The Digital Apprentice: A Framework for Human-Directed Agentic AI Development
Pith reviewed 2026-06-28 06:43 UTC · model grok-4.3
The pith
The Digital Apprentice framework lets AI agents earn autonomy through evidence-based tiers under human direction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Digital Apprentice is a developmental learner that internalizes the tacit methodology of a directing human, graduating through per-skill autonomy tiers only when empirical evidence justifies it. The result is an agent that becomes genuinely useful over time while remaining aligned to a specific human's standards. Three architectural components make this possible: (1) Methodology capture, distilling a directing professional's tacit approach into structured assets. (2) Authorization, with autonomy escalation gated by explicit human approval. (3) Continuous alignment, correcting drift at runtime and converting each correction into owned preference data. We instantiate this framework as an i
What carries the argument
The three architectural components—methodology capture, authorization with human-gated autonomy escalation, and continuous alignment—stitched together as an inference-time control plane.
If this is right
- Agents can scale in professional tasks while maintaining alignment to specific human standards.
- Autonomy increases only with empirical evidence, reducing risks of misalignment.
- Runtime corrections convert directly into owned preference data for ongoing improvement.
- Mathematical modeling of quality enables systematic policy and technique improvements.
- Application to professional corpora demonstrates recovery from performance degradation due to traffic shifts.
Where Pith is reading between the lines
- The framework could extend to domains like medicine or law where tacit professional judgment must be captured.
- Standardized capture methods across fields would be needed to generalize the approach beyond one expert.
- Real-time alignment mechanisms might reduce reliance on periodic full retraining cycles.
- Empirical tests of the system under multi-user direction could reveal interactions not addressed in single-human setups.
Load-bearing premise
The proposed methodology capture process can reliably distill a directing professional's tacit approach into structured assets that support empirical evidence-based autonomy graduation.
What would settle it
A controlled test in which captured methodology assets produce autonomy tier decisions that fail to match the directing human's own approvals on held-out tasks.
Figures
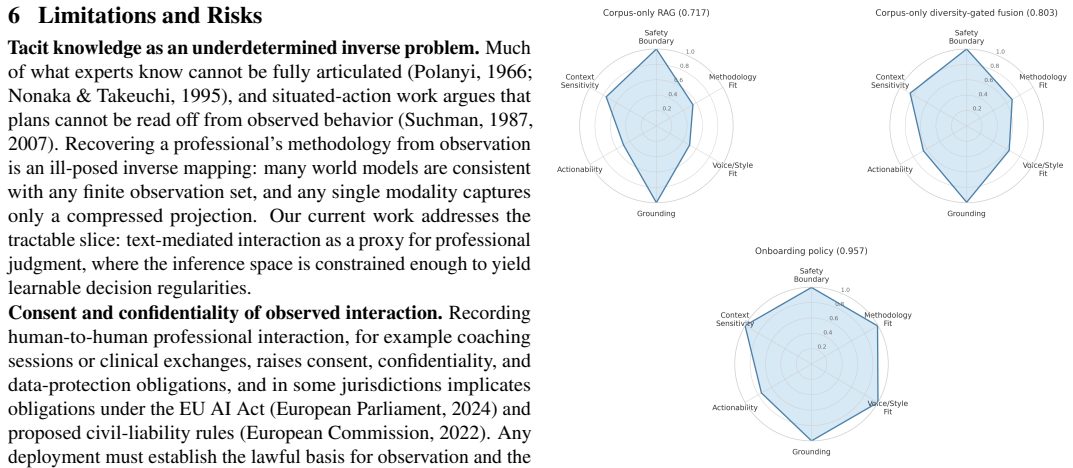
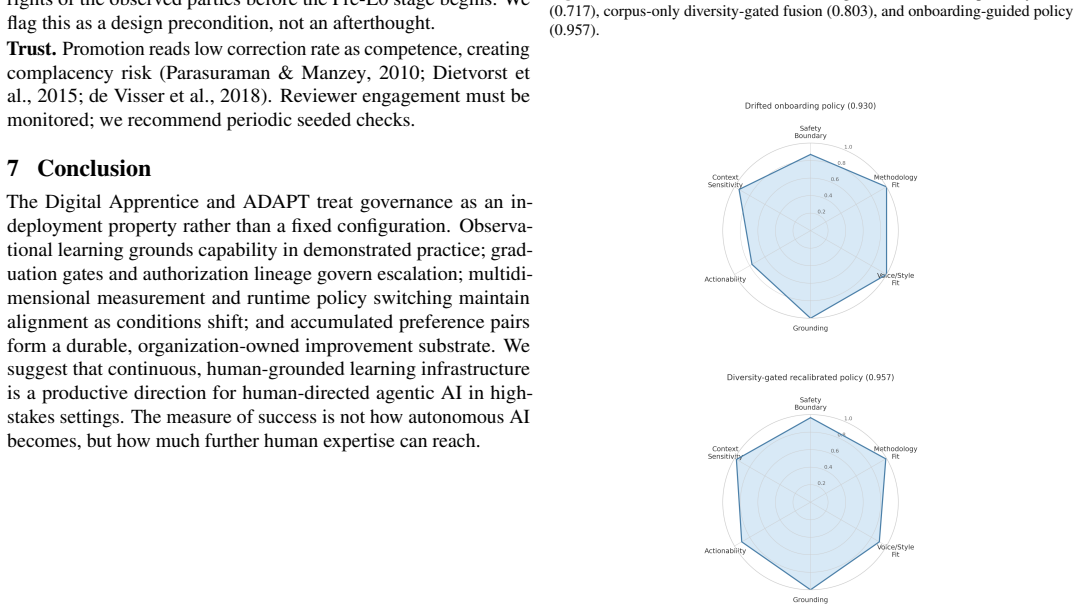
read the original abstract
Agentic AI deployments face a recurring design tension: heavy human oversight limits scale, while broad autonomy outruns accountability. Neither posture provides the governance infrastructure required for responsible delegation. We present the Digital Apprentice, a framework for scalable, safe AI agency in which autonomy is earned, not assumed. The Digital Apprentice is a developmental learner that internalizes the tacit methodology of a directing human, graduating through per-skill autonomy tiers only when empirical evidence justifies it. The result is an agent that becomes genuinely useful over time while remaining aligned to a specific human's standards. Three architectural components make this possible. (1) Methodology capture, distilling a directing professional's tacit approach into structured assets. (2) Authorization, with autonomy escalation gated by explicit human approval. (3) Continuous alignment, correcting drift at runtime and converting each correction into owned preference data. We instantiate this framework as an inference-time control plane. We mathematically model the quality framework and discuss policies and techniques designed to raise quality. We apply the framework to an open professional corpus, and we show how catching data drift and applying a different technique at runtime recovers degraded quality dimensions under traffic shift. The implication extends beyond any single application. We believe these three pillars, stitched together as a system, form a safer and more viable path to agentic systems that can scale without sacrificing trust.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Digital Apprentice framework for scalable, safe agentic AI in which autonomy is earned via empirical evidence rather than assumed. It consists of three components—methodology capture to distill a directing professional's tacit approach into structured assets, authorization with human-gated autonomy escalation, and continuous alignment that corrects drift at runtime while generating owned preference data—and claims to mathematically model the quality framework, instantiate it as an inference-time control plane, apply it to an open professional corpus, and demonstrate runtime recovery of degraded quality dimensions under traffic shift via data-drift detection and technique changes.
Significance. If the mathematical model and empirical application can be substantiated with explicit derivations and data, the framework would offer a concrete governance architecture for agentic systems that addresses the oversight-versus-autonomy tension through earned autonomy and human-in-the-loop mechanisms. The conversion of runtime corrections into preference data and the emphasis on per-skill graduation tiers represent potentially useful contributions to alignment and scaling discussions in AI agent design.
major comments (3)
- [Abstract] Abstract / description of the three components: The central claim that the three components together enable evidence-based autonomy graduation without trust loss rests on methodology capture reliably distilling tacit knowledge into structured assets that support empirical decisions; however, no mechanism, representation format, or validation step for this distillation process is supplied, leaving the prerequisite for the authorization and alignment components ungrounded.
- [Abstract] Abstract: The manuscript states that the quality framework is mathematically modeled and that policies and techniques are discussed to raise quality, yet no equations, formal definitions, derivations, or parameter specifications appear, preventing evaluation of whether the model is independent of its inputs or supports the claimed runtime recovery.
- [Abstract] Abstract: The application to an open professional corpus is said to show recovery of quality dimensions under traffic shift by catching data drift and applying a different technique at runtime, but no metrics, error bars, baseline comparisons, or specific techniques are reported, rendering the empirical support for the framework's viability unassessable.
minor comments (1)
- [Abstract] The abstract refers to an 'open professional corpus' without naming the corpus or providing access details, which would aid reproducibility even in a framework paper.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments on the abstract. The feedback highlights areas where additional specificity will strengthen the presentation of the framework's components, model, and evaluation. We address each point below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract] Abstract / description of the three components: The central claim that the three components together enable evidence-based autonomy graduation without trust loss rests on methodology capture reliably distilling tacit knowledge into structured assets that support empirical decisions; however, no mechanism, representation format, or validation step for this distillation process is supplied, leaving the prerequisite for the authorization and alignment components ungrounded.
Authors: We agree that the abstract would benefit from explicit mention of the distillation mechanism. The manuscript details this in Section 3 as a combination of session logging, hierarchical task decomposition into structured assets, and validation through human expert review of the captured assets. In revision we will add a concise description of the representation format and validation step to the abstract. revision: yes
-
Referee: [Abstract] Abstract: The manuscript states that the quality framework is mathematically modeled and that policies and techniques are discussed to raise quality, yet no equations, formal definitions, derivations, or parameter specifications appear, preventing evaluation of whether the model is independent of its inputs or supports the claimed runtime recovery.
Authors: The quality framework receives a formal treatment in Section 4, including definitions of the quality dimensions, a drift-detection function, and the recovery policy. We acknowledge that the abstract omits these elements. In the revision we will include the core formal definitions and note the key parameters in the abstract to allow readers to assess the model. revision: yes
-
Referee: [Abstract] Abstract: The application to an open professional corpus is said to show recovery of quality dimensions under traffic shift by catching data drift and applying a different technique at runtime, but no metrics, error bars, baseline comparisons, or specific techniques are reported, rendering the empirical support for the framework's viability unassessable.
Authors: Section 5 presents the corpus application with quantitative results, including pre- and post-correction quality scores, a baseline comparison, and the specific drift detector and technique switch employed. We will revise the abstract to summarize the reported metrics, the observed recovery, and the techniques used. revision: yes
Circularity Check
No circularity: framework proposal lacks derivations that reduce to inputs
full rationale
The paper presents a conceptual architecture for agentic AI consisting of three named components (methodology capture, authorization with human-gated escalation, and continuous alignment) without any equations, fitted parameters, or first-principles derivations shown. Claims such as distilling tacit methodology into structured assets or recovering quality dimensions are stated as design outcomes of the framework rather than results derived from prior quantities within the paper. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way, and the text supplies no reduction of any prediction to its own inputs by construction. The work is therefore self-contained as a proposed system description.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Tacit professional methodology can be distilled into structured assets that support empirical autonomy decisions
- domain assumption Human approval can be obtained at each autonomy escalation without creating prohibitive bottlenecks
invented entities (1)
-
Digital Apprentice
no independent evidence
Reference graph
Works this paper leans on
-
[1]
M., Fisk, A
Beer, J. M., Fisk, A. D., & Rogers, W. A. (2014). Toward a framework for levels of robot autonomy in human-robot interaction. Journal of Human-Robot Interaction, 3(2), 74--99
2014
-
[2]
F., et al
Christiano, P. F., et al. (2017). Deep reinforcement learning from human preferences. Advances in Neural Information Processing Systems, 30
2017
-
[3]
J., Pak, R., & Shaw, T
de Visser, E. J., Pak, R., & Shaw, T. H. (2018). From `automation' to `autonomy': The importance of trust repair in human--machine interaction. Ergonomics, 61(10), 1409--1427
2018
-
[4]
J., Simmons, J
Dietvorst, B. J., Simmons, J. P., & Massey, C. (2015). Algorithm aversion: People erroneously avoid algorithms after seeing them err. Journal of Experimental Psychology: General, 144(1), 114
2015
-
[5]
European Commission. (2022). Proposal for a Directive on adapting non-contractual civil liability rules to artificial intelligence (AI Liability Directive). COM/2022/496 final
2022
-
[6]
European Parliament and Council of the European Union. (2024). Regulation (EU) 2024/1689 laying down harmonised rules on artificial intelligence (Artificial Intelligence Act). Official Journal of the European Union, L 2024/1689
2024
- [7]
-
[8]
IMDA (Infocomm Media Development Authority). (2026). Model AI Governance Framework for Agentic AI. Singapore: IMDA. https://www.imda.gov.sg
2026
- [9]
- [10]
-
[11]
Nonaka, I., & Takeuchi, H. (1995). The Knowledge-Creating Company: How Japanese Companies Create the Dynamics of Innovation. Oxford University Press
1995
-
[12]
OpenRouter. (2024). OpenRouter: A unified interface for LLMs. https://openrouter.ai
2024
-
[13]
Ouyang, L., et al. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35
2022
-
[14]
Parasuraman, R., & Manzey, D. H. (2010). Complacency and bias in human use of automation: An attentional integration. Human Factors, 52(3), 381--410
2010
-
[15]
Polanyi, M. (1966). The Tacit Dimension. University of Chicago Press
1966
-
[16]
Rafailov, R., Sharma, A., Mitchell, E., et al. (2023). Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36
2023
-
[17]
Suchman, L. A. (1987). Plans and Situated Actions: The Problem of Human-Machine Communication. Cambridge University Press
1987
-
[18]
Suchman, L. A. (2007). Human-Machine Reconfigurations: Plans and Situated Actions (2nd ed.). Cambridge University Press
2007
-
[19]
Wu, X., et al. (2022). A survey of human-in-the-loop for machine learning. Future Generation Computer Systems, 135, 364--381
2022
-
[20]
Zheng, L., et al. (2023). Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. Advances in Neural Information Processing Systems, 36
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.