Multi-SPIN: Multi-Access Speculative Inference for Cooperative Token Generation at the Edge
Pith reviewed 2026-06-28 04:37 UTC · model grok-4.3
The pith
Multi-SPIN deploys speculative inference across edge devices and a server so that on-device small models draft tokens for batched verification, raising sum token goodput up to 88 percent through joint draft-length and bandwidth control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
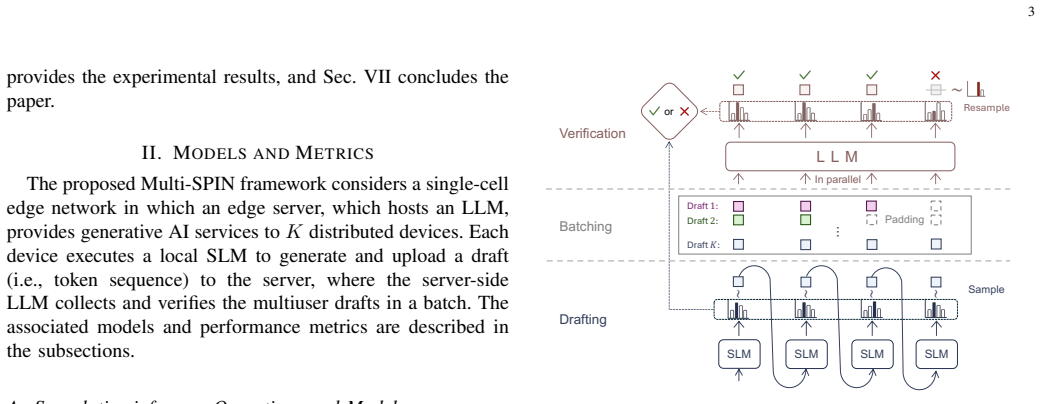
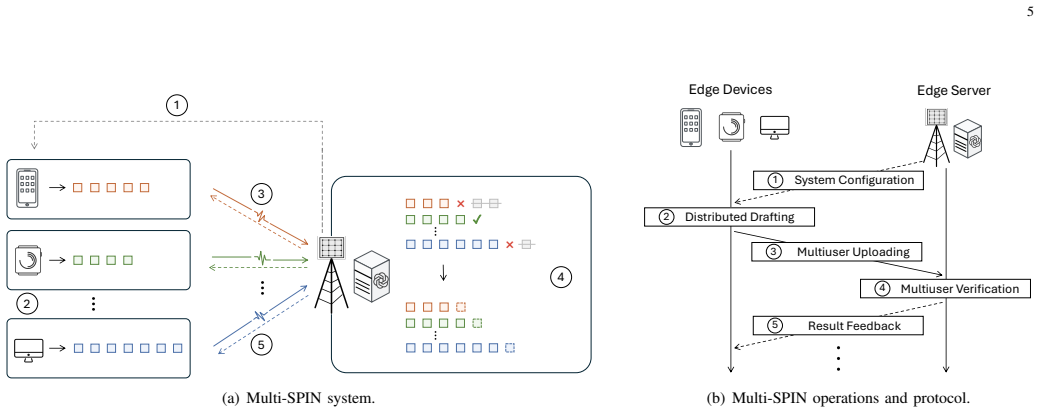
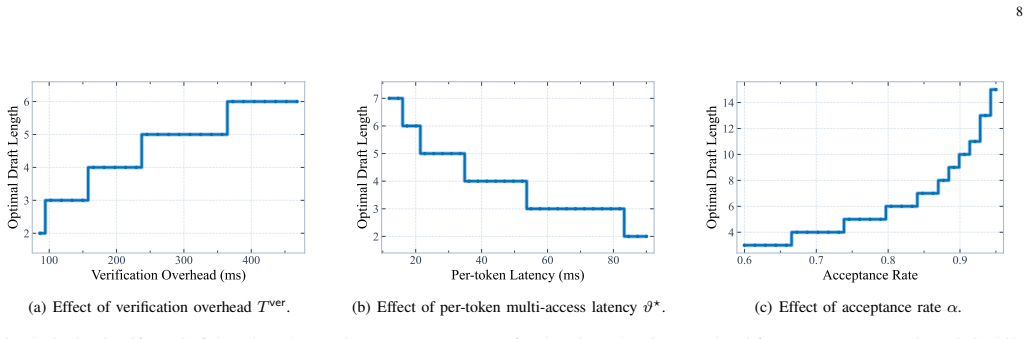
Multi-SPIN reduces the problem of cooperative token generation to a joint optimization of per-user draft lengths and bandwidth shares that maximizes total accepted tokens per unit time. In the homogeneous-draft case the optimum compensates users with weaker compute and communication links to satisfy batch synchronization; in the heterogeneous-draft case the optimum instead rewards users whose drafts are accepted at higher rates. Both problems decompose into tractable subproblems whose solutions are explicit functions of each user's compute time, channel gain, and observed acceptance rate.
What carries the argument
Multi-access draft control, the joint optimization of draft lengths and FDMA bandwidth allocations that governs sum token goodput.
If this is right
- In the homogeneous case bandwidth is deliberately given to weaker users to meet batch synchronization constraints.
- In the heterogeneous case bandwidth is given to users with higher acceptance rates because synchronization is no longer required.
- Decomposition yields closed-form draft-length rules that can be recomputed at each control interval.
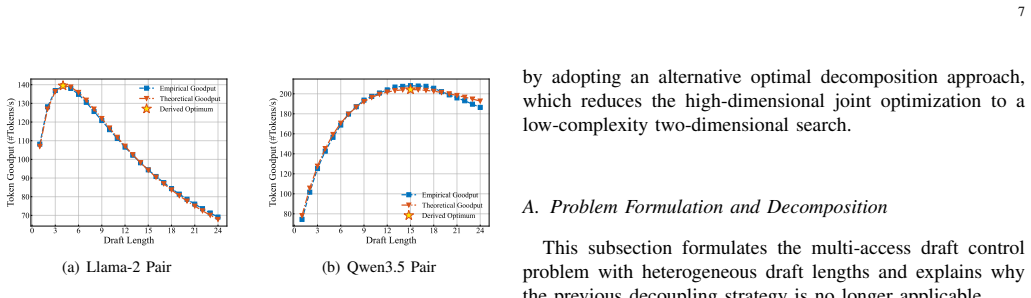
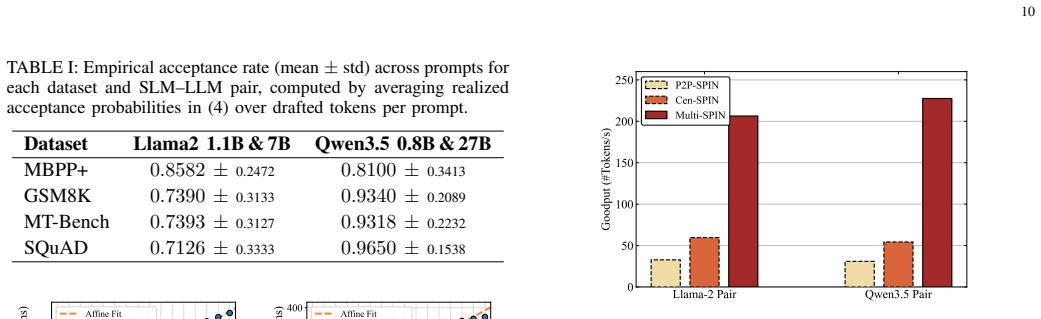
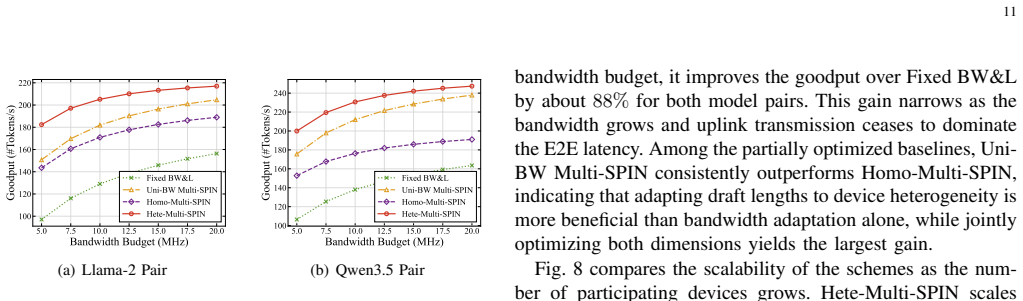
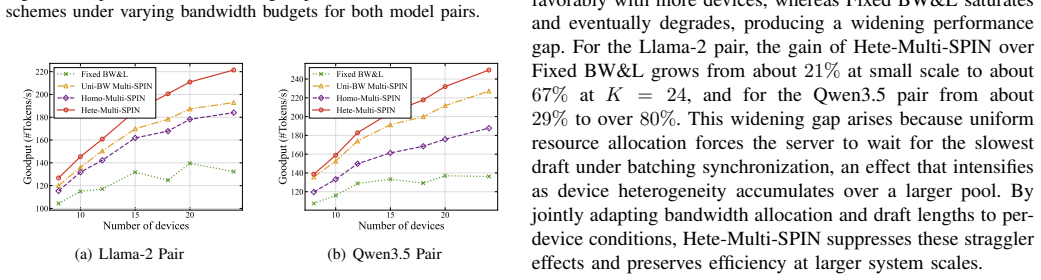
- The 88 percent goodput gain is measured on Llama-2 and Qwen3.5 model pairs over diverse tasks.
Where Pith is reading between the lines
- Acceptance rate becomes a natural priority metric for scheduling future inference requests in the same edge system.
- The same draft-control logic could be applied to any speculative decoding pipeline once a batch-verification primitive exists.
- Device heterogeneity changes from a liability to an asset when draft lengths are chosen per user rather than forced uniform.
Load-bearing premise
Small on-device models must produce drafts whose acceptance rates are high enough that the added communication and synchronization overhead still yields net gains over direct server inference for heterogeneous users.
What would settle it
An experiment in which measured acceptance rates fall low enough that total goodput under the derived draft controls drops below the goodput of a heterogeneity-agnostic baseline that sends no drafts.
Figures

read the original abstract
Speculative inference (SPIN) was originally developed as an efficient architecture to accelerate Large Language Models (LLMs). In this work, we propose its distributed deployment to enable cooperative token generation in a multiuser edge system; its advantage is to effectively balance computational loads between resource-constrained devices and servers. The resulting architecture, termed Multi-access SPIN (Multi-SPIN), utilizes on-device small language models to generate and upload candidate token drafts, while an edge server operates the LLM to verify them in parallel batches. Given the severe heterogeneity in users' computation and communication capabilities, the draft length emerges as a critical control variable that influences node-level computation loads and multi-access latency, thereby governing the sum token goodput. Consequently, considering frequency-division multiple access, we investigate the problem of multi-access draft control, a joint optimization of draft-length control and bandwidth allocation to maximize sum token goodput. We examine two cases: (1) homogeneous draft lengths across users to facilitate server-side batching, and (2) heterogeneous draft lengths to introduce a new dimension for goodput enhancement. By developing decomposition methods, we reduce these complex optimizations into tractable sub-problems, which allow efficient draft control algorithms to be derived in closed form. Our analysis shows that the optimal bandwidth allocation compensates users with weaker computation-and-communication capabilities in the homogeneous case due to the batching synchronization requirements, whereas its heterogeneous-case counterpart rewards users with higher acceptance rates by relaxing such requirements. Experiments using Llama-2 and Qwen3.5 model pairs across diverse tasks demonstrate that Multi-SPIN improves goodput by up to 88% over heterogeneity-agnostic baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Multi-SPIN, extending speculative inference to a multi-user edge setting where on-device small language models generate token drafts that a server LLM verifies in parallel batches. It formulates the multi-access draft control problem as a joint optimization of draft lengths and bandwidth allocation (under FDMA) to maximize sum token goodput, considering both homogeneous draft lengths (to enable batching) and heterogeneous draft lengths. Decomposition methods are claimed to yield closed-form draft-control algorithms; experiments with Llama-2/Qwen3.5 pairs report up to 88% goodput gains over heterogeneity-agnostic baselines.
Significance. If the derivations and experimental claims hold, the work addresses a practically relevant problem in distributed LLM inference by explicitly handling compute/communication heterogeneity and providing tractable control algorithms. The distinction between homogeneous and heterogeneous draft-length regimes and the closed-form solutions (if rigorously derived without hidden parameter dependence) would be a strength; the reported goodput gains, if reproducible with full acceptance-rate data, could influence edge AI system design.
major comments (3)
- [Abstract] Abstract: the claim that 'decomposition methods' reduce the optimizations to tractable sub-problems yielding 'closed-form' draft-control algorithms is presented without any equations, derivation steps, or acceptance-rate model; this is load-bearing for both the homogeneous/heterogeneous distinction and the 88% goodput result.
- [Abstract] Abstract and experimental description: no measured acceptance rates, no characterization of how acceptance probability varies with draft length or user heterogeneity, and no ablation showing when net gains disappear are provided; without these the central assumption that on-device SLM drafts offset communication and batch-synchronization overheads cannot be verified.
- [Abstract] Abstract: the 88% goodput improvement is stated without error bars, confidence intervals, or description of how post-hoc parameter choices affect the numbers, undermining the cross-task and cross-model-pair claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, with clarifications from the full paper and indications of where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'decomposition methods' reduce the optimizations to tractable sub-problems yielding 'closed-form' draft-control algorithms is presented without any equations, derivation steps, or acceptance-rate model; this is load-bearing for both the homogeneous/heterogeneous distinction and the 88% goodput result.
Authors: The abstract is a concise summary and omits equations per standard length limits. The acceptance-rate model (based on empirical token acceptance probabilities for SLM drafts) is defined in Section II, while the decomposition into tractable subproblems and resulting closed-form draft-length and bandwidth solutions for both homogeneous and heterogeneous cases are derived rigorously in Sections III and IV without hidden parameter dependence. We will revise the abstract to briefly reference the acceptance-rate model and note the closed-form derivations. revision: partial
-
Referee: [Abstract] Abstract and experimental description: no measured acceptance rates, no characterization of how acceptance probability varies with draft length or user heterogeneity, and no ablation showing when net gains disappear are provided; without these the central assumption that on-device SLM drafts offset communication and batch-synchronization overheads cannot be verified.
Authors: The experimental evaluation reports measured acceptance rates for Llama-2 and Qwen pairs across draft lengths and tasks. We will add an explicit characterization (e.g., acceptance vs. draft length curves under heterogeneity) and an ablation study in the revised experimental section to identify the regime where net goodput gains vanish, directly verifying the overhead-offset assumption. revision: yes
-
Referee: [Abstract] Abstract: the 88% goodput improvement is stated without error bars, confidence intervals, or description of how post-hoc parameter choices affect the numbers, undermining the cross-task and cross-model-pair claims.
Authors: The 88% value is the peak observed gain; the results section includes multiple runs. We will revise the abstract and results to report error bars/confidence intervals from repeated trials and explicitly describe the parameter selection process (including any post-hoc tuning) to support the cross-task and cross-model claims. revision: yes
Circularity Check
No significant circularity; optimization derives from external goodput metric.
full rationale
The paper poses a joint optimization over draft length and bandwidth allocation to maximize an externally defined sum token goodput metric under FDMA. It reduces the problem via decomposition into tractable sub-problems yielding closed-form algorithms for homogeneous and heterogeneous cases. No quoted equations, self-citations, or fitted parameters reduce any claimed result to its own inputs by construction. Experimental gains are reported against heterogeneity-agnostic baselines on Llama-2/Qwen3.5 pairs; the derivation chain remains independent of the target performance numbers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The roadmap to 6G: AI empowered wireless networks,
K. B. Letaief, W. Chen, Y . Shi, J. Zhang, and Y .-J. A. Zhang, “The roadmap to 6G: AI empowered wireless networks,”IEEE Commun. Mag., vol. 57, no. 8, pp. 84–90, 2019
2019
-
[2]
Toward an intelligent edge: Wireless communication meets machine learning,
G. Zhu, D. Liu, Y . Du, C. You, J. Zhang, and K. Huang, “Toward an intelligent edge: Wireless communication meets machine learning,” IEEE Commun. Mag., vol. 58, no. 1, pp. 19–25, 2020
2020
-
[3]
Resource allocation for multiuser edge inference with batching and early exiting,
Z. Liu, Q. Lan, and K. Huang, “Resource allocation for multiuser edge inference with batching and early exiting,”IEEE J. Sel. Areas Commun., vol. 41, no. 4, pp. 1186–1200, 2023
2023
-
[4]
PartialLoading: User scheduling and bandwidth allocation for parameter-sharing edge inference,
G. Qu, Q. Chen, X. Chen, K. Huang, and Y . Fang, “PartialLoading: User scheduling and bandwidth allocation for parameter-sharing edge inference,”arXiv:2503.22982, 2025
-
[5]
AI flow at the network edge,
J. Shao and X. Li, “AI flow at the network edge,”IEEE Netw., vol. 40, no. 1, pp. 330–336, 2026
2026
-
[6]
Fast inference from transform- ers via speculative decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast inference from transform- ers via speculative decoding,” inProc. Int. Conf. Mach. Learn. (ICML), Honolulu, HI, USA, 2023, pp. 19 274–19 286
2023
-
[7]
Efficient memory management for large language model serving with PagedAttention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with PagedAttention,” inProc. ACM Symp. Operating Syst. Princ. (SOSP), Koblenz, Germany, 2023, pp. 611–626
2023
-
[8]
EdgeShard: Efficient LLM inference via collaborative edge computing,
M. Zhang, X. Shen, J. Cao, Z. Cui, and S. Jiang, “EdgeShard: Efficient LLM inference via collaborative edge computing,”IEEE Internet Things J., vol. 12, no. 10, pp. 13 119–13 131, 2025
2025
-
[9]
Hybrid SLM and LLM for edge-cloud collaborative inference,
Z. Hao, H. Jiang, S. Jiang, J. Ren, and T. Cao, “Hybrid SLM and LLM for edge-cloud collaborative inference,” inProc. Workshop Edge Mobile Found. Models (EdgeFM), Minato-ku, Tokyo, Japan, 2024, pp. 36–41
2024
-
[10]
EdgeLLM: Fast on-device LLM inference with speculative decoding,
D. Xu, W. Yin, H. Zhang, X. Jin, Y . Zhang, S. Wei, M. Xu, and X. Liu, “EdgeLLM: Fast on-device LLM inference with speculative decoding,” IEEE Trans. Mobile Comput., vol. 24, no. 4, pp. 3256–3273, 2025
2025
-
[11]
SpecInfer: Accelerating large language model serving with tree-based speculative inference and veri- fication,
X. Miao, G. Oliaro, Z. Zhang, X. Cheng, Z. Wang, Z. Zhang, R. Y . Y . Wong, A. Zhu, L. Yang, X. Shiet al., “SpecInfer: Accelerating large language model serving with tree-based speculative inference and veri- fication,” inProc. ACM Int. Conf. Archit. Support Program. Lang. Oper. Syst. (ASPLOS), La Jolla, CA, USA, 2024, pp. 932–949
2024
-
[12]
Accelerating Large Language Model Decoding with Speculative Sampling
C. Chen, S. Borgeaud, G. Irving, J.-B. Lespiau, L. Sifre, and J. Jumper, “Accelerating large language model decoding with speculative sam- pling,”arXiv:2302.01318, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Edge AI: On-demand acceler- ating deep neural network inference via edge computing,
E. Li, L. Zeng, Z. Zhou, and X. Chen, “Edge AI: On-demand acceler- ating deep neural network inference via edge computing,”IEEE Trans. Wireless Commun., vol. 19, no. 1, pp. 447–457, 2020
2020
-
[14]
Communication-computation trade-off in resource-constrained edge inference,
J. Shao and J. Zhang, “Communication-computation trade-off in resource-constrained edge inference,”IEEE Commun. Mag., vol. 58, no. 12, pp. 20–26, 2020
2020
-
[15]
Optimal model placement and online model splitting for device-edge co-inference,
J. Yan, S. Bi, and Y .-J. A. Zhang, “Optimal model placement and online model splitting for device-edge co-inference,”IEEE Trans. Wireless Commun., vol. 21, no. 10, pp. 8354–8367, 2022
2022
-
[16]
Revisiting outage for edge inference systems,
Z. Wang, Q. Zeng, H. Zheng, and K. Huang, “Revisiting outage for edge inference systems,”arXiv:2504.03686, 2025
-
[17]
Airbreath sensing: Protecting over-the-air distributed sensing against interference,
Z. Wang, M. Cui, H. Yang, Q. Zeng, M. Sheng, and K. Huang, “Airbreath sensing: Protecting over-the-air distributed sensing against interference,”IEEE Trans. Wireless Commun., vol. 25, pp. 17 415– 17 429, 2026
2026
-
[18]
Knowledge-based ultra-low-latency semantic communications for robotic edge intelligence,
Q. Zeng, Z. Wang, Y . Zhou, H. Wu, L. Yang, and K. Huang, “Knowledge-based ultra-low-latency semantic communications for robotic edge intelligence,”IEEE Trans. Commun., vol. 73, no. 7, pp. 4925–4940, 2025
2025
-
[19]
Communication- efficient distributed on-device LLM inference over wireless networks,
K. Zhang, H. He, S. Song, J. Zhang, and K. B. Letaief, “Communication- efficient distributed on-device LLM inference over wireless networks,” IEEE J. Sel. Topics Signal Process., vol. 19, no. 7, pp. 1301–1317, 2025
2025
-
[20]
WDMoE: Wireless distributed mixture of experts for large language models,
N. Xue, Y . Sun, Z. Chen, M. Tao, X. Xu, L. Qian, S. Cui, W. Zhang, and P. Zhang, “WDMoE: Wireless distributed mixture of experts for large language models,”IEEE Trans. Wireless Commun., vol. 25, pp. 559–572, 2026
2026
-
[21]
SpaceMoE: Realizing Distributed Mixture-of-Experts Inference over Space Networks
Z. Wang, H. Yang, M. Sheng, K. B. Letaief, and K. Huang, “SpaceMoE: Realizing distributed mixture-of-experts inference over space networks,” arXiv:2605.00515, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Communication-efficient collaborative LLM inference via distributed speculative decoding,
C. Zheng and T. Yang, “Communication-efficient collaborative LLM inference via distributed speculative decoding,” inProc. IEEE Int. Conf. Wireless Commun. Signal Process. (WCSP), Chongqing, China, 2025, pp. 1–6
2025
-
[23]
Uncertainty-aware hybrid inference with on-device small and remote large language models,
S. Oh, J. Kim, J. Park, S.-W. Ko, T. Q. Quek, and S.-L. Kim, “Uncertainty-aware hybrid inference with on-device small and remote large language models,” inProc. IEEE Int. Conf. Mach. Learn. Commun. Netw. (ICMLCN), Barcelona, Spain, 2025, pp. 1–7
2025
-
[24]
Quantize- sample-and-verify: LLM acceleration via adaptive edge-cloud specula- tive decoding,
G. Zhang, Y . Cai, G. Yu, P. Popovski, and O. Simeone, “Quantize- sample-and-verify: LLM acceleration via adaptive edge-cloud specula- tive decoding,”IEEE Commun. Lett., vol. 30, pp. 852–856, 2026
2026
-
[25]
Fast collaborative inference via distributed speculative decoding,
C. Zheng, K. Zhang, S. Chen, W. Zhang, Q. Liu, and A. A. Tesfay, “Fast collaborative inference via distributed speculative decoding,”J. Inf. Intell., vol. 4, no. 1, pp. 67–85, 2026
2026
-
[26]
Task- oriented sensing, computation, and communication integration for multi- device edge AI,
D. Wen, P. Liu, G. Zhu, Y . Shi, J. Xu, Y . C. Eldar, and S. Cui, “Task- oriented sensing, computation, and communication integration for multi- device edge AI,”IEEE Trans. Wireless Commun., vol. 23, no. 3, pp. 2486–2502, 2024
2024
-
[27]
SPIN: Accelerating large language model inference with heterogeneous speculative models,
F. Chen, P. Li, T. H. Luan, Z. Su, and J. Deng, “SPIN: Accelerating large language model inference with heterogeneous speculative models,” inProc. IEEE Conf. Comput. Commun. (INFOCOM), London, U.K., 2025, pp. 1–10
2025
-
[28]
Rethinking resource management in edge learning: A joint pre-training and fine- tuning design paradigm,
Z. Lyu, Y . Li, G. Zhu, J. Xu, H. V . Poor, and S. Cui, “Rethinking resource management in edge learning: A joint pre-training and fine- tuning design paradigm,”IEEE Trans. on Wireless Commun., vol. 24, no. 2, pp. 1584–1601, 2024
2024
-
[29]
Efficiently scaling transformer inference,
R. Pope, S. Douglas, A. Chowdhery, J. Devlin, J. Bradbury, J. Heek, K. Xiao, S. Agrawal, and J. Dean, “Efficiently scaling transformer inference,” inProc. Mach. Learn. Syst. (MLSys), Miami Beach, FL, USA, 2023, pp. 606–624
2023
-
[30]
NVIDIA Corporation,NVIDIA A100 Tensor Core GPU: Data Sheet, NVIDIA Corporation, 2020, accessed: Jun. 7, 2026. [Online]. Avail- able: https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/ a100/pdf/nvidia-a100-datasheet-nvidia-us-2188504-web.pdf
2020
-
[31]
BASS: Batched attention-optimized speculative sampling,
H. Qian, S. K. Gonugondla, S. Ha, M. Shang, S. K. Gouda, R. Nallapati, S. Sengupta, X. Ma, and A. Deoras, “BASS: Batched attention-optimized speculative sampling,” inProc. Findings Assoc. Comput. Linguistics (ACL), Bangkok, Thailand, 2024, pp. 8214–8224
2024
-
[32]
Q. Su, C. Giannoula, and G. Pekhimenko, “The synergy of spec- ulative decoding and batching in serving large language models,” arXiv:2310.18813, 2023
-
[33]
Resource management for low-latency cooperative fine-tuning of foundation models at the network edge,
H. Wu, X. Chen, and K. Huang, “Resource management for low-latency cooperative fine-tuning of foundation models at the network edge,”IEEE Trans. Wireless Commun., vol. 24, no. 6, pp. 4839–4852, 2025
2025
-
[34]
Energy-efficient resource allocation for mobile-edge computation offloading,
C. You, K. Huang, H. Chae, and B.-H. Kim, “Energy-efficient resource allocation for mobile-edge computation offloading,”IEEE Trans. Wire- less Commun., vol. 16, no. 3, pp. 1397–1411, 2017
2017
-
[35]
PEARL: Parallel speculative decoding with adaptive draft length,
T. Liu, Y . Li, Q. Lv, K. Liu, J. Zhu, W. Hu, and X. Sun, “PEARL: Parallel speculative decoding with adaptive draft length,” inProc. Int. Conf. Learn. Represent. (ICLR), Singapore, 2025
2025
-
[36]
Optimal batch-size control for low-latency federated learning with device heterogeneity,
H. Yang, Z. Wang, and K. Huang, “Optimal batch-size control for low-latency federated learning with device heterogeneity,”IEEE Trans. Commun., vol. 74, pp. 5232–5247, 2026
2026
-
[37]
Boyd and L
S. Boyd and L. Vandenberghe,Convex Optimization. Cambridge, U.K.: Cambridge Univ. Press, 2004
2004
-
[38]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Qwen3.5: Towards native multimodal agents,
Qwen Team, “Qwen3.5: Towards native multimodal agents,” Online, Feb. 2026. [Online]. Available: https://qwen.ai/blog?id=qwen3.5
2026
-
[40]
Program Synthesis with Large Language Models
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Leet al., “Program synthesis with large language models,”arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[41]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakanoet al., “Training verifiers to solve math word problems,”arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[42]
Judging LLM-as-a-judge with MT-Bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xinget al., “Judging LLM-as-a-judge with MT-Bench and chatbot arena,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), New Orleans, LA, USA, 2023, pp. 46 595–46 623
2023
-
[43]
SQuAD: 100,000+ questions for machine comprehension of text,
P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang, “SQuAD: 100,000+ questions for machine comprehension of text,” inProc. Conf. Empirical Methods Natural Lang. Process. (EMNLP), Austin, TX, USA, 2016, pp. 2383–2392
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.