Cosine Misleads: Auxiliary Losses Reshape Vision Language Models, Not Their Latents
Pith reviewed 2026-06-28 03:04 UTC · model grok-4.3
The pith
Auxiliary cosine losses improve vision-language models by reshaping shared parameters rather than aligning their supervised latents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
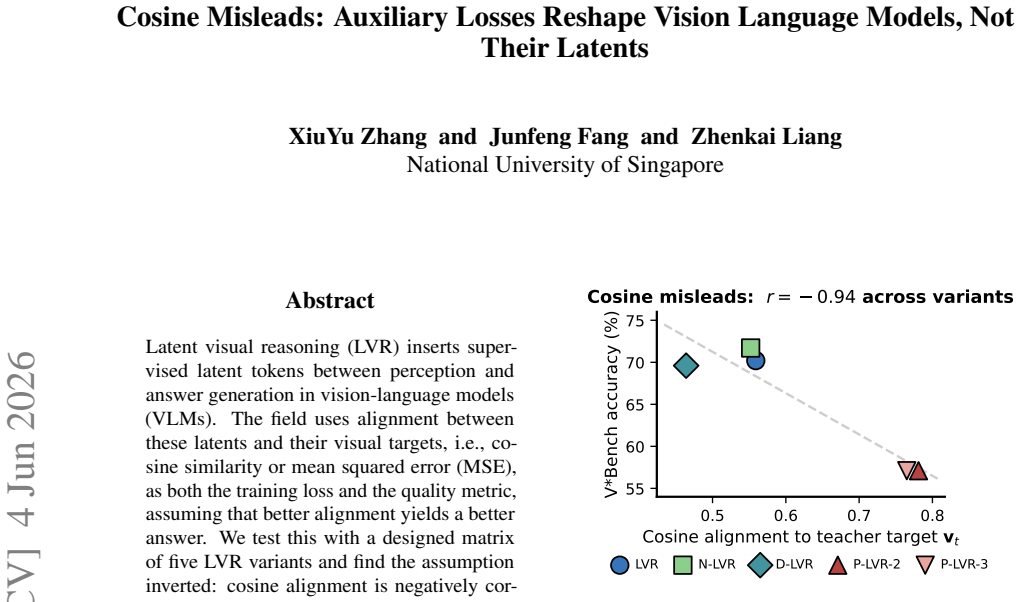
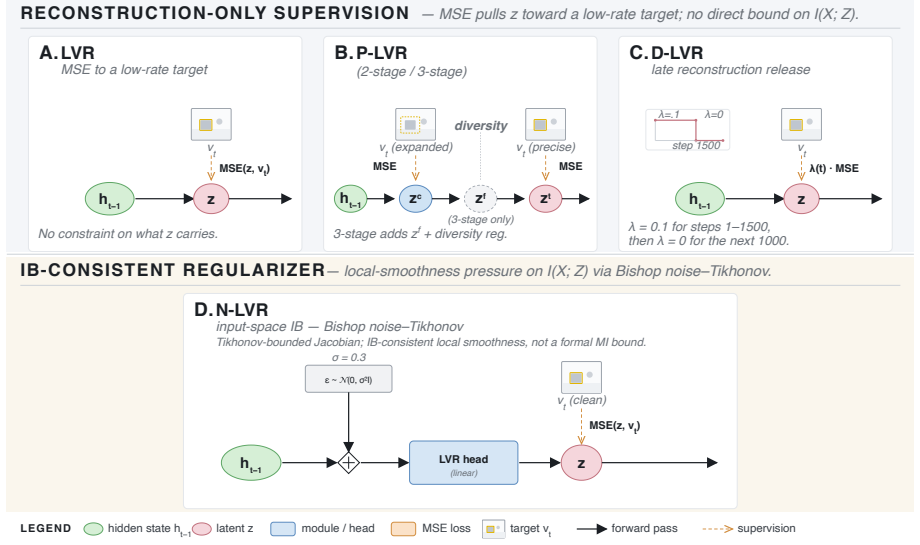
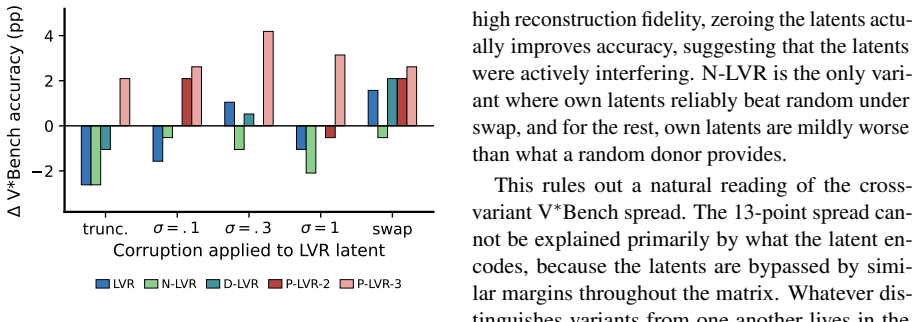
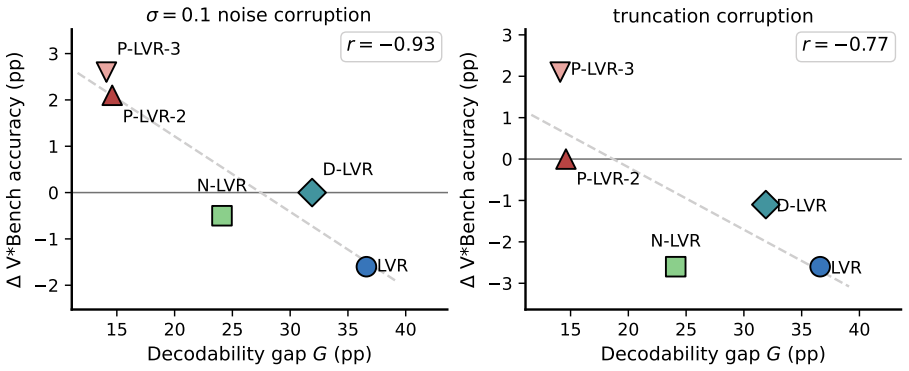
In latent visual reasoning for VLMs the assumption that cosine alignment between supervised latents and visual targets improves answer accuracy is inverted (r=-0.94 across five variants). PRISM diagnostics show the supervised latents are largely bypassed: answers are decodable downstream of the latent but not at it, and corrupting the latents shifts accuracy by at most four points. The auxiliary objective therefore reshapes the language model via shared parameters rather than via the latent variable it nominally optimizes.
What carries the argument
PRISM, a pair of inference-time diagnostics (linear probe for decodability location and corruption test for load-bearing status) that measure whether the supervised latent carries the answer.
If this is right
- Cosine similarity and MSE are unreliable training signals for latent visual reasoning because they do not track downstream utility.
- Performance gains from auxiliary losses arise from changes to shared language-model parameters, not from the latents themselves.
- The decodability gap between the latent and later layers predicts how much a given variant will rely on its latent when perturbed.
- Information-bottleneck dynamics explain why an auxiliary objective can improve accuracy while leaving its nominal latent variable unused.
- The same bypassing pattern holds across multiple LVR architectural variants.
Where Pith is reading between the lines
- Designers of other auxiliary-loss regimes in multimodal models should test whether gains come from parameter sharing rather than from the explicit intermediate representation.
- Directly optimizing for the downstream reshaping effect could replace alignment objectives in future LVR training.
- The result raises the question of whether similar bypassing occurs in other chain-of-thought or latent-reasoning setups that use auxiliary supervision.
Load-bearing premise
The linear probe and corruption test accurately measure whether the answer is decodable at the latent and whether the latent is load-bearing for the final answer.
What would settle it
An experiment that forces the latent to be the sole information path (for example by zeroing all other connections after the latent) and then checks whether cosine alignment then becomes positively correlated with accuracy.
Figures

read the original abstract
Latent visual reasoning (LVR) inserts supervised latent tokens between perception and answer generation in vision-language models (VLMs). The field uses alignment between these latents and their visual targets, i.e., cosine similarity or mean squared error (MSE), as both the training loss and the quality metric, assuming that better alignment yields a better answer. We test this with a designed matrix of five LVR variants and find the assumption inverted: cosine alignment is negatively correlated with accuracy across all five (r=-0.94). To explain this, we introduce PRISM, a pair of inference-time diagnostics: a linear probe that asks where the answer is decodable, and a corruption test that asks whether the latent is load-bearing. The supervised latents are largely bypassed. Corrupting them shifts accuracy by at most four points. The answer is decodable downstream of the latent but not at it, and the size of this decodability gap predicts how much each variant relies on its latent under perturbation. Consistent with an Information Bottleneck reading of the loss, the auxiliary objective reshapes the language model via shared parameters rather than via the latent variable it nominally optimizes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines the effectiveness of cosine similarity as both a training loss and quality metric for supervised latent tokens in latent visual reasoning (LVR) setups within vision-language models. Across a designed matrix of five LVR variants, it reports a strong negative correlation (r=-0.94) between cosine alignment and downstream accuracy, inverting the standard assumption. The authors introduce PRISM (a linear probe for decodability and a corruption test for load-bearing status) to show that the supervised latents are largely bypassed: the answer is decodable downstream of the latent but not at it, corruption shifts accuracy by at most four points, and the decodability gap predicts reliance on the latent. The auxiliary objective is argued to reshape the language model via shared parameters rather than the nominal latent, consistent with an Information Bottleneck view.
Significance. If the central empirical findings hold after validation of the diagnostics, the result would be significant for VLM training practices, as it challenges reliance on alignment metrics like cosine similarity or MSE for latent quality and suggests auxiliary losses primarily act through parameter sharing. The direct measurements across variants and the introduction of inference-time tests are strengths of the empirical approach.
major comments (2)
- [Abstract] Abstract: The PRISM diagnostics (linear probe for decodability location and corruption test for load-bearing status) are introduced as the key evidence for the bypass claim without any reported controls, ablations, sanity checks, or validation (e.g., probe capacity, whether corruption perturbs attention/shared weights, or tests on architectures where the latent is known to be critical). This is load-bearing for the central claim that latents are bypassed and the auxiliary loss acts via shared parameters.
- [Abstract] Abstract and experimental matrix: The r=-0.94 correlation is reported across only five variants with no details on statistical controls, variance, or sensitivity to variant selection; this small n makes the inversion claim sensitive and requires additional robustness checks to support the conclusion that cosine alignment is anti-correlated with accuracy.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify areas where additional validation and robustness analysis would strengthen the manuscript. We address each point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: The PRISM diagnostics (linear probe for decodability location and corruption test for load-bearing status) are introduced as the key evidence for the bypass claim without any reported controls, ablations, sanity checks, or validation (e.g., probe capacity, whether corruption perturbs attention/shared weights, or tests on architectures where the latent is known to be critical). This is load-bearing for the central claim that latents are bypassed and the auxiliary loss acts via shared parameters.
Authors: We agree that the abstract does not enumerate explicit controls and that further validation would make the PRISM diagnostics more robust. The full manuscript already varies probe capacity implicitly through layer-wise testing and applies corruption across all five variants while monitoring downstream effects. To directly address the referee's examples, the revision will add: (i) an ablation on probe hidden dimension and regularization, (ii) attention-map comparisons before/after corruption to confirm shared weights are not inadvertently perturbed, and (iii) a discussion of why direct tests on architectures with provably critical latents are currently limited by the LVR literature. These additions will appear in a new subsection on diagnostic validation. revision: yes
-
Referee: [Abstract] Abstract and experimental matrix: The r=-0.94 correlation is reported across only five variants with no details on statistical controls, variance, or sensitivity to variant selection; this small n makes the inversion claim sensitive and requires additional robustness checks to support the conclusion that cosine alignment is anti-correlated with accuracy.
Authors: The five variants were deliberately constructed to span distinct supervision, alignment, and architectural choices rather than random sampling; the negative correlation is uniform across them. We acknowledge that n=5 warrants explicit sensitivity analysis. The revision will include: bootstrap confidence intervals for the correlation, per-variant accuracy variance across random seeds, and a leave-one-variant-out sensitivity check. These results will be reported in the experimental matrix section and will qualify the strength of the inversion claim. revision: yes
Circularity Check
No circularity: purely empirical measurements with direct observations
full rationale
The paper reports experimental results across five LVR variants, including a measured correlation (r=-0.94) between cosine alignment and accuracy, plus outcomes from linear probes and corruption tests. No equations, derivations, or first-principles claims are present that could reduce to inputs by construction. PRISM diagnostics are introduced as new inference-time tests whose validity is assessed via the reported empirical outcomes themselves; no self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The analysis is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions about linear probes and corruption tests as valid measures of decodability and causal importance in neural networks
invented entities (1)
-
PRISM (linear probe + corruption test pair)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
An Introduction to Vision-Language Modeling , author=. 2024 , eprint=
2024
-
[2]
The Fourteenth International Conference on Learning Representations , year=
Latent Visual Reasoning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[3]
2025 , eprint=
Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens , author=. 2025 , eprint=
2025
-
[4]
2026 , eprint=
Interleaved Latent Visual Reasoning with Selective Perceptual Modeling , author=. 2026 , eprint=
2026
-
[5]
2025 , eprint=
Monet: Reasoning in Latent Visual Space Beyond Images and Language , author=. 2025 , eprint=
2025
-
[6]
2026 , eprint=
Vision-aligned Latent Reasoning for Multi-modal Large Language Model , author=. 2026 , eprint=
2026
-
[7]
V*: Guided Visual Search as a Core Mechanism in Multimodal LLMs , year=
Wu, Penghao and Xie, Saining , booktitle=. V*: Guided Visual Search as a Core Mechanism in Multimodal LLMs , year=
-
[8]
and Ma, Wei-Chiu and Krishna, Ranjay , title =
Fu, Xingyu and Hu, Yushi and Li, Bangzheng and Feng, Yu and Wang, Haoyu and Lin, Xudong and Roth, Dan and Smith, Noah A. and Ma, Wei-Chiu and Krishna, Ranjay , title =. 2024 , isbn =. doi:10.1007/978-3-031-73337-6_9 , booktitle =
-
[9]
In: 2024 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR)
Tong, Shengbang and Liu, Zhuang and Zhai, Yuexiang and Ma, Yi and LeCun, Yann and Xie, Saining , booktitle =. 2024 , volume =. doi:10.1109/CVPR52733.2024.00914 , url =
-
[10]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Leng, Xingjian and Singh, Jaskirat and Hou, Yunzhong and Xing, Zhenchang and Xie, Saining and Zheng, Liang , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[11]
2018 , eprint=
Understanding intermediate layers using linear classifier probes , author=. 2018 , eprint=
2018
-
[12]
Designing and Interpreting Probes with Control Tasks
Hewitt, John and Liang, Percy. Designing and Interpreting Probes with Control Tasks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1275
-
[13]
Computational Linguistics , volume =
Belinkov, Yonatan. Probing Classifiers: Promises, Shortcomings, and Advances. Computational Linguistics. 2022. doi:10.1162/coli_a_00422
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[14]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[15]
Measuring chain of thought faithfulness by unlearning reasoning steps
Tutek, Martin and Hashemi Chaleshtori, Fateme and Marasovic, Ana and Belinkov, Yonatan. Measuring Chain of Thought Faithfulness by Unlearning Reasoning Steps. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.504
-
[16]
2000 , eprint=
The information bottleneck method , author=. 2000 , eprint=
2000
-
[17]
International Conference on Learning Representations , year=
Deep Variational Information Bottleneck , author=. International Conference on Learning Representations , year=
-
[18]
Information Maximization in Noisy Channels : A Variational Approach , url =
Barber, David and Agakov, Felix , booktitle =. Information Maximization in Noisy Channels : A Variational Approach , url =
-
[19]
, journal=
Bishop, Chris M. , journal=. Training with Noise is Equivalent to Tikhonov Regularization , year=
-
[20]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[21]
The Thirty-eighth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Visual CoT: Advancing Multi-Modal Language Models with a Comprehensive Dataset and Benchmark for Chain-of-Thought Reasoning , author=. The Thirty-eighth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.