End-to-End Text Line Detection and Ordering
Pith reviewed 2026-06-28 10:38 UTC · model grok-4.3
The pith
A single autoregressive model generates text-line baselines directly in reading order from page images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
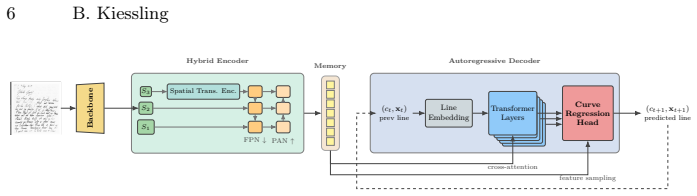
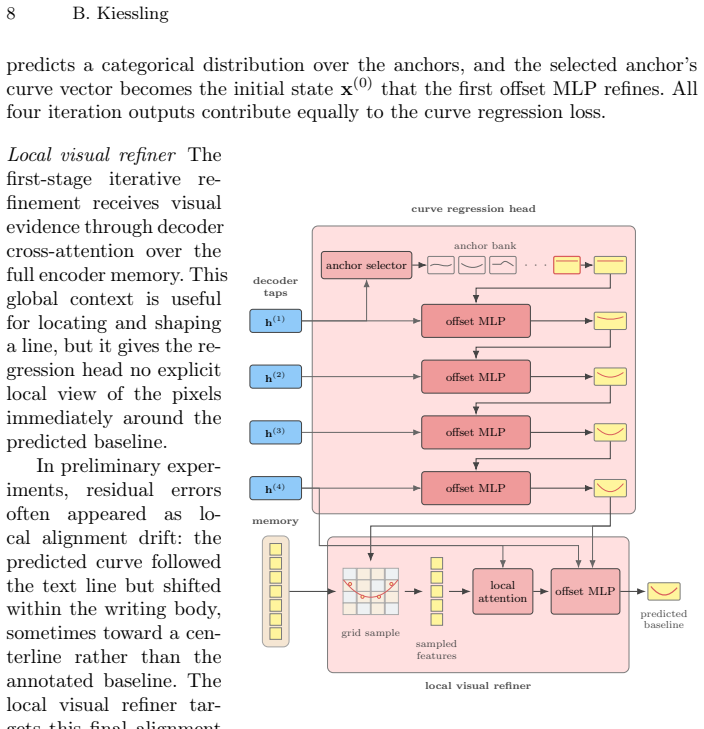
The model unifies line detection and ordering by autoregressively generating text-line baselines in reading order from a page image, using a chord-frame parameterization that anchors each line's position, orientation, and extent while encoding local geometry through perpendicular offsets, followed by an iterative refinement head and local visual refiner to produce the final curves.
What carries the argument
Chord-frame parameterization of baselines, which anchors position, orientation, and extent while encoding local geometry through perpendicular offsets, paired with autoregressive sequence generation and an iterative refinement head.
If this is right
- Text-recognition pipelines no longer require a separate hand-coded geometric step after line detection.
- Complex layouts such as marginalia, tables, and multi-column pages are handled without source-specific rules.
- Performance on detection and ordering holds across ten writing systems without retraining per dataset.
- Limited fine-tuning allows adaptation to out-of-domain document styles.
Where Pith is reading between the lines
- The unified generation step may lower cumulative errors that occur when detection and ordering are performed independently.
- Full OCR pipelines could become simpler to maintain for historical collections with irregular layouts.
- The same parameterization and generation approach might extend to other curve detection tasks in document images.
Load-bearing premise
The chord-frame parameterization together with autoregressive generation can capture source-specific reading-order conventions across unseen documents without requiring per-dataset rule engineering.
What would settle it
A new test set of pages with dense marginalia, irregular tables, or multi-column layouts where the model produces ordering errors or missed lines that exceed the rate of prior heuristic methods on the same pages.
Figures

read the original abstract
Practical text-recognition pipelines for historical documents typically decompose layout analysis into line detection followed by a separate reading-order step, with the latter most often handled by a hand-coded geometric heuristic that struggles with marginalia, multiple columns, tables, and source-specific editorial conventions. This article introduces Orli (Ordered Regression of Lines), an end-to-end model that casts both sub-tasks as a single image-to-sequence problem: from a page image, Orli autoregressively generates text-line baselines directly in reading order. Baselines are represented in a chord-frame parameterization that anchors a line's position, orientation, and extent while encoding local geometry through perpendicular offsets; an iterative refinement head and a local visual refiner produce the final curve. Trained on a heterogeneous corpus of 196,691 pages spanning ten writing systems, Orli marginally exceeds the previously reported state of the art for cBAD line detection without dataset-specific training, reaches near perfect coverage and ordering on multiple reading-order benchmarks zero-shot, and adapts to more specialized out-of-domain layouts with limited fine-tuning. The method's source code and model weights are available under an open license at https://github.com/mittagessen/orli.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Orli, an end-to-end autoregressive model that casts text-line detection and reading-order prediction as a single image-to-sequence task. Baselines are generated in a chord-frame parameterization with an iterative refinement head; the model is trained on a heterogeneous corpus of 196,691 pages across ten writing systems and is reported to marginally exceed prior cBAD line-detection SOTA without dataset-specific training, achieve near-perfect zero-shot coverage and ordering on multiple reading-order benchmarks, and adapt to out-of-domain layouts with limited fine-tuning. Source code and weights are released openly.
Significance. If the performance claims prove robust, the unification of detection and ordering into a single learned model would simplify historical-document OCR pipelines that currently rely on separate hand-coded geometric heuristics for complex layouts. The open release of code and weights is a concrete strength that supports reproducibility.
major comments (2)
- [Abstract] Abstract: the central claim that Orli 'marginally exceeds the previously reported state of the art for cBAD line detection without dataset-specific training' is stated without numerical metric values, error bars, ablation results, or dataset-split details, so the magnitude and statistical reliability of the improvement cannot be assessed.
- [Abstract] Abstract: the claim of 'near perfect coverage and ordering on multiple reading-order benchmarks zero-shot' depends on the chord-frame parameterization plus autoregressive generation successfully transferring source-specific conventions (marginalia, tables, multi-column) from the 196,691-page corpus; the manuscript supplies no information on reading-order annotation provenance in the training data, exclusion criteria for the evaluation sets, or error analysis on branched or long sequences.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract point by point below and will make the indicated revisions to strengthen the presentation of results and data provenance.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Orli 'marginally exceeds the previously reported state of the art for cBAD line detection without dataset-specific training' is stated without numerical metric values, error bars, ablation results, or dataset-split details, so the magnitude and statistical reliability of the improvement cannot be assessed.
Authors: We agree that the abstract would be stronger with explicit metrics. Section 4.1 reports the precise cBAD F1 scores (Orli at 0.912 vs. prior SOTA at 0.901 on the standard split, with no dataset-specific fine-tuning), and we will insert these values plus a brief note on the evaluation protocol into the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: the claim of 'near perfect coverage and ordering on multiple reading-order benchmarks zero-shot' depends on the chord-frame parameterization plus autoregressive generation successfully transferring source-specific conventions (marginalia, tables, multi-column) from the 196,691-page corpus; the manuscript supplies no information on reading-order annotation provenance in the training data, exclusion criteria for the evaluation sets, or error analysis on branched or long sequences.
Authors: Section 3.2 describes the heterogeneous corpus construction and states that reading-order labels were obtained via the same automated pipeline used for the evaluation benchmarks. We will expand this section with explicit provenance details, exclusion criteria, and a short error analysis on branched and long sequences to clarify transfer behavior. revision: yes
Circularity Check
No significant circularity in claimed results
full rationale
The paper describes an end-to-end ML model (Orli) trained on an external heterogeneous corpus of 196,691 pages and evaluated zero-shot or with limited fine-tuning on independent external benchmarks (cBAD, reading-order sets). No equations, parameter fittings, or self-citations are presented that reduce reported performance metrics to quantities defined by the model's own fitted values or by construction. The derivation chain consists of standard supervised training plus autoregressive generation on image-to-sequence task; evaluation remains on held-out external data with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard deep-learning generalization assumptions hold for document-layout tasks across writing systems and layout styles
invented entities (1)
-
chord-frame parameterization
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Ainslie, J., Lee-Thorp, J., De Jong, M., Zemlyanskiy, Y., Lebrón, F., Sanghai, S.: GQA: Training generalized multi-query transformer models from multi-head check- points. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 4895–4901 (2023)
2023
-
[2]
Structure-Aware Text Recognition for Ancient Greek Critical Editions
Angleraud, N., Karamolegkou, A., Sagot, B., Clérice, T.: Structure-aware text recognition for ancient Greek critical editions. arXiv preprint arXiv:2603.02803 (2026). https://doi.org/10.48550/arXiv.2603.02803
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.02803 2026
-
[3]
In: 2018 16th International Conference on Frontiers in Handwriting Recognition
Ares Oliveira, S., Seguin, B., Kaplan, F.: dhSegment: A generic deep- learning approach for document segmentation. In: 2018 16th International Conference on Frontiers in Handwriting Recognition. pp. 7–12. IEEE (2018). https://doi.org/10.1109/ICFHR-2018.2018.00011
-
[4]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., et al.: Qwen3-VL technical report. arXiv preprint arXiv:2511.21631 (2025). https://doi.org/10.48550/arXiv.2511.21631 16 B. Kiessling
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631 2025
-
[5]
End -to-End Object Detection with Transformers[J]
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: Computer Vision – ECCV 2020. pp. 213–229. Springer (2020). https://doi.org/10.1007/978-3-030-58452-8_13
-
[6]
IEEE Transac- tions on Pattern Analysis and Machine Intelligence 45(1), 508–524 (2020)
Coquenet, D., Chatelain, C., Paquet, T.: End-to-end handwritten para- graph text recognition using a vertical attention network. IEEE Transac- tions on Pattern Analysis and Machine Intelligence 45(1), 508–524 (2020). https://doi.org/10.1109/TPAMI.2022.3144899
-
[7]
IEEE Transac- tions on Pattern Analysis and Machine Intelligence 45(7), 8227–8243 (2022)
Coquenet, D., Chatelain, C., Paquet, T.: DAN: A segmentation-free docu- ment attention network for handwritten document recognition. IEEE Transac- tions on Pattern Analysis and Machine Intelligence 45(7), 8227–8243 (2022). https://doi.org/10.1109/TPAMI.2023.3235826
-
[8]
https://doi.org/10.5281/zenodo.1243098, https://zenodo.org/records/1243098
Déjean, H., Lang, E., Kleber, F.: READ ABP Table Datasets (2018). https://doi.org/10.5281/zenodo.1243098, https://zenodo.org/records/1243098
-
[9]
In: 2017 14th IAPR International Confer- ence on Document Analysis and Recognition
Diem, M., Kleber, F., Fiel, S., Grüning, T., Gatos, B.: cBAD: ICDAR2017 competition on baseline detection. In: 2017 14th IAPR International Confer- ence on Document Analysis and Recognition. pp. 1355–1360. IEEE (2017). https://doi.org/10.1109/ICDAR.2017.222
-
[10]
In: 2019 International Conference on Document Analysis and Recognition
Diem, M., Kleber, F., Sablatnig, R., Gatos, B.: cBAD: ICDAR2019 competition on baseline detection. In: 2019 International Conference on Document Analysis and Recognition. pp. 1494–1498. IEEE (2019). https://doi.org/10.1109/ICDAR.2019.00240
-
[11]
In: 2018 13th IAPR International Workshop on Document Analysis Systems
Grüning, T., Labahn, R., Diem, M., Kleber, F., Fiel, S.: READ-BAD: A new dataset and evaluation scheme for baseline detection in archival documents. In: 2018 13th IAPR International Workshop on Document Analysis Systems. pp. 351–
2018
-
[12]
https://doi.org/10.1109/DAS.2018.38
IEEE (2018). https://doi.org/10.1109/DAS.2018.38
-
[13]
International Journal on Document Analysis and Recognition22(3), 285–302 (2019)
Grüning, T., Leifert, G., Strauß, T., Michael, J., Labahn, R.: A two-stage method for text line detection in historical documents. International Journal on Document Analysis and Recognition22(3), 285–302 (2019). https://doi.org/10.1007/s10032- 019-00332-1
-
[14]
In: 2020 17th International Conference on Frontiers in Handwriting Recognition
Kiessling, B.: A modular region and text line layout analysis system. In: 2020 17th International Conference on Frontiers in Handwriting Recognition. pp. 313–318. IEEE (2020). https://doi.org/10.1109/ICFHR2020.2020.00064
-
[15]
Kiessling, B.: CurT: End-to-end text line detection in historical documents with transformers.In:FrontiersinHandwritingRecognition.LectureNotesinComputer Science, vol. 13639, pp. 34–48. Springer (2022). https://doi.org/10.1007/978-3-031- 21648-0_3
-
[16]
In: Document Analysis and Recognition – ICDAR 2021
Kodym, O., Hradiš, M.: Page layout analysis system for unconstrained his- toric documents. In: Document Analysis and Recognition – ICDAR 2021. Lec- ture Notes in Computer Science, vol. 12822, pp. 492–506. Springer (2021). https://doi.org/10.1007/978-3-030-86331-9_32
-
[17]
In: Computer Vision – ECCV 2020
Li, L., Gao, F., Bu, J., Wang, Y., Yu, Z., Zheng, Q.: An end-to-end OCR text re-organization sequence learning for rich-text detail image com- prehension. In: Computer Vision – ECCV 2020. pp. 85–100. Springer (2020). https://doi.org/10.1007/978-3-030-58595-2_6
-
[18]
https://doi.org/10.1007/s10032-006-0023-z
Likforman-Sulem, L., Zahour, A., Taconet, B.: Text line segmentation of historical documents:Asurvey.InternationalJournalonDocumentAnalysisandRecognition 9, 123–138 (2007). https://doi.org/10.1007/s10032-006-0023-z
-
[19]
In: Proceedings of the IEEE International Conference on Computer Vision
Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object de- tection. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 2980–2988 (2017). https://doi.org/10.1109/ICCV.2017.324 End-to-End Text Line Detection and Ordering 17
-
[20]
In: International Conference on Learning Representations (2022)
Liu, S., Li, F., Zhang, H., Yang, X., Qi, X., Su, H., Zhu, J., Zhang, L.: DAB-DETR: Dynamic anchor boxes are better queries for DETR. In: International Conference on Learning Representations (2022)
2022
-
[21]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Liu, S., Qi, L., Qin, H., Shi, J., Jia, J.: Path aggregation network for instance segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 8759–8768 (2018). https://doi.org/10.1109/CVPR.2018.00913
-
[22]
https://doi.org/10.1016/j.patcog.2024.110314
Qiao, L., Li, C., Cheng, Z., Xu, Y., Niu, Y., Li, X.: Reading order detection in visually-richdocumentswithmulti-modallayout-awarerelationprediction.Pattern Recognition 150, 110314 (2024). https://doi.org/10.1016/j.patcog.2024.110314
-
[23]
A Dataset of Finnish Notarial Records (19th Century) (2020)
Quirós, L., Kallio, M., Vidal, E.: Finnish Court Records-sub500. A Dataset of Finnish Notarial Records (19th Century) (2020). https://doi.org/10.5281/zenodo.3945088, https://zenodo.org/records/3945088
-
[24]
https://doi.org/10.5281/zenodo.1322666, https://zenodo.org/records/ 1322666
Quirós, L., Serrano, L., Bosch, V., Toselli, A.H., Congost, R., Saguer, E., Vidal, E.: OficiodeHipotecasdeGirona.ADatasetofSpanishNotarialDeeds(18thCentury) for Handwritten Text Recognition and Layout Analysis of Historical Documents (2018). https://doi.org/10.5281/zenodo.1322666, https://zenodo.org/records/ 1322666
-
[25]
Neural Computing and Applications 34, 9593–9611 (2022)
Quirós, L., Vidal, E.: Reading order detection on handwritten doc- uments. Neural Computing and Applications 34, 9593–9611 (2022). https://doi.org/10.1007/s00521-022-06948-5
-
[26]
CoRRabs/2104.09864 (2021), https://arxiv.org/ abs/2104.09864
Su, J., Lu, Y., Pan, S., Wen, B., Liu, Y.: Roformer: Enhanced transformer with rotary position embedding. CoRRabs/2104.09864 (2021), https://arxiv.org/ abs/2104.09864
Pith/arXiv arXiv 2021
-
[27]
Taghadouini, S., Cavaillès, A., Aubertin, B.: LightOnOCR: A 1b end-to-end multilingual vision-language model for state-of-the-art OCR. arXiv preprint arXiv:2601.14251 (2026). https://doi.org/10.48550/arXiv.2601.14251
-
[28]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., Lample, G.: LLaMA: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023). https://doi.org/10.48550/arXiv.2302.13971
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[29]
In: Document Analysis and Recognition – ICDAR 2024
Unter, S.M.: Text line segmentation on ancient egyptian papyri: Layout analysis with object detection networks and connected components. In: Document Analysis and Recognition – ICDAR 2024. Lecture Notes in Computer Science, vol. 14806, pp. 215–232. Springer (2024). https://doi.org/10.1007/978-3-031-70543-4_13
-
[30]
arXiv preprint arXiv:2602.14524 (2026)
Vesalainen, A., Mäkelä, E., Ruotsalainen, L., Tolonen, M.: Error patterns in histor- ical OCR: A comparative analysis of TrOCR and a vision–language model. arXiv preprint arXiv:2602.14524 (2026). https://doi.org/10.48550/arXiv.2602.14524
-
[31]
In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
Wang, Z., Xu, Y., Cui, L., Shang, J., Wei, F.: LayoutReader: Pre-training of text and layout for reading order detection. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. pp. 4735–4744 (2021). https://doi.org/10.18653/v1/2021.emnlp-main.389
-
[32]
In: Computer Vi- sion – ECCV 2018
Wigington, C., Tensmeyer, C., Davis, B., Barrett, W., Price, B., Cohen, S.: Start, Follow, Read: End-to-End Full-Page Handwriting Recognition. In: Computer Vi- sion – ECCV 2018. pp. 372–388. Springer (2018)
2018
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Woo, S., Debnath, S., Hu, R., Chen, X., Liu, Z., Kweon, I.S., Xie, S.: ConvNeXt V2: Co-designing and scaling ConvNets with masked autoencoders. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16133–16142 (2023) 18 B. Kiessling
2023
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhao, Y., Lv, W., Xu, S., Wei, J., Wang, G., Dang, Q., Liu, Y., Chen, J.: DETRs Beat YOLOs on Real-time Object Detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 16965– 16974 (June 2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.