TARPO: Token-Wise Latent-Explicit Reasoning via Action-Routing Policy Optimization
Pith reviewed 2026-06-28 01:38 UTC · model grok-4.3
The pith
TARPO trains LLMs to decide at each token whether to output explicitly or reason in continuous latent space using reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
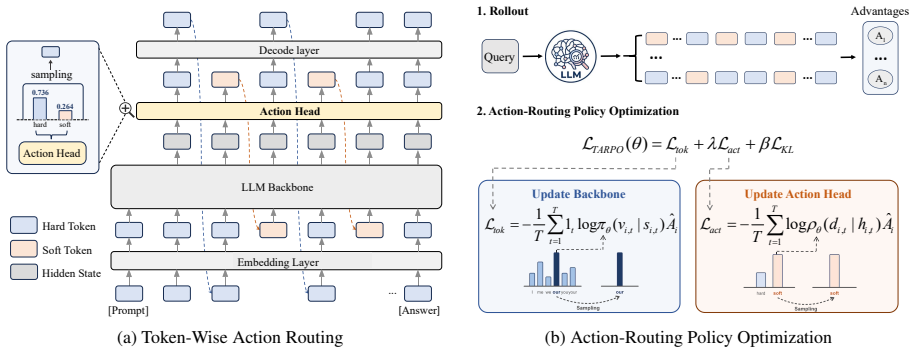
TARPO is a pure RL framework in which an action head router observes the hidden state at each step and samples a binary decision to route either to discrete token generation from the vocabulary or to continuous latent reasoning; the LLM and router are optimized end-to-end with group-relative advantages, producing better reasoning performance than baselines that stay fixed in one mode.
What carries the argument
The lightweight action head router that samples a binary mode-selection decision from the current hidden state to choose between explicit token output and latent reasoning.
If this is right
- Models learn to insert latent steps only where they help, avoiding unnecessary explicit tokens.
- Joint optimization keeps training dynamics stable while exploring both reasoning modes.
- The same routing mechanism works across model families and sizes from 1.5B to 8B parameters.
- Adaptive switching reduces reliance on fixed-length explicit chains.
Where Pith is reading between the lines
- The binary router could be extended to multi-way decisions that include different latent granularities.
- If the router generalizes, it may allow hybrid reasoning on tasks where pure latent methods currently underperform.
- Ablating the router after training would test whether the learned policy truly depends on per-step adaptation.
Load-bearing premise
A simple router looking only at the current hidden state can produce routing decisions that preserve enough randomness for effective exploration in the combined discrete-latent policy.
What would settle it
Running the same benchmarks with the router removed or with its sampling made deterministic yields no improvement or a drop relative to the non-routed latent or explicit baselines.
Figures




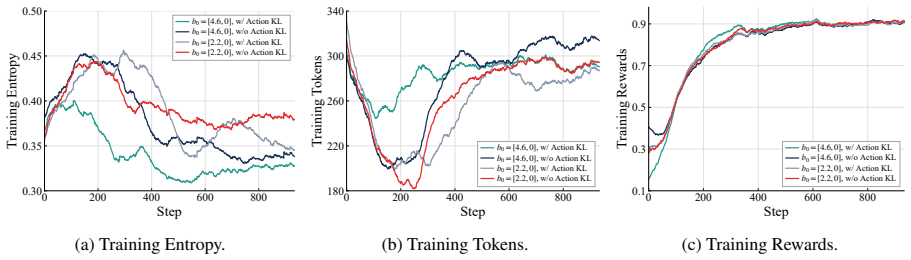
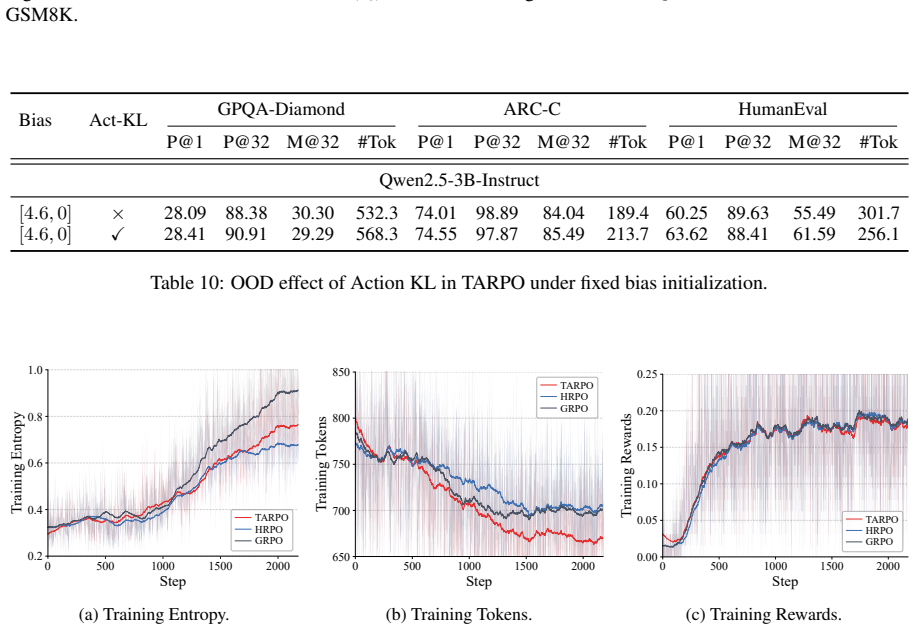
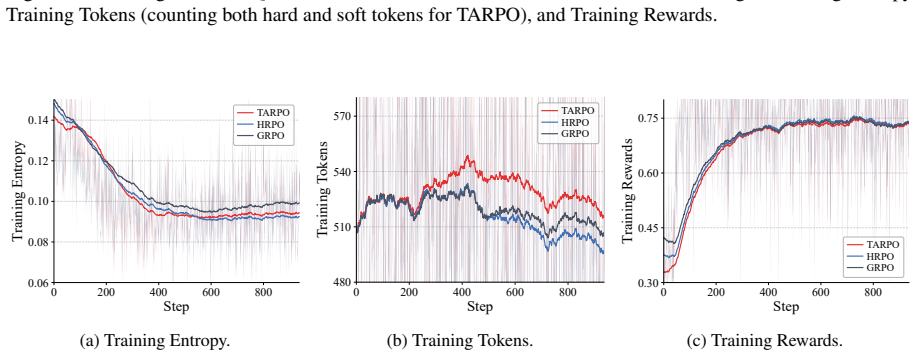
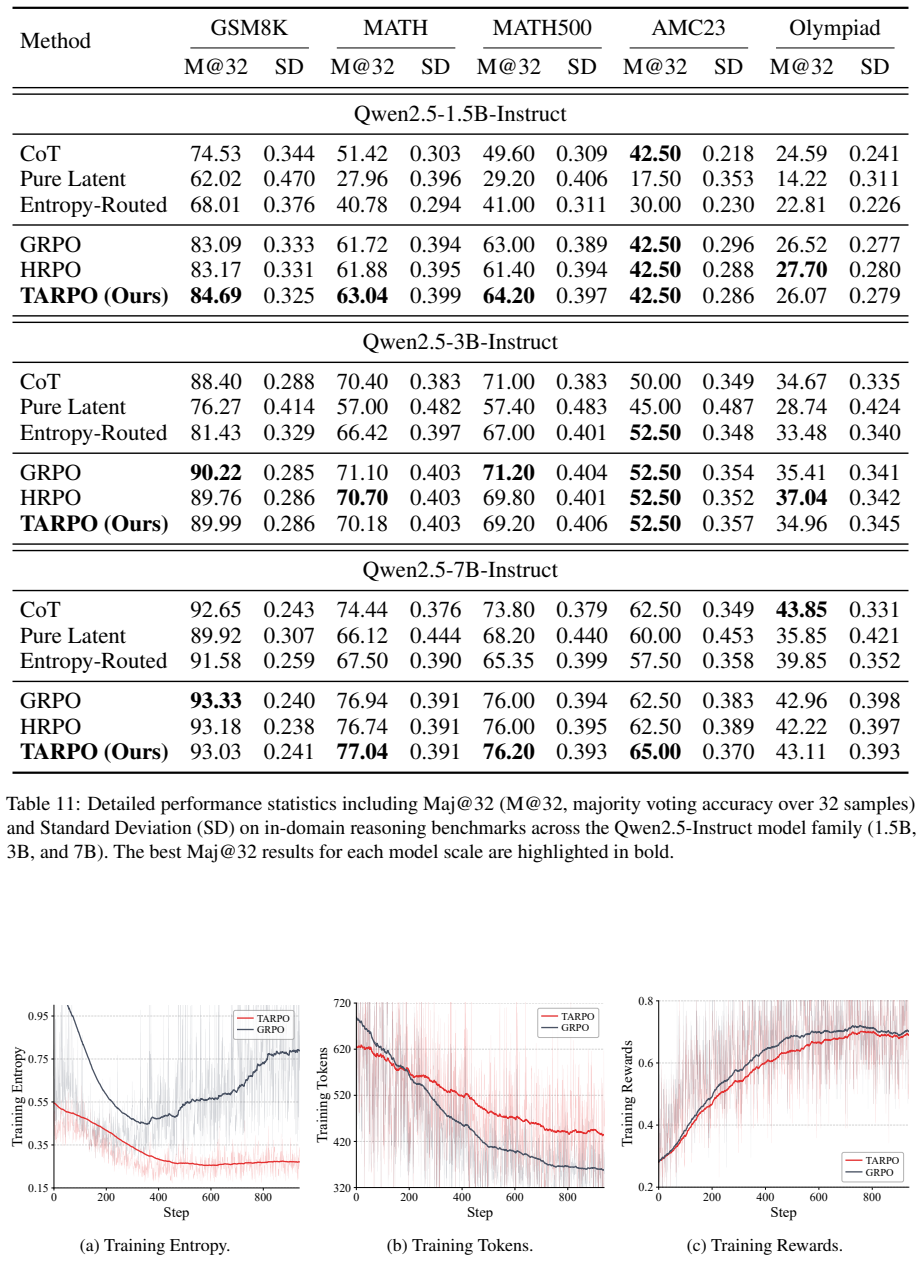
read the original abstract
Latent reasoning has emerged as a promising alternative to discrete Chain-of-Thought (CoT) in large language models (LLMs), enabling more expressive reasoning by operating over continuous representations. However, the inherently deterministic nature of continuous representations limits policy exploration in reinforcement learning (RL). To address this, we propose TARPO (Token-Wise Latent-Explicit Reasoning via Action-Routing Policy Optimization), a pure RL framework that adaptively switches between discrete token generation and continuous latent reasoning at each step. TARPO introduces a lightweight action head router that observes the current hidden state and samples a routing decision from a binary mode-selection space, preserving the stochasticity of discrete token sampling from the vocabulary. The LLM backbone and router are jointly optimized end-to-end with a shared group-relative advantage signal. Extensive experiments across Qwen2.5 (from 1.5B to 7B) and Llama-3.1-8B backbones demonstrate that TARPO consistently outperforms existing explicit and latent reasoning RL baselines across diverse benchmarks. Further analysis shows that TARPO learns adaptive token-wise switching behaviors while maintaining stable training dynamics. Our code is available at https://github.com/NKU-LITI/TARPO-master.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TARPO, a pure RL framework for LLMs that adaptively routes between discrete token generation and continuous latent reasoning at each step via a lightweight action head router. The router observes the hidden state and samples from a binary mode-selection space; the backbone and router are jointly optimized end-to-end using a shared group-relative advantage. Experiments on Qwen2.5 (1.5B–7B) and Llama-3.1-8B models report consistent outperformance over explicit and latent RL baselines across diverse benchmarks, with additional analysis of learned switching behavior and training stability. Code is released.
Significance. If the empirical gains and the router's exploration properties hold under scrutiny, TARPO would offer a practical way to combine the expressivity of latent reasoning with the stochasticity of discrete sampling inside a single RL loop. The end-to-end joint optimization and released code are positive features for reproducibility.
major comments (2)
- [Abstract / router description] The central claim that the binary router 'preserves the stochasticity of discrete token sampling' (Abstract) rests on an unverified assumption: that a 1-bit decision per step, conditioned only on the hidden state and trained with the same group-relative advantage, will not collapse under joint optimization. No entropy regularization, temperature schedule, or router-entropy curves are referenced to counteract this risk; without such evidence the advantage over purely latent baselines is not yet load-bearing.
- [Abstract] The outperformance claim is stated without any quantitative support in the provided abstract (no metrics, baselines, or ablation tables). Even if the full experimental section exists, the absence of these details in the summary makes it impossible to evaluate whether the router mechanism, rather than other implementation choices, drives the reported gains.
minor comments (1)
- Notation for the binary mode-selection space and the precise interface between the router output and the LLM forward pass should be formalized with an equation or pseudocode for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the router's stochastic properties and the abstract's clarity. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract / router description] The central claim that the binary router 'preserves the stochasticity of discrete token sampling' (Abstract) rests on an unverified assumption: that a 1-bit decision per step, conditioned only on the hidden state and trained with the same group-relative advantage, will not collapse under joint optimization. No entropy regularization, temperature schedule, or router-entropy curves are referenced to counteract this risk; without such evidence the advantage over purely latent baselines is not yet load-bearing.
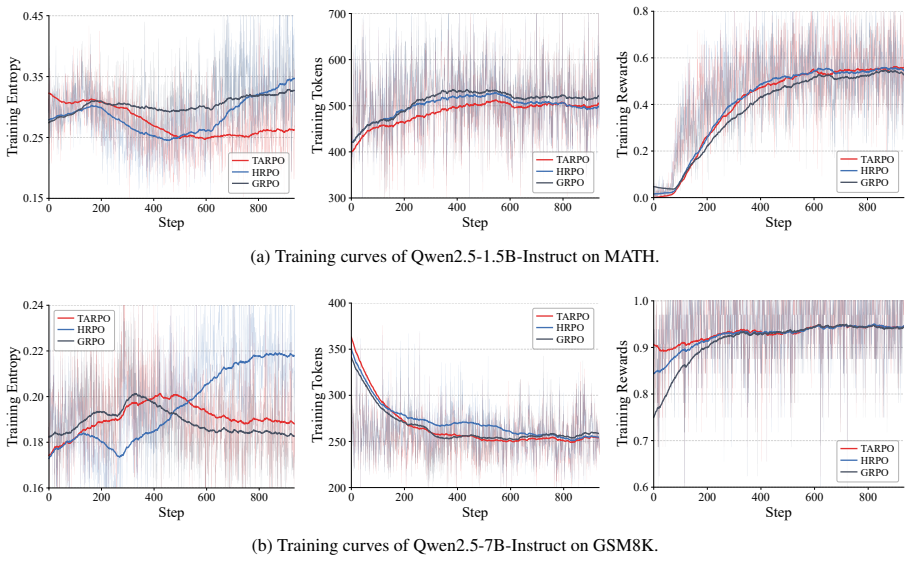
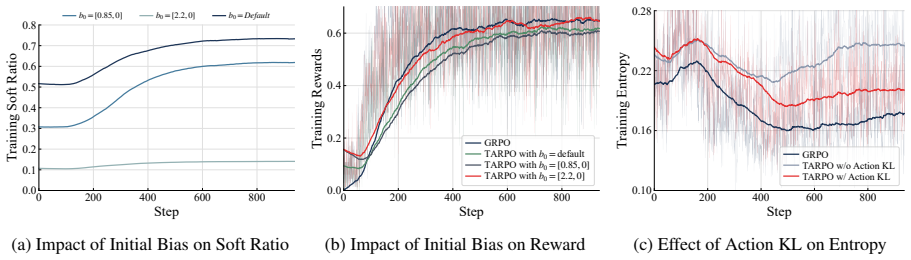
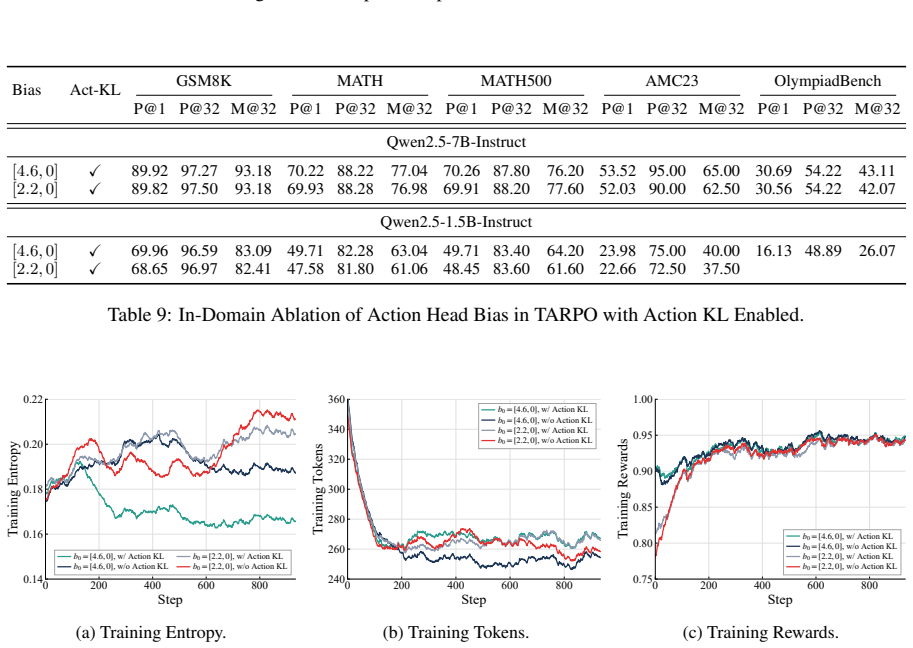
Authors: We agree that the manuscript would benefit from explicit evidence that the router does not collapse. The router samples from a binary mode-selection space at each step, which introduces stochasticity by construction. The full manuscript analyzes learned switching behavior showing non-trivial, context-dependent routing decisions. To directly address the concern about potential collapse under joint optimization, we will add router-entropy curves and related analysis in the revised version. revision: yes
-
Referee: [Abstract] The outperformance claim is stated without any quantitative support in the provided abstract (no metrics, baselines, or ablation tables). Even if the full experimental section exists, the absence of these details in the summary makes it impossible to evaluate whether the router mechanism, rather than other implementation choices, drives the reported gains.
Authors: We acknowledge that the current abstract lacks specific quantitative results, which limits immediate evaluation. The full paper reports consistent gains on Qwen2.5 and Llama-3.1 models across benchmarks, but to improve clarity we will revise the abstract to include key metrics (e.g., average improvements) and name the primary baselines. revision: yes
Circularity Check
No significant circularity; empirical framework with independent components
full rationale
The paper introduces TARPO as an RL method with a new lightweight router for binary mode selection, jointly optimized via group-relative advantage, and supports its claims solely through benchmark experiments on Qwen and Llama models. No derivation chain, first-principles predictions, or mathematical results are presented that reduce to fitted parameters, self-definitions, or self-citation chains. The router's stochasticity claim is an architectural definition, not a tautological prediction, and performance outperformance is an empirical observation rather than a constructed result. The framework is self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
invented entities (1)
-
action head router
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[2]
International Conference on Machine Learning , pages=
Metastable Dynamics of Chain-of-Thought Reasoning: Provable Benefits of Search, RL and Distillation , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[3]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[4]
Advances in neural information processing systems , volume=
Large language models are zero-shot reasoners , author=. Advances in neural information processing systems , volume=
-
[5]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[6]
Advances in Neural Information Processing Systems , volume=
S-grpo: Early exit via reinforcement learning in reasoning models , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[8]
2025 , eprint=
A Survey on Latent Reasoning , author=. 2025 , eprint=
2025
-
[9]
arXiv preprint arXiv:2505.16782 , year=
Reasoning Beyond Language: A Comprehensive Survey on Latent Chain-of-Thought Reasoning , author=. arXiv preprint arXiv:2505.16782 , year=
-
[10]
arXiv preprint arXiv:2501.19201 , year=
Efficient reasoning with hidden thinking , author=. arXiv preprint arXiv:2501.19201 , year=
-
[11]
arXiv preprint arXiv:2502.03275 , year=
Token assorted: Mixing latent and text tokens for improved language model reasoning , author=. arXiv preprint arXiv:2502.03275 , year=
-
[12]
arXiv preprint arXiv:2412.06769 , year=
Training large language models to reason in a continuous latent space , author=. arXiv preprint arXiv:2412.06769 , year=
-
[13]
Advances in Neural Information Processing Systems , volume=
Reasoning by superposition: A theoretical perspective on chain of continuous thought , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
arXiv preprint arXiv:2405.14838 , year=
From explicit cot to implicit cot: Learning to internalize cot step by step , author=. arXiv preprint arXiv:2405.14838 , year=
-
[15]
International Conference on Learning Representations , volume=
Think before you speak: Training language models with pause tokens , author=. International Conference on Learning Representations , volume=
-
[16]
arXiv preprint arXiv:2403.09629 , year=
Quiet-star: Language models can teach themselves to think before speaking , author=. arXiv preprint arXiv:2403.09629 , year=
-
[17]
Advances in Neural Information Processing Systems , volume=
System-1.5 reasoning: Traversal in language and latent spaces with dynamic shortcuts , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
arXiv preprint arXiv:2505.13308 , year=
Seek in the dark: Reasoning via test-time instance-level policy gradient in latent space , author=. arXiv preprint arXiv:2505.13308 , year=
-
[19]
Advances in Neural Information Processing Systems , volume=
Soft thinking: Unlocking the reasoning potential of llms in continuous concept space , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Advances in Neural Information Processing Systems , volume=
Scaling up test-time compute with latent reasoning: A recurrent depth approach , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
arXiv preprint arXiv:2508.03440 , year=
Llms are single-threaded reasoners: Demystifying the working mechanism of soft thinking , author=. arXiv preprint arXiv:2508.03440 , year=
-
[22]
arXiv preprint arXiv:2509.19170 , year=
Soft tokens, hard truths , author=. arXiv preprint arXiv:2509.19170 , year=
-
[23]
arXiv preprint arXiv:2511.06411 , year=
SofT-GRPO: Surpassing Discrete-Token LLM Reinforcement Learning via Gumbel-Reparameterized Soft-Thinking Policy Optimization , author=. arXiv preprint arXiv:2511.06411 , year=
-
[24]
arXiv e-prints , pages=
LEPO: Latent Reasoning Policy Optimization for Large Language Models , author=. arXiv e-prints , pages=
-
[25]
Advances in Neural Information Processing Systems , volume=
Think silently, think fast: Dynamic latent compression of llm reasoning chains , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
arXiv preprint arXiv:2604.27998 , year=
Latent-GRPO: Group Relative Policy Optimization for Latent Reasoning , author=. arXiv preprint arXiv:2604.27998 , year=
-
[27]
arXiv preprint arXiv:2505.19092 , year=
Reinforced latent reasoning for llm-based recommendation , author=. arXiv preprint arXiv:2505.19092 , year=
-
[28]
Advances in Neural Information Processing Systems , volume=
Hybrid latent reasoning via reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
arXiv preprint arXiv:2601.08808 , year=
Multiplex Thinking: Reasoning via Token-wise Branch-and-Merge , author=. arXiv preprint arXiv:2601.08808 , year=
-
[30]
arXiv preprint arXiv:2510.05069 , year=
SwiReasoning: Switch-Thinking in Latent and Explicit for Pareto-Superior Reasoning LLMs , author=. arXiv preprint arXiv:2510.05069 , year=
-
[31]
arXiv preprint arXiv:2602.11683 , year=
ThinkRouter: Efficient Reasoning via Routing Thinking between Latent and Discrete Spaces , author=. arXiv preprint arXiv:2602.11683 , year=
-
[32]
arXiv preprint arXiv:2604.08299 , year=
SeLaR: Selective Latent Reasoning in Large Language Models , author=. arXiv preprint arXiv:2604.08299 , year=
-
[33]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Beyond Tokens: Dynamic Latent Reasoning via Semantic Residual Refinement , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[34]
arXiv preprint arXiv:2512.02240 , year=
Lightweight Latent Reasoning for Narrative Tasks , author=. arXiv preprint arXiv:2512.02240 , year=
-
[35]
The Fourteenth International Conference on Learning Representations , year=
Learning to Reason over Continuous Tokens with Reinforcement Learning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[36]
arXiv preprint arXiv:2511.08577 , year=
Think-at-Hard: Selective Latent Iterations to Improve Reasoning Language Models , author=. arXiv preprint arXiv:2511.08577 , year=
-
[37]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Softcot: Soft chain-of-thought for efficient reasoning with llms , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[38]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[39]
Measuring Mathematical Problem Solving With the MATH Dataset , author=
-
[40]
Advances in Neural Information Processing Systems , volume=
Dapo: An open-source llm reinforcement learning system at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[42]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark , author=
-
[43]
Bowman , booktitle=
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle=. 2024 , url=
2024
-
[44]
arXiv preprint arXiv:2311.12022 , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
-
[45]
arXiv preprint arXiv:1803.05457 , year=
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
-
[46]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.