When to Re-Plan: Subgoal Persistence in Hierarchical Latent Reasoning
Pith reviewed 2026-07-01 07:49 UTC · model grok-4.3
The pith
Moderate subgoal persistence periods improve latent reasoning performance over frequent or long re-planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
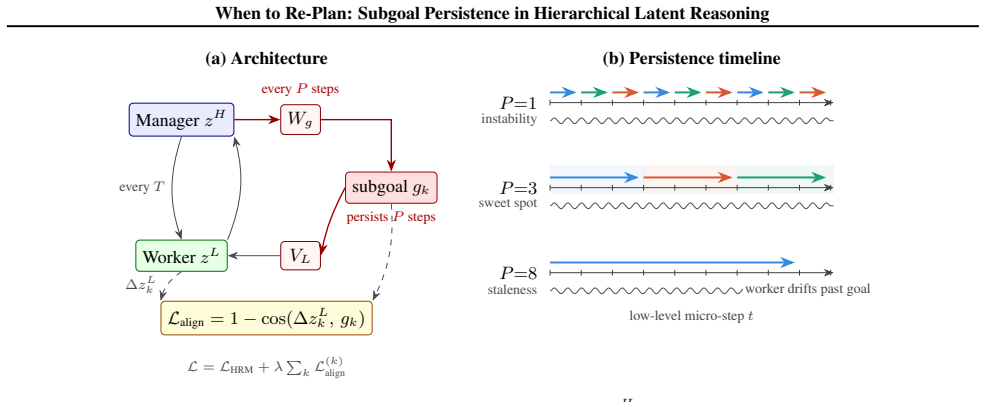
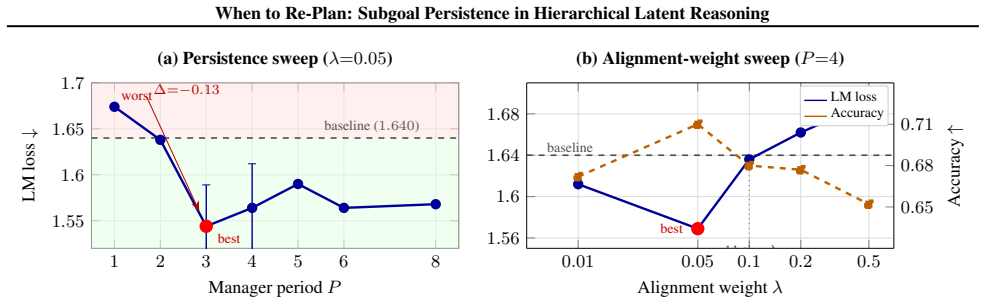
Extending the Hierarchical Reasoning Model with a feudal-style manager-worker interface, in which a slow high-level module emits a normalized directional subgoal that persists for P low-level steps, biases the worker's hidden-state updates and supplies an intrinsic cosine alignment loss; moderate persistence periods P in [3,6] consistently outperform both very frequent re-planning (P=1) and very long horizons, with minimum LM loss at P=3.
What carries the argument
The persistence duration P of the normalized directional subgoal emitted by the manager module, which biases worker hidden-state updates across multiple steps and supplies a cosine alignment loss.
If this is right
- Moderate persistence allows multi-step computational structure to form inside hidden states before the next re-plan.
- Very frequent re-planning prevents coherence while overly long horizons allow plans to go stale.
- The intrinsic alignment weight has a complementary narrow optimum near 0.05.
- When the alignment signal exceeds its optimum, the source of interference is learned directional structure rather than architectural capacity or the auxiliary loss alone.
Where Pith is reading between the lines
- The same persistence knob may affect performance in other hierarchical latent models on tasks requiring longer compositional chains.
- Varying the base architecture while holding the manager-worker interface fixed would test whether the [3,6] sweet spot is architecture-dependent.
- The design principle could be tested in non-latent settings by inserting analogous persistence constraints into explicit planning loops.
Load-bearing premise
Performance differences arise specifically from the persistence of the normalized directional subgoal biasing worker hidden-state updates and the cosine alignment loss, rather than from unexamined interactions with the base HRM architecture, training procedure, or task features.
What would settle it
Re-running the ablation series while removing only the persistence mechanism (keeping subgoal injection and the alignment loss) would show whether the U-shaped loss curve over P flattens or disappears.
Figures
read the original abstract
Long-horizon reasoning requires a system to commit to medium-horizon intent without becoming rigid: re-plan too often and computation never coheres into multi-step structure; commit too long and the plan goes stale. We study this stability-adaptivity tradeoff in the latent reasoning setting, where multi-step computation occurs inside hidden state rather than externalized token traces. We extend the Hierarchical Reasoning Model (HRM) with a feudal-style manager-worker interface: a slow high-level module periodically emits a normalized directional subgoal that persists for P low-level steps, biasing the worker's hidden-state updates and supplying an intrinsic cosine alignment loss. On ARC and ConceptARC, we find that subgoal persistence -- not subgoal injection alone -- is the central knob: moderate periods P in [3, 6] consistently outperform both very frequent (P=1) and very long horizons, with a clear minimum LM loss at P=3 (1.544 vs. 1.674 at P=1, 1.640 baseline; replicated over 5 seeds at mean 1.595, std 0.045). The intrinsic alignment weight lambda shows a complementary narrow optimum (lambda approximately 0.05). A controlled ablation at past-sweet-spot lambda isolates learned directional structure -- not architectural capacity or auxiliary loss alone -- as the source of interference when the alignment signal exceeds its optimum. Together these findings implicate a design principle for compositional planning in latent reasoning systems: medium-horizon intent must be coherent across enough computational steps for compositional structure to form.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends the Hierarchical Reasoning Model (HRM) with a feudal-style manager-worker interface in which a high-level module periodically emits a normalized directional subgoal that persists for P low-level steps. This subgoal biases the worker's hidden-state updates and supplies an intrinsic cosine alignment loss weighted by lambda. Experiments on ARC and ConceptARC report that moderate persistence periods P in [3,6] minimize LM loss relative to P=1 or longer horizons (minimum at P=3: 1.544 vs. 1.674 at P=1 and 1.640 baseline), with results replicated over 5 seeds (mean 1.595, std 0.045). Lambda shows a narrow optimum near 0.05. A controlled ablation at the sweet-spot lambda is presented as isolating learned directional structure rather than capacity or auxiliary loss alone, supporting a design principle that medium-horizon intent must persist across enough steps for compositional structure to form.
Significance. If the central experimental claims hold after clarification of controls, the work supplies concrete evidence on the stability-adaptivity tradeoff in latent hierarchical reasoning. The replication across seeds and the ablation isolating the alignment signal constitute strengths that ground the claim that persistence (rather than injection alone) is the operative mechanism. This could inform architectural choices for compositional planning in systems that perform multi-step computation inside hidden states.
major comments (2)
- [Abstract] Abstract: the claim that 'subgoal persistence -- not subgoal injection alone -- is the central knob' and that the ablation 'isolates learned directional structure' rests on the controlled ablation at lambda approximately 0.05. However, the manuscript provides no description of how base HRM update rules, optimizer schedule, or ARC-specific features (e.g., grid symmetries) are held constant across the P sweep. Without these controls, the observed minimum at P=3 could arise from unexamined interactions with the base architecture or task structure rather than the normalized directional biasing and cosine loss.
- [Abstract] Abstract: the baseline loss of 1.640 is contrasted with both P=1 (1.674) and the P=3 result, but it is not stated whether the baseline corresponds to the unmodified HRM, to P=1 without the alignment loss, or to another condition. This ambiguity weakens the separation between 'injection alone' and the persistence mechanism.
minor comments (2)
- The replication over 5 seeds with reported mean and standard deviation is a positive feature; adding error bars to any P-sweep or lambda-sweep figures and a statistical test for the reported differences would further strengthen the quantitative claims.
- Notation for the persistence period P and alignment weight lambda is introduced in the abstract; ensure consistent definition and units (if any) when first appearing in the methods or experimental sections.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on experimental clarity. We address each major comment below and will revise the manuscript to improve transparency of controls and baseline definitions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'subgoal persistence -- not subgoal injection alone -- is the central knob' and that the ablation 'isolates learned directional structure' rests on the controlled ablation at lambda approximately 0.05. However, the manuscript provides no description of how base HRM update rules, optimizer schedule, or ARC-specific features (e.g., grid symmetries) are held constant across the P sweep. Without these controls, the observed minimum at P=3 could arise from unexamined interactions with the base architecture or task structure rather than the normalized directional biasing and cosine loss.
Authors: We agree that the abstract should explicitly confirm the controls. All conditions in the P sweep use identical base HRM update rules, optimizer schedule, learning rate, batch size, and ARC preprocessing steps (including handling of grid symmetries). Only P and lambda are varied. We will add a clarifying sentence to the abstract and methods to state that these elements are held constant, ensuring the minimum at P=3 is attributable to the persistence mechanism. revision: yes
-
Referee: [Abstract] Abstract: the baseline loss of 1.640 is contrasted with both P=1 (1.674) and the P=3 result, but it is not stated whether the baseline corresponds to the unmodified HRM, to P=1 without the alignment loss, or to another condition. This ambiguity weakens the separation between 'injection alone' and the persistence mechanism.
Authors: The baseline of 1.640 is the unmodified original HRM without the feudal manager or cosine alignment loss. P=1 corresponds to subgoal injection without persistence. We will revise the abstract to explicitly define the baseline as the unmodified HRM, thereby sharpening the distinction between injection alone and the persistence effect. revision: yes
Circularity Check
No significant circularity; results from direct experiments
full rationale
The paper's claims rest on empirical measurements of LM loss across P values and lambda on ARC/ConceptARC tasks using an HRM extension. Central findings (minimum at P=3, lambda~0.05) are obtained from hyperparameter sweeps and ablations whose outcomes are measured independently rather than defined by construction or reduced to fitted inputs. No equations, self-citations, or uniqueness theorems appear in the provided text as load-bearing steps. The derivation chain consists of architectural description plus controlled runs whose results do not loop back to the inputs by definition.
Axiom & Free-Parameter Ledger
free parameters (2)
- persistence period P =
3
- alignment weight lambda =
0.05
axioms (2)
- domain assumption The Hierarchical Reasoning Model (HRM) is a valid base architecture for studying latent reasoning.
- domain assumption The feudal-style manager-worker interface can be effectively implemented in latent space.
Reference graph
Works this paper leans on
-
[1]
2011 , publisher =
Thinking, Fast and Slow , author =. 2011 , publisher =
2011
-
[2]
Perspectives on Psychological Science , volume =
Dual-Process Theories of Higher Cognition: Advancing the Debate , author =. Perspectives on Psychological Science , volume =
-
[3]
Advances in Neural Information Processing Systems , volume =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , volume =
-
[4]
Hierarchical Reasoning Model , author =. arXiv preprint arXiv:2506.21734 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Adaptive Computation Time for Recurrent Neural Networks
Adaptive Computation Time for Recurrent Neural Networks , author =. arXiv preprint arXiv:1603.08983 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Vezhnevets, Alexander Sasha and Osindero, Simon and Schaul, Tom and Heess, Nicolas and Jaderberg, Max and Silver, David and Kavukcuoglu, Koray , booktitle =
-
[7]
and Precup, Doina and Singh, Satinder , journal =
Sutton, Richard S. and Precup, Doina and Singh, Satinder , journal =. Between
-
[8]
Moskvichev, Arseny and Odouard, Victor Vikram and Mitchell, Melanie , journal =. The
-
[9]
On the Measure of Intelligence
On the Measure of Intelligence , author =. arXiv preprint arXiv:1911.01547 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[10]
Reinforcement Learning: An Introduction , author =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.