Knockoffs-based False Discovery Rate Control and Simplification for Deep Neural Networks
Pith reviewed 2026-06-28 04:33 UTC · model grok-4.3
The pith
Knockoff methods can screen input variables in deep neural networks while controlling the false discovery rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
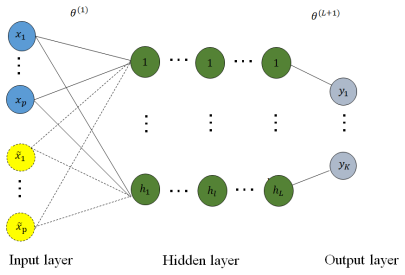
Building on knockoff methods and using the regularised neural network, the paper proposes three variable screening methods under the condition of controlling false discovery rates: one layer filter, multiple layers filter, variable weight aggregation filter. In comparison with existing algorithms, the algorithms show satisfactory performance.
What carries the argument
The three variable screening filters that apply knockoff statistics to the weights or activations of a regularized deep neural network to select variables while bounding the false discovery rate.
If this is right
- The one layer filter enables screening focused on individual network layers while preserving FDR guarantees.
- The multiple layers filter incorporates information across network depths for variable decisions.
- The variable weight aggregation filter combines weights to produce more stable selection under FDR control.
- All three methods reduce the number of irrelevant inputs or parameters fed into the network.
- The procedures maintain the error-rate control property of classical knockoffs when transferred to regularized neural networks.
Where Pith is reading between the lines
- If the methods succeed, they could be tested on whether they also improve out-of-sample prediction by removing noise variables.
- The same knockoff adaptation might apply to other black-box models whose internal representations can be regularized.
- Performance comparisons in the paper leave open whether one filter dominates the others across different network depths or data regimes.
Load-bearing premise
The exchangeability and other statistical properties required for valid knockoff-based FDR control in linear regression continue to hold when the same framework is applied to the weights or activations of a regularized deep neural network.
What would settle it
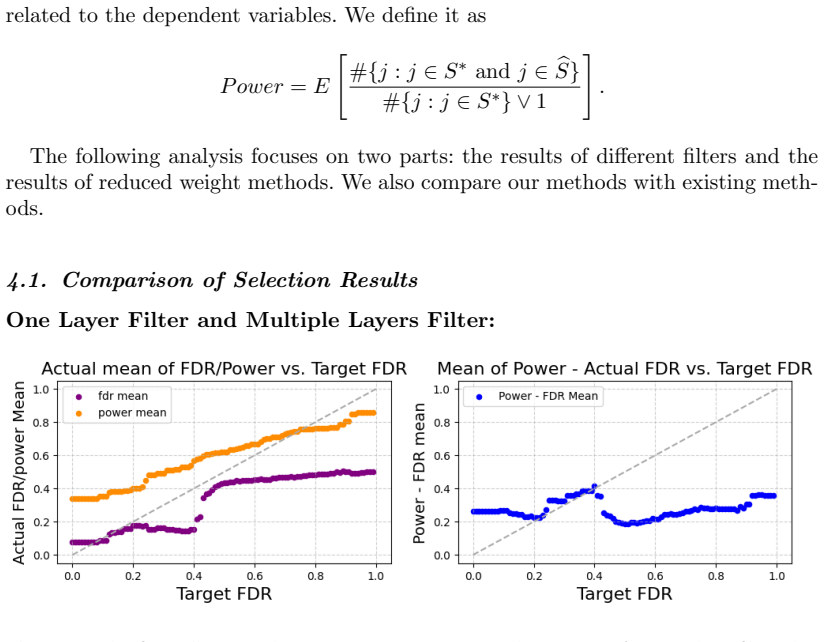
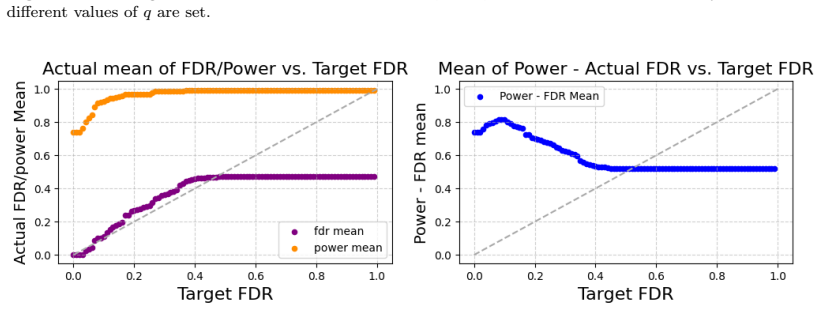
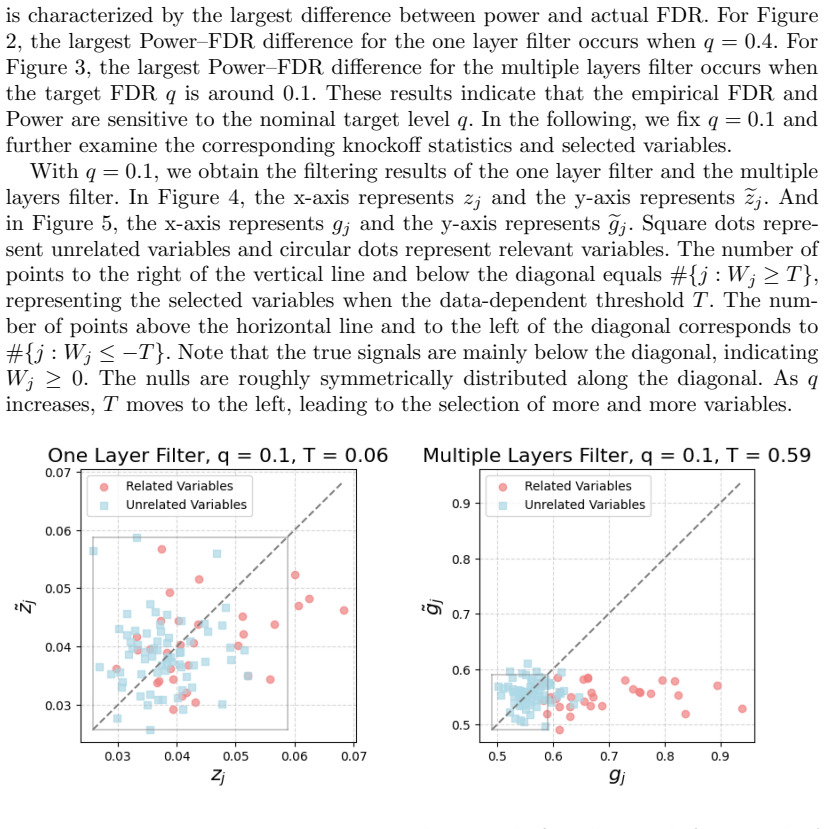
A simulation study with known ground-truth relevant variables where the observed false discovery proportion for each proposed filter exceeds the target FDR level at the nominal threshold.
Figures
read the original abstract
The deep neural network is a widely used framework in machine learning that has been widely applied in various fields. However, deep neural networks often involve a large number of parameters and inputs, many of which may be irrelevant to the goal or true output. These parameters and \textcolor{black}{input variables} not only increase computational complexity, but also contribute to additional computational cost. One solution to this problem is knockoff methods, which have proven successful in controlling false discovery rates in high-dimensional regression. Building on the knockoff methods and using the regularised neural network, this paper proposes three variable screening methods under the condition of controlling false discovery rates: \textit{one layer filter}, \textit{multiple layers filter}, \textit{variable weight aggregation filter}. In comparison with existing algorithms, we find that our algorithms show satisfactory performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes three knockoff-based variable screening procedures for regularized deep neural networks (one-layer filter, multiple-layers filter, and variable weight aggregation filter) that are asserted to control the false discovery rate while simplifying the network; empirical comparisons are claimed to show satisfactory performance relative to existing algorithms.
Significance. If the FDR guarantees transfer, the work would provide a principled extension of knockoff methods beyond linear models, enabling controlled variable selection and network simplification in high-dimensional DNN settings.
major comments (2)
- [Abstract] Abstract: the central claim that the three filters control FDR is unsupported by any derivation or argument showing that the exchangeability (and sign-flip) properties required for valid knockoff FDR control continue to hold when the procedure is applied to DNN weights or activations rather than linear regression coefficients.
- The manuscript supplies no statement of the knockoff statistic constructed from the regularized network, no proof that the nonlinear mappings and shared parameters preserve the necessary symmetry, and no experimental protocol detailing how the regularization interacts with the knockoff generation step; without these the FDR claim cannot be evaluated.
minor comments (1)
- [Abstract] The abstract contains the LaTeX artifact '\textcolor{black}{input variables}' that should be removed in the final version.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the current version lacks explicit derivations and definitions supporting the FDR claims and will revise accordingly to address these gaps.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the three filters control FDR is unsupported by any derivation or argument showing that the exchangeability (and sign-flip) properties required for valid knockoff FDR control continue to hold when the procedure is applied to DNN weights or activations rather than linear regression coefficients.
Authors: We agree that the manuscript does not currently include a derivation establishing that exchangeability and sign-flip properties hold when knockoffs are applied to DNN weights or activations. In the revision we will add a dedicated theoretical section deriving these properties for the one-layer, multiple-layers, and variable-weight-aggregation filters, showing how the regularized network mappings preserve the required symmetry. revision: yes
-
Referee: The manuscript supplies no statement of the knockoff statistic constructed from the regularized network, no proof that the nonlinear mappings and shared parameters preserve the necessary symmetry, and no experimental protocol detailing how the regularization interacts with the knockoff generation step; without these the FDR claim cannot be evaluated.
Authors: We acknowledge that the manuscript omits an explicit definition of the knockoff statistic, a proof of symmetry preservation under nonlinear mappings and shared parameters, and details on regularization-knockoff interaction. The revised manuscript will include: (i) a precise statement of the statistic derived from the regularized network, (ii) a proof that the necessary symmetry is preserved, and (iii) an expanded methods section specifying the experimental protocol for regularization and knockoff generation. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and context describe an application of existing knockoff FDR methods to regularized DNN weights/activations via three proposed filters. No equations, self-citations, or fitted quantities are shown that reduce any claimed prediction or guarantee to an input by construction. The exchangeability assumption for DNNs is an external modeling choice rather than a self-referential step. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Knockoff exchangeability properties hold for DNN parameters under regularization
Reference graph
Works this paper leans on
-
[1]
Abramovich, F. (2006). Adapting to unknown sparsity by controlling the false discovery rate.Annals of Statistics, 34(2): 205-208
2006
-
[2]
Bai, J., Song, Q., & Cheng, G. (2020). Efficient variational inference for sparse deep learning with theoretical guarantee.Advances in Neural Information Processing Sys- tems, 33, 466-476
2020
-
[3]
Barber, R. F. & Cand` es, E. J. (2015). Controlling the false discovery rate via knockoffs. Annals of Statistics, 43(5): 2055-2085
2015
-
[4]
Barber, R. F. & Emmanuel J. Cand` es. (2019). A knockoff filter for high-dimensional selective inference.arXiv: 1602.03574
Pith/arXiv arXiv 2019
-
[5]
Benjamini, Y. (2009). A simple forward selection procedure based on false discovery rate control.The Annals of Applied Statistics, 3(1): 179-198
2009
-
[6]
& Yekutieli, D
Benjamini, Y. & Yekutieli, D. (2001). The control of the false discovery rate in multiple testing under dependency.Annals of Statistics, 29(4): 1165-1188
2001
-
[7]
Candes, E. (2018). Panning for gold: ‘model-X’ knockoffs for high dimensional con- trolled variable selection.arXiv: 1610.02351
Pith/arXiv arXiv 2018
-
[8]
Chen, W., Noble, W. S., & Lu, Y. Y. (2023). DeepROCK: Error-controlled interaction detection in deep neural networks.arXiv: 2309.15319
arXiv 2023
-
[9]
Chen, Y., Gao, H., Liang, F., & Wang, X. (2021). Nonlinear variable selection via deep neural networks.Journal of Computational and Graphical Statistics, 30(2): 484–492
2021
-
[10]
Dietterich, T.G. (2000). Ensemble methods in machine learning. In: Multiple Classifier systems.Lecture Notes in Computer Science, 1857. Springer, Berlin, Heidelberg. 1-15
2000
-
[11]
C., & Ho, L
Dinh, V. C., & Ho, L. S. (2020). Consistent feature selection for analytic deep neural networks.Advances in Neural Information Processing Systems, 33: 2420-2431
2020
-
[12]
Dziugaite, G. K., Roy, D. M., & Ghahramani, Z. (2015). Training generative neural networks via maximum mean discrepancy optimization.arXiv: 1505.03906
Pith/arXiv arXiv 2015
-
[13]
F., Sriram, A., et al
Fan, Z., Kernan, K. F., Sriram, A., et al. (2023). Deep neural networks with knockoff 21 features identify nonlinear causal relations and estimate effect sizes in complex biolog- ical systems.GigaScience, 12: 1-18
2023
-
[14]
Ghosh , S., Yao, J., & Doshi-Velez, F. (2019). Model Selection in Bayesian Neural Networks via Horseshoe Priors.J. Mach. Learn. Res, 20(182): 1-46
2019
-
[15]
Ithapu, V. K., Ravi, S. N., & Singh, V. (2017). On architectural choices in deep learn- ing: from network structure to gradient convergence and parameter estimation.arXiv: 1702.08670
Pith/arXiv arXiv 2017
-
[16]
Jordon, J., Yoon, J., & Schaar, M. V. (2019). KnockoffGAN: Generating knockoffs for feature selection using generative adversarial networks.International Conference on Learning Representations
2019
-
[17]
H., Fred, L., Yann, L
Kassani, P. H., Fred, L., Yann, L. G., Belloy, M. E., & Zihuai, H. (2022). Deep neural networks with controlled variable selection for the identification of putative causal genetic variants.Nature Machine Intelligence, 9(4): 761-771
2022
-
[18]
Kurz, M. S. (2022). Vine copula based knockoff generation for high-dimensional con- trolled variable selection.arXiv: 2210.11196
arXiv 2022
-
[19]
Lin, W. Y. & Lee, W. C. (2012). Improving Power of genome-wide association studies with weighted false discovery rate control and prioritized subset analysis.PLoS One, 7(4): e33716
2012
-
[20]
Liu, T., Melnikov, K., & Penin, A. A. (2019). Nonfactorizable QCD effects in Higgs boson production via vector boson fusion.Physical review letters, 123(12): 122002
2019
-
[21]
Lu, Y., Fan, Y., Lv, J., & Stafford Noble, W. (2018). DeepPINK: reproducible feature selection in deep neural networks.Advances in Neural Information Processing Systems, 31
2018
-
[22]
Miller, K., Alfaro-Almagro, F., Bangerter, N., et al. (2016). Multimodal population brain imaging in the UK Biobank prospective epidemiological study.Nature Neuro- science, 19(11): 1523-1536
2016
-
[23]
Pienta K. J. & Coffey D. S.(1991) Correlation of nuclear morphometry with progression of breast cancer.Cancer, 68(9): 2012-2016
1991
-
[24]
Reimand, J., Isserlin, R., Voisin, V., . et al. (2019). Pathway enrichment analysis and visualization of omics data using g: Profiler, GSEA, Cytoscape and EnrichmentMap. Nature Protocols, 14(2): 482-517
2019
-
[25]
Romano, Y., Sesia, M., & Cand` es, E. (2020). Deep knockoffs.Journal of the American Statistical Association, 115(532): 1861-1872
2020
-
[26]
Sesia, M., Sabatti, C., & Cand` es, E. J. (2019). Gene hunting with hidden Markov model knockoffs.Biometrika, 106(1): 1-18
2019
-
[27]
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: a simple way to prevent neural networks from overfitting.The journal of Machine Learning Research, 15(1): 1929-1958
2014
-
[28]
Taheri, M., Xie, F., & Lederer, J. (2021). Statistical guarantees for regularized neural networks.Neural Networks, 142: 148-161
2021
-
[29]
& Lederer, J
Xie, F. & Lederer, J. (2021). Aggregating knockoffs for false discovery rate control with an application to gut microbiome data.Entropy, 23(2): 230
2021
-
[30]
Xu, K., Fukuchi, K., Akimoto, Y., & Sakuma, J. (2023). Statistically significant concept-based explanation of image classifiers via model knockoffs.arXiv: 2305.18362
arXiv 2023
-
[31]
Yasuda, T., Bateni, M., Chen, L., Fahrbach, M., Fu, G., & Mirrokni, V. (2022). Se- quential attention for feature selection.arXiv:2209.14881
arXiv 2022
-
[32]
M., & Pal, N
Zhang, H., Wang, J., Sun, Z., Zurada, J. M., & Pal, N. R. (2019). Feature selection for neural networks using group lasso regularization.IEEE Transactions on Knowledge and Data Engineering, 32(4): 659-673
2019
-
[33]
Zhu, Z., Fan, Y., Kong, Y., Lv, J., & Sun, F. (2021). DeepLINK: deep learning inference using knockoffs with applications to genomics.Proceedings of the National Academy of Sciences, 118(36): e2104683118. 22 Appendix A. Simulation: Results of Reduce Weight (Section 4.2) Figure A1.Reduce weight results for OL and ML filter when deletion ratec= 0.5 Figure A...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.