RSC: Decentralized Rigid Formation Flocking for Large-Scale Swarms via Hybrid Predictive Control and Online Reconfiguration
Pith reviewed 2026-06-28 09:27 UTC · model grok-4.3
The pith
RSC combines finite-horizon predictions with reactive safety control and role-exchange reconfiguration to let decentralized swarms maintain rigid formations while avoiding obstacles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
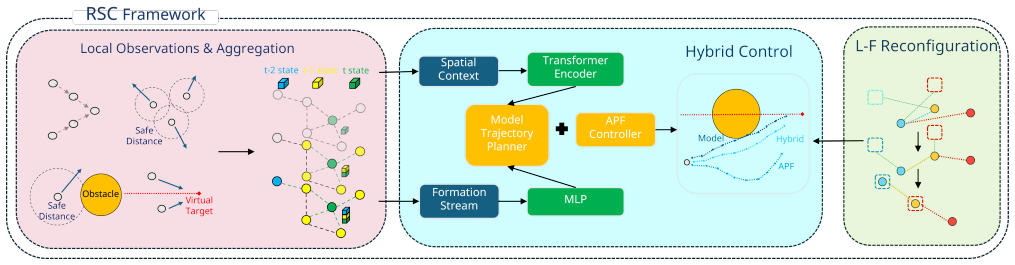
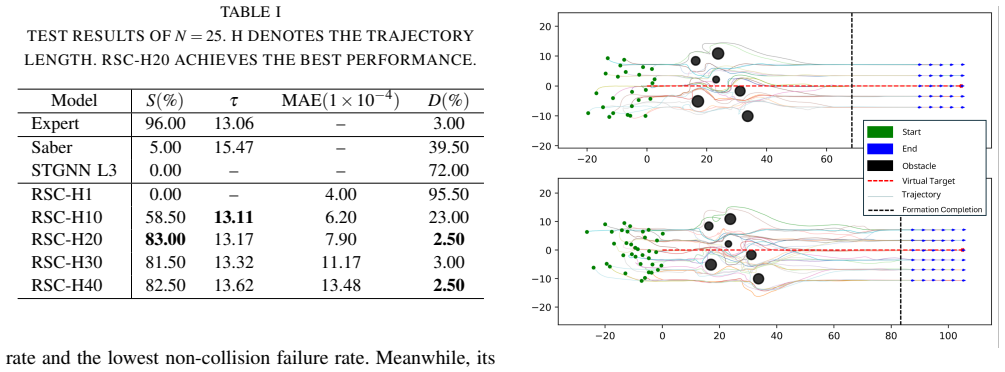
RSC integrates finite-horizon trajectory predictions with a reactive artificial potential field safety controller in a hybrid architecture to escape local minima while ensuring safety, and adds an online leader-follower reconfiguration mechanism based on stable role exchange to accelerate formation reassembly after obstacle traversal, delivering collision-free operation with maximum relative edge-length error below 10 percent at an 83 percent success rate in evaluations with 25 UAVs.
What carries the argument
Hybrid predictive-reactive architecture that pairs finite-horizon trajectory predictions with a reactive APF safety controller, together with the stable leader-follower role-exchange reconfiguration mechanism.
If this is right
- Large swarms can sustain rigid formations and track targets through obstacle fields without central coordination.
- Formation reassembly occurs faster after obstacles because role exchanges happen without halting the overall task.
- Decentralized rigid flocking becomes viable under the same strict success criteria where heuristic and learning baselines remain below 5 percent success.
- The hybrid architecture unifies long-term planning with short-term safety so that neither component alone suffices.
Where Pith is reading between the lines
- The method could extend to non-UAV platforms if the prediction horizon and potential-field gains are retuned for different dynamics.
- Sensor noise or communication delays not modeled in simulation would likely reduce the observed success rate and require explicit robustness margins.
- Combining the role-exchange logic with learned prediction models might further lower the failure rate in novel environments.
- Scaling beyond 25 agents would test whether the decentralized communication load remains manageable as swarm size grows.
Load-bearing premise
The combination of finite-horizon predictions, reactive safety control, and role exchanges will escape local minima and avoid both oscillations and new deadlocks while preserving strict distance constraints.
What would settle it
A single run in a cluttered test environment where the system either collides, exceeds 10 percent relative edge-length error, or enters a deadlock while all other components function as described.
Figures


read the original abstract
Decentralized rigid formation flocking requires a swarm of autonomous agents to maintain a predetermined geometric configuration while moving, relying solely on local sensing and communication. However, existing decentralized control methods struggle to maintain strict inter-agent distance constraints in cluttered environments, often suffering from local minima deadlocks, high frequency control oscillations, or limited flexibility during obstacle navigation, resulting in low success rate. To address these limitations, we propose Rigid Swarm Control (RSC), a decentralized control framework for large-scale rigid formation flocking. To escape local minima via robust long-term planning while ensuring short-term safety, RSC integrates finite-horizon trajectory predictions with a reactive artificial potential field (APF) safety controller within a hybrid architecture. Furthermore, to accelerate formation reassembly after obstacle traversal without interrupting task execution, RSC introduces an online leader-follower reconfiguration mechanism based on stable role exchange. Extensive evaluations in challenging cluttered environments with 25 UAVs demonstrate that RSC reliably unifies rigid formation maintenance, obstacle avoidance, and target tracking. Under strict success criteria - collision-free operation with a maximum relative edge-length error below 10%, RSC achieves an 83% success rate, significantly outperforming existing heuristic and learning-based baselines that fall below 5%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
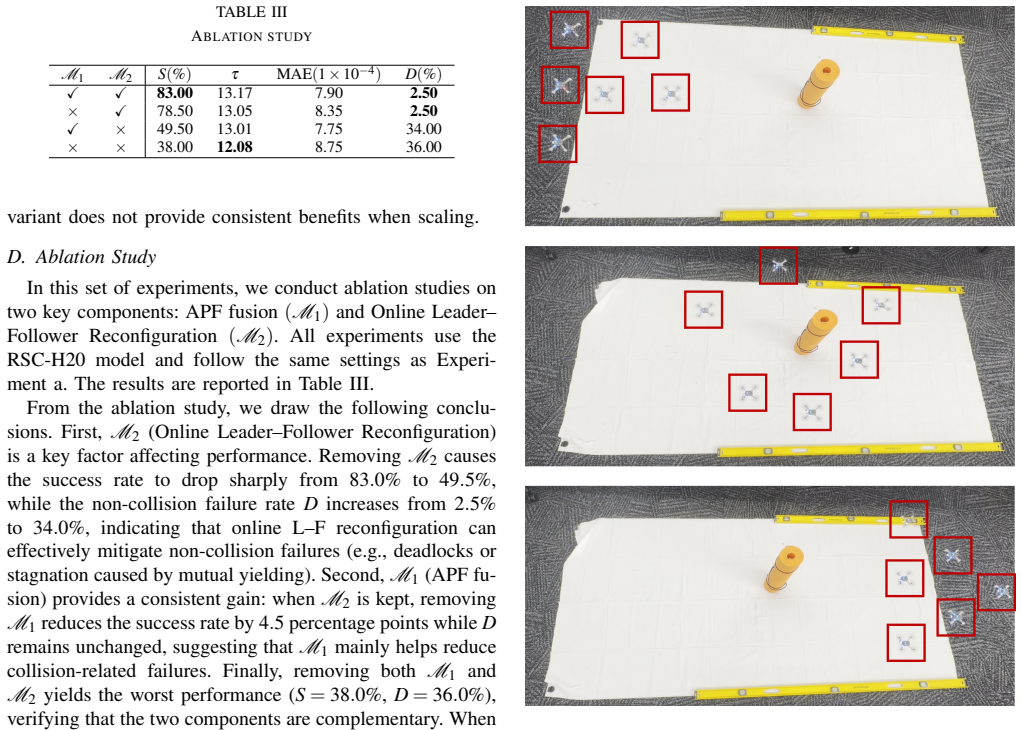
Summary. The paper proposes Rigid Swarm Control (RSC), a decentralized framework for rigid formation flocking of large swarms. It integrates finite-horizon trajectory predictions with a reactive APF safety controller in a hybrid architecture to escape local minima while maintaining short-term safety and collision avoidance, and introduces an online leader-follower reconfiguration mechanism based on stable role exchange to accelerate reassembly after obstacle traversal. Evaluations with 25 UAVs in cluttered environments report an 83% success rate (collision-free with max relative edge-length error <10%), significantly outperforming heuristic and learning-based baselines (<5%).
Significance. If the hybrid architecture and reconfiguration can be rigorously shown to avoid introducing oscillations or deadlocks while preserving rigidity, the work would represent a practical advance in decentralized swarm control for cluttered environments, where existing methods often fail. The reported performance gap is notable for applications in UAV swarms, but the empirical focus without supporting stability analysis limits broader theoretical impact.
major comments (2)
- [Hybrid architecture description] Hybrid architecture (description of finite-horizon predictions guiding reactive APF): no switching law, dwell-time condition, or combined Lyapunov function is provided for the hybrid MPC+APF integration. This is load-bearing for the central claim, as the paper asserts the predictions guide the APF to escape local minima without oscillations or new deadlocks, yet APF chattering is a known issue with short horizons relative to obstacle spacing and directly undermines verification of the 83% success rate versus baselines.
- [Role-exchange mechanism] Online reconfiguration mechanism (role-exchange section): the mechanism is described as 'stable' but no analysis or proof is given that it preserves rigidity during exchange. This is load-bearing for the claim of accelerating formation reassembly without interrupting task execution or violating distance constraints.
minor comments (1)
- [Abstract] The abstract reports the 83% success rate and baseline comparisons without specifying the number of trials, variance, exact protocol for measuring edge-length error, or implementation details of the baselines, which affects reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of the hybrid architecture and reconfiguration mechanism that would benefit from additional clarification and analysis. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Hybrid architecture description] Hybrid architecture (description of finite-horizon predictions guiding reactive APF): no switching law, dwell-time condition, or combined Lyapunov function is provided for the hybrid MPC+APF integration. This is load-bearing for the central claim, as the paper asserts the predictions guide the APF to escape local minima without oscillations or new deadlocks, yet APF chattering is a known issue with short horizons relative to obstacle spacing and directly undermines verification of the 83% success rate versus baselines.
Authors: We agree that a formal hybrid systems analysis, including an explicit switching law and combined Lyapunov function, is not provided in the current manuscript. The implementation uses a fixed prediction horizon of 10 steps to detect impending local minima and activates the APF only when the predicted rigid-formation error exceeds a threshold; the APF is deactivated once the predicted trajectory returns within bounds. This heuristic separation of timescales is intended to prevent chattering, but we acknowledge it lacks rigorous dwell-time guarantees. We will revise the paper to include an explicit description of the switching condition in Section III, add a new subsection discussing practical mitigation of oscillations (supported by plots of control inputs from the 25-UAV experiments), and provide an informal argument based on the prediction horizon being longer than typical APF reaction times. A full combined Lyapunov analysis is beyond the scope of the current empirical focus but will be noted as future work. revision: yes
-
Referee: [Role-exchange mechanism] Online reconfiguration mechanism (role-exchange section): the mechanism is described as 'stable' but no analysis or proof is given that it preserves rigidity during exchange. This is load-bearing for the claim of accelerating formation reassembly without interrupting task execution or violating distance constraints.
Authors: We concur that the manuscript does not supply a formal proof that rigidity is preserved during role exchange. The mechanism performs an instantaneous leader-follower swap only when the candidate pair already satisfies the target distance within 5% tolerance and both agents have matching velocities; the underlying communication graph remains unchanged at the instant of exchange. We will revise the relevant section to include a short proof sketch showing that the rigidity matrix rank is unaffected because positions and edges are identical before and after the swap, and we will add experimental traces confirming that inter-agent distances never exceed the 10% error threshold during exchanges in the reported trials. revision: yes
Circularity Check
No circularity; empirical performance claims rest on simulation outcomes
full rationale
The provided abstract and text describe a hybrid MPC+APF controller plus role-exchange mechanism, then report an 83% success rate under explicit success criteria from evaluations with 25 UAVs. No equations, parameter fits, derivation steps, or self-citations appear in the given material. The central result is therefore an empirical observation rather than a reduction of any claimed prediction or uniqueness theorem to the method's own inputs or prior self-citations. The derivation chain is self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Flocking for Multi-Agent Dynamic Systems: Algo- rithms and Theory,
R. Olfati-Saber, “Flocking for Multi-Agent Dynamic Systems: Algo- rithms and Theory,”IEEE Transactions on Automatic Control, vol. 51, pp. 401–420, Mar. 2006
2006
-
[2]
Consensus Problems in Networks of Agents With Switching Topology and Time-Delays,
R. Olfati-Saber and R. Murray, “Consensus Problems in Networks of Agents With Switching Topology and Time-Delays,”IEEE Transac- tions on Automatic Control, vol. 49, pp. 1520–1533, Sept. 2004
2004
-
[3]
An Improved Artificial Potential Field Method for Path Planning and Formation Control of the Multi-UA V Systems,
Z. Pan, C. Zhang, Y . Xia, H. Xiong, and X. Shao, “An Improved Artificial Potential Field Method for Path Planning and Formation Control of the Multi-UA V Systems,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 69, pp. 1129–1133, Mar. 2022
2022
-
[4]
Learning Decentralized Controllers for Robot Swarms with Graph Neural Networks,
E. Tolstaya, F. Gama, J. Paulos, G. Pappas, V . Kumar, and A. Ribeiro, “Learning Decentralized Controllers for Robot Swarms with Graph Neural Networks,”Foundations and Trends® in Machine Learning, vol. 10, no. 1-2, pp. 1–141, 2017. arXiv:1903.10527 [cs]
-
[5]
Learning Decen- tralized Strategies for a Perimeter Defense Game with Graph Neural Networks,
E. S. Lee, L. Zhou, A. Ribeiro, and V . Kumar, “Learning Decen- tralized Strategies for a Perimeter Defense Game with Graph Neural Networks,” Sept. 2022. arXiv:2211.01757 [cs]
-
[6]
Escaping Local Minima: Hybrid Artificial Potential Field with Wall- Follower for Decentralized Multi-Robot Navigation,
J. Kim, S. Park, W. Lee, W. Kim, H. Choi, N. Doh, and C. Nam, “Escaping Local Minima: Hybrid Artificial Potential Field with Wall- Follower for Decentralized Multi-Robot Navigation,” in2025 IEEE International Conference on Robotics and Automation (ICRA), (At- lanta, GA, USA), pp. 6616–6622, IEEE, May 2025
2025
-
[7]
Towards Solving Multi-Agent Potential Field Local Minimas Through Imitation Learning,
Y . Moukhlis, B. E. Khamlichi, and A. E. Fallah Seghrouchni, “Towards Solving Multi-Agent Potential Field Local Minimas Through Imitation Learning,” in2025 IEEE 22nd Consumer Communications & Networking Conference (CCNC), (Las Vegas, NV , USA), pp. 1–5, IEEE, Jan. 2025
2025
-
[8]
Reinforced Potential Field for Multi-Robot Motion Planning in Cluttered Envi- ronments,
D. Zhang, X. Zhang, Z. Zhang, B. Zhu, and Q. Zhang, “Reinforced Potential Field for Multi-Robot Motion Planning in Cluttered Envi- ronments,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), (Detroit, MI, USA), pp. 699–704, IEEE, Oct. 2023
2023
-
[9]
Test-time GNN Model Evaluation on Dynamic Graphs,
B. Li, X. Zheng, M. Jin, C. Wang, and S. Pan, “Test-time GNN Model Evaluation on Dynamic Graphs,” Sept. 2025. arXiv:2509.23816 [cs]
-
[10]
Learning Decentralized Flocking Controllers with Spatio-Temporal Graph Neural Network,
S. Chen, Y . Sun, P. Li, L. Zhou, and C.-T. Lu, “Learning Decentralized Flocking Controllers with Spatio-Temporal Graph Neural Network,” in2024 IEEE International Conference on Robotics and Automation (ICRA), (Yokohama, Japan), pp. 2596–2602, IEEE, May 2024
2024
-
[11]
Formation Control with Collision Avoidance for a Multi-UA V System Using Decentralized MPC and Consensus-Based Control,
Y . Kuriki and T. Namerikawa, “Formation Control with Collision Avoidance for a Multi-UA V System Using Decentralized MPC and Consensus-Based Control,”SICE Journal of Control, Measurement, and System Integration, vol. 8, pp. 285–294, July 2015
2015
-
[12]
Heuristic Predictive Control for Multirobot Flocking in Congested Environments,
G. Zhu, Q. Zhang, B. Zhu, and T. Hu, “Heuristic Predictive Control for Multirobot Flocking in Congested Environments,”IEEE/ASME Transactions on Mechatronics, vol. 30, pp. 1435–1446, Apr. 2025
2025
-
[13]
Data-Driven MPC for Quadrotors,
G. Torrente, E. Kaufmann, P. F ¨ohn, and D. Scaramuzza, “Data-Driven MPC for Quadrotors,”IEEE Robotics and Automation Letters, vol. 6, pp. 3769–3776, Apr. 2021
2021
-
[14]
Leader-based multi-agent coordination: controllability and optimal control,
Meng Ji, A. Muhammad, and M. Egerstedt, “Leader-based multi-agent coordination: controllability and optimal control,” in2006 American Control Conference, (Minneapolis, MN, USA), p. 6 pp., IEEE, 2006
2006
-
[15]
A Decentralized Approach to Drone Formation Based on Leader-Follower Technique,
A. M. De Souza Neto and R. A. F. Romero, “A Decentralized Approach to Drone Formation Based on Leader-Follower Technique,” in2019 Latin American Robotics Symposium (LARS), 2019 Brazilian Symposium on Robotics (SBR) and 2019 Workshop on Robotics in Education (WRE), (Rio Grande, Brazil), pp. 358–362, IEEE, Oct. 2019
2019
-
[16]
UA V formation control with obstacle avoidance using improved artificial potential fields,
Y . Zhao, L. Jiao, R. Zhou, and J. Zhang, “UA V formation control with obstacle avoidance using improved artificial potential fields,” in2017 36th Chinese Control Conference (CCC), (Dalian, China), pp. 6219– 6224, IEEE, July 2017
2017
-
[17]
UA V Formation Control via the Virtual Structure Approach,
A. Askari, M. Mortazavi, and H. A. Talebi, “UA V Formation Control via the Virtual Structure Approach,”Journal of Aerospace Engineer- ing, vol. 28, p. 04014047, Jan. 2015
2015
-
[18]
Formation control and collision avoidance for multi-UA V systems based on V oronoi partition,
J. Hu, M. Wang, C. Zhao, Q. Pan, and C. Du, “Formation control and collision avoidance for multi-UA V systems based on V oronoi partition,”Science China Technological Sciences, vol. 63, pp. 65–72, Jan. 2020
2020
-
[19]
UA V Formation Shape Control via Decentralized Markov Decision Processes,
M. A. Azam, H. D. Mittelmann, and S. Ragi, “UA V Formation Shape Control via Decentralized Markov Decision Processes,”Algorithms, vol. 14, p. 91, Mar. 2021
2021
-
[20]
End-to-end decentralized formation control using a graph neural network-based learning method,
C. Jiang, X. Huang, and Y . Guo, “End-to-end decentralized formation control using a graph neural network-based learning method,”Fron- tiers in Robotics and AI, vol. 10, p. 1285412, Nov. 2023
2023
-
[21]
A DRL Based Distributed Formation Control Scheme with Stream-Based Collision Avoidance,
X. Qiu, X. Li, J. Wang, Y . Wang, and Y . Shen, “A DRL Based Distributed Formation Control Scheme with Stream-Based Collision Avoidance,” in2021 IEEE International Conference on Autonomous Systems (ICAS), (Montreal, QC, Canada), pp. 1–5, IEEE, Aug. 2021
2021
-
[22]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention Is All You Need,” Aug. 2023. arXiv:1706.03762 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Leader-to-formation stability,
H. Tanner, G. Pappas, and V . Kumar, “Leader-to-formation stability,” IEEE Transactions on Robotics and Automation, vol. 20, pp. 443–455, June 2004
2004
-
[24]
Modeling and control of formations of nonholonomic mobile robots,
J. Desai, J. Ostrowski, and V . Kumar, “Modeling and control of formations of nonholonomic mobile robots,”IEEE Transactions on Robotics and Automation, vol. 17, pp. 905–908, Dec. 2001
2001
-
[25]
ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst,
M. Bansal, A. Krizhevsky, and A. Ogale, “ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst,” inRobotics: Science and Systems XV, Robotics: Science and Systems Foundation, June 2019
2019
-
[26]
Planning- oriented Autonomous Driving,
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang, L. Lu, X. Jia, Q. Liu, J. Dai, Y . Qiao, and H. Li, “Planning- oriented Autonomous Driving,” in2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (Vancouver, BC, Canada), pp. 17853–17862, IEEE, June 2023
2023
-
[27]
End-to-end Interpretable Neural Motion Planner,
W. Zeng, W. Luo, S. Suo, A. Sadat, B. Yang, S. Casas, and R. Ur- tasun, “End-to-end Interpretable Neural Motion Planner,” Jan. 2021. arXiv:2101.06679 [cs]
-
[28]
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
S. Ross, G. J. Gordon, and J. A. Bagnell, “A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning,” Mar. 2011. arXiv:1011.0686 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[29]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimiza- tion,” Jan. 2017. arXiv:1412.6980 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Crazyswarm: A large nano-quadcopter swarm,
J. A. Preiss, W. Honig, G. S. Sukhatme, and N. Ayanian, “Crazyswarm: A large nano-quadcopter swarm,” in2017 IEEE International Con- ference on Robotics and Automation (ICRA), (Singapore, Singapore), pp. 3299–3304, IEEE, May 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.