Towards Pretraining Text Encoders for TabPFN
Pith reviewed 2026-06-28 07:35 UTC · model grok-4.3
The pith
A lightweight adapter projects text embeddings into TabPFN's embedding space as tokens, eliminating the PCA compression step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
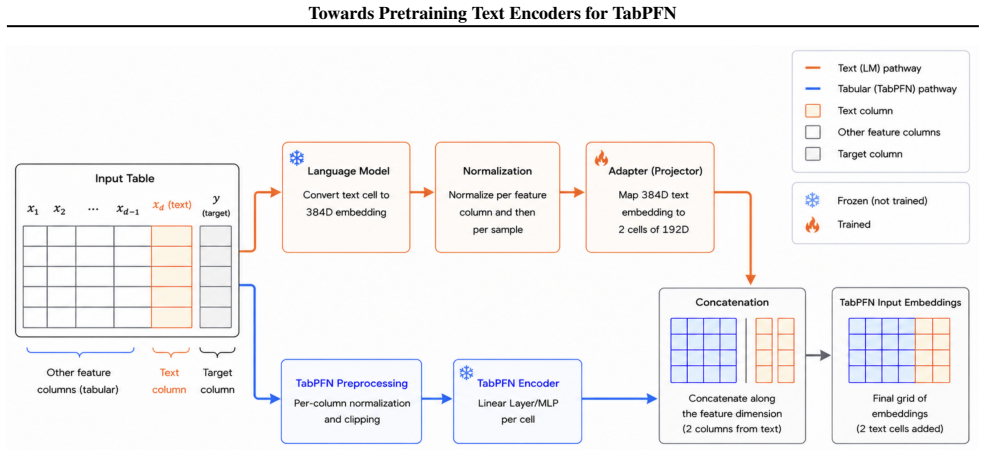
The central claim is that freezing the sentence encoder and TabPFN while training only a lightweight adapter successfully maps text embeddings into a short sequence of tokens in TabPFN's embedding space. This removes the information bottleneck created by PCA compression of high-dimensional text vectors and avoids the data hunger of end-to-end pretraining pipelines that combine text and tabular data.
What carries the argument
The TabPFN Text Adapter, a lightweight projection module that converts frozen sentence-encoder embeddings into tokens inside TabPFN's embedding space.
If this is right
- TabPFN gains the ability to process rich text features while retaining its pre-trained numerical strengths.
- The adapter approach requires substantially less pretraining data than end-to-end text-tabular models.
- Training cost drops because only the adapter parameters are updated instead of the full pipeline.
- No PCA compression step is needed, so all embedding dimensions remain available to the model.
Where Pith is reading between the lines
- The same freezing-plus-adapter pattern could be tested on other tabular foundation models to see whether the alignment cost stays low.
- If the adapter generalizes across sentence encoders, practitioners could swap language models without retraining the tabular side.
- Downstream tasks that combine tables with long documents might become feasible by feeding multiple adapter outputs into one TabPFN forward pass.
Load-bearing premise
A lightweight adapter trained while freezing the sentence encoder and TabPFN can align text embeddings into TabPFN's embedding space without significant performance loss.
What would settle it
On tabular datasets containing high-cardinality text columns, run the adapter-augmented TabPFN against the standard PCA-compressed pipeline and an end-to-end text-tabular baseline; if accuracy does not exceed the PCA version or if training cost remains comparable to full retraining, the claimed removal of the bottleneck fails.
Figures
read the original abstract
Tabular foundation models, such as TabPFN, achieve strong performance on tabular datasets with numerical and categorical data, but do not natively handle high-cardinality text features. Standard pipelines, therefore, embed text with a language model and compress the resulting vectors with PCA into a small number of scalar features before inputting them into TabPFN. This creates an information bottleneck: most embedding dimensions are discarded, and the compressed representation must then be expanded again by TabPFN's feature encoder. End-to-end alternatives can avoid PCA, but they require large amounts of pretraining data containing text cells and usually perform subpar compared to tabular foundation models that were pretrained on large amounts of synthetic data. Inspired by modality-alignment approaches like LLaVA (vision-to-LLM token projection) and TableGPT-style systems (table-to-LLM token projection), we introduce the TabPFN Text Adapter (text-to-TFM token projection). We freeze both the sentence encoder and TabPFN, and train only a lightweight adapter that maps text embeddings into a short sequence of tokens in TabPFN's embedding space. This design removes the PCA bottleneck, preserves TabPFN's numerical strengths, and is more efficient to train than end-to-end text-tabular pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the TabPFN Text Adapter: a lightweight module that maps embeddings from a frozen sentence encoder into a short sequence of tokens in the embedding space of a frozen TabPFN model. The design is intended to handle high-cardinality text features in tabular data without PCA compression, while preserving TabPFN's strengths on numerical/categorical data and requiring less pretraining data than end-to-end text-tabular pipelines.
Significance. If the adapter can be shown to align modalities effectively, the approach would offer a parameter-efficient way to extend tabular foundation models to text features, avoiding both the information loss of PCA and the data/compute costs of full end-to-end pretraining.
major comments (1)
- [Abstract] Abstract: the claim that the design 'preserves TabPFN's numerical strengths' rests on the untested assumption that a lightweight adapter can project text embeddings into TabPFN's token space without degrading the frozen TabPFN's behavior on numerical and categorical features. No architecture details, training objective, data, or results are provided to support this load-bearing assumption.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the design 'preserves TabPFN's numerical strengths' rests on the untested assumption that a lightweight adapter can project text embeddings into TabPFN's token space without degrading the frozen TabPFN's behavior on numerical and categorical features. No architecture details, training objective, data, or results are provided to support this load-bearing assumption.
Authors: We agree that the abstract, being a concise summary, does not itself contain the supporting details. The manuscript provides the adapter architecture (Section 3), training objective (Section 4), pretraining data (Section 5), and experimental results (Section 6) showing that TabPFN performance on numerical/categorical features is not degraded when the frozen model receives the additional projected text tokens. To address the concern, we will revise the abstract to indicate that preservation of numerical strengths is supported by the experiments rather than asserted without qualification. revision: yes
Circularity Check
No circularity: architectural proposal with no derivations or self-referential fits
full rationale
The paper proposes the TabPFN Text Adapter as a design choice: freeze the sentence encoder and TabPFN, train only a lightweight adapter to map text embeddings into TabPFN's token space. No equations, parameters, or predictions are defined anywhere in the provided text. No self-citations appear as load-bearing justifications for uniqueness, ansatzes, or theorems. The central claims (removal of PCA bottleneck, preservation of numerical strengths, training efficiency) are direct consequences of the freezing strategy as stated, without any reduction of outputs to inputs by construction. This matches the default case of a self-contained architectural proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Text embeddings from a sentence encoder can be meaningfully projected into the embedding space of TabPFN via a lightweight adapter.
invented entities (1)
-
TabPFN Text Adapter
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models , author=. 2026 , eprint=
2026
-
[2]
2020 , eprint=
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers , author=. 2020 , eprint=
2020
-
[3]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, Nils and Gurevych, Iryna. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. 2019
2019
-
[4]
1st ICML Workshop on Foundation Models for Structured Data , year=
Real-TabPFN: Improving Tabular Foundation Models via Continued Pre-training With Real-World Data , author=. 1st ICML Workshop on Foundation Models for Structured Data , year=
-
[5]
Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation
Reimers, Nils and Gurevych, Iryna. Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. 2020
2020
-
[6]
2025 , eprint=
ConTextTab: A Semantics-Aware Tabular In-Context Learner , author=. 2025 , eprint=
2025
-
[7]
2025 , eprint=
TabSTAR: A Tabular Foundation Model for Tabular Data with Text Fields , author=. 2025 , eprint=
2025
-
[8]
Hollmann and S
N. Hollmann and S. M. Tab
-
[9]
Nature , volume=
Accurate predictions on small data with a tabular foundation model , author=. Nature , volume=. 2025 , publisher=
2025
-
[10]
, title =
Karl Pearson F.R.S. , title =. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science , volume =. 1901 , publisher =
1901
-
[11]
2023 , eprint=
Visual Instruction Tuning , author=. 2023 , eprint=
2023
-
[12]
2024 , eprint=
Large Scale Transfer Learning for Tabular Data via Language Modeling , author=. 2024 , eprint=
2024
-
[13]
2025 , eprint=
TabGemma: Text-Based Tabular ICL via LLM using Continued Pretraining and Retrieval , author=. 2025 , eprint=
2025
-
[14]
2024 , eprint=
CARTE: Pretraining and Transfer for Tabular Learning , author=. 2024 , eprint=
2024
-
[15]
2025 , eprint=
Table Foundation Models: on knowledge pre-training for tabular learning , author=. 2025 , eprint=
2025
-
[16]
2017 , eprint=
Enriching Word Vectors with Subword Information , author=. 2017 , eprint=
2017
-
[17]
2025 , eprint=
Towards Benchmarking Foundation Models for Tabular Data With Text , author=. 2025 , eprint=
2025
-
[18]
2023 , eprint=
TableGPT: Towards Unifying Tables, Natural Language and Commands into One GPT , author=. 2023 , eprint=
2023
-
[19]
2025 , eprint=
TabArena: A Living Benchmark for Machine Learning on Tabular Data , author=. 2025 , eprint=
2025
-
[20]
skrub: Prepping tables for machine learning , year =
-
[21]
2026 , eprint=
STRABLE: Benchmarking Tabular Machine Learning with Strings , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.