Causal Scaffolding for Physical Reasoning: A Benchmark for Causally-Informed Physical World Understanding in VLMs
Pith reviewed 2026-06-27 23:13 UTC · model grok-4.3
The pith
Vision-language models improve physical reasoning when their chains of thought are aligned with expert causal graphs of object dependencies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
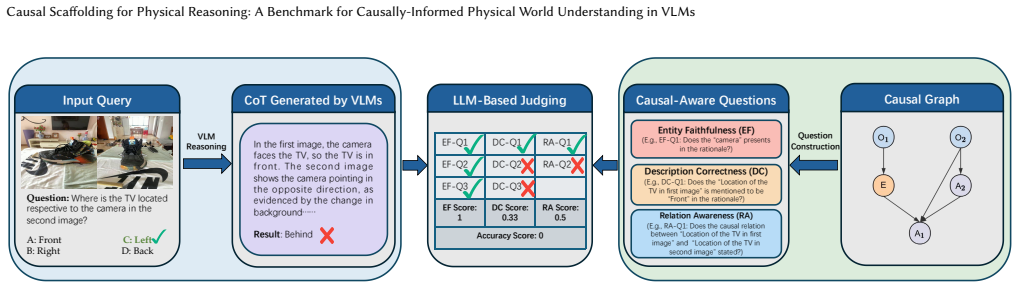
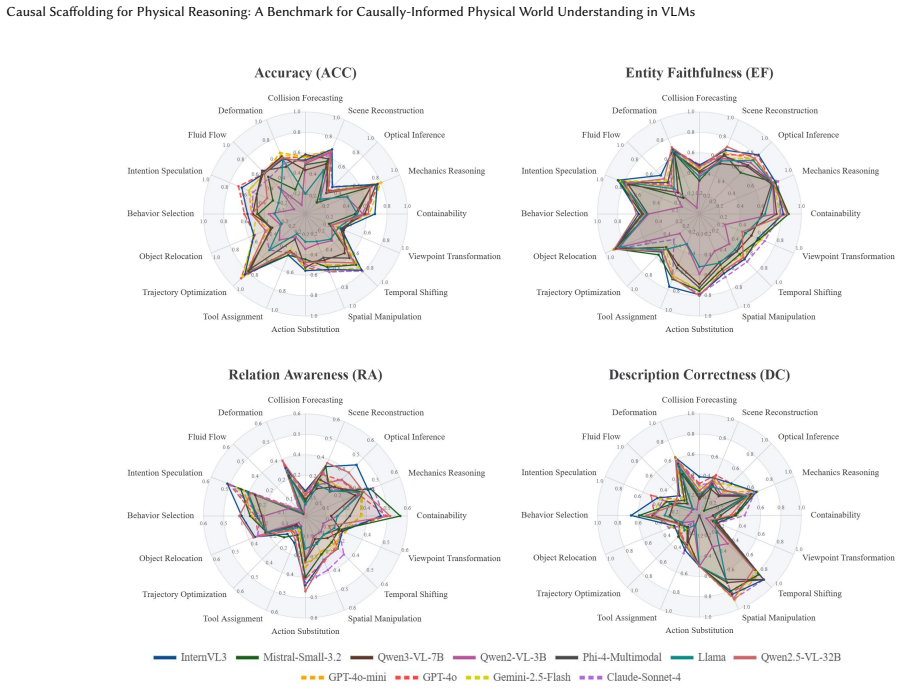
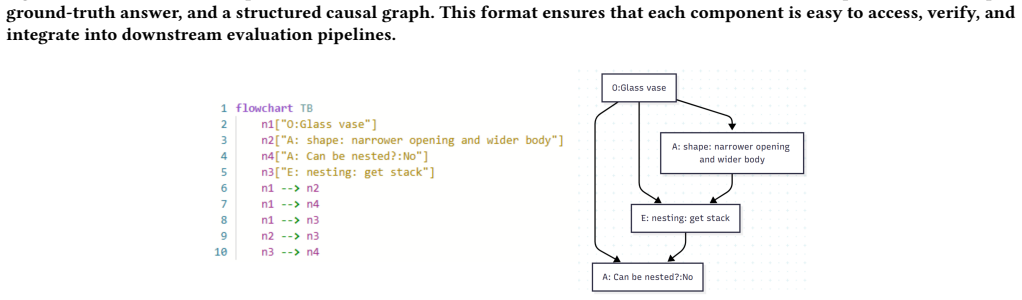
Expert-annotated causal graphs paired with questions allow a new metric to diagnose how well VLM reasoning chains respect object-attribute-event dependencies; explicitly fine-tuning models to produce chains that match these graphs raises both accuracy and the alignment score on physical reasoning tasks.
What carries the argument
The causal-graph-grounded metric that scores alignment between a model's chain-of-thought and the expert causal relations; Causal Rationale-informed Fine-Tuning (CRFT) that enforces this alignment during training.
If this is right
- Models can be systematically diagnosed for which causal links they miss rather than only whether their final answers are right.
- Causality-aware training produces reasoning traces that are more human-interpretable in addition to being more accurate.
- The same graph-based supervision approach can be applied to any domain where object or event dependencies can be annotated.
- Future model development can target specific gaps in causal structure capture rather than generic accuracy.
Where Pith is reading between the lines
- The method may generalize to non-physical domains if similar causal graphs can be constructed for those tasks.
- Current pre-training objectives may need to be augmented with explicit causal structure signals to reduce reliance on post-hoc fine-tuning.
- The benchmark could serve as a testbed for comparing different ways of injecting causal knowledge, such as graph neural modules versus text-based prompting.
Load-bearing premise
The expert-annotated causal graphs correctly capture the true dependencies among objects, attributes, and events in the physical scenes.
What would settle it
A controlled test in which CRFT is applied to multiple VLMs and the resulting accuracy and alignment scores on a new set of physical scenarios show no improvement over standard fine-tuning.
Figures



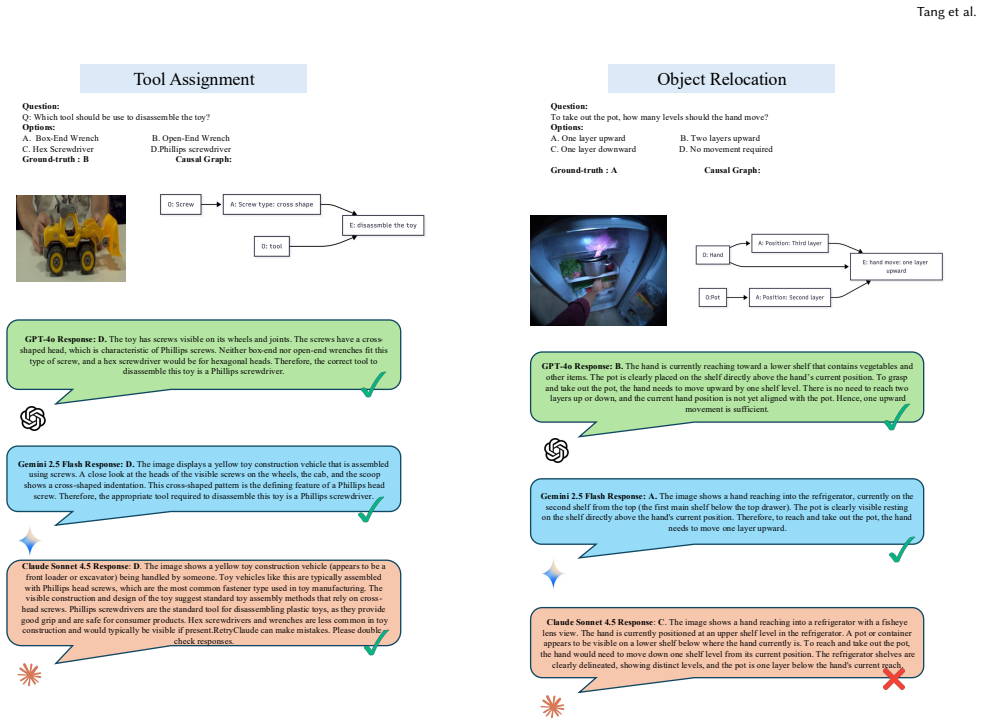
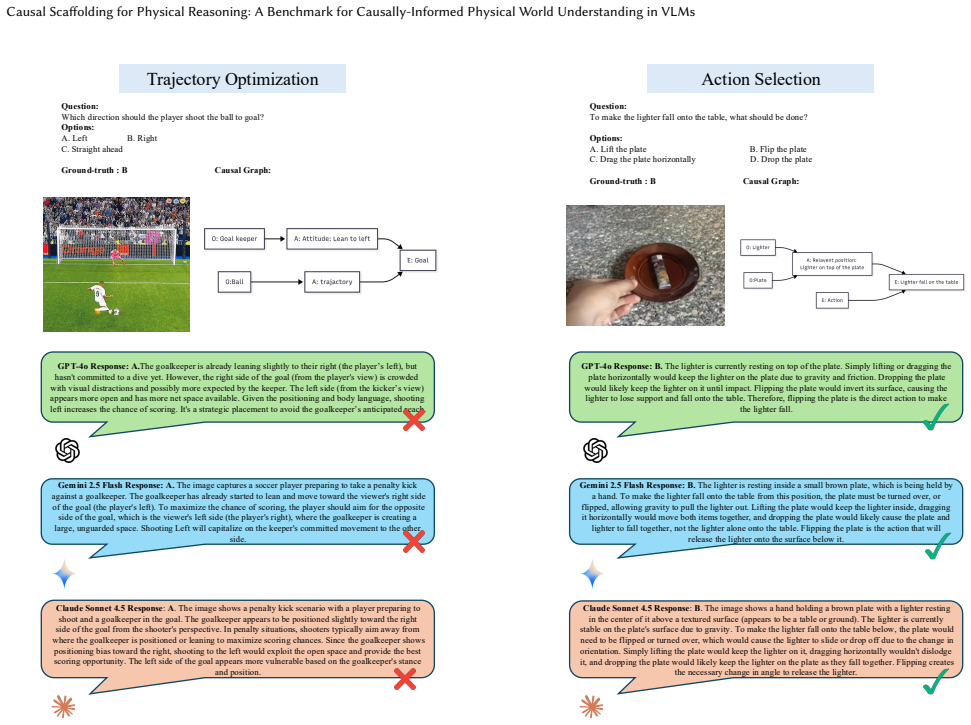
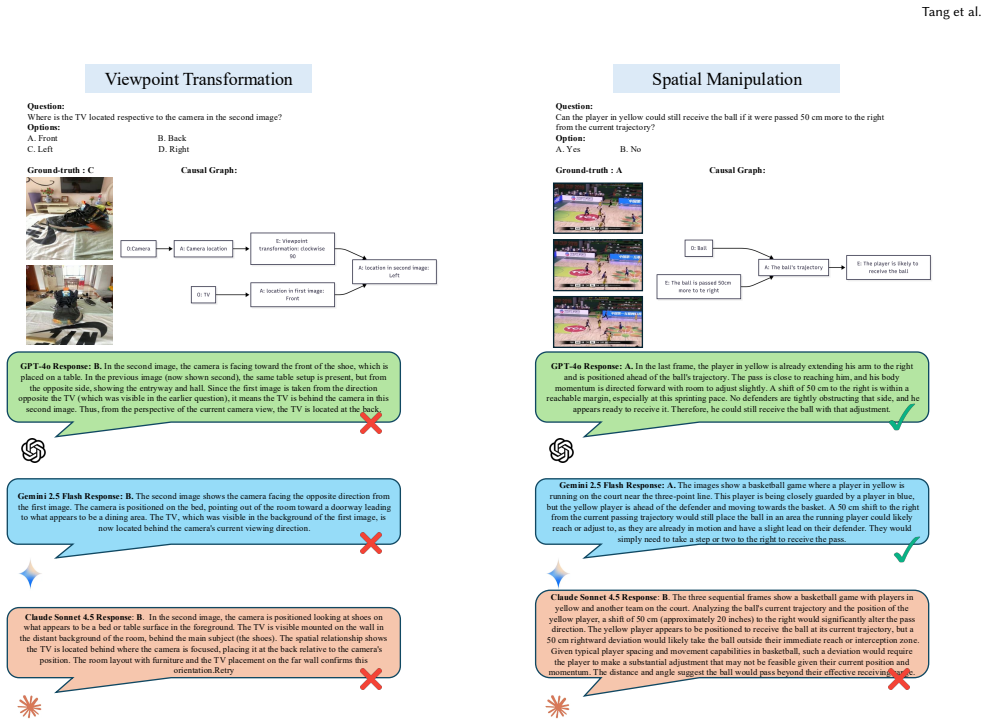
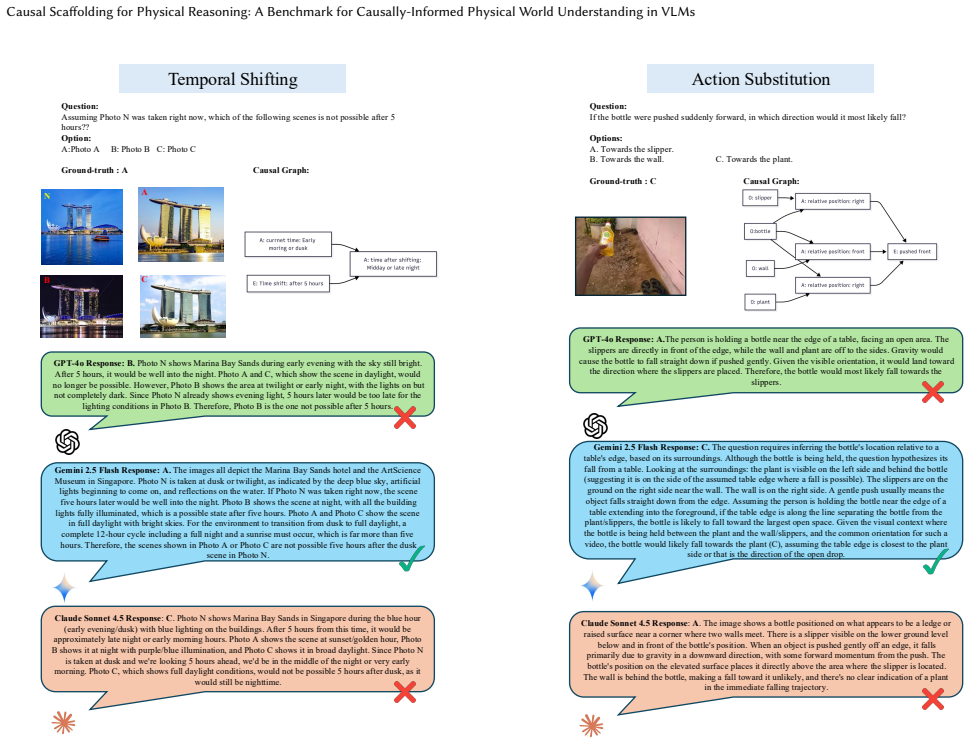
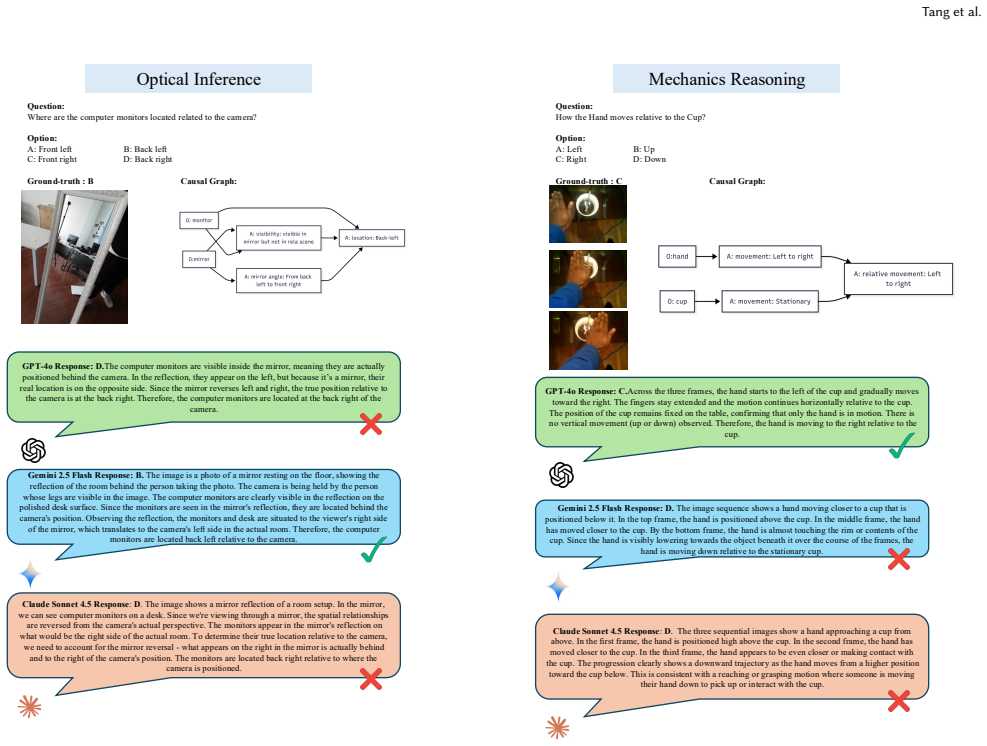
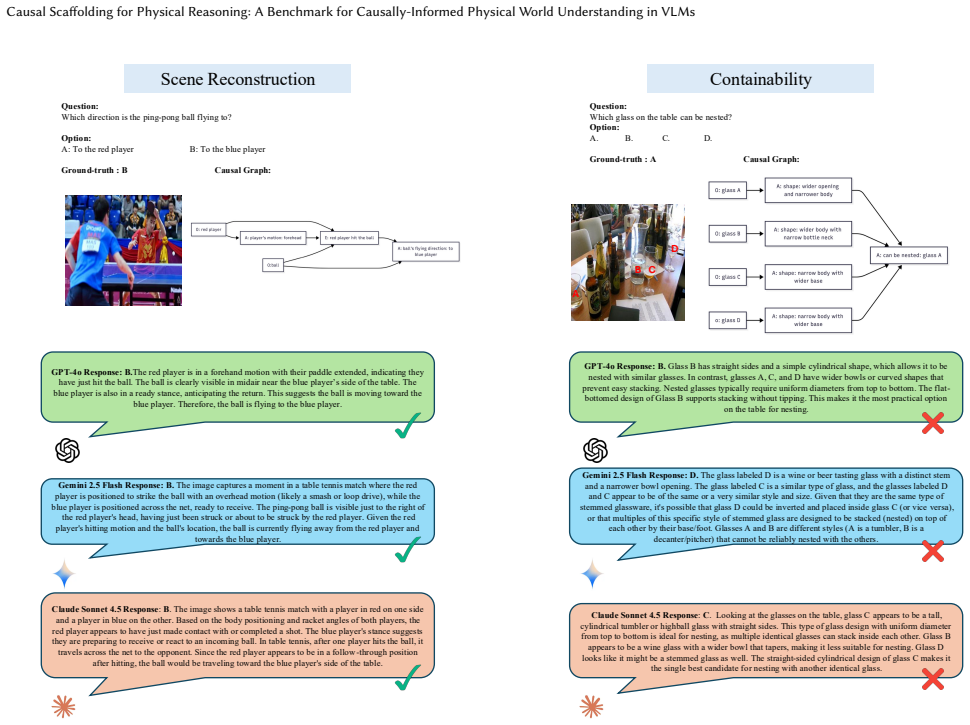
read the original abstract
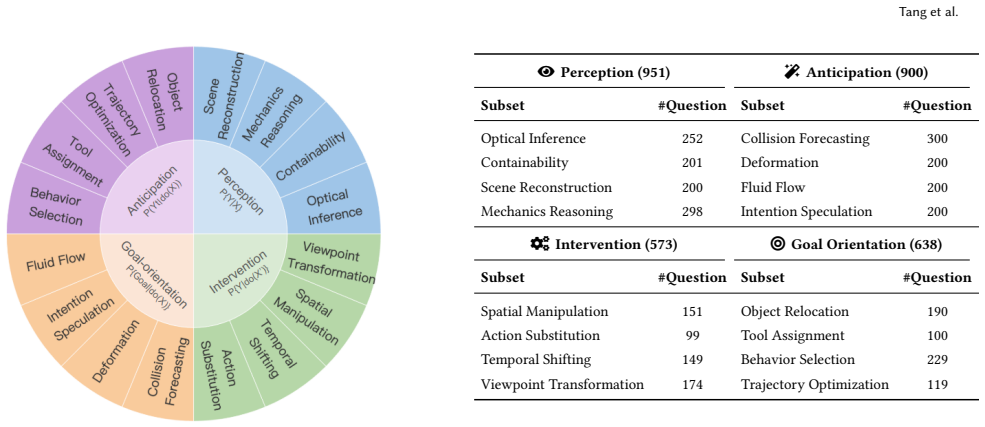
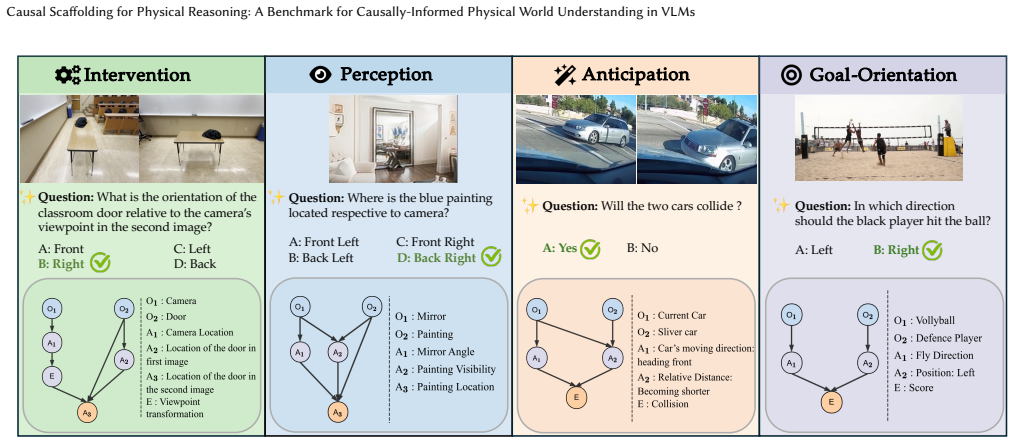
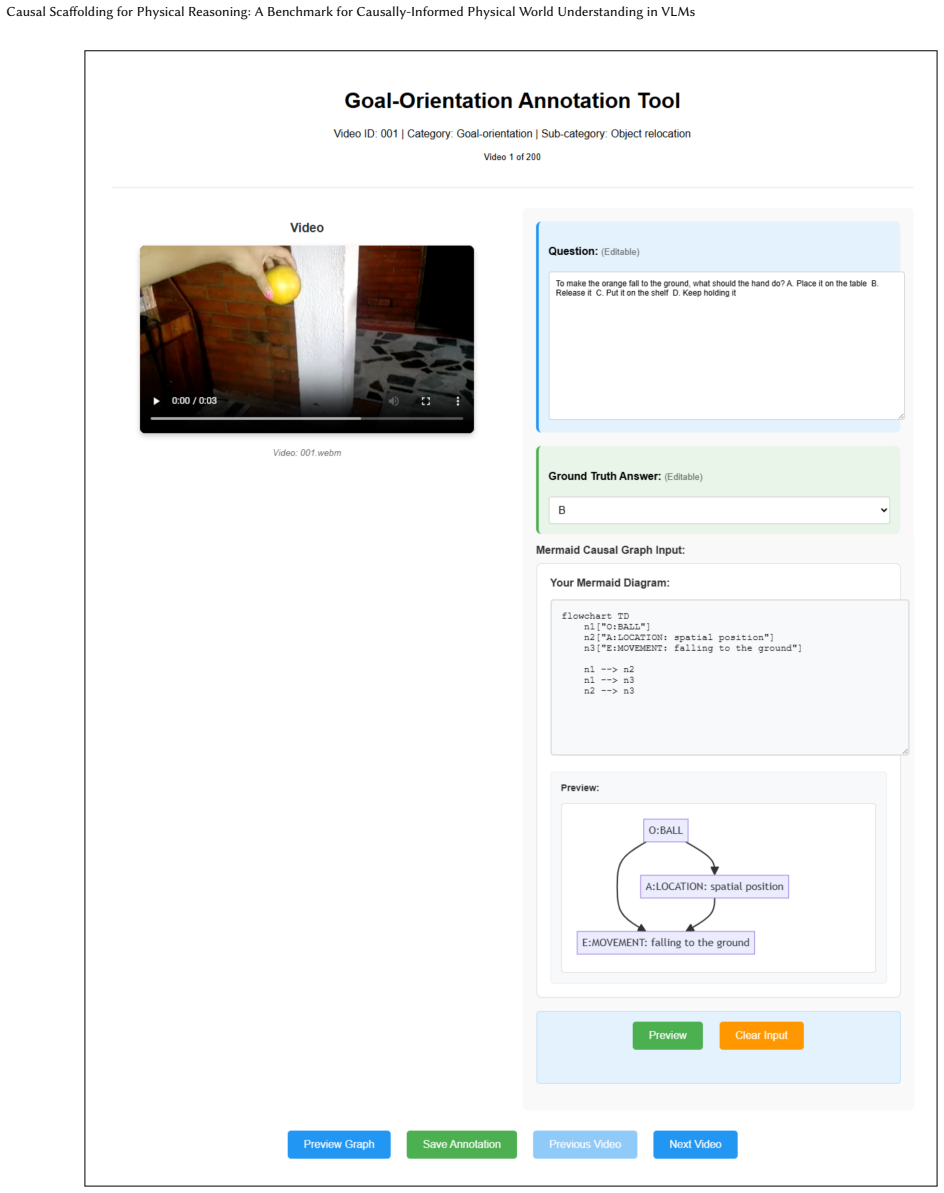
Understanding and reasoning about the physical world is the foundation of intelligent behavior, yet state-of-the-art vision-language models (VLMs) still fail at causal physical reasoning, often producing plausible but incorrect answers. To address this gap, we introduce CausalPhys, a benchmark of over 3,000 carefully curated video- and image-based questions spanning four domains: Perception, Anticipation, Intervention, and Goal Orientation. Each question is paired with an expert-annotated causal graph capturing object-attribute-event dependencies, enabling interpretable and fine-grained evaluation of causal understanding. Building on this, we formulate a causal-graph-grounded metric that quantitatively measures how well a model's chain-of-thought reasoning aligns with the correct causal relations, moving beyond answer-only accuracy and enabling systematic diagnosis of VLMs' causal reasoning failures. Using this metric, we conduct a comprehensive analysis of leading VLMs, revealing systematic gaps in capturing causal dependencies and underscoring the need for causality-aware learning. To address these limitations, we further propose Causal Rationale-informed Fine-Tuning (CRFT), which explicitly aligns VLM reasoning with causal structures. Extensive experiments demonstrate that CRFT substantially enhances both reasoning accuracy and interpretability across multiple model backbones. By unifying dataset curation, causal evaluation, and causality-informed learning, CausalPhys establishes a strong foundation for advancing modern VLMs toward causally grounded physical reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CausalPhys, a benchmark of over 3,000 video- and image-based questions spanning Perception, Anticipation, Intervention, and Goal Orientation domains. Each question is paired with an expert-annotated causal graph of object-attribute-event dependencies. The authors define a causal-graph-grounded metric to evaluate alignment between VLM chain-of-thought reasoning and these graphs, analyze systematic failures in leading VLMs, and propose Causal Rationale-informed Fine-Tuning (CRFT) that explicitly aligns reasoning with the causal structures, claiming substantial gains in accuracy and interpretability across model backbones.
Significance. If the expert annotations reliably represent true causal dependencies and the metric validly quantifies alignment, the work could provide a useful structured benchmark and training paradigm for improving causal physical reasoning in VLMs. The integration of dataset curation, fine-grained causal evaluation, and causality-informed fine-tuning is a coherent contribution that addresses a recognized limitation in current VLMs.
major comments (2)
- [Dataset Construction] The central claims rest on the expert-annotated causal graphs serving as objective ground truth for both the causal-graph-grounded metric and CRFT. The manuscript provides no information on annotation protocol, inter-annotator agreement, adjudication, or external validation (e.g., against intervention outcomes or physics simulators) in the dataset construction section. Without this, reported CRFT gains may reflect overfitting to annotation patterns rather than improved causal understanding.
- [Evaluation] §4 (Evaluation): The causal-graph-grounded metric is presented as enabling systematic diagnosis beyond answer accuracy, yet its validity depends entirely on the unverified annotations. If the graphs contain systematic biases, the metric and the claimed CRFT improvements on multiple backbones cannot be interpreted as evidence of causally grounded reasoning.
minor comments (2)
- [Abstract] The abstract states 'extensive experiments demonstrate that CRFT substantially enhances' performance but does not report concrete accuracy deltas, statistical significance, or ablation details; these should be summarized with numbers in the abstract or early results section.
- [Metric Definition] Notation for the causal-graph-grounded metric is introduced without an explicit equation or pseudocode in the main text; adding a formal definition would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that the absence of annotation protocol details, inter-annotator agreement, and validation information weakens the ability to interpret the causal graphs as ground truth and thus limits the strength of claims about the metric and CRFT. In the revised manuscript we will expand the relevant sections to address these points directly. We also note that accuracy improvements under CRFT are measured on held-out test sets using both graph-aligned and standard accuracy metrics, providing some independent support, but we accept that fuller documentation is required.
read point-by-point responses
-
Referee: [Dataset Construction] The central claims rest on the expert-annotated causal graphs serving as objective ground truth for both the causal-graph-grounded metric and CRFT. The manuscript provides no information on annotation protocol, inter-annotator agreement, adjudication, or external validation (e.g., against intervention outcomes or physics simulators) in the dataset construction section. Without this, reported CRFT gains may reflect overfitting to annotation patterns rather than improved causal understanding.
Authors: We acknowledge the omission. The current manuscript does not describe the annotation protocol, number of annotators, agreement statistics, adjudication procedure, or external validation steps. In revision we will add a dedicated subsection detailing: the expert guidelines and causal-graph template used; the annotator pool and training; inter-annotator agreement computed on an overlap set (including the specific metric); how disagreements were resolved; and any consistency checks performed against physics simulators or intervention outcomes where feasible. We will also report the size of the overlap set and any remaining disagreement rate. To address the overfitting concern we will add an ablation showing CRFT performance on causal structures not seen during fine-tuning and will clarify that accuracy gains are evaluated on standard answer correctness independent of the graphs. revision: yes
-
Referee: [Evaluation] §4 (Evaluation): The causal-graph-grounded metric is presented as enabling systematic diagnosis beyond answer accuracy, yet its validity depends entirely on the unverified annotations. If the graphs contain systematic biases, the metric and the claimed CRFT improvements on multiple backbones cannot be interpreted as evidence of causally grounded reasoning.
Authors: We agree that the metric's diagnostic value rests on annotation quality. The planned expansion of the dataset section will supply the missing reliability evidence. In addition, the revision will include a limitations paragraph explicitly discussing possible expert biases and the conditions under which the metric should be interpreted. We note that CRFT also produces measurable gains on conventional accuracy metrics across backbones; these results will be highlighted to provide triangulation. Nevertheless, without the annotation details the causal interpretation remains provisional, and the revision will make this dependence transparent. revision: yes
Circularity Check
No significant circularity; benchmark and metric are self-contained by design
full rationale
The paper introduces CausalPhys benchmark, expert-annotated causal graphs, a causal-graph-grounded metric, and CRFT fine-tuning without any equations, derivations, or self-referential definitions that reduce inputs to outputs by construction. The metric is explicitly formulated to measure alignment with the provided annotations as the core evaluation mechanism, not as a 'prediction' derived from fitted parameters. No self-citation load-bearing steps, uniqueness theorems, or ansatzes smuggled via citation appear in the abstract or described framework. Empirical experiments on multiple backbones provide independent content for the claims of improved accuracy and interpretability. The derivation chain is self-contained against the introduced benchmark and does not collapse to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, et al . 2024. Phi-4 Technical Report. arXiv:2412.08905 [cs.CL] https://arxiv.org/abs/2412.08905
Pith/arXiv arXiv 2024
-
[2]
Anthropic. 2025. Introducing Claude 4. https://www.anthropic.com/news/claude-
2025
-
[3]
Accessed: 2025-09-25
2025
-
[4]
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. 2015. Vqa: Visual question answering. In Proceedings of the IEEE international conference on computer vision. 2425–2433
2015
-
[5]
Samuel Ayman. [n. d.]. Cup Dataset [Kaggle]. Accessed: 2025-11-21
2025
-
[6]
Alisson Azzolini, Junjie Bai, Hannah Brandon, Jiaxin Cao, Prithvijit Chattopad- hyay, Huayu Chen, Jinju Chu, Yin Cui, Jenna Diamond, Yifan Ding, et al. 2025. Cosmos-reason1: From physical common sense to embodied reasoning.arXiv preprint arXiv:2503.15558(2025)
Pith/arXiv arXiv 2025
-
[7]
Daniel M Bear, Elias Wang, Damian Mrowca, Felix J Binder, Hsiao-Yu Fish Tung, RT Pramod, Cameron Holdaway, Sirui Tao, Kevin Smith, Fan-Yun Sun, et al. 2021. Physion: Evaluating physical prediction from vision in humans and machines. arXiv preprint arXiv:2106.08261(2021)
arXiv 2021
-
[8]
Susan Carey. 2000. The origin of concepts.Journal of Cognition and Development 1, 1 (2000), 37–41
2000
-
[9]
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexan- der Kirillov, and Sergey Zagoruyko. 2020. End-to-end object detection with transformers. InEuropean conference on computer vision. Springer, 213–229
2020
-
[10]
Meiqi Chen, Bo Peng, Yan Zhang, and Chaochao Lu. 2024. Cello: Causal evalua- tion of large vision-language models.arXiv preprint arXiv:2406.19131(2024)
arXiv 2024
-
[11]
Zhenfang Chen, Kexin Yi, Yunzhu Li, Mingyu Ding, Antonio Torralba, Joshua B Tenenbaum, and Chuang Gan. 2022. Comphy: Compositional physical reasoning of objects and events from videos.arXiv preprint arXiv:2205.01089(2022)
arXiv 2022
-
[12]
Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Guizilini, and Yue Wang
-
[13]
Physbench: Benchmarking and enhancing vision-language models for physical world understanding.arXiv preprint arXiv:2501.16411(2025)
arXiv 2025
-
[14]
Zhao, Yanping Huang, Andrew M
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Al- bert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Y. Zhao, Yanp...
2024
-
[15]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, et al. 2025. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities. arXiv:2507.06261 [cs.CL] https: //arxiv.org/abs/2507.06261
Pith/arXiv arXiv 2025
-
[16]
Yutao Cui, Chenkai Zeng, Xiaoyu Zhao, Yichun Yang, Gangshan Wu, and Limin Wang. 2023. SportsMOT: A Large Multi-Object Tracking Dataset in Multiple Sports Scenes. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023. IEEE, 9887–9897. doi:10.1109/ICCV51070. 2023.00910
-
[17]
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. 2021. The EPIC-KITCHENS Dataset: Collection, Challenges and Baselines.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)43, 11 (2021), 4125–4141. doi:10.1...
-
[18]
Zhuobai Dong, Junchao Yi, Ziyuan Zheng, Haochen Han, Xiangxi Zheng, Alex Jin- peng Wang, Fangming Liu, and Linjie Li. 2025. Seeing is Not Reasoning: MVP- Bench for Graph-based Evaluation of Multi-path Visual Physical CoT.arXiv preprint arXiv:2505.24182(2025)
arXiv 2025
-
[19]
Aaron Foss, Chloe Evans, Sasha Mitts, Koustuv Sinha, Ammar Rizvi, and Justine T Kao. 2025. CausalVQA: A Physically Grounded Causal Reasoning Benchmark for Video Models.arXiv preprint arXiv:2506.09943(2025)
arXiv 2025
-
[20]
Jiarun Fu, Lizhong Ding, Hao Li, Pengqi Li, Qiuning Wei, and Xu Chen. 2025. Un- veiling and causalizing cot: A causal pespective.arXiv preprint arXiv:2502.18239 (2025)
arXiv 2025
-
[21]
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fründ, Peter Yianilos, Moritz Mueller-Freitag, Florian Hoppe, Christian Thurau, Ingo Bax, and Roland Memisevic. 2017. The "Something Something" Video Database for Learning and Evaluating Visual Common Sense. InIEEE International C...
-
[22]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI] https://arxiv.org/abs/2407.21783
Pith/arXiv arXiv 2024
-
[23]
Kristen Grauman, Andrew Westbury, Eugene Byrne, Vincent Cartillier, and al Zachary Chavis et. 2025. Ego4D: Around the World in 3,600 Hours of Egocentric Video.IEEE Trans. Pattern Anal. Mach. Intell.47, 11 (2025), 9468–9509. doi:10. 1109/TPAMI.2024.3381075
arXiv 2025
-
[24]
Agrim Gupta, Silvio Savarese, Surya Ganguli, and Li Fei-Fei. 2021. Embodied intelligence via learning and evolution.Nature communications12, 1 (2021), 5721
2021
-
[25]
Victor-Louis De Gusseme, Thomas Lips, Remko Proesmans, Julius Hietala, Giwan Lee, Jiyoung Choi, Jeongil Choi, Geon Kim, and al Phayuth Yonrith et. 2025. A Dataset and Benchmark for Robotic Cloth Unfolding Grasp Selection: The ICRA 2024 Cloth Competition. arXiv:2508.16749 [cs.RO] https://arxiv.org/abs/2508. 16749
arXiv 2025
-
[26]
Yunzhuo Hao, Jiawei Gu, Huichen Will Wang, Linjie Li, Zhengyuan Yang, Lijuan Wang, and Yu Cheng. 2025. Can mllms reason in multimodality? emma: An enhanced multimodal reasoning benchmark.arXiv preprint arXiv:2501.05444 (2025)
arXiv 2025
-
[27]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al . 2024. Olympiad- bench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems.arXiv preprint arXiv:2402.14008(2024)
Pith/arXiv arXiv 2024
-
[28]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
Pith/arXiv arXiv 2024
-
[29]
Dongzhi Jiang, Renrui Zhang, Ziyu Guo, Yanwei Li, Yu Qi, Xinyan Chen, Liuhui Wang, Jianhan Jin, Claire Guo, Shen Yan, Bo Zhang, Chaoyou Fu, Peng Gao, and Hongsheng Li. 2025. MME-CoT: Benchmarking Chain-of-Thought in Large Multimodal Models for Reasoning Quality, Robustness, and Efficiency.CoRR abs/2502.09621 (2025). arXiv:2502.09621 doi:10.48550/ARXIV.2502.09621
-
[30]
Zhihuan Jiang, Zhen Yang, Jinhao Chen, Zhengxiao Du, Weihan Wang, Bin Xu, and Jie Tang. 2024. Visscience: An extensive benchmark for evaluating k12 educational multi-modal scientific reasoning.arXiv preprint arXiv:2409.13730 (2024). Tang et al
arXiv 2024
-
[31]
Zhijing Jin, Yuen Chen, Felix Leeb, Luigi Gresele, Ojasv Kamal, Zhiheng Lyu, Kevin Blin, Fernando Gonzalez Adauto, Max Kleiman-Weiner, Mrinmaya Sachan, et al. 2023. Cladder: Assessing causal reasoning in language models.Advances in Neural Information Processing Systems36 (2023), 31038–31065
2023
-
[32]
Thomas Jiralerspong, Xiaoyin Chen, Yash More, Vedant Shah, and Yoshua Bengio
-
[33]
Efficient causal graph discovery using large language models.arXiv preprint arXiv:2402.01207(2024)
Pith/arXiv arXiv 2024
-
[34]
Kantine. [n. d.]. DOMOTIC PouringCoffee Expert Dataset [Hugging Face]. Ac- cessed: 2025-11-20
2025
-
[35]
Aneesh Komanduri, Karuna Bhaila, and Xintao Wu. 2025. CausalVLBench: Benchmarking Visual Causal Reasoning in Large Vision-Language Models.arXiv preprint arXiv:2506.11034(2025)
arXiv 2025
-
[36]
Ville Kuosmanen. [n. d.]. AGILEX Clean Pour Water Dataset [Hugging Face]. Accessed: 2025-11-20
2025
-
[37]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730–19742
2023
-
[38]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning. PMLR, 12888–12900
2022
-
[39]
Jianing Li, Xi Nan, Ming Lu, Li Du, and Shanghang Zhang. 2024. Proximity qa: Unleashing the power of multi-modal large language models for spatial proximity analysis.arXiv preprint arXiv:2401.17862(2024)
arXiv 2024
-
[40]
Zhiyuan Li, Heng Wang, Dongnan Liu, Chaoyi Zhang, Ao Ma, Jieting Long, and Weidong Cai. 2025. Multimodal Causal Reasoning Benchmark: Challenging Multimodal Large Language Models to Discern Causal Links Across Modalities. InFindings of the Association for Computational Linguistics: ACL 2025. Association for Computational Linguistics, Vienna, Austria, 5509–...
-
[41]
Disheng Liu, Yiran Qiao, Wuche Liu, Yiren Lu, Yunlai Zhou, Tuo Liang, Yu Yin, and Jing Ma. 2025. Causal3d: A comprehensive benchmark for causal learning from visual data.arXiv preprint arXiv:2503.04852(2025)
arXiv 2025
-
[42]
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022. Learn to explain: Multimodal reasoning via thought chains for science question answering.Ad- vances in Neural Information Processing Systems35 (2022), 2507–2521
2022
-
[43]
Michael McCloskey, Allyson Washburn, and Linda Felch. 1983. Intuitive physics: the straight-down belief and its origin.Journal of Experimental Psychology: Learning, Memory, and Cognition9, 4 (1983), 636
1983
-
[44]
Moura, Shizhan Zhu, and Orly Zvitia
Daniel C. Moura, Shizhan Zhu, and Orly Zvitia. 2025. Nexar Dashcam Collision Prediction Dataset and Challenge. InIEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2025, Nashville, TN, USA, June 11-15, 2025. Computer Vision Foundation / IEEE, 2583–2591. https://openaccess.thecvf.com/content/CVPR2025W/WAD/html/Moura_ N...
2025
-
[45]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, and et al. 2024. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL] https://arxiv.org/abs/2303.08774
Pith/arXiv arXiv 2024
-
[46]
2009.Causality
Judea Pearl. 2009.Causality. Cambridge university press
2009
-
[47]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, et al. 2025. Qwen2.5 Technical Report. arXiv:2412.15115 [cs.CL] https://arxiv.org/abs/2412.15115
Pith/arXiv arXiv 2025
-
[48]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[49]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763
-
[50]
Goutham Rajendran, Simon Buchholz, Bryon Aragam, Bernhard Schölkopf, and Pradeep Ravikumar. 2024. Learning interpretable concepts: Unifying causal representation learning and foundation models.arXiv preprint arXiv:2402.09236 (2024)
arXiv 2024
-
[51]
Fatemeh Shiri, Xiao-Yu Guo, Mona Golestan Far, Xin Yu, Gholamreza Haffari, and Yuan-Fang Li. 2024. An empirical analysis on spatial reasoning capabilities of large multimodal models.arXiv preprint arXiv:2411.06048(2024)
arXiv 2024
-
[52]
Sanjana Srivastava, Chengshu Li, Michael Lingelbach, Roberto Martín-Martín, Fei Xia, Kent Elliott Vainio, Zheng Lian, Cem Gokmen, Shyamal Buch, Karen Liu, et al. 2022. Behavior: Benchmark for everyday household activities in virtual, interactive, and ecological environments. InConference on robot learning. PMLR, 477–490
2022
-
[53]
Mistral AI Team. 2025. Mistral Small 3: Apache 2.0, 81% MMLU, 150 tokens/s. https://mistral.ai/news/mistral-small-3. Accessed: 2025-09-25
2025
-
[54]
Hsiao-Yu Tung, Mingyu Ding, Zhenfang Chen, Daniel Bear, Chuang Gan, Josh Tenenbaum, Dan Yamins, Judith Fan, and Kevin Smith. 2023. Physion++: Evalu- ating physical scene understanding that requires online inference of different physical properties.Advances in Neural Information Processing Systems36 (2023), 67048–67068
2023
-
[55]
Casper Van Engelenburg, Fatemeh Mostafavi, Emanuel Kuhn, Yuntae Jeon, Michael Franzen, Matthias Standfest, Jan van Gemert, and Seyran Khademi
-
[56]
InEuropean Conference on Computer Vision
MSD: A Benchmark Dataset for Floor Plan Generation of Building Com- plexes. InEuropean Conference on Computer Vision. Springer, 60–75
-
[57]
Tai Wang, Xiaohan Mao, Chenming Zhu, Runsen Xu, Ruiyuan Lyu, Peisen Li, Xiao Chen, Wenwei Zhang, Kai Chen, Tianfan Xue, et al. 2024. Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 19757– 19767
2024
-
[58]
Qi Wu, Damien Teney, Peng Wang, Chunhua Shen, Anthony Dick, and Anton Van Den Hengel. 2017. Visual question answering: A survey of methods and datasets.Computer Vision and Image Understanding163 (2017), 21–40
2017
-
[59]
An Yang, Anfeng Li, Baosong Yang, et al . 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https://arxiv.org/abs/2505.09388
Pith/arXiv arXiv 2025
-
[60]
An Yang, Baosong Yang, Binyuan Hui, et al . 2024. Qwen2 Technical Report. arXiv:2407.10671 [cs.CL] https://arxiv.org/abs/2407.10671
Pith/arXiv arXiv 2024
-
[61]
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. 2025. Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference. 10632–10643
2025
-
[62]
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B Tenenbaum. 2019. Clevrer: Collision events for video representation and reasoning.arXiv preprint arXiv:1910.01442(2019)
Pith/arXiv arXiv 2019
-
[63]
Baiqiao Yin, Qineng Wang, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, Saining Xie, Manling Li, Jiajun Wu, and Li Fei-Fei. 2025. Spatial Mental Modeling from Limited Views.CoRRabs/2506.21458 (2025). arXiv:2506.21458 doi:10.48550/ ARXIV.2506.21458
arXiv 2025
-
[64]
Xinyu Zhang, Yuxuan Dong, Yanrui Wu, Jiaxing Huang, Chengyou Jia, Basura Fernando, Mike Zheng Shou, Lingling Zhang, and Jun Liu. 2025. Physreason: A comprehensive benchmark towards physics-based reasoning.arXiv preprint arXiv:2502.12054(2025)
arXiv 2025
-
[65]
Jinguo Zhu, Weiyun Wang, Zhe Chen, et al . 2025. InternVL3: Exploring Ad- vanced Training and Test-Time Recipes for Open-Source Multimodal Models. arXiv:2504.10479 [cs.CV] https://arxiv.org/abs/2504.10479
Pith/arXiv arXiv 2025
-
[66]
Mingye Zhu, Yi Liu, Zheren Fu, Quan Wang, and Yongdong Zhang. 2025. In- Token Rationality Optimization: Towards Accurate and Concise LLM Reasoning via Self-Feedback. arXiv:2511.09865 [cs.CL] https://arxiv.org/abs/2511.09865
arXiv 2025
-
[67]
Mingwei Zhu, Leigang Sha, Yu Shu, Kangjia Zhao, Tiancheng Zhao, and Jianwei Yin. 2023. Benchmarking sequential visual input reasoning and prediction in multimodal large language models.arXiv preprint arXiv:2310.13473(2023). Causal Scaffolding for Physical Reasoning: A Benchmark for Causally-Informed Physical World Understanding in VLMs Supplementary Mater...
arXiv 2023
-
[68]
Generate a clear, step-by-step rationale (max 8 sentences) wrapped in<rationale>...</rationale>
-
[69]
The agent is provided with the question, causal graph,visual input and ground-truth answer
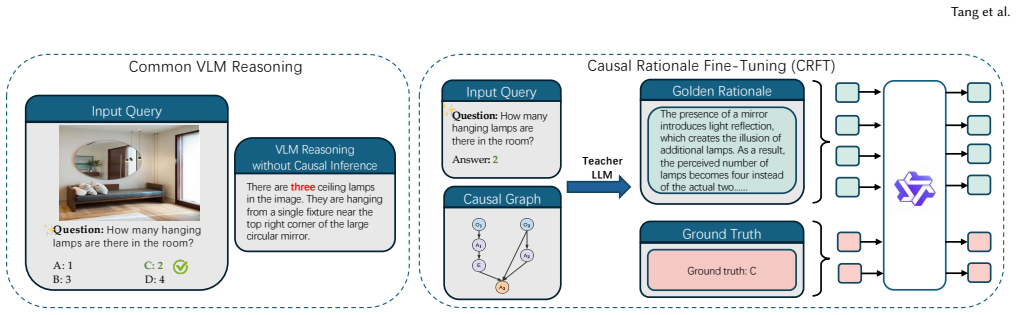
Your answer must be in EXACTLY ONE CAPITAL LETTER: A, B, C, or D wrapped in<result>...</result> C.2 Gold Rationale Generation Based on the ground-truth causal graph, the teacher LLM is required to generate a gold rationale that reflects the reasoning implied by the nodes and edges. The agent is provided with the question, causal graph,visual input and gro...
-
[70]
Write an objective, answer-focused rationale in natural language
-
[71]
Treat the supporting information as reference only (do not describe it)
-
[72]
Write ONE coherent paragraph (max 8 sentences) that flows naturally
-
[73]
Include relevant elements from the reference only when needed for reasoning (do not enumerate them)
-
[74]
Follow the correct logical order: causes must appear before their effects
-
[75]
If an element has a description, state it clearly and exactly as provided
-
[76]
entity",
Use natural, everyday language (avoid terms like "entity", "relation", "graph", "structure")
-
[77]
Ensure proper grammar and spelling
-
[78]
Make the explanation easy to understand and self-contained
-
[79]
kicker” for “Fighter
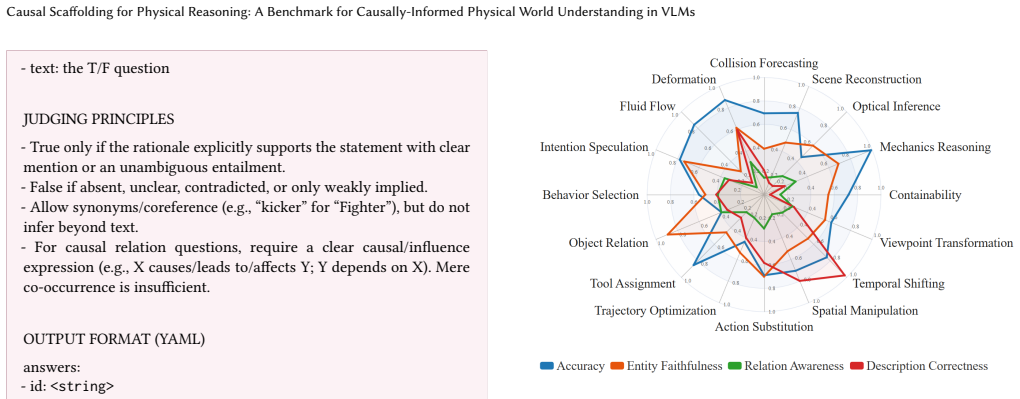
Present the reasoning as a logical analysis of the situation ## Output format - Single paragraph only - No bullet points, lists, or special formatting - Plain English text - Complete explanation that follows the logical reasoning sequence ## Important The supporting information (entities, descriptions, relations) is for reference only. Do NOT describe or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.