Speedrunning Tabular Foundation Model Pretraining
Pith reviewed 2026-06-28 11:36 UTC · model grok-4.3
The pith
A community speedrun protocol reaches tabular foundation model pretraining targets in 0.92 minutes, an 81x improvement over the baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
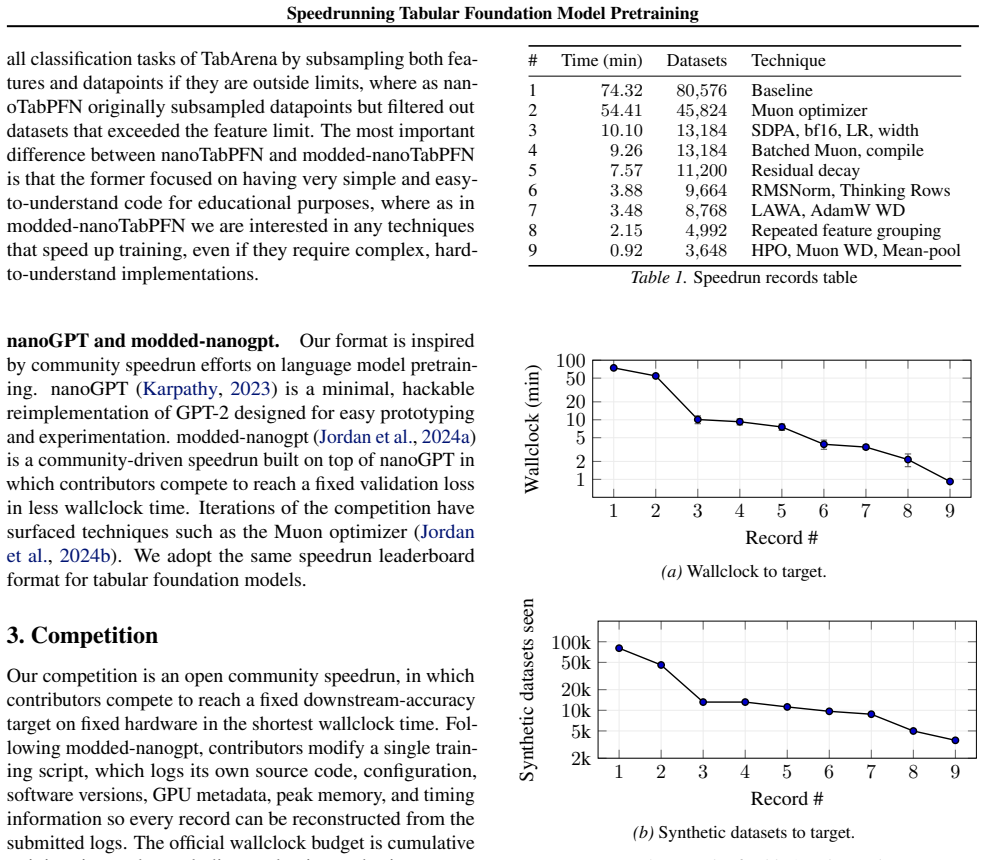
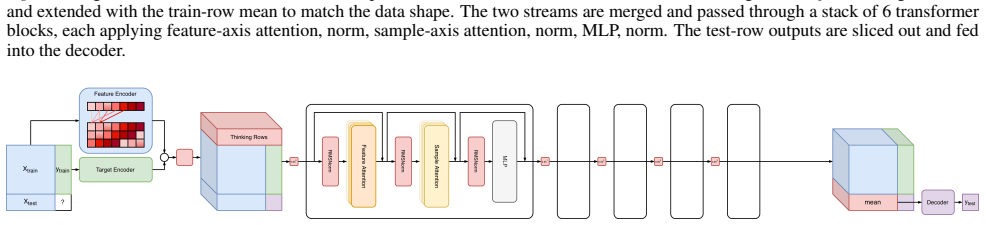
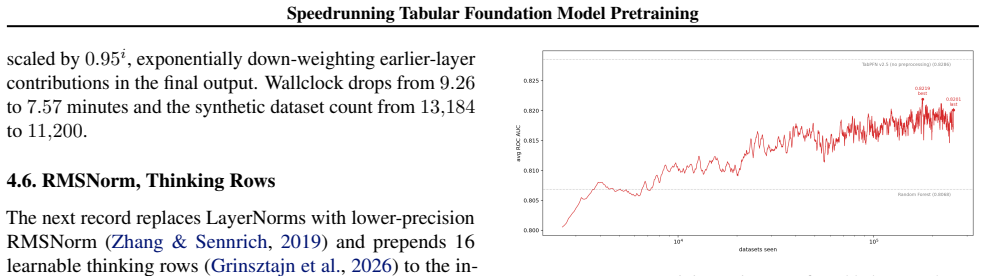
By establishing a speedrun challenge with a fixed ROC AUC target on subsampled TabArena and one NVIDIA L40S GPU, the authors create a standardized protocol that lets participants modify the training script and compete directly on pretraining time, with the best entry currently achieving the target in 0.92 minutes versus the 74.32-minute baseline while requiring 22x fewer synthetic datasets.
What carries the argument
The speedrun protocol: a fixed downstream performance target, single-file training script, and public leaderboard that enables verification and stacking of pretraining modifications.
If this is right
- New ideas for architectures, priors, or optimization can be tested by submitting modified scripts and measuring time to target.
- Successful modifications can be combined over successive leaderboard updates.
- Pretraining experiments become feasible on modest hardware, shortening research cycles.
- The community gains a shared, auditable record of efficiency gains.
Where Pith is reading between the lines
- The format could be adapted to other foundation-model domains where pretraining cost is the main bottleneck.
- The winning entry's use of far less data points to data efficiency as a major route to speedups.
- Widespread adoption might shift emphasis from scaling compute to measuring and improving training efficiency.
Load-bearing premise
That reaching the fixed ROC AUC target on subsampled TabArena reliably indicates overall pretraining quality regardless of how the training script is altered.
What would settle it
A script that hits the target faster yet produces models with lower performance on a wider collection of tabular tasks or real datasets outside the speedrun benchmark.
Figures


read the original abstract
Pretraining cost is a major bottleneck for research on tabular foundation models, slowing the iteration cycle for new architectures, priors, and optimization ideas. Yet the community lacks a simple way to compare and accumulate pretraining speedups. We introduce a community speedrun for nanoTabPFN: contributors modify a single-file training script and compete to reach a fixed downstream ROC AUC target on subsampled TabArena using one NVIDIA L40S GPU. The current best record reaches the target in 0.92 minutes, an 81x speedup over the 74.32 minute baseline while using 22x fewer synthetic datasets. The speedrun format provides a simple protocol for the community to add, verify, and stack pretraining improvements, with the leaderboard open to contributions. Code and records are available at https://github.com/borawhocodess/modded-nanotabpfn.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a community 'speedrun' benchmark for pretraining nanoTabPFN tabular foundation models. Participants modify a single-file training script to reach a fixed downstream ROC AUC target on a subsampled TabArena dataset using one NVIDIA L40S GPU. The current record achieves the target in 0.92 minutes (81x speedup over the 74.32-minute baseline) while using 22x fewer synthetic datasets. The format is intended to enable the community to add, verify, and stack pretraining improvements via an open leaderboard, with code available at the provided GitHub link.
Significance. If the evaluation protocol proves robust, the speedrun format could meaningfully lower iteration costs for tabular foundation model research by providing a simple, low-resource, community-verifiable benchmark that accumulates incremental gains. The open code and explicit empirical record (wall-clock time and dataset count) are strengths that support reproducibility and stacking of improvements.
major comments (1)
- [Abstract] Abstract: The headline claim of an 81x speedup and a useful community protocol rests on the assumption that a fixed ROC AUC target on the subsampled TabArena remains a stable, comparable proxy for pretraining quality under arbitrary modifications to data generation, optimization, architecture, or regularization. No analysis, ablation, or verification is provided that this specific target and subsample do not admit exploits of idiosyncrasies (e.g., the exact threshold, GPU timing, or distribution shift) without producing generally better foundation models; this is load-bearing for the central empirical contribution.
minor comments (1)
- The manuscript would benefit from an explicit section detailing the precise measurement protocol, baseline implementation details, dataset subsampling procedure, and any exclusion rules for the speedrun to allow independent reproduction and extension.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of validating the evaluation protocol. The concern about the fixed ROC AUC target serving as a robust proxy is substantive and directly relevant to the benchmark's long-term value. We address it point-by-point below and commit to revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of an 81x speedup and a useful community protocol rests on the assumption that a fixed ROC AUC target on the subsampled TabArena remains a stable, comparable proxy for pretraining quality under arbitrary modifications to data generation, optimization, architecture, or regularization. No analysis, ablation, or verification is provided that this specific target and subsample do not admit exploits of idiosyncrasies (e.g., the exact threshold, GPU timing, or distribution shift) without producing generally better foundation models; this is load-bearing for the central empirical contribution.
Authors: We agree that the stability of the chosen target and subsample is load-bearing and that the manuscript provides no explicit ablations or verification against potential exploits. The target was selected in preliminary runs to be reachable by the baseline yet require non-trivial improvements; the subsample size was chosen for computational feasibility on a single L40S. However, we did not test sensitivity to the precise AUC threshold, timing variance across GPU runs, or correlation with performance on held-out datasets or shifted distributions. In revision we will add a dedicated subsection under 'Evaluation Protocol' that (1) reports the exact target selection procedure, (2) includes a small set of sanity checks (re-evaluating the current record on two additional TabArena splits and on a different downstream metric), and (3) explicitly discusses known limitations and the role of the open leaderboard in surfacing future exploits. We view these additions as necessary to support the central claim. revision: yes
Circularity Check
No circularity; empirical benchmark with no derivation chain
full rationale
The paper introduces a community speedrun protocol for tabular foundation model pretraining and reports an empirical wall-clock record (0.92 min vs baseline). No mathematical derivations, equations, parameter fittings, predictions, or self-citation chains are present in the provided text. The contribution is a benchmark setup and leaderboard, not a claimed derivation that reduces to its inputs. This is self-contained against external benchmarks by design.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models , author=. 2026 , eprint=
2026
-
[2]
Deep Neural Networks and Tabular Data: A Survey , journal =
Borisov, Vadim and Leemann, Tobias and Se. Deep Neural Networks and Tabular Data: A Survey , journal =. 2024 , doi =
2024
-
[3]
Proceedings of the 41st International Conference on Machine Learning , series =
van Breugel, Boris and van der Schaar, Mihaela , title =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , url =
2024
-
[4]
The Eleventh International Conference on Learning Representations (ICLR) , publisher =
Hollmann, Noah and M. The Eleventh International Conference on Learning Representations (ICLR) , publisher =. 2023 , url =
2023
-
[5]
Accurate predictions on small data with a tabular foundation model , journal =
Hollmann, Noah and M. Accurate predictions on small data with a tabular foundation model , journal =. 2025 , doi =
2025
-
[6]
Proceedings of the 42nd International Conference on Machine Learning , series =
Qu, Jingang and Holzm. Proceedings of the 42nd International Conference on Machine Learning , series =. 2025 , url =
2025
-
[7]
arXiv preprint arXiv:2602.11139 , year =
Qu, Jingang and Holzm. arXiv preprint arXiv:2602.11139 , year =
-
[8]
2025 , eprint =
Zhang, Xingxuan and Ren, Gang and Yu, Han and Yuan, Hao and Wang, Hui and Li, Jiansheng and Wu, Jiayun and Mo, Lang and Mao, Li and Hao, Mingchao and Dai, Ningbo and Xu, Renzhe and Li, Shuyang and Zhang, Tianyang and He, Yue and Wang, Yuanrui and Zhang, Yunjia and Xu, Zijing and others , title =. 2025 , eprint =
2025
-
[9]
2025 , eprint =
Pfefferle, Alexander and Hog, Johannes and Purucker, Lennart and Hutter, Frank , title =. 2025 , eprint =
2025
-
[10]
Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track , year =
Erickson, Nick and Purucker, Lennart and Tschalzev, Andrej and Holzm. Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track , year =
-
[11]
2024 , url =
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , url =
2024
-
[12]
2026 , url =
Karpathy, Andrej , title =. 2026 , url =
2026
-
[13]
2023 , url =
Karpathy, Andrej , title =. 2023 , url =
2023
-
[14]
modded-nanogpt: Speedrunning the
Jordan, Keller and Bernstein, Jeremy and Rappazzo, Brendan and. modded-nanogpt: Speedrunning the. 2024 , url =
2024
-
[15]
Proceedings of the 40th International Conference on Machine Learning , series =
Geiping, Jonas and Goldstein, Tom , title =. Proceedings of the 40th International Conference on Machine Learning , series =. 2023 , url =
2023
-
[16]
and Golestan, Keyvan and Yu, Guangwei and Caterini, Anthony L
Ma, Junwei and Thomas, Valentin and Hosseinzadeh, Rasa and Labach, Alex and Kamkari, Hamidreza and Cresswell, Jesse C. and Golestan, Keyvan and Yu, Guangwei and Caterini, Anthony L. and Volkovs, Maksims , title =. The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS) , year =
-
[17]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Zhang, Biao and Sennrich, Rico , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2019 , url =
2019
-
[18]
2022 , eprint =
Kaddour, Jean , title =. 2022 , eprint =
2022
-
[19]
First Conference on Language Modeling (COLM) , year =
Sanyal, Sunny and Neerkaje, Atula Tejaswi and Kaddour, Jean and Kumar, Abhishek and Sanghavi, Sujay , title =. First Conference on Language Modeling (COLM) , year =
-
[20]
, title =
Ba, Jimmy Lei and Kiros, Jamie Ryan and Hinton, Geoffrey E. , title =. 2016 , eprint =
2016
-
[21]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Paszke, Adam and Gross, Sam and Massa, Francisco and Lerer, Adam and Bradbury, James and Chanan, Gregory and Killeen, Trevor and Lin, Zeming and Gimelshein, Natalia and Antiga, Luca and Desmaison, Alban and K. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2019 , url =
2019
-
[22]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Defazio, Aaron and Yang, Xingyu Alice and Mehta, Harsh and Mishchenko, Konstantin and Khaled, Ahmed and Cutkosky, Ashok , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.