TaDA: Calibrated Probe Gating for Task-Domain LoRA Merging
Pith reviewed 2026-06-28 05:46 UTC · model grok-4.3
The pith
Calibrated per-layer gating that accounts for depth-dependent task-domain asymmetry outperforms uniform LoRA merging on QA and classification benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
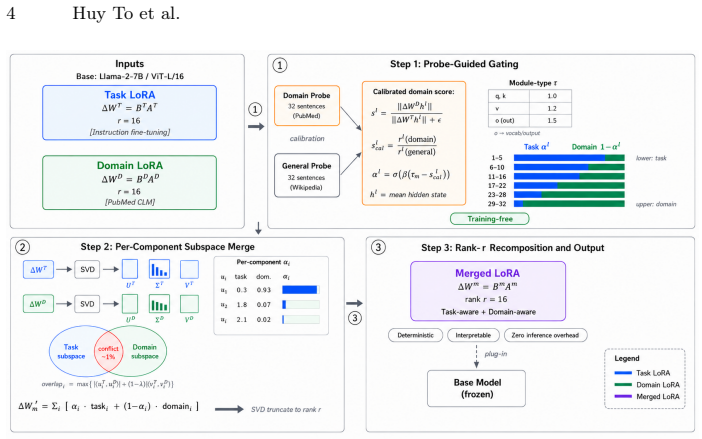
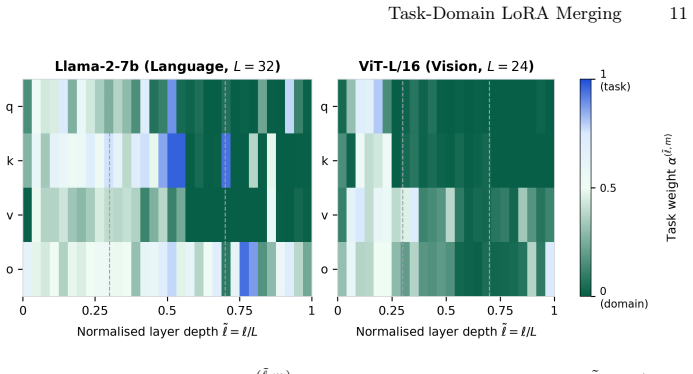
By identifying that domain dominance increases with layer depth while shallower layers retain stronger task-relevant signals, TaDA applies calibrated probe-guided per-layer gating using a magnitude-invariant probe signal and discards conflicting singular directions in subspace-aware merging to create an effective unified rank-r LoRA adapter.
What carries the argument
Calibrated probe-guided per-layer gating combined with per-component subspace-aware merging that exploits the observed depth-dependent task-domain asymmetry.
If this is right
- Merged adapters reach higher accuracy than uniform-weight baselines on scientific QA tasks with Llama-2-7B.
- The same merging procedure improves results on image classification with ViT-L/16 while leading on three of six benchmarks.
- The output remains a standard rank-r LoRA adapter requiring no extra computation at inference time.
- Gains hold when merging task and domain adapters trained on separate objectives without joint retraining.
Where Pith is reading between the lines
- The depth pattern could inform weight assignment when merging three or more distinct adapters.
- Probe-based gating might transfer to merging strategies for other parameter-efficient tuning methods.
- The invariance of the probe signal to adapter magnitude suggests it could stabilize merging under different training regimes.
Load-bearing premise
Task and domain adapters exhibit a consistent depth-dependent asymmetry across transformer architectures.
What would settle it
Repeating the per-layer signal strength measurements on additional transformer models and finding either uniform task-domain contributions across depths or reversed patterns would falsify the asymmetry premise.
Figures
read the original abstract
Combining a task LoRA adapter with a domain LoRA adapter into a single unified model is a practical yet largely unexplored challenge. Existing methods treat both adapters as symmetric peers, applying uniform weights across all layers. We argue that task and domain adapters exhibit a consistent depth-dependent asymmetry across transformer architectures. Domain dominance increases with layer depth, while shallower layers retain stronger task-relevant signals. Motivated by this observation, we propose $\textbf{TaDA}$ ($\textbf{Ta}$sk-$\textbf{D}$omain LoR$\textbf{A}$ Merging), a training-free algorithm that exploits this structure through calibrated probe-guided per-layer gating and per-component subspace-aware merging. The gating assigns individual weights per layer and projection type using a probe signal proved invariant to adapter weight magnitude. The merging discards conflicting singular directions before combining the remaining components. $\textbf{TaDA}$ produces a standard rank-$r$ LoRA adapter with zero inference overhead. On six scientific QA benchmarks with Llama-2-7B, TaDA achieves an average accuracy of 0.452, outperforming DARE-TIES by +3.6 percentage points and obtaining the best result on all six benchmarks. On six image classification benchmarks with ViT-L/16, TaDA reaches 85.9\% average accuracy, improving over the strongest merging baseline while leading in three of the six individual benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TaDA, a training-free algorithm for merging task and domain LoRA adapters. It is motivated by an observed depth-dependent asymmetry in which domain adapters dominate deeper layers while task signals are stronger in shallower layers. The method uses a calibrated probe for per-layer and per-projection gating (claimed invariant to adapter magnitude) and subspace-aware merging to discard conflicting directions. It reports an average accuracy of 0.452 on six scientific QA benchmarks using Llama-2-7B (outperforming DARE-TIES by 3.6 pp and best on all), and 85.9% on six image classification tasks with ViT-L/16.
Significance. If the asymmetry holds and the gating exploits it causally rather than as generic weighting, this could offer an effective, zero-overhead way to combine specialized adapters, which is practically valuable for efficient model customization. The consistent outperformance on all benchmarks in one setting is a notable result if the experimental protocol is fully specified and reproducible.
major comments (2)
- [Abstract] Abstract: The depth-dependent asymmetry ('domain dominance increases with layer depth, while shallower layers retain stronger task-relevant signals') is asserted as motivation and the basis for the per-layer gating, but the text supplies no quantitative measurements (e.g., per-layer cosine similarities or activation norms) or ablations removing the depth-dependent component; without this, it is unclear whether the reported +3.6 pp margin over DARE-TIES is driven by the claimed structure rather than other implementation choices.
- [Abstract] Abstract: The gating mechanism relies on a 'probe signal proved invariant to adapter weight magnitude,' yet no derivation, equation, or proof sketch is provided to establish this invariance, which is central to the calibrated per-layer weighting claim.
minor comments (1)
- The abstract reports results on ViT-L/16 but does not clarify whether the depth-dependent asymmetry was verified for vision transformers or if the method required adaptation.
Simulated Author's Rebuttal
We thank the referee for these comments. Both points identify genuine gaps in the current manuscript: the absence of quantitative support for the claimed depth-dependent asymmetry and the lack of a derivation for the probe-signal invariance. We will address both by adding the requested material in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The depth-dependent asymmetry ('domain dominance increases with layer depth, while shallower layers retain stronger task-relevant signals') is asserted as motivation and the basis for the per-layer gating, but the text supplies no quantitative measurements (e.g., per-layer cosine similarities or activation norms) or ablations removing the depth-dependent component; without this, it is unclear whether the reported +3.6 pp margin over DARE-TIES is driven by the claimed structure rather than other implementation choices.
Authors: We agree that the manuscript currently asserts the asymmetry without presenting supporting measurements or an ablation that isolates its contribution. In the revised version we will add a new subsection containing (i) per-layer cosine-similarity and activation-norm statistics between task and domain adapters on the Llama-2-7B and ViT backbones, and (ii) an ablation that replaces the depth-dependent gating with uniform layer weights while keeping all other components fixed. These additions will allow readers to assess whether the reported gains are attributable to the depth-dependent structure. revision: yes
-
Referee: [Abstract] Abstract: The gating mechanism relies on a 'probe signal proved invariant to adapter weight magnitude,' yet no derivation, equation, or proof sketch is provided to establish this invariance, which is central to the calibrated per-layer weighting claim.
Authors: We accept that the manuscript states the invariance without supplying the supporting derivation. In the revision we will insert a dedicated paragraph (with equations) in the Methods section that derives the probe signal, shows the normalization step that removes magnitude dependence, and includes a short proof sketch establishing invariance under scaling of the adapter weights. revision: yes
Circularity Check
No circularity; empirical results on external benchmarks with independent motivation
full rationale
The paper reports measured accuracies on six scientific QA benchmarks and six image classification benchmarks, outperforming baselines like DARE-TIES. The method is motivated by an observed depth-dependent asymmetry in task/domain adapters, implemented via probe-guided gating claimed to be invariant to weight magnitude. No equations, fitted parameters, or self-citations are exhibited that reduce the reported gains to quantities defined from the same data by construction. The derivation chain is self-contained against the external benchmarks and does not rely on renaming, self-definition, or load-bearing self-citations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Task and domain adapters exhibit consistent depth-dependent asymmetry across transformer architectures
- domain assumption Probe signal is invariant to adapter weight magnitude
Reference graph
Works this paper leans on
-
[1]
Chen, Q., Hong, Y.: Medblip: Bootstrapping language-image pretraining from 3d medical images and texts. In: Computer Vision – ACCV 2024: 17th Asian Conference on Computer Vision, Hanoi, Vietnam, December 8–12, 2024, Pro- ceedings, Part III. p. 98–113. Springer-Verlag, Berlin, Heidelberg (2024).https: //doi.org/10.1007/978- 981- 96- 0908- 6_6,https://doi.o...
-
[2]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2014) 7 Task-Domain LoRA Merging 15
Cimpoi, M., Maji, S., Kokkinos, I., Mohamed, S., Vedaldi, A.: Describing textures in the wild. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2014) 7 Task-Domain LoRA Merging 15
2014
-
[3]
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., Tafjord, O.: Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457v1 (2018) 6
Pith/arXiv arXiv 2018
-
[4]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition. pp. 248–255 (2009).https://doi.org/10.1109/CVPR.2009. 52068486, 7
-
[5]
In: In- ternational Conference on Learning Representations (2021),https://openreview
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: In- ternational Conference on Learning Representations (2021),https://openreview. net/forum?id=YicbFdNTTy3, 6
2021
-
[6]
In: Proceedings of the Asian Con- ference on Computer Vision
He, H., Liu, W., Xing, W.: Biefficient: Bidirectionally prompting vision-language models for parameter-efficient video recognition. In: Proceedings of the Asian Con- ference on Computer Vision. pp. 108–125 (2024) 3
2024
-
[7]
Helber, P., Bischke, B., Dengel, A., Borth, D.: Introducing eurosat: A novel dataset anddeeplearningbenchmarkforlanduseandlandcoverclassification.In:IGARSS 2018 - 2018 IEEE International Geoscience and Remote Sensing Symposium. pp. 204–207 (2018).https://doi.org/10.1109/IGARSS.2018.85192487
-
[8]
Proceedings of the International Conference on Learning Representations (ICLR) (2021) 6
Hendrycks, D., Burns, C., Basart, S., Critch, A., Li, J., Song, D., Steinhardt, J.: Aligning ai with shared human values. Proceedings of the International Conference on Learning Representations (ICLR) (2021) 6
2021
-
[9]
Proceedings of the In- ternational Conference on Learning Representations (ICLR) (2021) 6
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. Proceedings of the In- ternational Conference on Learning Representations (ICLR) (2021) 6
2021
-
[10]
In: International Con- ference on Learning Representations (2022),https://openreview.net/forum?id= nZeVKeeFYf91, 3
Hu, E.J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: International Con- ference on Learning Representations (2022),https://openreview.net/forum?id= nZeVKeeFYf91, 3
2022
-
[11]
In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=6t0Kwf8- jrj3, 7, 9, 10
Ilharco, G., Ribeiro, M.T., Wortsman, M., Schmidt, L., Hajishirzi, H., Farhadi, A.: Editing models with task arithmetic. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=6t0Kwf8- jrj3, 7, 9, 10
2023
-
[12]
Applied Sciences11(14) (2021).https://doi.org/10.3390/ app11146421,https://www.mdpi.com/2076-3417/11/14/64216
Jin, D., Pan, E., Oufattole, N., Weng, W.H., Fang, H., Szolovits, P.: What dis- ease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences11(14) (2021).https://doi.org/10.3390/ app11146421,https://www.mdpi.com/2076-3417/11/14/64216
2021
-
[13]
URLhttps://doi.org/10.18653/v1/D19-1259
Jin,Q.,Dhingra,B.,Liu,Z.,Cohen,W.,Lu,X.:PubMedQA:Adatasetforbiomed- ical research question answering. In: Inui, K., Jiang, J., Ng, V., Wan, X. (eds.) Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Pro- cessing(EMNLP-IJCNLP).pp.2567–2577.AssociationforCom...
-
[14]
Krizhevsky, A., Hinton, G.: Learning multiple layers of features from tiny images. Tech. Rep. 0, University of Toronto, Toronto, Ontario (2009),https://www.cs. toronto.edu/~kriz/learning-features-2009-TR.pdf7
2009
-
[15]
In: Flores, G., Chen, G.H., Pollard, T., Ho, J.C., Naumann, T
Pal, A., Umapathi, L.K., Sankarasubbu, M.: Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In: Flores, G., Chen, G.H., Pollard, T., Ho, J.C., Naumann, T. (eds.) Proceedings of the Conference 16 Huy To et al. on Health, Inference, and Learning. Proceedings of Machine Learning Research, vol. 174, pp. 248–260....
2022
-
[16]
In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id=67X93aZHII3
Stoica, G., Ramesh, P., Ecsedi, B., Choshen, L., Hoffman, J.: Model merging with SVD to tie the knots. In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id=67X93aZHII3
2025
-
[17]
Taori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., Hashimoto, T.B.: Stanford alpaca: An instruction-following llama model.https: //github.com/tatsu-lab/stanford_alpaca(2023) 6
2023
-
[18]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A
Tenney, I., Das, D., Pavlick, E.: BERT rediscovers the classical NLP pipeline. In: Korhonen, A., Traum, D., Màrquez, L. (eds.) Proceedings of the 57th An- nual Meeting of the Association for Computational Linguistics. pp. 4593–4601. Association for Computational Linguistics, Florence, Italy (Jul 2019).https: //doi.org/10.18653/v1/P19-1452,https://aclantho...
-
[19]
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., Lample, G.: Llama: Open and efficient foundation language models (2023), https://arxiv.org/abs/2302.139716
Pith/arXiv arXiv 2023
-
[20]
In: Derczynski, L., Xu, W., Ritter, A., Baldwin, T
Welbl, J., Liu, N.F., Gardner, M.: Crowdsourcing multiple choice science ques- tions. In: Derczynski, L., Xu, W., Ritter, A., Baldwin, T. (eds.) Proceedings of the 3rd Workshop on Noisy User-generated Text. pp. 94–106. Association for Com- putational Linguistics, Copenhagen, Denmark (Sep 2017).https://doi.org/10. 18653/v1/W17-4413,https://aclanthology.org...
2017
-
[21]
Wortsman, M., Ilharco, G., Gadre, S.Y., Roelofs, R., Gontijo-Lopes, R., Morcos, A.S., Namkoong, H., Farhadi, A., Carmon, Y., Kornblith, S., Schmidt, L.: Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time (2022),https://arxiv.org/abs/2203.054821, 3, 7, 9, 10
arXiv 2022
-
[22]
In: Thirty-seventh Conference on Neu- ral Information Processing Systems (2023),https://openreview.net/forum?id= xtaX3WyCj11, 3, 7, 9, 10
Yadav, P., Tam, D., Choshen, L., Raffel, C., Bansal, M.: TIES-merging: Resolv- ing interference when merging models. In: Thirty-seventh Conference on Neu- ral Information Processing Systems (2023),https://openreview.net/forum?id= xtaX3WyCj11, 3, 7, 9, 10
2023
-
[23]
Scientific Data10(1), 41 (2023) 6, 7
Yang,J.,Shi,R.,Wei,D.,Liu,Z.,Zhao,L.,Ke,B.,Pfister,H.,Ni,B.:Medmnistv2- a large-scale lightweight benchmark for 2d and 3d biomedical image classification. Scientific Data10(1), 41 (2023) 6, 7
2023
-
[24]
In: International Conference on Learning Representations (2023),https://openreview.net/forum?id=CIoSZ_HKHS73
Yang, T., Zhu, Y., Xie, Y., Zhang, A., Chen, C., Li, M.: Aim: Adapting image models for efficient video understanding. In: International Conference on Learning Representations (2023),https://openreview.net/forum?id=CIoSZ_HKHS73
2023
-
[25]
In: Proceedings of the 41st International Conference on Machine Learning
Yu, L., Yu, B., Yu, H., Huang, F., Li, Y.: Language models are super mario: absorbing abilities from homologous models as a free lunch. In: Proceedings of the 41st International Conference on Machine Learning. ICML’24, JMLR.org (2024) 1, 3, 7, 9, 10
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.