Rethinking Sales Lead Scoring with LLM-based Hierarchical Preference Ranking
Pith reviewed 2026-06-28 04:41 UTC · model grok-4.3
The pith
An LLM framework with hierarchical preference ranking turns sparse sales labels into dense funnel pairs and raises conversion rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
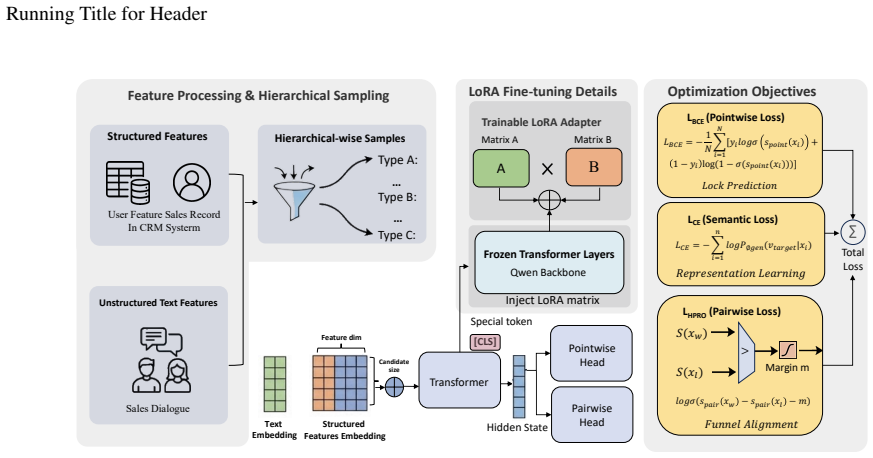
The central claim is that HPRO augments lead scoring by transforming sparse binary conversion labels into dense, funnel-aware preference pairs through a margin-aware Bradley-Terry formulation, enabling the model to use both pointwise and pairwise supervision while jointly modeling structured and unstructured data, which yields an AUC of 0.8161 and a 9.5 percent sales-volume increase in a 132-day online test.
What carries the argument
HPRO (Hierarchical Preference Ranking Optimization), which applies a margin-aware Bradley-Terry model to generate dense preference pairs from sparse binary labels that reflect hierarchical sales-funnel priorities.
If this is right
- Joint use of structured CRM features and unstructured interaction text closes the semantic gap that limits traditional pointwise models.
- The preference-ranking objective improves precision among the highest-ranked leads by 39.7 percent over prior methods.
- The same trained model produces both classification probabilities and relative rankings without separate heads.
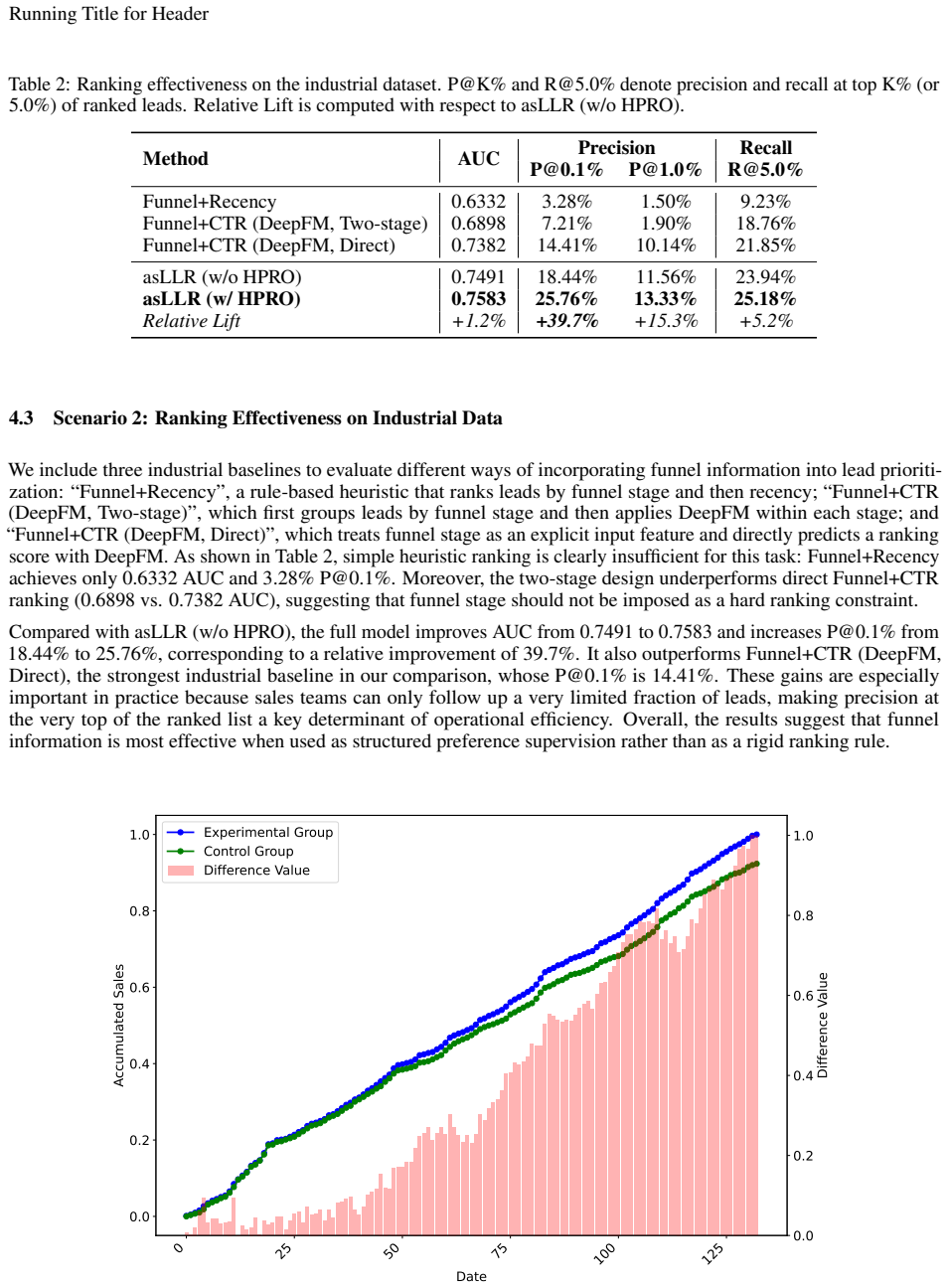
- The approach delivers a 9.5 percent sales-volume increase when deployed in a live 132-day A/B test on real customer leads.
Where Pith is reading between the lines
- The same preference-pair construction could be applied to other staged decision processes such as insurance underwriting or enterprise software sales where conversion labels are also sparse.
- If the Bradley-Terry margins are calibrated per funnel stage, the method might reduce systematic over- or under-ranking of leads that sit at particular decision points.
- Extending the framework to multi-turn customer dialogues would test whether the current single-interaction modeling already captures enough of the prolonged decision cycle.
Load-bearing premise
The margin-aware Bradley-Terry formulation can turn sparse binary labels into unbiased, funnel-aware preference pairs without distortion from the multi-stage structure or from LLM semantic modeling.
What would settle it
A controlled comparison in which the preference-pair component is removed and ranking or sales-lift performance drops to or below the pointwise baseline would falsify the claimed benefit of the transformation.
Figures
read the original abstract
Sales lead conversion in high-stakes domains (e.g., automotive, real estate) differs fundamentally from e-commerce recommendation due to prolonged decision cycles and multi-stage funnels. Traditional lead scoring methods rule-based scorecards, machine learning, or pointwise CTR models face severe challenges: sparse supervision, a semantic gap in unstructured CRM logs, and inability to capture relative lead priority. While Large Language Models(LLMs) offer superior semantic understanding of customer interactions, general-purpose LLMs are ill-suited for lead ranking: they generate text rather than comparable scores, and lack alignment with the hierarchical priorities of sales funnels. We introduce an LLM-based discriminative framework for sales lead scoring, which supports joint modeling of structured CRM features and unstructured customer interactions. On top of this framework, we propose HPRO (Hierarchical Preference Ranking Optimization), which augments sales lead scoring with a hierarchical preference ranking objective. HPRO employs a margin-aware Bradley-Terry formulation to transform sparse binary labels into dense, funnel-aware preference pairs, enabling lead scoring to leverage both pointwise and pairwise supervision. Experiments on large-scale data from a leading NEV brand demonstrate state-of-the-art classification (AUC 0.8161) and ranking performance (+39.7% precision among top-ranked leads). A 132-day online A/B test validates 9.5% sales volume uplift, confirming real-world commercial impact.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an LLM-based discriminative framework for sales lead scoring that jointly models structured CRM features and unstructured interactions. It proposes HPRO, which augments this with a hierarchical preference ranking objective using a margin-aware Bradley-Terry formulation to convert sparse binary conversion labels into dense, funnel-aware preference pairs, enabling combined pointwise and pairwise supervision. Experiments on large-scale data from a leading NEV brand report state-of-the-art classification (AUC 0.8161) and ranking (+39.7% precision among top-ranked leads), with a 132-day online A/B test showing 9.5% sales volume uplift.
Significance. If the claims hold after validation of the preference construction, the work would advance lead scoring methods for prolonged, multi-stage decision processes by integrating LLM semantics with preference learning. The real-world A/B test provides direct evidence of commercial impact, which strengthens the practical significance beyond offline metrics.
major comments (3)
- [Abstract] Abstract: The headline claims of AUC 0.8161 and +39.7% top-k precision are presented without any reference to the specific baselines, data splits, or statistical significance tests used; this information is required to determine whether the reported gains are attributable to the HPRO objective rather than implementation details.
- [HPRO formulation] HPRO (margin-aware Bradley-Terry formulation): The central claim that this formulation reliably produces unbiased, funnel-aware preference pairs from sparse labels rests on an untested assumption that pair sampling across stages does not correlate with stage-specific conversion rates; no ablation, sensitivity analysis on the margin parameter, or correlation check is described to support this, which directly underpins the ranking performance and A/B uplift attribution.
- [Online A/B test] Online A/B test section: The reported 9.5% sales volume uplift over 132 days lacks any description of the randomization procedure, control group construction, or statistical testing for the lift; without these, the result cannot be confidently attributed to the model rather than external confounds.
minor comments (1)
- The abstract could include a short statement on the specific LLM backbone and the structured CRM features used to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below and commit to revisions that improve clarity without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims of AUC 0.8161 and +39.7% top-k precision are presented without any reference to the specific baselines, data splits, or statistical significance tests used; this information is required to determine whether the reported gains are attributable to the HPRO objective rather than implementation details.
Authors: The abstract provides a concise summary of results as is conventional. Full details on baselines (rule-based, ML, and LLM pointwise models), train/validation/test splits, and statistical significance (bootstrap confidence intervals and paired tests) appear in Section 4 and the appendix. We will revise the abstract to briefly reference the primary baselines and note statistical significance of the gains. revision: yes
-
Referee: [HPRO formulation] HPRO (margin-aware Bradley-Terry formulation): The central claim that this formulation reliably produces unbiased, funnel-aware preference pairs from sparse labels rests on an untested assumption that pair sampling across stages does not correlate with stage-specific conversion rates; no ablation, sensitivity analysis on the margin parameter, or correlation check is described to support this, which directly underpins the ranking performance and A/B uplift attribution.
Authors: Section 3.2 describes the margin-aware Bradley-Terry construction and hierarchical sampling explicitly designed to respect funnel stages. The formulation mitigates bias by construction through stage-aware margins. We agree additional validation strengthens the paper and will add an ablation on the margin parameter, sensitivity analysis, and a post-hoc correlation check between sampling and stage conversion rates in the revision. revision: yes
-
Referee: [Online A/B test] Online A/B test section: The reported 9.5% sales volume uplift over 132 days lacks any description of the randomization procedure, control group construction, or statistical testing for the lift; without these, the result cannot be confidently attributed to the model rather than external confounds.
Authors: We agree the description is insufficiently detailed. The experiment used user-level randomization with the production model as control; lift significance was evaluated via two-sample t-test. We will expand the online A/B test section to explicitly document the randomization procedure, control construction, and statistical testing. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces HPRO as a novel augmentation to lead scoring via margin-aware Bradley-Terry pair construction from binary labels, followed by joint pointwise+pairwise training. Reported metrics (AUC 0.8161, +39.7% top-k precision, 9.5% A/B uplift) are measured on held-out large-scale data and a separate 132-day online experiment; these are external evaluations, not quantities forced by construction from the input labels or the pair-generation step itself. No self-definitional reductions, fitted-input predictions, or load-bearing self-citations appear in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A framework for customer relationship management.California management review, 43(4):89– 105, 2001
Russell S Winer. A framework for customer relationship management.California management review, 43(4):89– 105, 2001
2001
-
[2]
A strategic framework for customer relationship management.Journal of marketing, 69(4):167–176, 2005
Adrian Payne and Pennie Frow. A strategic framework for customer relationship management.Journal of marketing, 69(4):167–176, 2005
2005
-
[3]
The state of lead scoring models and their impact on sales performance.Information Technology and Management, 25(1):69–98, 2024
Migao Wu, Pavel Andreev, and Morad Benyoucef. The state of lead scoring models and their impact on sales performance.Information Technology and Management, 25(1):69–98, 2024
2024
-
[4]
Lead Scoring in SAP CRM, 2022
SAP. Lead Scoring in SAP CRM, 2022. Accessed: 2025-05-20
2022
-
[5]
AI Predictive Lead Scoring, 2023
Act-On. AI Predictive Lead Scoring, 2023. Accessed: 2025-05-20
2023
-
[6]
Mastering the digital transformation of sales.California Management Review, 62(4):57–85, 2020
Paolo Guenzi and Johannes Habel. Mastering the digital transformation of sales.California Management Review, 62(4):57–85, 2020
2020
-
[7]
Industrial sales lead conversion modeling.Marketing Intelligence & Planning, 29(2):178–194, 2011
Jamie P Monat. Industrial sales lead conversion modeling.Marketing Intelligence & Planning, 29(2):178–194, 2011
2011
-
[8]
Wide & deep learning for recommender systems
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. Wide & deep learning for recommender systems. InProceedings of the 1st workshop on deep learning for recommender systems, pages 7–10, 2016
2016
-
[9]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. Deepfm: a factorization-machine based neural network for ctr prediction.arXiv preprint arXiv:1703.04247, 2017
Pith/arXiv arXiv 2017
-
[10]
Digital transformation: A multidisciplinary reflection and research agenda.Journal of business research, 122:889–901, 2021
Peter C Verhoef, Thijs Broekhuizen, Yakov Bart, Abhi Bhattacharya, John Qi Dong, Nicolai Fabian, and Michael Haenlein. Digital transformation: A multidisciplinary reflection and research agenda.Journal of business research, 122:889–901, 2021
2021
-
[11]
Niladri Syam and Arun Sharma. Waiting for a sales renaissance in the fourth industrial revolution: Machine learning and artificial intelligence in sales research and practice.Industrial marketing management, 69:135–146, 2018
2018
-
[12]
Necessary condition analysis for sales funnel optimization.Journal of marketing analytics, pages 1–13, 2025
Richard Conde. Necessary condition analysis for sales funnel optimization.Journal of marketing analytics, pages 1–13, 2025
2025
-
[13]
The three stages of lead scoring: Lambs, ducks & kudus
L Boogar. The three stages of lead scoring: Lambs, ducks & kudus. the madkudu blog post, 2019
2019
-
[14]
Trends in machine learning applied to demand & sales forecasting: A review
Juan Pablo Usuga Cadavid, Samir Lamouri, and Bernard Grabot. Trends in machine learning applied to demand & sales forecasting: A review. InInternational conference on information systems, logistics and supply chain, 2018
2018
-
[15]
The evolution from traditional to predictive lead scoring
D McDonnell. The evolution from traditional to predictive lead scoring. demand gen report, 2019
2019
-
[16]
The relevance of lead prioritization: a b2b lead scoring model based on machine learning.Frontiers in Artificial Intelligence, 8:1554325, 2025
Laura González-Flores, Jessica Rubiano-Moreno, and Guillermo Sosa-Gómez. The relevance of lead prioritization: a b2b lead scoring model based on machine learning.Frontiers in Artificial Intelligence, 8:1554325, 2025. 7 Running Title for Header
2025
-
[17]
Assessing the success of automotive sales transactions using selected machine learning algorithms.Applied Sciences, 15(21):11562, 2025
Mateusz Mazur, Ondrej Stopka, Mária Stopková, Jiˇrí Hanzl, Anna Borucka, and Robert Czerniak. Assessing the success of automotive sales transactions using selected machine learning algorithms.Applied Sciences, 15(21):11562, 2025
2025
-
[18]
Smart sales: amplifying the power of predictive lead scoring in b2b sales
Migao Wu, Pavel Andreev, and Morad Benyoucef. Smart sales: amplifying the power of predictive lead scoring in b2b sales. 2024
2024
-
[19]
Random forest versus logistic regression: a large-scale benchmark experiment.BMC bioinformatics, 19(1):270, 2018
Raphael Couronné, Philipp Probst, and Anne-Laure Boulesteix. Random forest versus logistic regression: a large-scale benchmark experiment.BMC bioinformatics, 19(1):270, 2018
2018
-
[20]
Deep & cross network for ad click predictions
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. Deep & cross network for ad click predictions. In Proceedings of the ADKDD’17, pages 1–7. 2017
2017
-
[21]
xdeepfm: Combining explicit and implicit feature interactions for recommender systems
Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. xdeepfm: Combining explicit and implicit feature interactions for recommender systems. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 1754–1763, 2018
2018
-
[22]
Autoint: Automatic feature interaction learning via self-attentive neural networks
Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. Autoint: Automatic feature interaction learning via self-attentive neural networks. InProceedings of the 28th ACM international conference on information and knowledge management, pages 1161–1170, 2019
2019
-
[23]
Generative ai at work.The Quarterly Journal of Economics, 140(2):889–942, 2025
Erik Brynjolfsson, Danielle Li, and Lindsey Raymond. Generative ai at work.The Quarterly Journal of Economics, 140(2):889–942, 2025
2025
-
[24]
Experimental evidence on the productivity effects of generative artificial intelligence.Science, 381(6654):187–192, 2023
Shakked Noy and Whitney Zhang. Experimental evidence on the productivity effects of generative artificial intelligence.Science, 381(6654):187–192, 2023
2023
-
[25]
Crmarena: Understanding the capacity of llm agents to perform professional crm tasks in realistic environments
Kung-Hsiang Huang, Akshara Prabhakar, Sidharth Dhawan, Yixin Mao, Huan Wang, Silvio Savarese, Caiming Xiong, Philippe Laban, and Chien-Sheng Wu. Crmarena: Understanding the capacity of llm agents to perform professional crm tasks in realistic environments. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for C...
2025
-
[26]
Kung-Hsiang Huang, Akshara Prabhakar, Onkar Thorat, Divyansh Agarwal, Prafulla Kumar Choubey, Yixin Mao, Silvio Savarese, Caiming Xiong, and Chien-Sheng Wu. Crmarena-pro: Holistic assessment of llm agents across diverse business scenarios and interactions.arXiv preprint arXiv:2505.18878, 2025
arXiv 2025
-
[27]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[28]
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[29]
Orpo: Monolithic preference optimization without reference model
Jiwoo Hong, Noah Lee, and James Thorne. Orpo: Monolithic preference optimization without reference model. arXiv preprint arXiv:2403.07691, 2024
Pith/arXiv arXiv 2024
-
[30]
A comprehensive survey on graph neural networks.IEEE transactions on neural networks and learning systems, 32(1):4–24, 2020
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S Yu. A comprehensive survey on graph neural networks.IEEE transactions on neural networks and learning systems, 32(1):4–24, 2020
2020
-
[31]
Graphfm: Improving large- scale gnn training via feature momentum
Haiyang Yu, Limei Wang, Bokun Wang, Meng Liu, Tianbao Yang, and Shuiwang Ji. Graphfm: Improving large- scale gnn training via feature momentum. InInternational conference on machine learning, pages 25684–25701. PMLR, 2022
2022
-
[32]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
2022
-
[33]
Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems
Ruoxi Wang, Rakesh Shivanna, Derek Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed Chi. Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. InProceedings of the web conference 2021, pages 1785–1797, 2021. 8
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.