KletterMix: Climbing Toward High-Quality German Pretraining Data
Pith reviewed 2026-06-28 10:19 UTC · model grok-4.3
The pith
Translating a top English pretraining corpus into German while keeping document boundaries and diversity produces data that improves downstream German evaluations over existing corpora.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
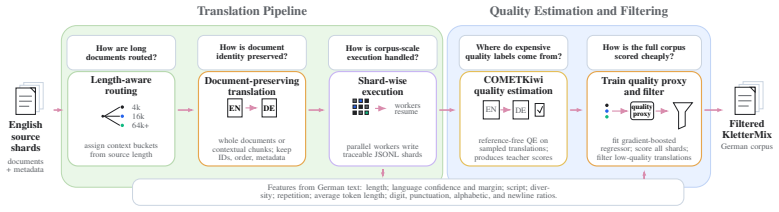
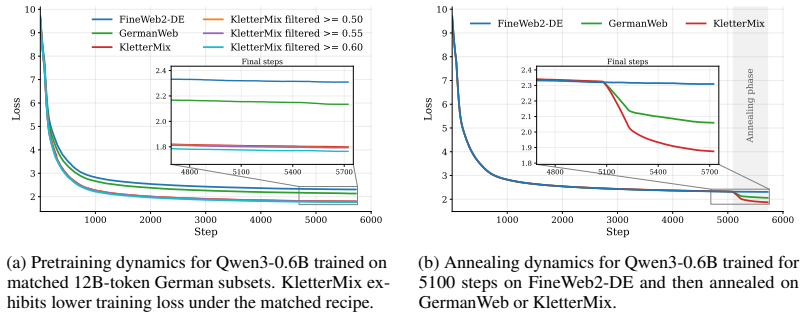
KletterMix is built by translating a state-of-the-art English pretraining corpus into German while preserving document boundaries, metadata, source structure, and topical diversity. Using COMETKiwi, the translated documents achieve strong quality across diverse domains. Through controlled pretraining and annealing ablations against established German corpora, models trained on KletterMix achieve measurable improvements on German-language downstream evaluations.
What carries the argument
The translation pipeline that converts an English pretraining corpus into German while preserving document boundaries, metadata, and topical diversity.
If this is right
- Models trained on KletterMix achieve measurable improvements on German-language downstream evaluations compared to established German corpora.
- Careful translation preserves much of the semantic and stylistic richness of the original English corpus.
- The resulting German corpus matches the scale and diversity of modern pretraining datasets while enabling direct comparison to its English source.
- KletterMix serves as a documented, reusable dataset artifact for the NLP community.
Where Pith is reading between the lines
- The same translation approach with structure preservation could be tested on other languages that lack high-quality native pretraining data.
- Combining KletterMix with native German sources might yield further gains, though the paper does not test this mixture.
- The downstream gains might vary with model scale or different annealing schedules, providing a testable extension beyond the reported ablations.
- This construction method offers a way to create comparable multilingual pretraining sets without starting from scratch in each language.
Load-bearing premise
That translation quality scores from COMETKiwi together with preserved document boundaries and topical diversity are enough to make the resulting data outperform existing German corpora in downstream model evaluations.
What would settle it
A controlled experiment in which models pretrained and annealed on KletterMix show no improvement or worse performance than models trained on established German corpora on the same German downstream benchmarks would falsify the central claim.
Figures
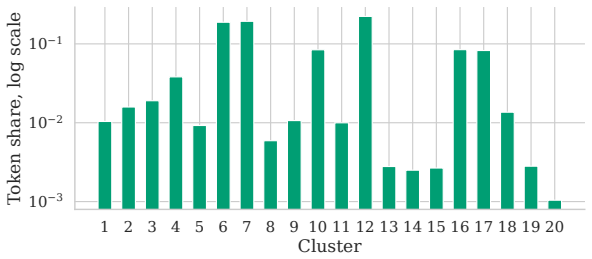
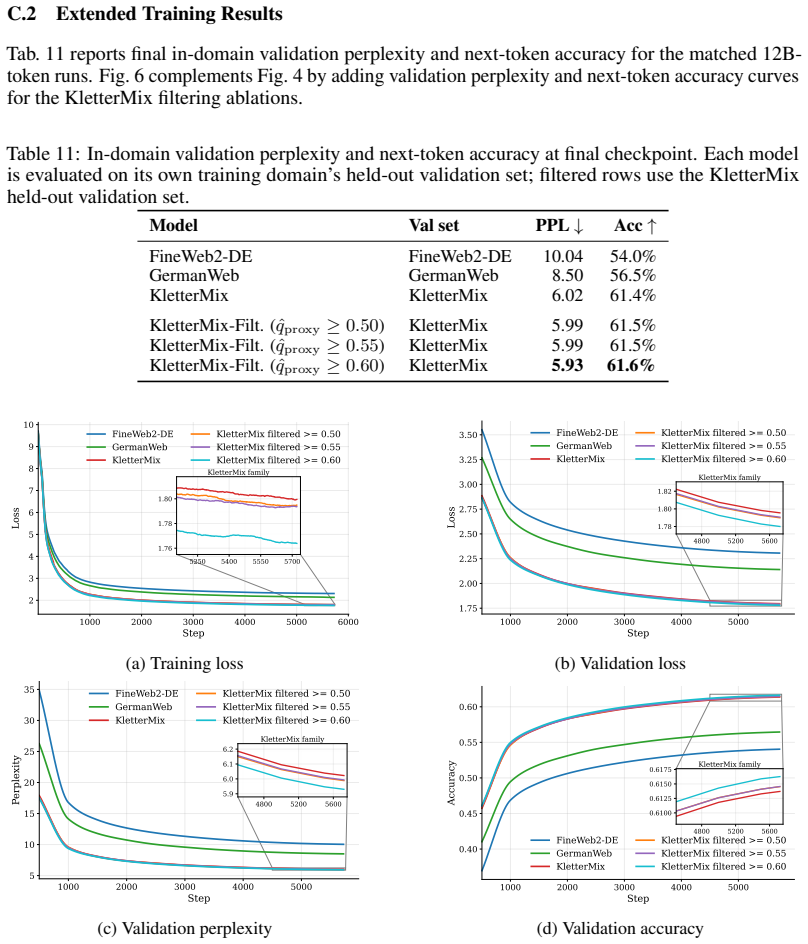
read the original abstract
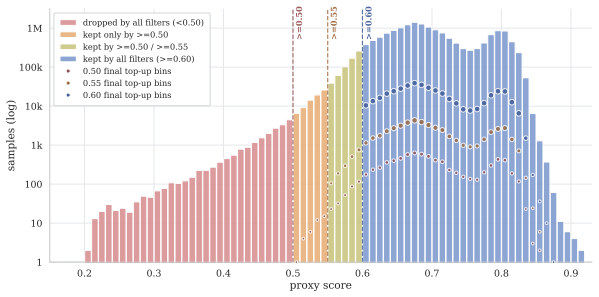
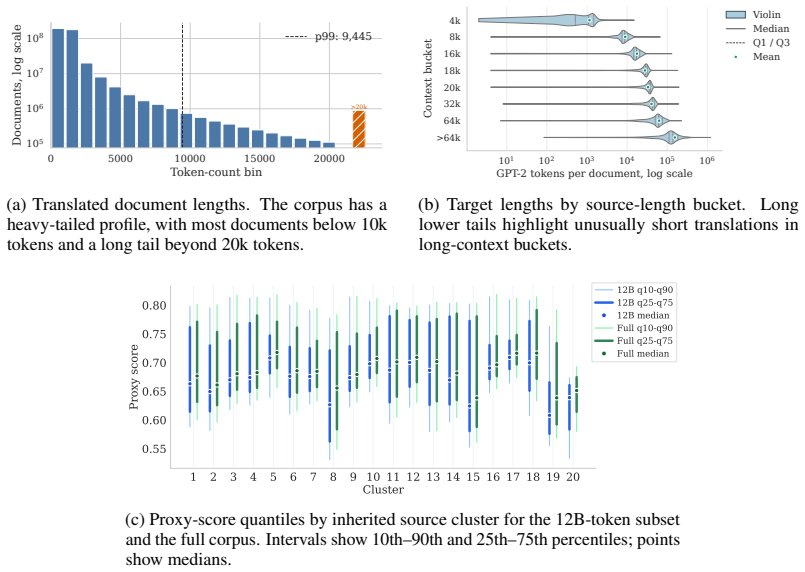
High-quality pretraining data is a central ingredient in modern language models, but German-language resources remain far less developed than their English counterparts: they are often smaller, less carefully curated, weakly documented, and rarely validated through controlled training experiments. We introduce KletterMix, a high-quality German corpus for language model pretraining and annealing, designed as a reusable dataset artifact for the natural language processing and modeling community. KletterMix is built by translating a state-of-the-art English pretraining corpus into German while preserving document boundaries, metadata, source structure, and topical diversity. This construction yields a German corpus with the scale and diversity of a modern pretraining dataset, while enabling direct comparison to its English source. We document the dataset through a broad set of corpus-level analyses, including translation quality, document length distributions, topic coverage, source composition, and geographic metadata. Using COMETKiwi, we show that the translated documents achieve strong quality across diverse domains, suggesting that careful translation can preserve much of the semantic and stylistic richness of the original corpus. Beyond dataset construction, we evaluate KletterMix as training data. Through controlled pretraining and annealing ablations against established German corpora, we show that models trained on KletterMix achieve measurable improvements on German-language downstream evaluations. These results demonstrate that carefully curated translated data can substantially strengthen the German pretraining data ecosystem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KletterMix, a German pretraining and annealing corpus constructed by translating a state-of-the-art English corpus while preserving document boundaries, metadata, source structure, and topical diversity. It documents corpus properties via analyses of translation quality (COMETKiwi), document lengths, topic coverage, and source composition, then reports that controlled pretraining and annealing ablations against established German corpora yield measurable gains on German-language downstream evaluations.
Significance. If the central experimental claims hold under matched conditions, the work would supply a large-scale, reusable, and directly comparable German dataset artifact that narrows the documented gap between English and German pretraining resources. The translation-plus-preservation approach, together with the emphasis on a community-reusable artifact, offers a concrete template for other languages and strengthens the case that high-quality translated data can improve downstream German LM performance.
major comments (1)
- [Experiments] Experiments section: the claim of 'controlled pretraining and annealing ablations' is load-bearing for the central result, yet the manuscript supplies no table or explicit statement confirming that total tokens seen, training steps, sequence length, optimizer state, and annealing schedule are identical across the KletterMix condition and all baseline German corpora. Without such equalization, observed downstream gains cannot be attributed to translation quality or preserved document structure rather than differences in effective compute or data volume.
minor comments (1)
- [Abstract] Abstract: the statement that models 'achieve measurable improvements' is not accompanied by any numerical deltas, error bars, or task list, which reduces the reader's ability to assess effect size before reaching the full experimental section.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The single major comment identifies a genuine gap in experimental documentation. We address it directly below and will revise the manuscript to include the requested controls.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the claim of 'controlled pretraining and annealing ablations' is load-bearing for the central result, yet the manuscript supplies no table or explicit statement confirming that total tokens seen, training steps, sequence length, optimizer state, and annealing schedule are identical across the KletterMix condition and all baseline German corpora. Without such equalization, observed downstream gains cannot be attributed to translation quality or preserved document structure rather than differences in effective compute or data volume.
Authors: We agree that the manuscript does not contain an explicit table or consolidated statement verifying that total tokens, training steps, sequence length, optimizer state, and annealing schedule were identical across all conditions. This documentation is necessary to support the claim of controlled ablations. We will add a new table (and accompanying text) in the Experiments section that lists these hyperparameters for the KletterMix runs and every baseline corpus, confirming they were matched. The revision will make the equalization explicit rather than implicit. revision: yes
Circularity Check
No circularity: empirical claims rest on external metrics and baselines
full rationale
The paper constructs KletterMix via translation of an external English corpus, documents it with COMETKiwi quality scores and corpus statistics, and reports downstream gains from controlled ablations against established German corpora. No equations, fitted parameters, or self-citations appear in the load-bearing steps. All evaluations use independent external benchmarks and prior corpora; the derivation chain does not reduce any result to a quantity defined by the authors' own prior work or by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Careful translation preserves semantic and stylistic richness sufficient for pretraining gains
Reference graph
Works this paper leans on
-
[1]
Mortensen, Noah A
Orevaoghene Ahia, Sachin Kumar, Hila Gonen, Jungo Kasai, David R. Mortensen, Noah A. Smith, and Yulia Tsvetkov. Do all languages cost the same? tokenization in the era of commer- cial language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Si...
2023
-
[2]
Teuken-7b-base & teuken-7b-instruct: Towards european llms
Mehdi Ali, Michael Fromm, Klaudia Thellmann, Jan Ebert, Alexander Arno Weber, Richard Rutmann, Charvi Jain, Max Lübbering, Daniel Steinigen, Johannes Leveling, Katrin Klug, Jasper Schulze Buschhoff, Lena Jurkschat, Hammam Abdelwahab, Benny Jörg Stein, Karl- Heinz Sylla, Pavel Denisov, Nicolo’ Brandizzi, Qasid Saleem, Anirban Bhowmick, Lennard Helmer, Chel...
2025
-
[3]
Occiglot at WMT24: european open-source large language models evaluated on translation
Eleftherios Avramidis, Annika Grützner-Zahn, Manuel Brack, Patrick Schramowski, Pedro Ortiz Suarez, Malte Ostendorff, Fabio Barth, Shushen Manakhimova, Vivien Macketanz, Georg Rehm, and Kristian Kersting. Occiglot at WMT24: european open-source large language models evaluated on translation. In Barry Haddow, Tom Kocmi, Philipp Koehn, and Christof Monz, ed...
2024
-
[4]
Bender and Batya Friedman
Emily M. Bender and Batya Friedman. Data statements for natural language processing: Toward mitigating system bias and enabling better science.Trans. Assoc. Comput. Linguistics, 6:587–604, 2018
2018
-
[5]
Burns, Letitia Parcalabescu, Stephan Wäldchen, Michael Barlow, Gregor Ziegltrum, V olker Stampa, Bastian Harren, and Björn Deiseroth
Thomas F. Burns, Letitia Parcalabescu, Stephan Wäldchen, Michael Barlow, Gregor Ziegltrum, V olker Stampa, Bastian Harren, and Björn Deiseroth. Aleph-alpha-germanweb: Improving german-language LLM pre-training with model-based data curation and synthetic data gen- eration. In Vera Demberg, Kentaro Inui, and Lluís Marquez, editors,Proceedings of the 19th C...
2026
-
[6]
Tyler A. Chang, Catherine Arnett, Abdelrahman Eldesokey, Abdelrahman Sadallah, Abeer Kashar, Abolade Daud, Abosede Grace Olanihun, Adamu Labaran Mohammed, Adeyemi Praise, Adhikarinayum Meerajita Sharma, Aditi Gupta, Afitab Iyigun, Afonso Simplício, Ahmed Essouaied, Aicha Chorana, Akhil Eppa, Akintunde Oladipo, Akshay Ramesh, Aleksei Dorkin, 11 Alfred Male...
Pith/arXiv arXiv 2025
-
[7]
Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018. arXiv:1803.05457
Pith/arXiv arXiv 2018
-
[8]
Smith, Ahmad Idrissi-Yaghir, Constantin Seibold, Jianning Li, Lars Heiliger, Christoph M
Amin Dada, Aokun Chen, Cheng Peng, Kaleb E. Smith, Ahmad Idrissi-Yaghir, Constantin Seibold, Jianning Li, Lars Heiliger, Christoph M. Friedrich, Daniel Truhn, Jan Egger, Jiang Bian, Jens Kleesiek, and Yonghui Wu. On the impact of cross-domain data on german language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association ...
2023
-
[9]
A new massive multilingual dataset for high- performance language technologies
Ona de Gibert, Graeme Nail, Nikolay Arefyev, Marta Bañón, Jelmer van der Linde, Shaoxiong Ji, Jaume Zaragoza-Bernabeu, Mikko Aulamo, Gema Ramírez-Sánchez, Andrey Kutuzov, Sampo Pyysalo, Stephan Oepen, and Jörg Tiedemann. A new massive multilingual dataset for high- performance language technologies. In Nicoletta Calzolari, Min-Yen Kan, Véronique Hoste, Al...
2024
-
[10]
WMT24++: Expanding the language coverage of WMT24 to 55 languages & dialects
Daniel Deutsch, Eleftheria Briakou, Isaac Rayburn Caswell, Mara Finkelstein, Rebecca Galor, Juraj Juraska, Geza Kovacs, Alison Lui, Ricardo Rei, Jason Riesa, Shruti Rijhwani, Parker Riley, Elizabeth Salesky, Firas Trabelsi, Stephanie Winkler, Biao Zhang, and Markus Freitag. WMT24++: Expanding the language coverage of WMT24 to 55 languages & dialects. In F...
2025
-
[11]
Shizhe Diao, Yu Yang, Yonggan Fu, Xin Dong, Dan Su, Markus Kliegl, Zijia Chen, Peter Belcak, Yoshi Suhara, Hongxu Yin, Mostofa Patwary, Yingyan, Lin, Jan Kautz, and Pavlo Molchanov. Nemotron-climb: Clustering-based iterative data mixture bootstrapping for language model pre-training, 2025. arXiv:2504.13161
Pith/arXiv arXiv 2025
-
[12]
Documenting large webtext corpora: A case study on the colossal clean crawled corpus
Jesse Dodge, Maarten Sap, Ana Marasovic, William Agnew, Gabriel Ilharco, Dirk Groeneveld, Margaret Mitchell, and Matt Gardner. Documenting large webtext corpora: A case study on the colossal clean crawled corpus. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors,Proceedings of the 2021 Conference on Empirical Methods in...
2021
-
[13]
Pretraining language models using translationese
Meet Doshi, Raj Dabre, and Pushpak Bhattacharyya. Pretraining language models using translationese. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024, pages 5843–5862. Association for Computational Linguistic...
2024
-
[14]
The pile: An 800gb dataset of diverse text for language modeling, 2020
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The pile: An 800gb dataset of diverse text for language modeling, 2020. arXiv:2101.00027
Pith/arXiv arXiv 2020
-
[15]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
2024
-
[16]
Wallach, Hal Daumé III, and Kate Crawford
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna M. Wallach, Hal Daumé III, and Kate Crawford. Datasheets for datasets.Commun. ACM, 64(12): 86–92, 2021
2021
-
[17]
The german commons - 154 billion tokens of openly licensed text for german language models, 2025
Lukas Gienapp, Christopher Schröder, Stefan Schweter, Christopher Akiki, Ferdinand Schlatt, Arden Zimmermann, Phillipe Genêt, and Martin Potthast. The german commons - 154 billion tokens of openly licensed text for german language models, 2025. arXiv:2510.13996
arXiv 2025
-
[18]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021
2021
-
[19]
Rae, and Laurent Sifre
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katherine Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Oriol Vinyals, Jack W. Rae, and Laurent S...
2022
-
[20]
Glotlid: Language identification for low-resource languages
Amir Hossein Kargaran, Ayyoob Imani, François Yvon, and Hinrich Schütze. Glotlid: Language identification for low-resource languages. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, Findings of ACL, pages 6155–6218. Association for Computational Li...
2023
-
[21]
Julia Kreutzer, Isaac Caswell, Lisa Wang, Ahsan Wahab, Daan van Esch, Nasanbayar Ulzii- Orshikh, Allahsera Tapo, Nishant Subramani, Artem Sokolov, Claytone Sikasote, Monang Setyawan, Supheakmungkol Sarin, Sokhar Samb, Benoît Sagot, Clara Rivera, Annette Rios, Isabel Papadimitriou, Salomey Osei, Pedro Javier Ortiz Suárez, Iroro Orife, Kelechi Ogueji, An- d...
2022
-
[22]
Yamshchikov
Pierre-Carl Langlais, Pavel Chizhov, Catherine Arnett, Carlos Rosas Hinostroza, Mattia Nee, Eliot Krzysztof Jones, Irène Girard, David Mach, Anastasia Stasenko, and Ivan P. Yamshchikov. Common corpus: The largest collection of ethical data for LLM pre-training. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[23]
The bigscience ROOTS corpus: A 1.6tb composite multilingual dataset
Hugo Laurençon, Lucile Saulnier, Thomas Wang, Christopher Akiki, Albert Villanova del Moral, Teven Le Scao, Leandro von Werra, Chenghao Mou, Eduardo González Ponferrada, Huu Nguyen, Jörg Frohberg, Mario Sasko, Quentin Lhoest, Angelina McMillan-Major, Gérard Dupont, Stella Biderman, Anna Rogers, Loubna Ben Allal, Francesco De Toni, Giada Pistilli, Olivier ...
2022
-
[24]
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Yitzhak Gadre, Hritik Bansal, Etash Kumar Guha, Sedrick Scott Keh, Kushal Arora, Saurabh Garg, Rui Xin, Niklas Muennighoff, Reinhard Heckel, Jean Mercat, Mayee F. Chen, Suchin Gururangan, Mitchell Wortsman, Alon Albalak, Yonatan Bitton, Marianna Nezhurina, Amro Abbas, Cheng-Yu Hsieh, D...
2024
-
[25]
Guerreiro, Ricardo Rei, Duarte M
Pedro Henrique Martins, Patrick Fernandes, João Alves, Nuno M. Guerreiro, Ricardo Rei, Duarte M. Alves, José Pombal, Amin Farajian, Manuel Faysse, Mateusz Klimaszewski, Pierre Colombo, Barry Haddow, José G. C. de Souza, Alexandra Birch, and André F. T. Martins. EuroLLM: Multilingual language models for europe, 2024. arXiv:2409.16235
arXiv 2024
-
[26]
Rossi, and Thien Huu Nguyen
Thuat Nguyen, Chien Van Nguyen, Viet Dac Lai, Hieu Man, Nghia Trung Ngo, Franck Dernoncourt, Ryan A. Rossi, and Thien Huu Nguyen. CulturaX: A cleaned, enormous, and multilingual dataset for large language models in 167 languages. In Nicoletta Calzolari, Min-Yen Kan, Véronique Hoste, Alessandro Lenci, Sakriani Sakti, and Nianwen Xue, editors, Proceedings o...
2024
-
[27]
Hplt 3.0: Very large- scale multilingual resources for llm and mt
Stephan Oepen, Nikolay Arefev, Mikko Aulamo, Marta Bañón, Maja Buljan, Laurie Burchell, Lucas Charpentier, Pinzhen Chen, Mariya Fedorova, Ona de Gibert, et al. Hplt 3.0: Very large- scale multilingual resources for llm and mt. mono-and bi-lingual data, multilingual evaluation, and pre-trained models.arXiv preprint arXiv:2511.01066, 2025
Pith/arXiv arXiv 2025
-
[28]
FineWeb2: One pipeline to scale them all — adapting pre-training data processing to every language
Guilherme Penedo, Hynek Kydlí ˇcek, Vinko Sabol ˇcec, Bettina Messmer, Negar Foroutan, Amir Hossein Kargaran, Colin Raffel, Martin Jaggi, Leandro V on Werra, and Thomas Wolf. FineWeb2: One pipeline to scale them all — adapting pre-training data processing to every language. InSecond Conference on Language Modeling, 2025
2025
-
[29]
Llämmlein: Transparent, compact and compet- itive german-only language models from scratch
Jan Pfister, Julia Wunderle, and Andreas Hotho. Llämmlein: Transparent, compact and compet- itive german-only language models from scratch. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna...
2025
-
[30]
Leolm: Igniting german-language llm research
Björn Plüster. Leolm: Igniting german-language llm research. LAION Blog, September 2023. URLhttps://laion.ai/blog/leo-lm/. Accessed: May 5, 2026
2023
-
[31]
Treviso, Nuno Miguel Guerreiro, Chrysoula Zerva, Ana C
Ricardo Rei, Marcos V . Treviso, Nuno Miguel Guerreiro, Chrysoula Zerva, Ana C. Farinha, Christine Maroti, José G. C. de Souza, Taisiya Glushkova, Duarte M. Alves, Luísa Coheur, Alon Lavie, and André F. T. Martins. CometKiwi: Ist-unbabel 2022 submission for the quality 14 estimation shared task. In Philipp Koehn, Loïc Barrault, Ondrej Bojar, Fethi Bougare...
2022
-
[32]
How good is your tokenizer? on the monolingual performance of multilingual language models
Phillip Rust, Jonas Pfeiffer, Ivan Vulic, Sebastian Ruder, and Iryna Gurevych. How good is your tokenizer? on the monolingual performance of multilingual language models. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors,Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joi...
2021
-
[33]
Gottbert: a pure german language model
Raphael Scheible, Johann Frei, Fabian Thomczyk, Henry He, Patric Tippmann, Jochen Knaus, Victor Jaravine, Frank Kramer, and Martin Boeker. Gottbert: a pure german language model. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, ...
2024
-
[34]
Megatron-LM: Training multi-billion parameter language models using model parallelism, 2020
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-LM: Training multi-billion parameter language models using model parallelism, 2020. arXiv:1909.08053
Pith/arXiv arXiv 2020
-
[35]
Shivalika Singh, Angelika Romanou, Clémentine Fourrier, David Ifeoluwa Adelani, Jian Gang Ngui, Daniel Vila-Suero, Peerat Limkonchotiwat, Kelly Marchisio, Wei Qi Leong, Yosephine Susanto, Raymond Ng, Shayne Longpre, Sebastian Ruder, Wei-Yin Ko, Antoine Bosselut, Alice Oh, André F. T. Martins, Leshem Choshen, Daphne Ippolito, Enzo Ferrante, Marzieh Fadaee,...
2025
-
[36]
Peters, Abhilasha Ravichander, Kyle Richardson, Zejiang Shen, Emma Strubell, Nishant Subramani, Oyvind Tafjord, Pete Walsh, Luke Zettlemoyer, Noah A
Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Raghavi Chandu, Jennifer Dumas, Yanai Elazar, Valentin Hofmann, Ananya Harsh Jha, Sachin Kumar, Li Lucy, Xinxi Lyu, Nathan Lambert, Ian Magnusson, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Abhilasha Rav...
2024
-
[37]
A monolingual approach to contextualized word embeddings for mid-resource languages
Pedro Javier Ortiz Suárez, Laurent Romary, and Benoît Sagot. A monolingual approach to contextualized word embeddings for mid-resource languages. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel R. Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pages 170...
2020
-
[38]
Towards multilingual llm evaluation for european languages, 2024
Klaudia Thellmann, Bernhard Stadler, Michael Fromm, Jasper Schulze Buschhoff, Alex Jude, Fabio Barth, Johannes Leveling, Nicolas Flores-Herr, Joachim Köhler, René Jäkel, and Mehdi Ali. Towards multilingual llm evaluation for european languages, 2024. URL https://arxiv. org/abs/2410.08928
arXiv 2024
-
[39]
A shocking amount of the web is machine translated: Insights from multi-way parallelism
Brian Thompson, Mehak Preet Dhaliwal, Peter Frisch, Tobias Domhan, and Marcello Federico. A shocking amount of the web is machine translated: Insights from multi-way parallelism. 15 In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11...
2024
-
[40]
Multilingual language model pretraining using machine- translated data
Jiayi Wang, Yao Lu, Maurice Weber, Max Ryabinin, David Ifeoluwa Adelani, Yihong Chen, Raphael Tang, and Pontus Stenetorp. Multilingual language model pretraining using machine- translated data. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Langu...
2025
-
[41]
mT5: A massively multilingual pre-trained text-to-text transformer
Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. mT5: A massively multilingual pre-trained text-to-text transformer. In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tür, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou, editors, Procee...
2021
-
[42]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
-
[43]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: can a machine really finish your sentence? In Anna Korhonen, David R. Traum, and Lluís Màrquez, editors,Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, pages 4791...
arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.