Zero knowledge verification for frontier AI training is possible
Pith reviewed 2026-06-28 06:04 UTC · model grok-4.3
The pith
Zero-knowledge verification of frontier AI training runs is feasible with a zkVM architecture at single-digit overhead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
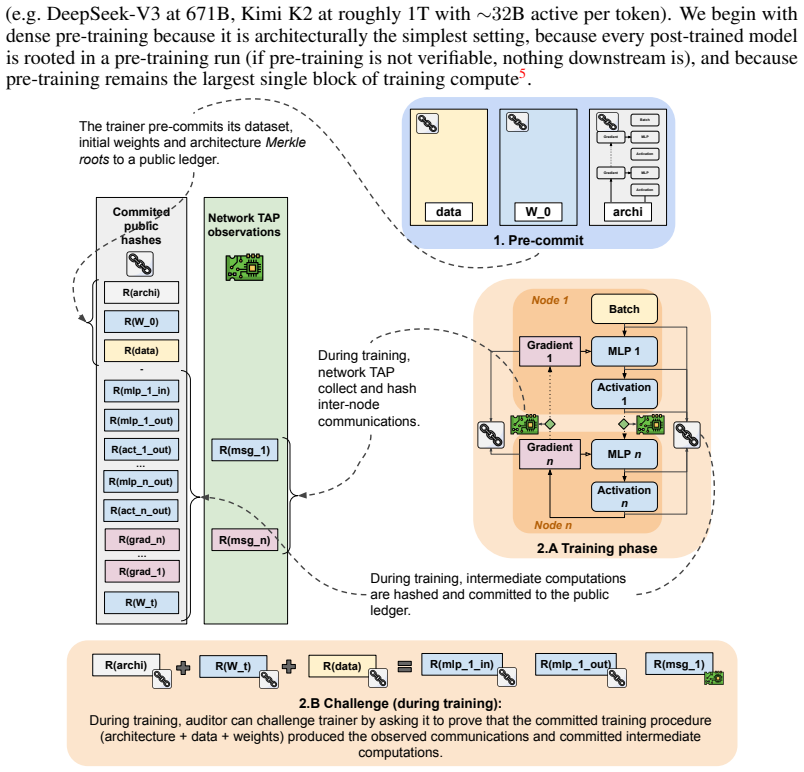
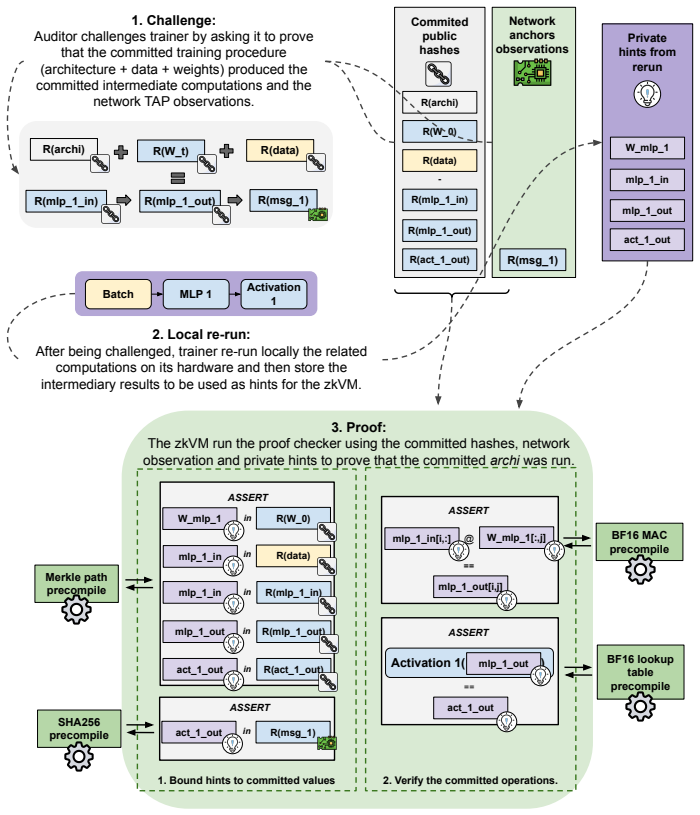
A verification architecture for frontier dense pre-training that combines a pre-committed training specification, inter-node network observations, and on-the-fly Merkle commitments of intermediate computation, verified through a zero-knowledge Virtual Machine with native BF16/FP32 precompiles. The proof checks the actual floating-point computation the GPU performed rather than a fixed-point approximation and preserves model-architecture confidentiality through a private training specification. The protocol produces a genesis proof at initialisation, in-training step proofs across the run, and ex-ante attestations enforcing policy-relevant claims as running invariants, turning the training re
What carries the argument
The zero-knowledge Virtual Machine (zkVM) with native BF16/FP32 precompiles that verifies actual floating-point GPU computations from Merkle commitments and network observations.
If this is right
- Training runs become auditable artefacts that can enforce cumulative compute thresholds without self-reporting.
- Model architecture remains confidential while still allowing verification of the computation performed.
- International regulatory agreements on frontier AI can incorporate technical verification primitives instead of remaining declaratory.
- A proof-of-concept system could be deployed in approximately 36 months rather than the six-to-ten-year timeline required for verification-grade custom silicon.
- The training record can carry running invariants that serve as ex-ante policy attestations.
Where Pith is reading between the lines
- If the architecture works, it could reduce the information asymmetry between AI developers and regulators on actual training effort.
- The same combination of network observation and Merkle commitments might extend to verifying other large-scale distributed computations beyond AI training.
- Cataloguing thirteen open research problems creates an explicit invitation for external groups to close the remaining gaps.
- Success would make cumulative training compute a more reliable basis for tiered governance rules.
Load-bearing premise
A zkVM supporting native BF16 and FP32 operations can be realized that verifies real GPU floating-point work at frontier scale while keeping total overhead in the single-digit percent range.
What would settle it
A working implementation showing that zkVM overhead for verifying BF16/FP32 matrix multiplies at frontier batch sizes exceeds single-digit percent or cannot attest inter-node network traffic and Merkle roots without revealing the model would falsify the claim.
Figures
read the original abstract
Frontier AI governance frameworks increasingly use cumulative training compute as the primary criterion for designating high-impact models, but enforcement rests on self-reporting because no technical verification primitive for training exists. Any future international agreement on frontier AI faces the same problem at higher stakes: coordinated regulation of technologies with significant externalities has historically rested on technical verification, without which agreements are declaratory. Recent governance analyses judge zero-knowledge proofs a promising candidate but currently impractical at frontier scale [26, 4]. We argue the impracticality is paradigm-bound rather than fundamental, and propose a verification architecture for frontier dense pre-training combining a pre-committed training specification, inter-node network observations, and on-the-fly Merkle commitments of intermediate computation, verified through a zero-knowledge Virtual Machine (zkVM) with native BF16/FP32 precompiles. The proof checks the actual floating-point computation the GPU performed rather than a fixed-point approximation, and preserves model-architecture confidentiality through a private training specification. The protocol produces three proof types: a genesis proof at initialisation, in-training step proofs across the run, and ex-ante attestations enforcing policy-relevant claims as running invariants, turning the training record into a governance-enforceable artefact. We estimate a deployable proof of concept within approximately 36 months at single-digit-percent training-side overhead, against a six-to-ten-year cycle for verification-grade custom silicon. Thirteen open research and engineering problems are catalogued as a research agenda for external contribution
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that zero-knowledge verification of frontier dense pre-training is feasible (rather than fundamentally impossible) via an architecture that combines a pre-committed training specification, inter-node network observations, on-the-fly Merkle commitments of intermediate states, and verification inside a zkVM equipped with native BF16/FP32 precompiles. The protocol emits three classes of proofs (genesis, in-training step proofs, and ex-ante policy invariants) that turn the training record into a governance-enforceable artefact while preserving model confidentiality; the authors estimate a deployable proof-of-concept within ~36 months at single-digit-percent training-side overhead and list thirteen open research problems.
Significance. If the proposed architecture can be realized at the claimed overhead, it would supply the first technical primitive capable of converting self-reported training compute into verifiable, policy-relevant artefacts, directly addressing the enforcement gap identified in current frontier-AI governance proposals. The explicit catalog of thirteen open problems is a constructive contribution that could usefully structure community follow-on work.
major comments (2)
- [Abstract] Abstract: the single-digit-percent training-side overhead estimate for verifying frontier-scale matmuls and layer norms inside a zkVM with native BF16/FP32 precompiles is asserted without any circuit-size bound, reduction to existing zkVM benchmarks, or even order-of-magnitude calculation of the dominant kernels; this figure is load-bearing for both the 36-month POC timeline and the claim that the approach is deployable rather than requiring custom silicon.
- [Abstract] Abstract / architecture description: the claim that inter-node network observations plus Merkle commitments suffice to attest the actual floating-point computation performed by GPUs (without custom silicon or loss of confidentiality) is presented at a high level; no concrete protocol sketch or security argument shows how these observations close the gap between the zkVM proof and the physical training run at the scale of current frontier clusters.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly contrasted the proposed zkVM-plus-Merkle approach with prior zkML or zk-training proposals referenced in [26,4] rather than only stating that prior work judged the problem impractical.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the recognition of the paper's potential significance for AI governance. We address the two major comments below. Both concern the level of detail in the abstract; we agree that additional supporting material strengthens the manuscript and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the single-digit-percent training-side overhead estimate for verifying frontier-scale matmuls and layer norms inside a zkVM with native BF16/FP32 precompiles is asserted without any circuit-size bound, reduction to existing zkVM benchmarks, or even order-of-magnitude calculation of the dominant kernels; this figure is load-bearing for both the 36-month POC timeline and the claim that the approach is deployable rather than requiring custom silicon.
Authors: The referee correctly notes that the single-digit overhead figure is presented as an estimate without an explicit circuit-size analysis or reduction to published zkVM benchmarks in the current text. The estimate is derived from scaling known zkVM costs for dense linear algebra under the assumption that native BF16/FP32 precompiles eliminate the dominant emulation overhead; however, we accept that this reasoning should be made explicit. We will add a short order-of-magnitude calculation section (drawing on existing RISC-V zkVM benchmarks for matrix kernels) to the revised manuscript and qualify the 36-month timeline as conditional on those precompiles being available. revision: yes
-
Referee: [Abstract] Abstract / architecture description: the claim that inter-node network observations plus Merkle commitments suffice to attest the actual floating-point computation performed by GPUs (without custom silicon or loss of confidentiality) is presented at a high level; no concrete protocol sketch or security argument shows how these observations close the gap between the zkVM proof and the physical training run at the scale of current frontier clusters.
Authors: The architecture is described at a conceptual level in the abstract and introduction. The full manuscript expands on the three proof classes and the role of committed specifications, but we agree that a concise protocol sketch showing how network observations and Merkle commitments bind the zkVM execution trace to the physical GPU run (while preserving confidentiality) would address the concern. We will insert a one-page protocol outline with a high-level security argument in the revised version. revision: yes
Circularity Check
No circularity: forward-looking proposal with explicit open problems
full rationale
The paper advances a high-level verification architecture combining pre-committed specs, network observations, Merkle commitments, and a zkVM with native floating-point precompiles. No equations, fitted parameters, or derivations appear in the provided text. The 36-month POC estimate and single-digit overhead are presented as engineering targets, not outputs of any internal fitting or self-referential reduction. Cited works [26,4] address prior impracticality judgments rather than supplying load-bearing uniqueness theorems or ansatzes from the same authors. Thirteen open research problems are explicitly catalogued, confirming the central claims remain non-self-contained proposals rather than closed loops.
Axiom & Free-Parameter Ledger
free parameters (1)
- single-digit-percent training-side overhead
axioms (2)
- domain assumption A zkVM with native BF16/FP32 precompiles can verify actual floating-point GPU computations at frontier scale with low overhead.
- domain assumption Inter-node network observations combined with on-the-fly Merkle commitments suffice to attest to the full training process.
Reference graph
Works this paper leans on
-
[1]
Ideals, macaulay bases, and pcps
Prashanth Amireddy, Amik Raj Behera, Srikanth Srinivasan, Madhu Sudan, and Sophus Valentin Willumsgaard. Ideals, macaulay bases, and pcps. InSTOC 2026, 2026
2026
-
[2]
Rothblum
Noga Amit, Shafi Goldwasser, Orr Paradise, and Guy N. Rothblum. Models that prove their own correctness. InICML 2024 Workshop on Theoretical Foundations of Foundation Models, 2024
2024
-
[3]
Proof verification and the hardness of approximation problems.J
Sanjeev Arora, Carsten Lund, Rajeev Motwani, Madhu Sudan, and Mario Szegedy. Proof verification and the hardness of approximation problems.J. ACM, 45(3):501–555, 1998
1998
-
[4]
Verifying international agreements on AI: Six layers of verification for rules on large-scale AI development and deployment
Mauricio Baker, Gabriel Kulp, Oliver Marks, Miles Brundage, and Lennart Heim. Verifying international agreements on AI: Six layers of verification for rules on large-scale AI development and deployment. 2025
2025
-
[5]
Scalable, transparent, and post-quantum secure computational integrity.Cryptology ePrint Archive, Report 2018/046, 2018
Eli Ben-Sasson, Iddo Bentov, Yinon Horesh, and Michael Riabzev. Scalable, transparent, and post-quantum secure computational integrity.Cryptology ePrint Archive, Report 2018/046, 2018
2018
-
[6]
Interactive oracle proofs
Eli Ben-Sasson, Alessandro Chiesa, and Nicholas Spooner. Interactive oracle proofs. InTheory of Cryptography Conference (TCC 2016-B), 2016
2016
-
[7]
Sum-check protocol for approximate computations.Cryptology ePrint Archive, Report 2025/2152, 2025
Dor Bitan, Zachary DeStefano, Shafi Goldwasser, Yuval Ishai, Yael Tauman Kalai, and Justin Thaler. Sum-check protocol for approximate computations.Cryptology ePrint Archive, Report 2025/2152, 2025
2025
-
[8]
ZKML: An optimizing system for ML inference in zero-knowledge proofs
Bing-Jyue Chen, Suppakit Waiwitlikhit, Ion Stoica, and Daniel Kang. ZKML: An optimizing system for ML inference in zero-knowledge proofs. InProceedings of the Nineteenth European Conference on Computer Systems (EuroSys), 2024
2024
-
[9]
The rising costs of training frontier AI models.arXiv preprint arXiv:2405.21015, 2024
Ben Cottier, Robi Rahman, Loredana Fattorini, Nestor Maslej, Tamay Besiroglu, and David Owen. The rising costs of training frontier AI models.arXiv preprint arXiv:2405.21015, 2024. Published by Epoch AI
arXiv 2024
-
[10]
Silent data corruptions at scale.arXiv preprint arXiv:2102.11245, 2021
Harish Dattatraya Dixit, Sneha Pendharkar, Matt Beadon, Chris Mason, Tejasvi Chakravarthy, Bharath Muthiah, and Sriram Sankar. Silent data corruptions at scale.arXiv preprint arXiv:2102.11245, 2021
arXiv 2021
-
[11]
The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[12]
Article 51: Classification of General-Purpose AI Models as General-Purpose AI Models with Systemic Risk
EU Council. Article 51: Classification of General-Purpose AI Models as General-Purpose AI Models with Systemic Risk. EU Artificial Intelligence Act Online Resource, https: //artificialintelligenceact.eu/article/51/, 2024. Regulation (EU) 2024/1689, Official Journal version of 13 June 2024. Accessed: 2026-04-22
2024
-
[13]
Experimenting with zero-knowledge proofs of training.arXiv preprint arXiv:2310.02421, 2023
Sanjam Garg, Aarushi Guo, Omer Reingold, and Ron Roth. Experimenting with zero-knowledge proofs of training.arXiv preprint arXiv:2310.02421, 2023. 10
arXiv 2023
-
[14]
Cambridge University Press, 2001
Oded Goldreich.Foundations of Cryptography: Basic Tools. Cambridge University Press, 2001
2001
-
[15]
Rothblum, Jonathan Shafer, and Amir Yehudayoff
Shafi Goldwasser, Guy N. Rothblum, Jonathan Shafer, and Amir Yehudayoff. Interactive Proofs for Verifying Machine Learning. In James R. Lee, editor,12th Innovations in Theoretical Computer Science Conference (ITCS 2021), volume 185 ofLeibniz International Proceedings in Informatics (LIPIcs), pages 41:1–41:19, Dagstuhl, Germany, 2021. Schloss Dagstuhl – Le...
2021
-
[16]
On the size of pairing-based non-interactive arguments
Jens Groth. On the size of pairing-based non-interactive arguments. InAdvances in Cryptology – EUROCRYPT 2016, 2016
2016
-
[17]
Hochschild, Paul Turner, Jeffrey C
Peter H. Hochschild, Paul Turner, Jeffrey C. Mogul, Rama Govindaraju, Parthasarathy Ran- ganathan, David E. Culler, and Amin Vahdat. Cores that don’t count. InProceedings of the Workshop on Hot Topics in Operating Systems (HotOS), 2021
2021
-
[18]
Scaling up trustless DNN inference with zero-knowledge proofs
Daniel Kang, Tatsunori Hashimoto, Ion Stoica, and Yi Sun. Scaling up trustless DNN inference with zero-knowledge proofs. InarXiv preprint arXiv:2210.08674, 2022
arXiv 2022
-
[19]
VeriLoRA: Fine-tuning large language models with verifiable security via zero-knowledge proofs
Guofu Liao, Taotao Wang, Shengli Zhang, Jiqun Zhang, Long Shi, and Dacheng Tao. VeriLoRA: Fine-tuning large language models with verifiable security via zero-knowledge proofs. In Network and Distributed System Security Symposium (NDSS), 2026
2026
-
[20]
An efficient transform from sigma protocols to nizk with a crs and non- programmable random oracle
Yehuda Lindell. An efficient transform from sigma protocols to nizk with a crs and non- programmable random oracle. InAdvances in Cryptology – EUROCRYPT 2015, 2015
2015
-
[21]
Llama 3 training economics and cost breakdown, 2024
Dylan Patel and SemiAnalysis. Llama 3 training economics and cost breakdown, 2024. Industry analysis; seehttps://www.semianalysis.com
2024
-
[22]
Guaranteeable memory: An HBM-based chiplet for verifiable AI workloads
James Petrie. Guaranteeable memory: An HBM-based chiplet for verifiable AI workloads. In Workshop on Technical AI Governance (TAIG) at ICML 2025, Vancouver, Canada, 2025
2025
-
[23]
James Petrie and Onni Aarne. Flexible hardware-enabled guarantees: Part II: Technical options for flexible hardware-enabled guarantees. Technical report, ARIA, 2025. arXiv:2506.03409
arXiv 2025
-
[24]
DASH: Deterministic attention scheduling for high-throughput reproducible LLM training
Xinwei Qiang, Hongmin Chen, Shixuan Sun, Jingwen Leng, Xin Liu, and Minyi Guo. DASH: Deterministic attention scheduling for high-throughput reproducible LLM training. InInterna- tional Conference on Learning Representations (ICLR), 2026
2026
-
[25]
An international agreement to prevent the premature creation of artificial superintelligence
Aaron Scher, David Abecassis, Peter Barnett, and Brian Abeyta. An international agreement to prevent the premature creation of artificial superintelligence. 2025
2025
-
[26]
What does it take to catch a Chinchilla? Verifying rules on large-scale neural network training via compute monitoring
Yonadav Shavit. What does it take to catch a Chinchilla? Verifying rules on large-scale neural network training via compute monitoring. 2023
2023
-
[27]
Tobin South, Alexander Camuto, Shrey Jain, Shayla Nguyen, Robert Mahari, Christian Paquin, Jason Morton, and Alex Pentland. Verifiable evaluations of machine learning models using zkSNARKs.arXiv preprint arXiv:2402.02675, 2024
arXiv 2024
-
[28]
zkLLM: Zero knowledge proofs for large language models
Haochen Sun, Jason Li, and Hongyang Zhang. zkLLM: Zero knowledge proofs for large language models. InProceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security (CCS), 2024
2024
-
[29]
Haochen Sun and Hongyang Zhang. zkdl: Efficient zero-knowledge proofs of deep learning training.arXiv preprint arXiv:2307.16273, 2024
arXiv 2024
-
[30]
US Exec. Ord. Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Executive Order No. 14110, 88 Fed. Reg. 75191, https://www.federalregister.gov/documents/2023/11/01/2023-24283/ safe-secure-and-trustworthy-development-and-use-of-artificial-intelligence ,
2023
-
[31]
Revoked by Executive Order No
Signed October 30, 2023; published November 1, 2023. Revoked by Executive Order No. 14148 (January 20, 2025). Accessed: 2026-04-22. 11 A Open problems This appendix catalogues the open research and engineering problems that remain after the ar- chitecture of Section 3. The list complements and expands the public roadmap maintained at gpaipolicylab.org/ver...
2023
-
[32]
The cleanest path, compatible with open-source verification, but requires ongoing mainte- nance as NCCL evolves
Patched NCCL with a documented canonical format.A forked NCCL exposes a version- locked on-wire layout and enumerates which logical tensor bytes map to which wire offsets. The cleanest path, compatible with open-source verification, but requires ongoing mainte- nance as NCCL evolves
-
[33]
Trades a small amount of additional memory traffic for independence from NCCL’s internals
Canonicalisation shim at the NCCL-to-transport boundary.A signed, auditable library interposed between NCCL and the NIC emits a canonicalised copy of each outgoing payload for the anchor to hash. Trades a small amount of additional memory traffic for independence from NCCL’s internals
-
[34]
verifiable NCCL
Vendor-supported “verifiable NCCL” mode.A first-class configuration flag with docu- mented wire semantics. The only path that does not require the verification ecosystem to maintain its own fork or shim; depends on vendor cooperation. 13 All three yield equivalent verification guarantees and differ in deployment effort, maintenance burden, and institution...
-
[35]
Network anchor.Catches any deviation that changes wire-bound content; deterministic (not statistical) detection on any sampled wire-bound tensor
-
[36]
Any error in any intermediate that propagates to the layer output changes the committed root; the proof catches this at the layer boundary
On-the-fly Merkle commitments.Each layer’s output is committed during training. Any error in any intermediate that propagates to the layer output changes the committed root; the proof catches this at the layer boundary
-
[37]
many cheap, few expensive
Interactive sampling.Adds 10−20 statistical assurance on intermediate GEMMs for deviations affecting≥1%of entries. Each layer is necessary: (1) alone cannot see intra-node computation; (2) alone does not rule out an adversary who produces internally consistent fake commitments; (3) alone has a detection floor at the deviation fraction. Together they provi...
-
[38]
A direct measurement is part of the planned empirical validation work
Proving throughput (∼106 constraints/s/GPU)is approximate and may be optimistic for constraint-heavy FP precompiles. A direct measurement is part of the planned empirical validation work. Relative comparisons between approaches are robust to this assumption
-
[39]
Absolute proof times scale linearly with this; the relative structure of the breakdown does not
Per-MAC constraint count (∼90)has a range of 50–150 depending on implementation. Absolute proof times scale linearly with this; the relative structure of the breakdown does not
-
[40]
Generation and validation of these tables is routine engineering work
Non-linear lookup tables(BF16 GELU, SiLU) must match the GPU kernel output at every input. Generation and validation of these tables is routine engineering work
-
[41]
Formal sensitivity analysis (OP-1) would close this
Sampling security at f <1% is a defense-in-depth argument, not a hard theorem. Formal sensitivity analysis (OP-1) would close this
-
[42]
GPU-concurrent Merkle hashing overhead (∼1–3%)needs empirical validation on H100 with realistic training workloads
-
[43]
A training stack that fuses FFN end-to-end (e.g
Fusion assumptions(Flash Attention truly fused, FFN GEMMs separable with lazy com- mitment) are kernel-dependent. A training stack that fuses FFN end-to-end (e.g. a memory- bound variant) materially increases per-sample FFN verification cost, and the sample count for fused blocks must be reduced correspondingly
-
[44]
The order-of-magnitude framing (K× per-expert-dense) holds across reasonable choices; concrete per-architecture figures require OP-10 resolution
MoE cost numbersdepend on sampling-scheme design decisions open under OP-10. The order-of-magnitude framing (K× per-expert-dense) holds across reasonable choices; concrete per-architecture figures require OP-10 resolution
-
[45]
FlashAttention-3-deterministic
INT8 training with INT32 accumulation(supported by H100/B200 Tensor Cores) would eliminate float non-associativity and make Freivalds directly applicable. No frontier model currently uses full INT8 pretraining, but the industry trend toward FP8 and FP4 is adjacent; verification cost at low-precision regimes is a worthwhile future study. C Determinism enfo...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.