (2)
- [Abstract] The abstract states that the efficient scattering variant 'replaces explicit pairwise interactions with positive-feature global propagation and a local diffusion branch,' but does not specify how positivity is enforced or how the diffusion branch is parameterized; a short clarifying paragraph or pseudocode in §3 would aid reproducibility.
- [Abstract] Notation for the normalized pairwise kernel and the relative positional bias is introduced without an accompanying equation; adding the explicit form (even if later approximated) would make the transition to the linear variant easier to follow.
Simulated Author's Rebuttal
We thank the referee for the supportive review and the recommendation of minor revision. The provided summary accurately captures the core ideas of LiNO, including the decomposition into reflection, refraction, and scattering mechanisms as well as the efficient linear-complexity variant.
Circularity Check
No circularity in derivation chain
full rationale
The paper presents LiNO as an architectural proposal that decomposes latent evolution into reflection, refraction, and scattering mechanisms motivated by light transport. This is explicitly a design choice to achieve interpretability, nonlocal communication, and linear complexity via a normalized pairwise kernel or its global+diffusion approximation. No equations, self-citations, or derivations are shown that reduce any claimed performance or uniqueness to fitted parameters, self-definitions, or prior author results by construction. The separation of local modulation from global propagation follows directly from the stated roles without circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tianping Chen and Hong Chen. Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems.IEEE Transactions on Neural Networks, 6(4):911–917, 1995
1995
-
[2]
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators.Nature Machine Intelligence, 3:218–229, 2021
Lu Lu, Pengzhan Jin, and George Em Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators.Nature Machine Intelligence, 3:218–229, 2021
2021
-
[3]
Neural operator: Learning maps between function spaces.Journal of Machine Learning Research, 24(89):1–97, 2023
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces.Journal of Machine Learning Research, 24(89):1–97, 2023
2023
-
[4]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, An- drew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. InInternational Conference on Learning Representations, 2021
2021
-
[5]
Neural Operator: Graph Kernel Network for Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Graph kernel network for partial differential equations.arXiv preprint arXiv:2003.03485, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[6]
Multipole graph neural operator for parametric partial differential equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Multipole graph neural operator for parametric partial differential equations. InAdvances in Neural Information Processing Systems, volume 33, pages 6755–6766, 2020
2020
-
[7]
A comprehensive and fair comparison of two neural operators (with prac- tical extensions) based on FAIR data.Computer Methods in Applied Mechanics and Engineering, 393:114778, 2022
Lu Lu, Xuhui Meng, Shengze Cai, Zhiping Mao, Somdatta Goswami, Zhongqiang Zhang, and George Em Karniadakis. A comprehensive and fair comparison of two neural operators (with prac- tical extensions) based on FAIR data.Computer Methods in Applied Mechanics and Engineering, 393:114778, 2022
2022
-
[8]
LNO: Laplace neural operator for solving differential equations.Nature Machine Intelligence, 6:631–640, 2024
Qianying Cao, Somdatta Goswami, and George Em Karniadakis. LNO: Laplace neural operator for solving differential equations.Nature Machine Intelligence, 6:631–640, 2024
2024
-
[9]
Tapas Tripura and Souvik Chakraborty. Wavelet neural operator for solving parametric partial dif- ferential equations in computational mechanics problems.Computer Methods in Applied Mechanics and Engineering, 404:115783, 2023
2023
-
[10]
Gege Wen, Zongyi Li, Kamyar Azizzadenesheli, Anima Anandkumar, and Sally M. Benson. U-FNO: An enhanced fourier neural operator-based deep-learning model for multiphase flow.Advances in Water Resources, 163:104180, 2022
2022
-
[11]
Ross, and Kamyar Azizzadenesheli
Md Ashiqur Rahman, Zachary E. Ross, and Kamyar Azizzadenesheli. U-NO: U-shaped neural operators.Transactions on Machine Learning Research, 2023
2023
-
[12]
Fourier neural operator with learned deformations for PDEs on general geometries.Journal of Machine Learning Research, 24(388):1–26, 2023
Zongyi Li, Daniel Zhengyu Huang, Burigede Liu, and Anima Anandkumar. Fourier neural operator with learned deformations for PDEs on general geometries.Journal of Machine Learning Research, 24(388):1–26, 2023. 23
2023
-
[13]
Geometry-informed neural operator for large-scale 3D PDEs
Zongyi Li, Nikola Kovachki, Chris Choy, Boyi Li, Jean Kossaifi, Shourya Otta, Mohammad Amin Nabian, Maximilian Stadler, Christian Hundt, Kamyar Azizzadenesheli, and Anima Anandkumar. Geometry-informed neural operator for large-scale 3D PDEs. InAdvances in Neural Information Processing Systems, December 2023
2023
-
[14]
Point cloud neural operator for parametric PDEs on complex and variable geometries.Computer Methods in Applied Mechanics and Engineering, 443:118022, 2025
Chenyu Zeng, Yanshu Zhang, Jiayi Zhou, Yuhan Wang, Zilin Wang, Yuhao Liu, Lei Wu, and Daniel Zhengyu Huang. Point cloud neural operator for parametric PDEs on complex and variable geometries.Computer Methods in Applied Mechanics and Engineering, 443:118022, 2025
2025
-
[15]
Mingyu Han, Daniel Zhengyu Huang, Yuhan Wang, Yanshu Zhang, and Jiayi Zhou. Geometric generalization of neural operators from kernel integral perspective.arXiv preprint arXiv:2602.01498, 2026
-
[16]
Koopman neural operator as a mesh-free solver of non-linear partial differential equations.Journal of Com- putational Physics, page 113194, 2024
Wei Xiong, Xiaomeng Huang, Ziyang Zhang, Ruixuan Deng, Pei Sun, and Yang Tian. Koopman neural operator as a mesh-free solver of non-linear partial differential equations.Journal of Com- putational Physics, page 113194, 2024
2024
-
[17]
Koopmanlab: machine learning for solving complex physics equations.APL Machine Learning, 1(3), 2023
Wei Xiong, Muyuan Ma, Xiaomeng Huang, Ziyang Zhang, Pei Sun, and Yang Tian. Koopmanlab: machine learning for solving complex physics equations.APL Machine Learning, 1(3), 2023
2023
-
[18]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[19]
Choose a Transformer: Fourier or Galerkin
Shuhao Cao. Choose a Transformer: Fourier or Galerkin. InAdvances in Neural Information Processing Systems, volume 34, pages 24924–24940, 2021
2021
-
[20]
Transformer for partial differential equations’ operator learning.Transactions on Machine Learning Research, 2023
Zijie Li, Kazem Meidani, and Amir Barati Farimani. Transformer for partial differential equations’ operator learning.Transactions on Machine Learning Research, 2023
2023
-
[21]
Transolver: A fast transformer solver for PDEs on general geometries
Haixu Wu, Huakun Luo, Haowen Wang, Jianmin Wang, and Mingsheng Long. Transolver: A fast transformer solver for PDEs on general geometries. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 53681–53705. PMLR, 2024
2024
-
[22]
Transolver++: An accurate neural solver for PDEs on million-scale geometries
Huakun Luo, Haixu Wu, Hang Zhou, Lanxiang Xing, Yichen Di, Jianmin Wang, and Mingsheng Long. Transolver++: An accurate neural solver for PDEs on million-scale geometries. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 41432–41449. PMLR, 2025
2025
-
[23]
Transolver-3: Scaling Up Transformer Solvers to Industrial-Scale Geometries
Hang Zhou, Haixu Wu, Haonan Shangguan, Yuezhou Ma, Huikun Weng, Jianmin Wang, and Ming- sheng Long. Transolver-3: Scaling up transformer solvers to industrial-scale geometries.arXiv preprint arXiv:2602.04940, 2026
work page internal anchor Pith review arXiv 2026
-
[24]
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and Fran¸ cois Fleuret. Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. InInternational conference on machine learning, pages 5156–5165. PMLR, 2020. 24
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.