Multi-task Learning is Not Enough: Representational Entanglement in Dual-output Second Language Speech Recognition
Pith reviewed 2026-06-28 01:29 UTC · model grok-4.3
The pith
Multi-task learning improves meaning but degrades surface transcription in dual-output L2 speech recognition due to encoder entanglement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
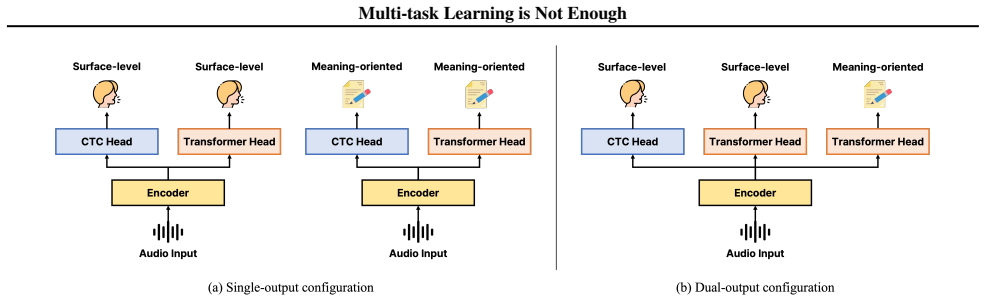
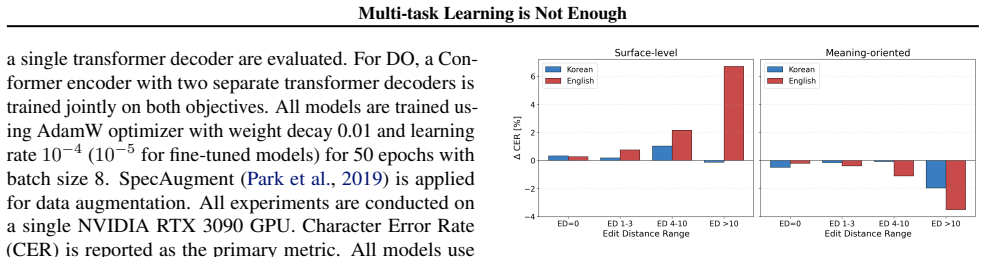
In dual-output second language automatic speech recognition, multi-task learning with shared encoders leads to representational entanglement that improves meaning transcription but degrades surface pronunciation transcription. The effect is stronger in English than in Korean, scaling with Levenshtein distance between surface and meaning forms. Encoder representations for the two tasks become nearly identical in English while remaining distinct in Korean, and decoders show different adaptation patterns.
What carries the argument
Encoder-level representational entanglement between surface transcription and meaning tasks in a multi-task learning setup for L2 ASR.
If this is right
- MTL frameworks must be redesigned to mitigate encoder entanglement to preserve surface transcription quality.
- Language pairs with high surface-meaning divergence will see greater benefits from entanglement-reducing techniques.
- Meaning decoders can adapt to entangled inputs while surface decoders cannot, suggesting task-specific architectural adjustments.
- Cross-task decoder analysis reveals opportunities for hybrid models that separate encoder representations.
Where Pith is reading between the lines
- Entanglement may be a general issue in multi-task learning for tasks with orthogonal objectives, such as in other speech or translation systems.
- Techniques like task-specific adapters or orthogonal regularization could be tested to disentangle representations without full model changes.
- The correlation with Levenshtein distance offers a way to select training data or predict failure cases in new L2 pairs.
- Implications extend to real-world L2 tools where accurate pronunciation feedback is critical alongside meaning.
Load-bearing premise
The degradation in surface transcription performance results from encoder-level representational entanglement rather than other training dynamics or architectural choices.
What would settle it
Training a model with explicit disentanglement mechanisms in the encoder and observing whether the surface transcription degradation is eliminated or reduced compared to standard MTL.
Figures
read the original abstract
Second-language (L2) speech recognition often requires transcriptions of pronunciations and intended meanings. Multi-task learning (MTL) is a natural approach because it assumes that shared representations benefit both outputs. However, this paper shows that this assumption does not hold across Korean and English. MTL improves meaning but degrades surface transcription, especially in English, where the degradation scales with surface-meaning divergence measured by Levenshtein edit distance. Encoder analysis links these patterns to encoder-level entanglement, with Korean preserving distinct task representations while English produces nearly identical ones. Cross-task decoder analysis shows that the meaning dual-output decoder adapts with a unique representation, while the surface dual-output decoder remains constrained by the encoder. These findings motivate the design of MTL frameworks that mitigate encoder-level entanglement to reduce surface degradation in dual-output L2 automatic speech recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines multi-task learning (MTL) for dual-output L2 ASR, where models must produce both surface (pronunciation) transcriptions and meaning transcriptions. It reports that MTL improves meaning output but degrades surface transcription accuracy, with the degradation in English scaling with surface-meaning divergence as measured by Levenshtein edit distance. Encoder analyses show that Korean maintains distinct task representations while English yields nearly identical ones, which the authors link to the observed surface degradation. Cross-task decoder analyses indicate that the meaning decoder develops a unique representation while the surface decoder remains constrained by the shared encoder. The work concludes that standard MTL is insufficient and motivates new frameworks that mitigate encoder-level entanglement.
Significance. If the reported patterns and mechanism hold, the result is significant for ASR and multi-task learning: it provides concrete evidence of negative transfer in dual-output settings and identifies encoder entanglement as a key failure mode that varies by language. The scaling with Levenshtein distance and the Korean/English contrast offer testable predictions. The decoder analysis adds nuance by localizing the constraint. These empirical observations could guide development of disentanglement techniques in speech models.
major comments (1)
- [Encoder analysis] Encoder analysis section: the claim that encoder-level representational entanglement is the mechanism driving MTL-induced surface WER degradation rests on correlational evidence (near-identical task vectors for English vs. distinct vectors for Korean, plus scaling with Levenshtein distance). No intervention experiment is described that selectively alters encoder disentanglement (e.g., via an auxiliary loss or architectural change) while holding loss weighting, optimizer, and decoder capacity fixed; therefore the causal direction remains unestablished and alternative explanations such as joint optimization dynamics cannot be ruled out.
minor comments (1)
- The abstract and results sections would benefit from explicit reporting of the number of runs, standard deviations, and statistical tests for the reported WER differences and Levenshtein correlations.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the encoder analysis. We agree that our evidence is correlational and will revise the manuscript to clarify the hypothesized nature of the mechanism while preserving the empirical observations.
read point-by-point responses
-
Referee: [Encoder analysis] Encoder analysis section: the claim that encoder-level representational entanglement is the mechanism driving MTL-induced surface WER degradation rests on correlational evidence (near-identical task vectors for English vs. distinct vectors for Korean, plus scaling with Levenshtein distance). No intervention experiment is described that selectively alters encoder disentanglement (e.g., via an auxiliary loss or architectural change) while holding loss weighting, optimizer, and decoder capacity fixed; therefore the causal direction remains unestablished and alternative explanations such as joint optimization dynamics cannot be ruled out.
Authors: We agree that the encoder analysis relies on correlational patterns: the near-identical task vectors in English, distinct vectors in Korean, and the scaling of degradation with Levenshtein distance. These observations are consistent with encoder-level entanglement as a contributing factor but do not constitute a causal intervention that isolates disentanglement while holding loss weighting, optimizer, and decoder capacity fixed. Alternative accounts, including joint optimization dynamics, therefore remain viable. In the revised manuscript we will (1) replace causal phrasing such as "the mechanism driving" with "a hypothesized mechanism supported by" in the encoder analysis and conclusion sections, (2) add an explicit limitations paragraph noting the absence of targeted disentanglement interventions, and (3) outline future experiments that could test causality under controlled conditions. These changes will be made without altering the reported empirical results. revision: yes
Circularity Check
No significant circularity; empirical claims rest on observations
full rationale
The paper presents an empirical study of MTL effects on dual-output L2 ASR, reporting performance differences, scaling with Levenshtein distance, and encoder representation similarities via analysis. No derivation chain, equations, or predictions reduce to fitted inputs by construction, nor do self-citations bear load on a uniqueness theorem or ansatz. Central claims are associative observations from experiments rather than self-referential definitions or renamings of known results. The derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International conference on machine learning , pages=
Similarity of neural network representations revisited , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[2]
Murat Saraçlar and Sanjeev Khudanpur , abstract =. Pronunciation change in conversational speech and its implications for automatic speech recognition , journal =. 2004 , issn =. doi:https://doi.org/10.1016/j.csl.2003.09.005 , url =
-
[3]
Journal of Phonetics , volume=
An introduction to reduced pronunciation variants , author=. Journal of Phonetics , volume=. 2011 , publisher=
2011
-
[4]
Frontiers in Communication , volume =
On the Difficulty of Defining ``Difficult'' in Second-Language Vowel Acquisition , author =. Frontiers in Communication , volume =. 2021 , doi =
2021
-
[5]
Speech Communication , volume =
An Overview of Spoken Language Technology for Education , author =. Speech Communication , volume =. 2009 , doi =
2009
-
[6]
An Overview of Multi-Task Learning in Deep Neural Networks
An overview of multi-task learning in deep neural networks , author=. arXiv preprint arXiv:1706.05098 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
2017 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=
Joint CTC-attention based end-to-end speech recognition using multi-task learning , author=. 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=. 2017 , organization=
2017
-
[8]
IEEE Journal of Selected Topics in Signal Processing , volume=
Hybrid CTC/attention architecture for end-to-end speech recognition , author=. IEEE Journal of Selected Topics in Signal Processing , volume=. 2017 , publisher=
2017
-
[9]
arXiv preprint arXiv:2104.02724 , year=
Relaxing the conditional independence assumption of CTC-based ASR by conditioning on intermediate predictions , author=. arXiv preprint arXiv:2104.02724 , year=
-
[10]
Proceedings of the 28th International Conference on Computational Linguistics , pages=
Dual-decoder transformer for joint automatic speech recognition and multilingual speech translation , author=. Proceedings of the 28th International Conference on Computational Linguistics , pages=
-
[11]
Unifying Diarization, Separation, and ASR with Multi-Speaker Encoder
Unifying diarization, separation, and ASR with multi-speaker encoder , author=. arXiv preprint arXiv:2508.20474 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Robust Speech Recognition via Large-Scale Weak Supervision
Robust Speech Recognition via Large-Scale Weak Supervision , url =. 2022 , bdsk-url-1 =. arXiv , author =:2212.04356 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Park and William Chan and Yu Zhang and Chung-Cheng Chiu and Barret Zoph and Ekin D
Park, Daniel S. and Chan, William and Zhang, Yu and Chiu, Chung-Cheng and Zoph, Barret and Cubuk, Ekin D. and Le, Quoc V. , booktitle =. SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition , url =. 2019 , bdsk-url-1 =. doi:10.21437/interspeech.2019-2680 , month = sep, pages =
-
[14]
doi:10.21437/Interspeech.2020-3015 , issn =
Gulati, Anmol and Qin, James and Chiu, Chung-Cheng and Parmar, Niki and Zhang, Yu and Yu, Jiahui and Han, Wei and Wang, Shibo and Zhang, Zhengdong and Wu, Yonghui and Pang, Ruoming , booktitle =. Conformer: Convolution-augmented Transformer for Speech Recognition , url =. 2020 , bdsk-url-1 =. doi:10.21437/Interspeech.2020-3015 , pages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.