AutoTail-BSFGM: Class-Balance-Aware Fine-Tuning for Chinese Scholarly Text Classification
Pith reviewed 2026-06-28 10:07 UTC · model grok-4.3
The pith
AutoTail-BSFGM improves validation accuracy by 0.83 points on Chinese scholarly abstract classification by adjusting for class imbalance during fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
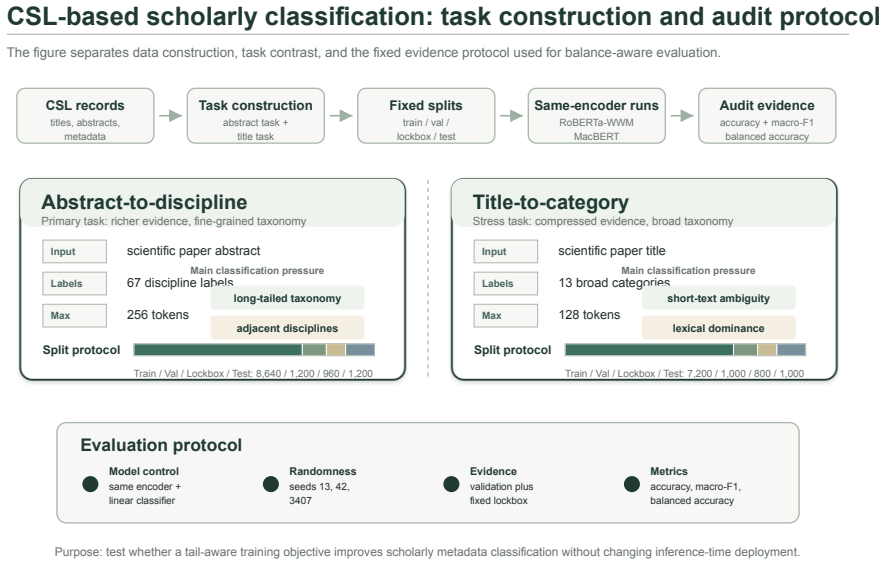
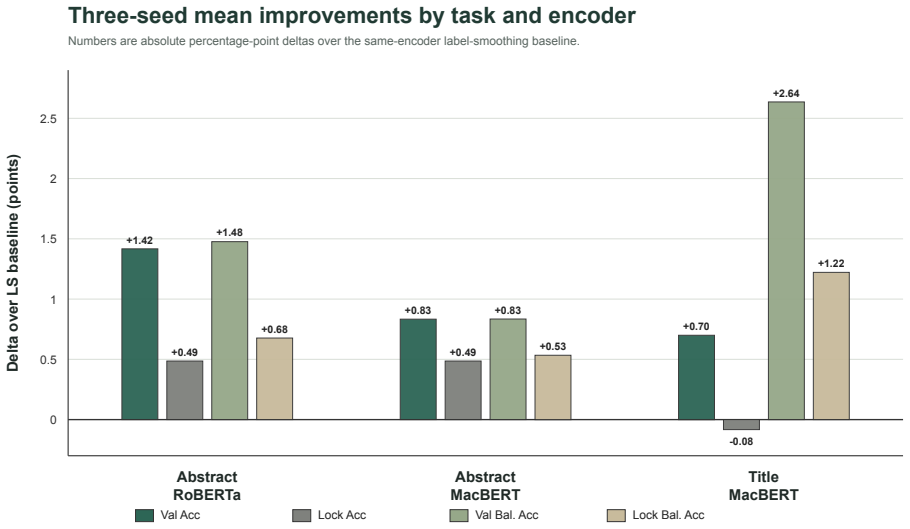
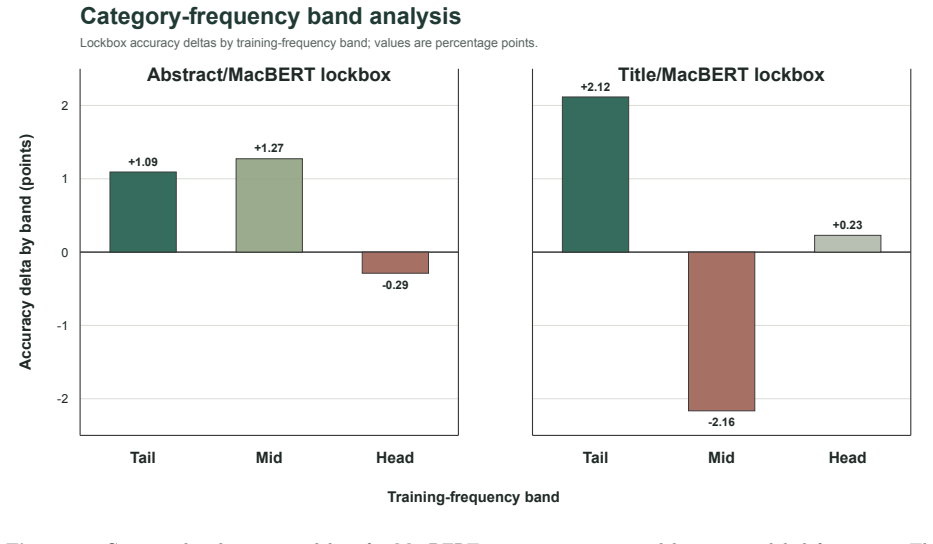
AutoTail-BSFGM changes only the training objective and procedure to improve class-balance-sensitive behavior in fine-tuning Chinese RoBERTa-WWM and MacBERT-base models. On the primary abstract task with 67 labels it increases validation accuracy by 0.83 points and lockbox accuracy by 0.49 points under MacBERT-base, accompanied by a pooled paired McNemar signal on validation (p = 0.023). On the title-to-category task with 13 categories it improves validation accuracy by 0.70 points and validation balanced accuracy by 2.64 points while showing approximately neutral lockbox accuracy but a 1.22-point gain in lockbox balanced accuracy.
What carries the argument
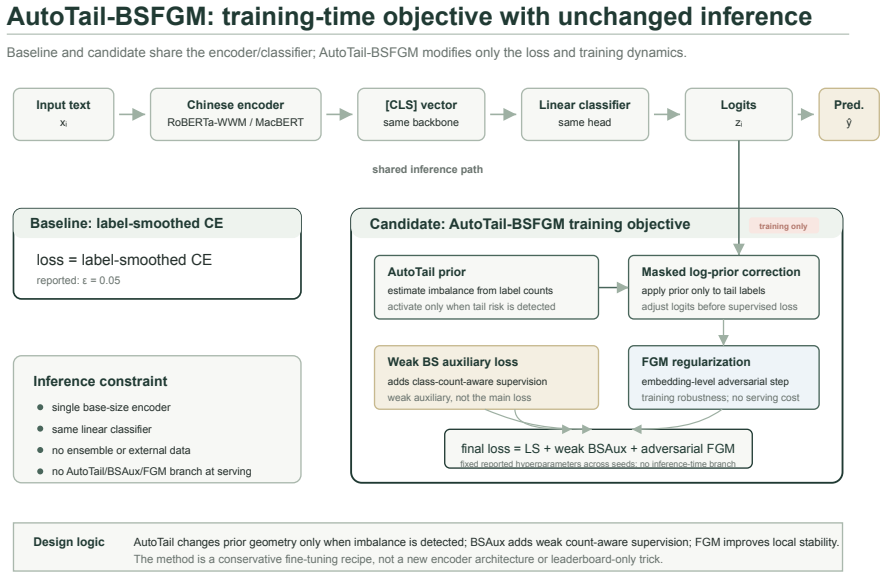
AutoTail-BSFGM, a class-balance-aware fine-tuning method that integrates an automatically gated tail-prior adjustment, a weak Balanced Softmax auxiliary loss, and Fast Gradient Method adversarial regularization.
If this is right
- The method improves class-balance-sensitive behavior on tasks with 67 imbalanced disciplinary labels.
- It produces consistent accuracy gains for abstract-based scholarly classification under two different base-size encoders.
- Validation balanced accuracy rises by 2.64 points on the 13-category title task.
- Inference cost remains identical to the label-smoothed baseline because only the training objective changes.
Where Pith is reading between the lines
- The same training-objective modifications could be tested on scholarly classification in other languages that exhibit label imbalance.
- Gains might be measured on encoder models larger than base size to check whether the class-balance adjustments scale.
- The approach suggests that auxiliary losses and adversarial steps can mitigate imbalance without requiring changes to model architecture or inference.
Load-bearing premise
The reported accuracy gains are caused by the class-balance-aware components rather than unstated differences in data preprocessing, hyperparameter search, or random seeds between the proposed method and the label-smoothed baseline.
What would settle it
A controlled replication that applies identical data preprocessing, hyperparameter search, and random seeds to the label-smoothed baseline and finds no accuracy difference on the same validation and lockbox splits would falsify the claim that the new components drive the gains.
Figures
read the original abstract
Scholarly text classification supports literature organization, subject indexing, and research intelligence, but Chinese scholarly corpora often contain imbalanced and semantically adjacent disciplinary labels. We propose AutoTail-BSFGM, a class-balance-aware fine-tuning method that combines an automatically gated tail-prior adjustment, a weak Balanced Softmax auxiliary loss, and Fast Gradient Method adversarial regularization. The method changes only the training objective and procedure; inference uses the same single base-size encoder and linear classifier as the corresponding label-smoothed baseline. We evaluate the method on two CSL-based tasks: an abstract-to-discipline task with 67 labels and a title-to-category task with 13 categories. On the primary abstract task, AutoTail-BSFGM improves validation and lockbox accuracy under both Chinese RoBERTa-WWM and MacBERT-base. With MacBERT-base, validation accuracy increases by 0.83 percentage points and lockbox accuracy by 0.49 points, with a pooled paired McNemar signal on validation (p = 0.023). On the title task, the method improves validation accuracy by 0.70 points and validation balanced accuracy by 2.64 points; lockbox accuracy is approximately neutral while lockbox balanced accuracy improves by 1.22 points. The results support a bounded contribution: AutoTail-BSFGM improves class-balance-sensitive behavior and yields consistent gains for abstract-based scholarly classification, without uniformly improving every metric on every split.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AutoTail-BSFGM, a class-balance-aware fine-tuning method for Chinese scholarly text classification that integrates an automatically gated tail-prior adjustment, a weak Balanced Softmax auxiliary loss, and Fast Gradient Method (FGM) adversarial regularization. It evaluates the approach on two CSL-based tasks—an abstract-to-discipline classification with 67 labels and a title-to-category task with 13 categories—using Chinese RoBERTa-WWM and MacBERT-base encoders. The central claim is that the method improves accuracy and balanced accuracy over a label-smoothed baseline (e.g., +0.83 pp validation and +0.49 pp lockbox accuracy with MacBERT-base on the abstract task, with McNemar p=0.023 on validation), while changing only the training objective and procedure; inference remains identical to the baseline. Results are reported on held-out validation and lockbox splits, with the improvements described as bounded and consistent rather than uniform across all metrics.
Significance. If the gains can be attributed to the proposed components, the work provides a practical, bounded improvement for handling imbalanced and semantically adjacent labels in Chinese scholarly corpora, which is relevant for literature organization and research intelligence applications. The use of a lockbox set and pooled paired McNemar test adds statistical rigor and helps guard against overfitting to validation. The explicit acknowledgment of bounded contributions is a strength. However, the absence of ablations and full implementation details limits assessment of which elements drive the effect and reproducibility of the small reported deltas.
major comments (3)
- [Methods / Training procedure description] The attribution of the reported accuracy lifts (0.83 pp validation, 0.49 pp lockbox for MacBERT-base on the abstract task) to the gated tail-prior, weak Balanced Softmax, and FGM rests on the assumption that data preprocessing, hyperparameter search, early-stopping, and random seeds are identical between AutoTail-BSFGM and the label-smoothed baseline. The manuscript provides no explicit statement or table confirming that hyperparameter tuning was performed under the same protocol or that the same seeds were used; this is load-bearing for the causal claim in the abstract and results.
- [Experimental results / Ablation analysis] No ablation experiments are reported that isolate the contribution of each component (gated tail-prior adjustment, weak Balanced Softmax auxiliary loss, FGM). For instance, it is not shown whether the +2.64 pp validation balanced-accuracy gain on the title task persists when any single component is removed. This omission prevents verification that the class-balance-aware elements, rather than incidental implementation differences, produce the observed effects.
- [Results (abstract task, MacBERT-base)] The McNemar test is reported only on the validation split (p=0.023); the lockbox results are described as approximately neutral for accuracy. Without a corresponding statistical test or confidence interval on the lockbox split, the claim of consistent improvement across both splits rests on point estimates whose reliability cannot be fully assessed.
minor comments (2)
- [Abstract] The abstract introduces 'weak Balanced Softmax' without a forward reference to its precise formulation or the value of the weighting hyperparameter; adding the relevant equation number from the methods section would improve clarity.
- [Experimental setup] The manuscript should include the exact number of runs or seeds used to obtain the reported accuracy figures, as single-run results with small deltas (0.49–0.83 pp) are sensitive to random variation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the practical relevance, use of a lockbox set, and bounded claims in our work. We address each major comment below with clarifications on the experimental protocol and commitments to revisions that strengthen reproducibility and component analysis without altering the core claims.
read point-by-point responses
-
Referee: [Methods / Training procedure description] The attribution of the reported accuracy lifts (0.83 pp validation, 0.49 pp lockbox for MacBERT-base on the abstract task) to the gated tail-prior, weak Balanced Softmax, and FGM rests on the assumption that data preprocessing, hyperparameter search, early-stopping, and random seeds are identical between AutoTail-BSFGM and the label-smoothed baseline. The manuscript provides no explicit statement or table confirming that hyperparameter tuning was performed under the same protocol or that the same seeds were used; this is load-bearing for the causal claim in the abstract and results.
Authors: The hyperparameter search, early-stopping criteria, data preprocessing steps, optimizer settings, and random seeds were identical between the label-smoothed baseline and AutoTail-BSFGM, as the proposed method modifies only the training objective and loss terms while preserving the model architecture, batch size, learning rate schedule, and evaluation protocol. We acknowledge that the manuscript lacks an explicit statement confirming this shared protocol. We will add a new subsection under Methods titled 'Shared Experimental Protocol' that details the common settings and includes a table listing all hyperparameters, seeds, and stopping criteria used for both methods. revision: yes
-
Referee: [Experimental results / Ablation analysis] No ablation experiments are reported that isolate the contribution of each component (gated tail-prior adjustment, weak Balanced Softmax auxiliary loss, FGM). For instance, it is not shown whether the +2.64 pp validation balanced-accuracy gain on the title task persists when any single component is removed. This omission prevents verification that the class-balance-aware elements, rather than incidental implementation differences, produce the observed effects.
Authors: We agree that ablation studies are required to attribute effects to individual components. We will perform and report a full set of ablations on both tasks, including single-component removals (no gated tail-prior, no weak Balanced Softmax, no FGM) and pairwise combinations, measuring impact on accuracy and balanced accuracy for validation and lockbox splits. These results, along with a discussion of each component's marginal contribution, will be added to the Experimental Results section. revision: yes
-
Referee: [Results (abstract task, MacBERT-base)] The McNemar test is reported only on the validation split (p=0.023); the lockbox results are described as approximately neutral for accuracy. Without a corresponding statistical test or confidence interval on the lockbox split, the claim of consistent improvement across both splits rests on point estimates whose reliability cannot be fully assessed.
Authors: The McNemar test was applied to the validation split because it served as the primary development set for observing the signal during method development. The lockbox split, being strictly held-out, shows smaller point-estimate gains that we already describe as bounded. We will add a pooled paired McNemar test (or bootstrap confidence intervals) on the lockbox predictions and update the Results section to report the outcome, noting any lack of significance as further evidence of the bounded nature of the improvements. revision: yes
Circularity Check
No circularity: empirical gains measured on held-out data with external test
full rationale
The paper reports accuracy improvements on validation and lockbox splits using McNemar tests. No derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. The method is described as changing only training objective while keeping inference identical to baseline; results are externally falsifiable on held-out sets. This matches the default expectation of no significant circularity for empirical ML papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of the Association for Information Science and Technology , volume =
Scaling Research Aim Identification: Language Models for Classifying Scientific and Societal-Oriented Studies , author =. Journal of the Association for Information Science and Technology , volume =. 2025 , doi =
2025
-
[2]
Science , volume =
Citation Analysis as a Tool in Journal Evaluation , author =. Science , volume =. 1972 , doi =
1972
-
[3]
1976 , note =
Evaluative Bibliometrics: The Use of Publication and Citation Analysis in the Evaluation of Scientific Activity , author =. 1976 , note =
1976
-
[4]
Journal of the Association for Information Science and Technology , volume =
Growth Rates of Modern Science: A Bibliometric Analysis Based on the Number of Publications and Cited References , author =. Journal of the Association for Information Science and Technology , volume =. 2015 , doi =
2015
-
[5]
Science , volume =
Science of Science , author =. Science , volume =. 2018 , doi =
2018
-
[6]
Journal of the American Society for Information Science and Technology , volume =
A New Methodology for Constructing a Publication-Level Classification System of Science , author =. Journal of the American Society for Information Science and Technology , volume =. 2012 , doi =
2012
-
[7]
Journal of the Association for Information Science and Technology , volume =
Creation of a Highly Detailed, Dynamic, Global Model and Map of Science , author =. Journal of the Association for Information Science and Technology , volume =. 2014 , doi =
2014
-
[8]
2022 , url =
Li, Yudong and Zhang, Yuqing and Zhao, Zhe and Shen, Linlin and Liu, Weijie and Mao, Weiquan and Zhang, Hui , booktitle =. 2022 , url =
2022
-
[9]
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics , pages =
A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents , author =. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics , pages =. 2018 , doi =
2018
-
[10]
2019 , doi =
Beltagy, Iz and Lo, Kyle and Cohan, Arman , booktitle =. 2019 , doi =
2019
-
[11]
, booktitle =
Lo, Kyle and Wang, Lucy Lu and Neumann, Mark and Kinney, Rodney and Weld, Daniel S. , booktitle =. 2020 , doi =
2020
-
[12]
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics , pages =
Construction of the Literature Graph in Semantic Scholar , author =. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics , pages =. 2018 , doi =
2018
-
[13]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages =
Multi-Task Identification of Entities, Relations, and Coreference for Scientific Knowledge Graph Construction , author =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages =. 2018 , doi =
2018
-
[14]
2019 , doi =
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle =. 2019 , doi =
2019
-
[15]
2019 , url =
Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin , journal =. 2019 , url =
2019
-
[16]
Pre-Training With Whole Word Masking for
Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing , journal =. Pre-Training With Whole Word Masking for. 2021 , doi =
2021
-
[17]
Revisiting Pre-Trained Models for
Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Wang, Shijin and Hu, Guoping , booktitle =. Revisiting Pre-Trained Models for. 2020 , doi =
2020
-
[18]
IEEE Transactions on Knowledge and Data Engineering , volume =
Learning from Imbalanced Data , author =. IEEE Transactions on Knowledge and Data Engineering , volume =. 2009 , doi =
2009
-
[19]
Neural Networks , volume =
A Systematic Study of the Class Imbalance Problem in Convolutional Neural Networks , author =. Neural Networks , volume =. 2018 , doi =
2018
-
[20]
Proceedings of the IEEE International Conference on Computer Vision , pages =
Focal Loss for Dense Object Detection , author =. Proceedings of the IEEE International Conference on Computer Vision , pages =. 2017 , doi =
2017
-
[21]
Advances in Neural Information Processing Systems , pages =
Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss , author =. Advances in Neural Information Processing Systems , pages =. 2019 , url =
2019
-
[22]
Advances in Neural Information Processing Systems , year =
Balanced Meta-Softmax for Long-Tailed Visual Recognition , author =. Advances in Neural Information Processing Systems , year =
-
[23]
International Conference on Learning Representations , year =
Long-tail Learning via Logit Adjustment , author =. International Conference on Learning Representations , year =
-
[24]
International Conference on Learning Representations , year =
Explaining and Harnessing Adversarial Examples , author =. International Conference on Learning Representations , year =
-
[25]
arXiv preprint arXiv:1605.07725 , year =
Adversarial Training Methods for Semi-Supervised Text Classification , author =. arXiv preprint arXiv:1605.07725 , year =
-
[26]
2020 , url =
Zhu, Chen and Cheng, Yu and Gan, Zhe and Sun, Siqi and Goldstein, Tom and Liu, Jingjing , booktitle =. 2020 , url =
2020
-
[27]
2020 , doi =
Jiang, Haoming and He, Pengcheng and Chen, Weizhu and Liu, Xiaodong and Gao, Jianfeng and Zhao, Tuo , booktitle =. 2020 , doi =
2020
-
[28]
2021 , url =
Liang, Xiaobo and Wu, Lijun and Li, Juntao and Wang, Yue and Meng, Qi and Qin, Tao and Chen, Wei and Zhang, Min and Liu, Tie-Yan , booktitle =. 2021 , url =
2021
-
[29]
Neural Computation , volume =
Approximate Statistical Tests for Comparing Supervised Classification Learning Algorithms , author =. Neural Computation , volume =. 1998 , doi =
1998
-
[30]
2023 , doi =
Singh, Amanpreet and D'Arcy, Mike and Cohan, Arman and Downey, Doug and Feldman, Sergey , booktitle =. 2023 , doi =
2023
-
[31]
2024 , url =
Ahmad, Raia Abu and Borisova, Ekaterina and Rehm, Georg , booktitle =. 2024 , url =
2024
-
[32]
Proceedings of the Fourth Workshop on Scholarly Document Processing , pages =
Artificial Intuition: Efficient Classification of Scientific Abstracts , author =. Proceedings of the Fourth Workshop on Scholarly Document Processing , pages =. 2024 , url =
2024
-
[33]
Proceedings of the First Workshop on Advancing Natural Language Processing for Wikipedia , pages =
Multi-Label Field Classification for Scientific Documents Using Expert and Crowd-Sourced Knowledge , author =. Proceedings of the First Workshop on Advancing Natural Language Processing for Wikipedia , pages =. 2024 , doi =
2024
-
[34]
Proceedings of the 7th International Conference on Natural Language and Speech Processing , pages =
Efficient Few-Shot Learning for Multi-Label Classification of Scientific Documents with Many Classes , author =. Proceedings of the 7th International Conference on Natural Language and Speech Processing , pages =. 2024 , url =
2024
-
[35]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages =
A Survey of Methods for Addressing Class Imbalance in Deep-Learning Based Natural Language Processing , author =. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages =. 2023 , doi =
2023
-
[36]
2024 , doi =
You, Zhiwen and Han, Kanyao and Zhu, Haotian and Ludaescher, Bertram and Diesner, Jana , booktitle =. 2024 , doi =
2024
-
[37]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
A Comprehensive Survey of Scientific Large Language Models and Their Applications in Scientific Discovery , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =. 2024 , doi =
2024
-
[38]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation , pages =
Language Models for Text Classification: Is In-Context Learning Enough? , author =. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation , pages =. 2024 , url =
2024
-
[39]
2023 , doi =
Chen, Canyu and Shu, Kai , booktitle =. 2023 , doi =
2023
-
[40]
2023 , doi =
Wang, Yau-Shian and Chi, Ta-Chung and Zhang, Ruohong and Yang, Yiming , booktitle =. 2023 , doi =
2023
-
[41]
Findings of the Association for Computational Linguistics: EACL 2023 , pages =
Long-Tailed Extreme Multi-Label Text Classification by the Retrieval of Generated Pseudo Label Descriptions , author =. Findings of the Association for Computational Linguistics: EACL 2023 , pages =. 2023 , doi =
2023
-
[42]
2026 , doi =
Lu, Wayne and Cui, Xiaoxi , booktitle =. 2026 , doi =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.