Mixed-Modality Dual Face-Hair Retrieval
Pith reviewed 2026-06-28 10:38 UTC · model grok-4.3
The pith
A new retrieval task combines a face image for identity with a separate hairstyle reference given as image or text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
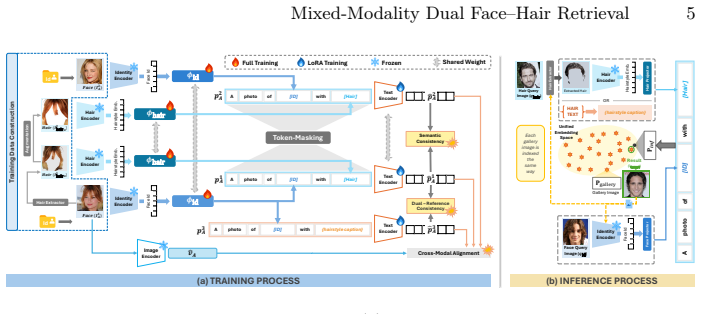
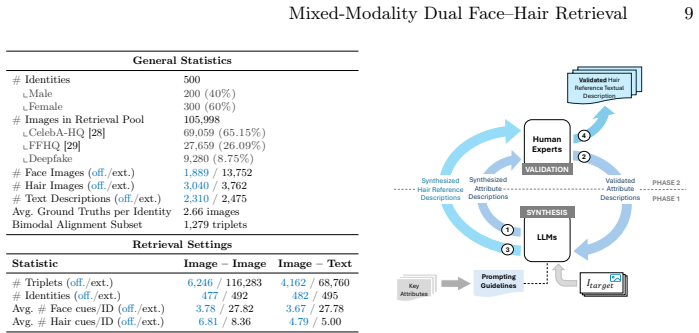
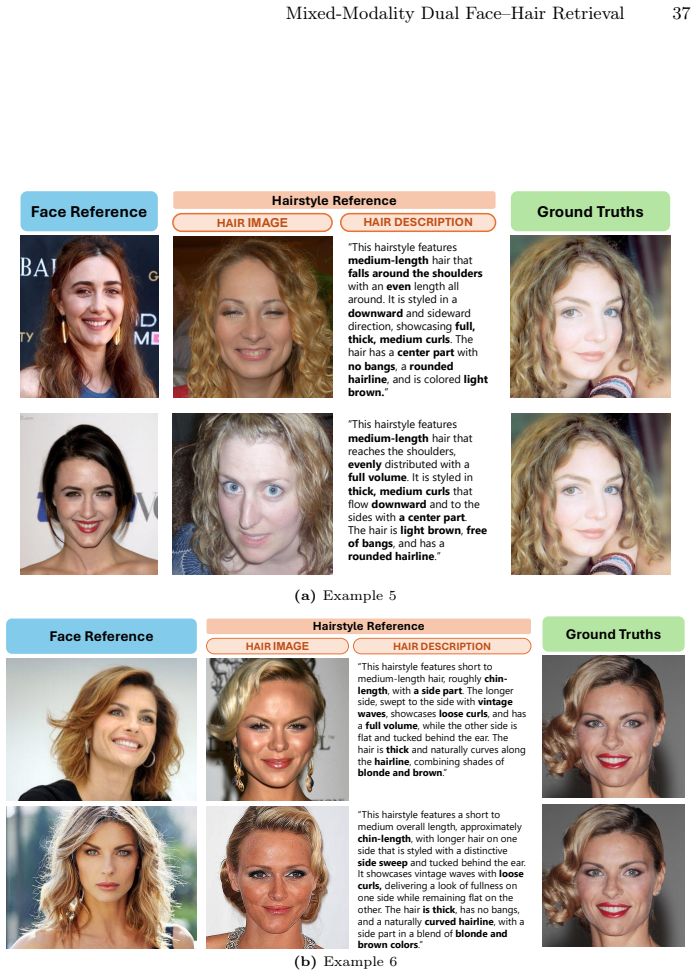
DFHR is a mixed-modality dual-reference task in image retrieval where a query consists of a face image specifying identity and a hairstyle reference expressed as either an image or text. Unlike prior retrieval settings, DFHR requires cross-component reasoning between two semantically independent attributes originating from heterogeneous modalities. DFHR-Bench comprises over 180K annotated triplets across dual-image and image-text settings. MFHC fuses disentangled identity and hairstyle embeddings through token injection and multi-view supervision.
What carries the argument
MFHC (Multimodal Face-Hair Combiner), a framework that fuses disentangled identity and hairstyle embeddings through token injection and multi-view supervision.
If this is right
- Retrieval systems can now treat identity and hairstyle as independently controllable inputs from different modalities.
- Evaluation becomes possible on dual-image and image-text query pairs within the same benchmark.
- Models must learn localized disentanglement plus cross-modal alignment inside one shared space.
- The construction method supplies a reusable protocol for building similar mixed-attribute datasets.
Where Pith is reading between the lines
- The same disentanglement-plus-fusion pattern could apply to other independent attribute pairs such as clothing and expression.
- Real deployment would require testing whether the annotation protocol scales without introducing systematic identity drift.
- Performance gains may depend on how cleanly the face and hair regions separate in the input images.
Load-bearing premise
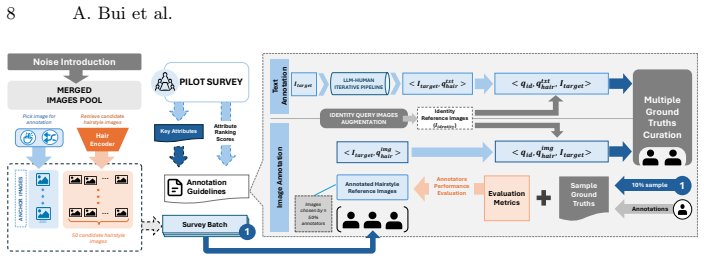
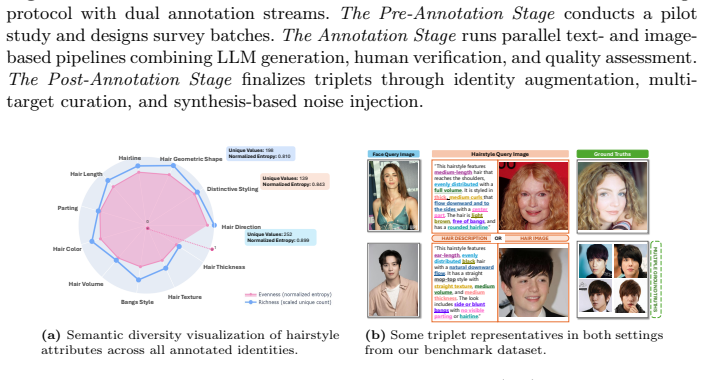
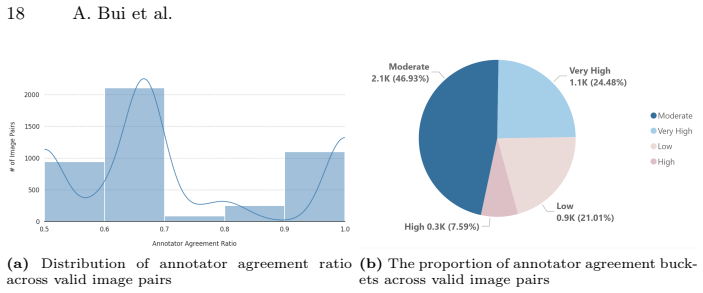
The multi-stage annotation protocol ensures semantic and identity integrity in the constructed DFHR-Bench triplets.
What would settle it
A direct check of whether a random sample of DFHR-Bench triplets contains identity or hairstyle mismatches, or whether MFHC retrieval accuracy on the benchmark drops below simple concatenation baselines.
Figures
















read the original abstract
We introduce Dual Face-Hair Retrieval (DFHR), a new mixed-modality dual-reference task in image retrieval where a query consists of a face image specifying identity and a hairstyle reference expressed as either an image or text. Unlike prior retrieval settings, DFHR requires cross-component reasoning between two semantically independent attributes -- identity and hairstyle -- originating from heterogeneous modalities. This formulation demands localized feature disentanglement, cross-modal semantic alignment, and mixed-modality composition within a unified embedding space. We construct DFHR-Bench, the first benchmark for mixed-modality face-hair retrieval, comprising over 180K annotated triplets across dual-image and image-text settings, built via a multi-stage annotation protocol ensuring semantic and identity integrity. We further propose MFHC (Multimodal Face-Hair Combiner), a unified framework that fuses disentangled identity and hairstyle embeddings through token injection and multi-view supervision. DFHR and DFHR-Bench together establish a new paradigm for identity-aware, attribute-controllable visual retrieval across modalities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Dual Face-Hair Retrieval (DFHR) as a mixed-modality dual-reference retrieval task in which a query pairs a face image (for identity) with a hairstyle reference that may be either an image or text. It constructs DFHR-Bench, a benchmark of over 180K annotated triplets built via a multi-stage annotation protocol, and proposes the MFHC framework that fuses disentangled identity and hairstyle embeddings via token injection and multi-view supervision, claiming that DFHR and DFHR-Bench together establish a new paradigm for identity-aware, attribute-controllable visual retrieval across modalities.
Significance. If the benchmark construction proves reliable and the MFHC model is shown to be effective, the work could open a useful new direction in cross-modal retrieval by emphasizing explicit disentanglement of identity from hairstyle attributes and mixed-modality composition. The scale of the proposed benchmark is potentially enabling for future research, but the absence of any empirical validation leaves the significance speculative rather than demonstrated.
major comments (2)
- Abstract: the claim that a multi-stage annotation protocol ensures semantic and identity integrity across >180K triplets is unsupported because the manuscript supplies zero description of the protocol stages, face-hair matching criteria, text validation steps, or quantitative integrity metrics (e.g., identity consistency or failure rates); this is load-bearing for the benchmark's utility in supporting the claimed disentanglement and cross-modal demands.
- Abstract: the manuscript describes the DFHR task, DFHR-Bench construction, and MFHC framework yet provides no quantitative results, ablation studies, or baseline comparisons, so the central claims about localized feature disentanglement, cross-modal semantic alignment, and mixed-modality composition cannot be assessed.
minor comments (1)
- Abstract: technical terms such as 'token injection' and 'multi-view supervision' are introduced without definition or reference to the sections where they are elaborated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [—] Abstract: the claim that a multi-stage annotation protocol ensures semantic and identity integrity across >180K triplets is unsupported because the manuscript supplies zero description of the protocol stages, face-hair matching criteria, text validation steps, or quantitative integrity metrics (e.g., identity consistency or failure rates); this is load-bearing for the benchmark's utility in supporting the claimed disentanglement and cross-modal demands.
Authors: We agree that the manuscript does not currently provide a description of the annotation protocol stages, matching criteria, validation steps, or quantitative integrity metrics. In the revised version we will add a dedicated section with these details to substantiate the benchmark construction claims. revision: yes
-
Referee: [—] Abstract: the manuscript describes the DFHR task, DFHR-Bench construction, and MFHC framework yet provides no quantitative results, ablation studies, or baseline comparisons, so the central claims about localized feature disentanglement, cross-modal semantic alignment, and mixed-modality composition cannot be assessed.
Authors: We acknowledge the absence of quantitative results, ablations, and baseline comparisons in the current manuscript. We will add an experimental section with performance evaluations, component ablations, and baseline comparisons to allow assessment of the framework claims. revision: yes
Circularity Check
No circularity; contribution is definitional with no derivations or fitted predictions
full rationale
The paper introduces DFHR as a new task definition and proposes MFHC as a framework, with DFHR-Bench constructed via an annotation protocol. No equations, parameter fitting, or derivation chains appear in the provided text. The central claim does not reduce any result to its inputs by construction, self-citation, or renaming; it is a task and benchmark proposal without mathematical self-reference. This matches the default non-circular case for papers lacking derivations.
Axiom & Free-Parameter Ledger
invented entities (3)
-
DFHR task
no independent evidence
-
DFHR-Bench
no independent evidence
-
MFHC
no independent evidence
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Agnolucci, L., Baldrati, A., Del Bimbo, A., Bertini, M.: isearle: Improving textual inversion for zero-shot composed image retrieval. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[2]
arXiv preprint arXiv:2309.16609 (2023)
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023)
Pith/arXiv arXiv 2023
-
[3]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Baldrati, A., Agnolucci, L., Bertini, M., Del Bimbo, A.: Zero-shot composed image retrieval with textual inversion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15338–15347 (2023)
2023
-
[4]
Cao, Q., Shen, L., Xie, W., Parkhi, O.M., Zisserman, A.: Vggface2: A dataset for recognising faces across pose and age (2018),https://arxiv.org/abs/1710.08092
Pith/arXiv arXiv 2018
-
[5]
In: International conference on machine learning
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. In: International conference on machine learning. pp. 1597–1607. PmLR (2020)
2020
-
[6]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, Y., Zhong, H., He, X., Peng, Y., Zhou, J., Cheng, L.: Fashionern: enhance- and-refine network for composed fashion image retrieval. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 1228–1236 (2024)
2024
-
[7]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chung, C., Park, S., Kim, J., Choo, J.: What to preserve and what to transfer: Faithful, identity-preserving diffusion-based hairstyle transfer. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 2582–2590 (2025)
2025
-
[8]
this is my unicorn, fluffy
Cohen, N., Gal, R., Meirom, E.A., Chechik, G., Atzmon, Y.: “this is my unicorn, fluffy”: Personalizing frozen vision-language representations. In: European confer- ence on computer vision. pp. 558–577. Springer (2022)
2022
-
[9]
Cole, R.: Inter-rater reliability methods in qualitative case study research. Socio- logical Methods & Research53(4), 1944–1975 (2024).https://doi.org/10.1177/ 00491241231156971,https://doi.org/10.1177/00491241231156971
-
[10]
Cui, X., Huang, Z., Adel, N.: Bias in, bias out: Annotation bias in multilingual large language models (2025),https://arxiv.org/abs/2511.14662
arXiv 2025
-
[11]
ACM Computing Surveys (Csur)40(2), 1–60 (2008)
Datta, R., Joshi, D., Li, J., Wang, J.Z.: Image retrieval: Ideas, influences, and trends of the new age. ACM Computing Surveys (Csur)40(2), 1–60 (2008)
2008
-
[12]
arXiv preprint arXiv:2203.08101 (2022) 16 A
Delmas, G., de Rezende, R.S., Csurka, G., Larlus, D.: Artemis: Attention- based retrieval with text-explicit matching and implicit similarity. arXiv preprint arXiv:2203.08101 (2022) 16 A. Bui et al
arXiv 2022
-
[13]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition
Deng, J., Guo, J., Ververas, E., Kotsia, I., Zafeiriou, S.: Retinaface: Single-shot multi-level face localisation in the wild. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition. pp. 5203–5212 (2020)
2020
-
[14]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deng, J., Guo, J., Xue, N., Zafeiriou, S.: Arcface: Additive angular margin loss for deep face recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4690–4699 (2019)
2019
-
[15]
Derksen, B.M., Bruinsma, W., Goslings, J.C., Schep, N.W.: The kappa paradox explained. The Journal of Hand Surgery49(5), 482–485 (2024).https://doi.org/ https://doi.org/10.1016/j.jhsa.2024.01.006,https://www.sciencedirect. com/science/article/pii/S0363502324000224
-
[16]
In: Proceedings of the IEEE International Conference on Computer Vision
Fernando, B., Tuytelaars, T.: Mining multiple queries for image retrieval: On-the- fly learning of an object-specific mid-level representation. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 2544–2551 (2013)
2013
-
[17]
arXiv preprint arXiv:2208.01618 (2022)
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G., Cohen-Or, D.: An image is worth one word: Personalizing text-to-image gener- ation using textual inversion. arXiv preprint arXiv:2208.01618 (2022)
Pith/arXiv arXiv 2022
-
[18]
Gallegos, I.O., Rossi, R.A., Barrow, J., Tanjim, M.M., Kim, S., Dernoncourt, F., Yu, T., Zhang, R., Ahmed, N.K.: Bias and fairness in large language models: A survey (2024),https://arxiv.org/abs/2309.00770
arXiv 2024
-
[19]
In: Blodgett, S.L., Cercas Curry, A., Dev, S., Madaio, M., Nenkova, A., Yang, D., Xiao, Z
Gautam, S., Srinath, M.: Blind spots and biases: Exploring the role of annotator cognitive biases in NLP. In: Blodgett, S.L., Cercas Curry, A., Dev, S., Madaio, M., Nenkova, A., Yang, D., Xiao, Z. (eds.) Proceedings of the Third Workshop on Bridging Human–Computer Interaction and Natural Language Processing. pp. 82–
-
[20]
https://doi.org/10.18653/v1/2024.hcinlp-1.8,https://aclanthology.org/ 2024.hcinlp-1.8/
Association for Computational Linguistics, Mexico City, Mexico (Jun 2024). https://doi.org/10.18653/v1/2024.hcinlp-1.8,https://aclanthology.org/ 2024.hcinlp-1.8/
-
[21]
British Journal of Mathematical and Statistical Psychology61(1), 29–48 (2008)
Gwet, K.: Computing inter-rater reliability and its variance in the presence of high agreement. The British journal of mathematical and statistical psychology 61, 29–48 (06 2008).https://doi.org/10.1348/000711006X126600
-
[22]
In: European Conference on Computer Vision
Han, Y., Zhu, J., He, K., Chen, X., Ge, Y., Li, W., Li, X., Zhang, J., Wang, C., Liu, Y.: Face-adapter for pre-trained diffusion models with fine-grained id and attribute control. In: European Conference on Computer Vision. pp. 20–36. Springer (2024)
2024
-
[23]
Hettiachchi, D., Holcombe-James, I., Livingstone, S., de Silva, A., Lease, M., Salim, F.D., Sanderson, M.: How crowd worker factors influence subjective annotations: A study of tagging misogynistic hate speech in tweets (2023),https://arxiv.org/ abs/2309.01288
arXiv 2023
-
[24]
In: Proceedings of the AAAI conference on artificial intel- ligence
Huang, F., Zhang, L., Fu, X., Song, S.: Dynamic weighted combiner for mixed- modal image retrieval. In: Proceedings of the AAAI conference on artificial intel- ligence. vol. 38, pp. 2303–2311 (2024)
2024
-
[25]
Huang, G.B., Ramesh, M., Berg, T., Learned-Miller, E.: Labeled faces in the wild: A database for studying face recognition in unconstrained environments. Tech. Rep. 07-49, University of Massachusetts, Amherst (October 2007)
2007
-
[26]
arXiv preprint arXiv:2404.16771 (2024)
Huang, J., Dong, X., Song, W., Chong, Z., Tang, Z., Zhou, J., Cheng, Y., Chen, L., Li, H., Yan, Y., et al.: Consistentid: Portrait generation with multimodal fine- grained identity preserving. arXiv preprint arXiv:2404.16771 (2024)
arXiv 2024
-
[27]
Jeong, H., Ma, S., Houmansadr, A.: Bias similarity measurement: A black-box audit of fairness across llms (2025),https://arxiv.org/abs/2410.12010
arXiv 2025
-
[28]
IEEE Transactions on Multimedia (2025) Mixed-Modality Dual Face–Hair Retrieval 17
Ji,Z.,Li,Z.,Zhang,Y.,Pang,Y.,Li,X.:Visualsemanticcontextualizationnetwork for multi-query image retrieval. IEEE Transactions on Multimedia (2025) Mixed-Modality Dual Face–Hair Retrieval 17
2025
-
[29]
Karras, T., Aila, T., Laine, S., Lehtinen, J.: Progressive growing of gans for im- proved quality, stability, and variation (2018),https://arxiv.org/abs/1710. 10196
2018
-
[30]
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks (2019),https://arxiv.org/abs/1812.04948
Pith/arXiv arXiv 2019
-
[31]
In: European conference on computer vision
Kim, T., Chung, C., Kim, Y., Park, S., Kim, K., Choo, J.: Style your hair: Latent optimization for pose-invariant hairstyle transfer via local-style-aware hair align- ment. In: European conference on computer vision. pp. 188–203. Springer (2022)
2022
-
[32]
In: 2021 IEEE International Conference on Image Processing (ICIP)
Kim, T., Chung, C., Park, S., Gu, G., Nam, K., Choe, W., Lee, J., Choo, J.: K- hairstyle:Alarge-scalekoreanhairstyledatasetforvirtualhaireditingandhairstyle classification. In: 2021 IEEE International Conference on Image Processing (ICIP). p. 1299–1303. IEEE (Sep 2021).https://doi.org/10.1109/icip42928.2021. 9506557,http://dx.doi.org/10.1109/ICIP42928.202...
-
[33]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Koley, S., Bhunia, A.K., Sain, A., Chowdhury, P.N., Xiang, T., Song, Y.Z.: You’ll never walk alone: A sketch and text duet for fine-grained image retrieval. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 16509–16519 (2024)
2024
-
[34]
Korteling, J.H., Toet, A., Gerritsma, J.: Retention and transfer of cognitive bias mitigation interventions: A systematic literature study (03 2021).https://doi. org/10.31234/osf.io/ed43s
-
[35]
Advances in neural information processing systems34, 9694–9705 (2021)
Li,J.,Selvaraju,R.,Gotmare,A.,Joty,S.,Xiong,C.,Hoi,S.C.H.:Alignbeforefuse: Vision and language representation learning with momentum distillation. Advances in neural information processing systems34, 9694–9705 (2021)
2021
-
[36]
In: Proceedings of the 47th In- ternational ACM SIGIR Conference on Research and Development in Information Retrieval
Lin, H., Wen, H., Song, X., Liu, M., Hu, Y., Nie, L.: Fine-grained textual inversion network for zero-shot composed image retrieval. In: Proceedings of the 47th In- ternational ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 240–250 (2024)
2024
-
[37]
arXiv preprint arXiv:2306.07272 (2023)
Liu, Y., Yao, J., Zhang, Y., Wang, Y., Xie, W.: Zero-shot composed text-image retrieval. arXiv preprint arXiv:2306.07272 (2023)
arXiv 2023
-
[38]
Liu, Z., Rodriguez-Opazo, C., Teney, D., Gould, S.: Image retrieval on real-life images with pre-trained vision-and-language models (2021),https://arxiv.org/ abs/2108.04024
arXiv 2021
-
[39]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Liu, Z., Sun, W., Hong, Y., Teney, D., Gould, S.: Bi-directional training for com- posed image retrieval via text prompt learning. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 5753–5762 (2024)
2024
-
[40]
In: Proceedings of International Conference on Computer Vision (ICCV) (December 2015)
Liu, Z., Luo, P., Wang, X., Tang, X.: Deep learning face attributes in the wild. In: Proceedings of International Conference on Computer Vision (ICCV) (December 2015)
2015
-
[41]
Mangrulkar, S., Gugger, S., Debut, L., Belkada, Y., Paul, S., Bossan, B.: PEFT: State-of-the-art parameter-efficient fine-tuning methods.https://github.com/ huggingface/peft(2022)
2022
-
[42]
Biochemia medica : ča- sopis Hrvatskoga društva medicinskih biokemičara / HDMB22, 276–82 (10 2012)
McHugh, M.: Interrater reliability: The kappa statistic. Biochemia medica : ča- sopis Hrvatskoga društva medicinskih biokemičara / HDMB22, 276–82 (10 2012). https://doi.org/10.11613/BM.2012.031
-
[43]
Messina, N., Vadicamo, L., Maltese, L., Gennaro, C.: Towards identity-aware cross- modal retrieval: a dataset and a baseline (2025),https://arxiv.org/abs/2412. 21009
2025
-
[44]
In: European Conference on Computer Vision
Mirza, M.J., Karlinsky, L., Lin, W., Doveh, S., Micorek, J., Kozinski, M., Kuehne, H., Possegger, H.: Meta-prompting for automating zero-shot visual recognition with llms. In: European Conference on Computer Vision. pp. 370–387. Springer (2024) 18 A. Bui et al
2024
-
[45]
Capturing Perspectives of Crowdsourced Annotators in Subjective Learning Tasks
Mokhberian, N., Marmarelis, M., Hopp, F., Basile, V., Morstatter, F., Lerman, K.: Capturing perspectives of crowdsourced annotators in subjective learning tasks. In: Duh, K., Gomez, H., Bethard, S. (eds.) Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1...
-
[46]
Nassar, J., Pavon-Harr, V., Bosch, M., McCulloh, I.: Assessing data quality of annotations with krippendorff alpha for applications in computer vision (2019), https://arxiv.org/abs/1912.10107
arXiv 2019
-
[47]
Advances in Neural In- formation Processing Systems37, 45600–45635 (2024)
Nikolaev, M., Kuznetsov, M., Vetrov, D., Alanov, A.: Hairfastgan: Realistic and robust hair transfer with a fast encoder-based approach. Advances in Neural In- formation Processing Systems37, 45600–45635 (2024)
2024
-
[48]
Plastic and reconstructive surgery126, 619–25 (08 2010).https://doi.org/10.1097/PRS
Pannucci, C., Wilkins, E.: Identifying and avoiding bias in research. Plastic and reconstructive surgery126, 619–25 (08 2010).https://doi.org/10.1097/PRS. 0b013e3181de24bc
work page doi:10.1097/prs 2010
-
[49]
In: European Confer- ence on Computer Vision
Papantoniou, F.P., Lattas, A., Moschoglou, S., Deng, J., Kainz, B., Zafeiriou, S.: Arc2face: A foundation model for id-consistent human faces. In: European Confer- ence on Computer Vision. pp. 241–261. Springer (2024)
2024
-
[50]
In: Proceedings of the 28th ACM interna- tional conference on multimedia
Qu, L., Liu, M., Cao, D., Nie, L., Tian, Q.: Context-aware multi-view summariza- tion network for image-text matching. In: Proceedings of the 28th ACM interna- tional conference on multimedia. pp. 1047–1055 (2020)
2020
-
[51]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[52]
In: Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval
Rao, J., Wang, F., Ding, L., Qi, S., Zhan, Y., Liu, W., Tao, D.: Where does the performance improvement come from? -a reproducibility concern about image- text retrieval. In: Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval. pp. 2727–2737 (2022)
2022
-
[53]
In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition
Saha, O., Van Horn, G., Maji, S.: Improved zero-shot classification by adapting vlms with text descriptions. In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition. pp. 17542–17552 (2024)
2024
-
[54]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Saito, K., Sohn, K., Zhang, X., Li, C.L., Lee, C.Y., Saenko, K., Pfister, T.: Pic2word: Mapping pictures to words for zero-shot composed image retrieval. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 19305–19314 (2023)
2023
-
[55]
ACM Transactions on Information Systems (2025)
Song, X., Lin, H., Wen, H., Hou, B., Xu, M., Nie, L.: A comprehensive survey on composed image retrieval. ACM Transactions on Information Systems (2025)
2025
-
[56]
In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition
Suo, Y., Ma, F., Zhu, L., Yang, Y.: Knowledge-enhanced dual-stream zero-shot composed image retrieval. In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition. pp. 26951–26962 (2024)
2024
-
[57]
Terhörst, P., Fährmann, D., Kolf, J.N., Damer, N., Kirchbuchner, F., Kuijper, A.: Maad-face: A massively annotated attribute dataset for face images (2021), https://arxiv.org/abs/2012.01030
arXiv 2021
-
[58]
org/abs/1812.07119 Mixed-Modality Dual Face–Hair Retrieval 19
Vo, N., Jiang, L., Sun, C., Murphy, K., Li, L.J., Fei-Fei, L., Hays, J.: Composing text and image for image retrieval - an empirical odyssey (2018),https://arxiv. org/abs/1812.07119 Mixed-Modality Dual Face–Hair Retrieval 19
Pith/arXiv arXiv 2018
-
[59]
Wang, J., Wang, L., Zheng, Y., Yeh, C.C.M., Jain, S., Zhang, W.: Learning-from- disagreement: A model comparison and visual analytics framework (2022),https: //arxiv.org/abs/2201.07849
arXiv 2022
-
[60]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, L., Ao, W., Boddeti, V.N., Lim, S.N.: Generative zero-shot composed im- age retrieval. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29690–29700 (2025)
2025
-
[61]
arXiv preprint arXiv:2401.07519 (2024)
Wang, Q., Bai, X., Wang, H., Qin, Z., Chen, A., Li, H., Tang, X., Hu, Y.: Instantid: Zero-shot identity-preserving generation in seconds. arXiv preprint arXiv:2401.07519 (2024)
Pith/arXiv arXiv 2024
-
[62]
Wang,X.,Ma,X.,Hou,X.,Ding,M.,Li,Y.,Chen,J.,Chen,W.,Peng,X.,Shen,L.: Facebench: A multi-view multi-level facial attribute vqa dataset for benchmarking face perception mllms (2025),https://arxiv.org/abs/2503.21457
arXiv 2025
-
[63]
In: Proceedings of the IEEE/CVF international conference on computer vision
Wei, T., Chen, D., Zhou, W., Liao, J., Zhang, W., Hua, G., Yu, N.: Hairclipv2: Unifying hair editing via proxy feature blending. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 23589–23599 (2023)
2023
-
[64]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wei, Y., Zhang, Y., Ji, Z., Bai, J., Zhang, L., Zuo, W.: Elite: Encoding visual concepts into textual embeddings for customized text-to-image generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15943–15953 (2023)
2023
-
[65]
In: Proceedings of the 47th International ACM SIGIR conference on research and development in information retrieval
Wen, H., Song, X., Chen, X., Wei, Y., Nie, L., Chua, T.S.: Simple but effective raw-data level multimodal fusion for composed image retrieval. In: Proceedings of the 47th International ACM SIGIR conference on research and development in information retrieval. pp. 229–239 (2024)
2024
-
[66]
Wu,H.,Gao,Y.,Guo,X.,Al-Halah,Z.,Rennie,S.,Grauman,K.,Feris,R.:Fashion iq: A new dataset towards retrieving images by natural language feedback (2020), https://arxiv.org/abs/1905.12794
arXiv 2020
-
[67]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xiao, R., Kim, S., Georgescu, M.I., Akata, Z., Alaniz, S.: Flair: Vlm with fine- grained language-informed image representations. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24884–24894 (2025)
2025
-
[68]
arXiv preprint arXiv:2510.14975 (2025)
Xu, H., Cheng, W., Xing, P., Fang, Y., Wu, S., Wang, R., Zeng, X., Jiang, D., Yu, G., Ma, X., et al.: Withanyone: Towards controllable and id consistent image generation. arXiv preprint arXiv:2510.14975 (2025)
arXiv 2025
-
[69]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yousaf, A., Shah, M.: Enhancing vision-language models for zero-shot video ac- tion recognition via visual-textual refinement and improved interpretability. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 331–340 (2025)
2025
-
[70]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Zhang, Y., Huang, N., Tang, F., Huang, H., Ma, C., Dong, W., Xu, C.: Inversion- based style transfer with diffusion models. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 10146–10156 (2023)
2023
-
[71]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhang, Y., Zhang, Q., Song, Y., Zhang, J., Tang, H., Liu, J.: Stable-hair: Real- world hair transfer via diffusion model. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 10348–10356 (2025)
2025
-
[72]
International Journal of Computer Vision130(9), 2337–2348 (2022)
Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Learning to prompt for vision-language models. International Journal of Computer Vision130(9), 2337–2348 (2022)
2022
-
[73]
Zhu, Z., Huang, G., Deng, J., Ye, Y., Huang, J., Chen, X., Zhu, J., Yang, T., Lu, J., Du, D., Zhou, J.: Webface260m: A benchmark unveiling the power of million-scale deep face recognition (2021),https://arxiv.org/abs/2103.04098 Mixed-Modality Dual Face–Hair Retrieval 1 Supplementary Material Mixed-Modality Dual Face–Hair Retrieval Table Of Content A Ethic...
arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.