V2V-Bench: A Comprehensive Benchmark for Video-to-Video Generation Evaluation
Pith reviewed 2026-06-28 02:17 UTC · model grok-4.3
The pith
V2V-Bench evaluates video-to-video models with 0.905 Spearman correlation to human judgments on six dimensions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
V2V-Bench is an 11-dimension benchmark organized into five categories that evaluates video-to-video outputs on how well they follow editing instructions and preserve frame-level correspondence with source videos; when applied to Grok Imagine, Gemini Veo3, and Open Sora 2 it identifies complementary strengths across models and attains 0.905 Spearman correlation with human judgments on the six V2V-specific dimensions.
What carries the argument
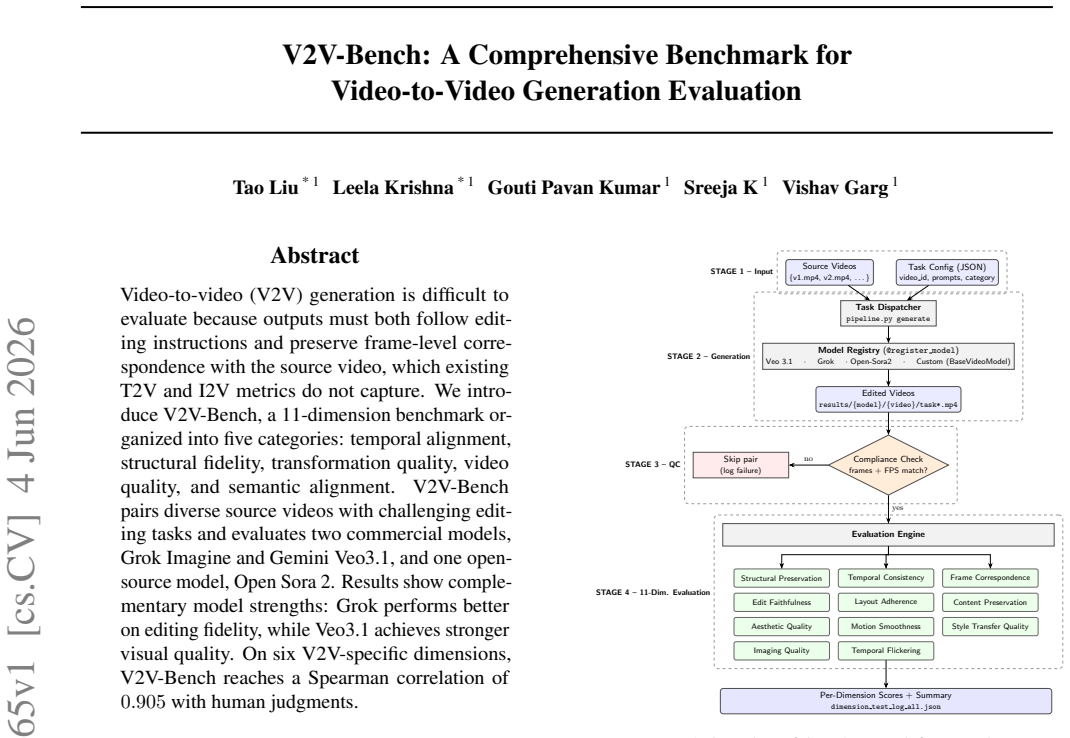
V2V-Bench, the 11-dimension benchmark with categories for temporal alignment, structural fidelity, transformation quality, video quality, and semantic alignment that pairs source videos with editing tasks to score model outputs.
If this is right
- Models can be ranked separately on editing fidelity versus visual quality rather than a single aggregate score.
- Grok Imagine shows stronger editing fidelity while Gemini Veo3 shows stronger visual quality under the benchmark dimensions.
- The same evaluation protocol applies equally to commercial and open-source V2V models.
- The high human correlation on V2V-specific dimensions supports using those six dimensions for future model comparisons.
Where Pith is reading between the lines
- The benchmark could be extended to measure performance on longer videos or more complex multi-step edits without changing its core dimensions.
- Developers might prioritize improvements in the dimensions where current models score lowest to close the gap with human expectations.
- Similar dimension sets could be adapted to evaluate consistency in related tasks such as image-to-video generation.
Load-bearing premise
The chosen source videos and editing tasks are representative enough of real-world video-to-video use cases to support general claims about model performance and benchmark validity.
What would settle it
A new human preference study on a wider collection of videos and models that yields Spearman correlation below 0.8 on the six V2V-specific dimensions would indicate the benchmark does not track human judgment as claimed.
Figures

read the original abstract
Video-to-video (V2V) generation is difficult to evaluate because outputs must both follow editing instructions and preserve frame-level correspondence with the source video, which existing T2V and I2V metrics do not capture. We introduce V2V-Bench, a 11-dimension benchmark organized into five categories: temporal alignment, structural fidelity, transformation quality, video quality, and semantic alignment. V2V-Bench pairs diverse source videos with challenging editing tasks and evaluates two commercial models, Grok Imagine and Gemini Veo3, and one open-source model, Open Sora 2. Results show complementary model strengths: Grok performs better on editing fidelity, while Veo3 achieves stronger visual quality. On six V2V-specific dimensions, V2V-Bench reaches a Spearman correlation of 0.905 with human judgments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces V2V-Bench, an 11-dimension benchmark for video-to-video generation organized into five categories (temporal alignment, structural fidelity, transformation quality, video quality, semantic alignment). It pairs 11 source videos with challenging editing tasks, evaluates Grok Imagine, Gemini Veo3, and Open Sora 2, and reports that the benchmark reaches a Spearman correlation of 0.905 with human judgments on six V2V-specific dimensions.
Significance. If the benchmark construction and human-study validation hold, V2V-Bench would address a clear gap by providing metrics that jointly assess instruction adherence and source-video preservation, unlike existing T2V/I2V metrics. The high reported correlation would indicate strong alignment with human preference, and the observed model complementarity (Grok on fidelity, Veo3 on quality) would offer actionable comparisons for the community.
major comments (2)
- [Dataset Construction / Human Evaluation] The representativeness of the 11 source videos and editing tasks is load-bearing for the central claim that the 0.905 Spearman correlation generalizes. The abstract asserts 'diverse source videos with challenging editing tasks' but supplies no counts, length distribution, motion complexity, category coverage, or provenance; without these details the observed correlation cannot be confidently extrapolated beyond the chosen test set.
- [Benchmark Design] The manuscript states an 11-dimension benchmark yet reports the key correlation only on six 'V2V-specific' dimensions. The criteria used to designate dimensions as V2V-specific, the rationale for selecting exactly those six for the human study, and any statistical validation of the dimension set are not described, weakening the claim of comprehensiveness.
minor comments (1)
- [Abstract] The abstract would benefit from stating the exact number of source videos (11) and models evaluated in the first sentence for immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and will revise the manuscript accordingly to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [Dataset Construction / Human Evaluation] The representativeness of the 11 source videos and editing tasks is load-bearing for the central claim that the 0.905 Spearman correlation generalizes. The abstract asserts 'diverse source videos with challenging editing tasks' but supplies no counts, length distribution, motion complexity, category coverage, or provenance; without these details the observed correlation cannot be confidently extrapolated beyond the chosen test set.
Authors: We agree that the current manuscript lacks sufficient detail on the source videos to allow readers to assess representativeness and generalizability. In the revision we will add a new subsection (and accompanying table) that reports: the exact number of source videos per category, length distribution (mean, min, max in seconds), motion complexity metrics (e.g., average optical-flow magnitude), scene/action category coverage, and provenance (public datasets or generation method). This will directly address the concern and strengthen the extrapolation argument. revision: yes
-
Referee: [Benchmark Design] The manuscript states an 11-dimension benchmark yet reports the key correlation only on six 'V2V-specific' dimensions. The criteria used to designate dimensions as V2V-specific, the rationale for selecting exactly those six for the human study, and any statistical validation of the dimension set are not described, weakening the claim of comprehensiveness.
Authors: We acknowledge that the manuscript does not explicitly define the criteria separating V2V-specific from other dimensions or justify the selection of the six dimensions used for the human correlation study. In the revision we will (1) state the operational definition of V2V-specific dimensions (those that jointly measure instruction adherence and source-video preservation), (2) list the rationale for choosing exactly those six for the human study (highest expected sensitivity to V2V edits plus coverage of the five top-level categories), and (3) add a short statistical validation subsection reporting inter-dimension Spearman correlations and an ablation showing that the six-dimension subset yields higher human correlation than random subsets of the same size. revision: yes
Circularity Check
No circularity; benchmark definition and human correlation are independent empirical measurements.
full rationale
The paper introduces V2V-Bench as an 11-dimension metric suite in five categories and reports an empirical Spearman correlation of 0.905 against human judgments on six dimensions. No equations, fitted parameters, or self-citations appear in the provided text. The correlation is computed on the chosen source videos and editing tasks without any reduction by construction to the benchmark definition itself. The derivation chain consists of metric definition followed by separate human evaluation, which are distinct steps with no self-definitional, fitted-input, or self-citation load-bearing elements. This is a standard non-circular benchmark validation result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
TokenFlow: Consistent Diffusion Features for Consistent Video Editing
Geyer, M., Bar-Tal, O., Bagon, S., and Dekel, T. Tokenflow: Consistent diffusion features for consistent video editing. arXiv preprint arXiv:2307.10373,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
LTX-Video: Realtime Video Latent Diffusion
HaCohen, Y ., Chiprut, N., Brazowski, B., Shalem, D., Moshe, D., Richardson, E., Levin, E., Shiran, G., Zabari, N., Gordon, O., et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103,
work page internal anchor Pith review Pith/arXiv arXiv
- [4]
-
[5]
Klingavatar 2.0 technical report.arXiv preprint arXiv:2512.13313,
Team, K., Chen, J., Ding, Y ., Fang, Z., Gai, K., Gao, Y ., He, K., Hua, J., Jiang, B., Lao, M., et al. Klingavatar 2.0 technical report.arXiv preprint arXiv:2512.13313,
-
[6]
Wang, B., Huang, H., Lu, Z., Liu, F., Ma, G., Yuan, J., Zhang, Y ., Duan, N., and Jiang, D. Storyanchors: Gener- ating consistent multi-scene story frames for long-form narratives.arXiv preprint arXiv:2505.08350, 2025a. Wang, H., Zhang, G., and Yan, K. Based on runway gen-4: A dynamic video generation method for optimizing movie vfx workflows. In2025 3rd ...
-
[7]
Wu, J. Z., Ge, Y ., Wang, X., Lei, S. W., Gu, Y ., Shi, Y ., Hsu, W., Shan, Y ., Qie, X., and Shou, M. Z. Tune-a-video: One- shot tuning of image diffusion models for text-to-video generation.arXiv preprint arXiv:2212.11565,
-
[8]
Zhang, P., Jia, Z., Liu, K., Weng, S., Li, S., and Shi, B. Stage: Storyboard-anchored generation for cinematic multi-shot narrative.arXiv preprint arXiv:2512.12372,
-
[9]
Zhao, M., Wang, R., Bao, F., Li, C., and Zhu, J. Con- trolvideo: Adding conditional control for one shot text- to-video editing.arXiv preprint arXiv:2305.17098, 2(3),
-
[10]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Zheng, D., Huang, Z., Liu, H., Zou, K., He, Y ., Zhang, F., Gu, L., Zhang, Y ., He, J., Zheng, W.-S., et al. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
6 Title Suppressed Due to Excessive Size Table 5.Per-dimension scores on V2V-Bench (higher is better). Dimension Veo-3.1 Grok Open-Sora2 Imaging Quality 0.3460.5780.248 Temporal Flickering 0.983 0.9870.984 Aesthetic Quality0.6070.508 0.503 Motion Smoothness0.9830.976 0.970 Structural Preservation 0.435 0.6740.305 Frame Correspondence 0.711 0.8290.638 Layo...
-
[12]
V2V-core dimensions are marked with †
In the case of a tie, Table 7.Win ratios for every dimension. V2V-core dimensions are marked with †. Dimension Model BENCHGemini 2.5 Pro GPT-4o Human SP† Veo 0.450 0.487 0.550 0.388 Grok0.963 0.650 0.588 0.896 OpenSora 0.087 0.362 0.362 0.217 TC† Veo 0.662 0.463 0.525 0.446 Grok0.800 0.650 0.600 0.840 OpenSora 0.037 0.388 0.375 0.215 FC† Veo 0.425 0.487 0...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.