Diff-CA: Separating Common and Salient Factors with Diffusion Models
Pith reviewed 2026-06-28 01:45 UTC · model grok-4.3
The pith
Diffusion models separate common and salient factors in images via identifiable additive factorization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
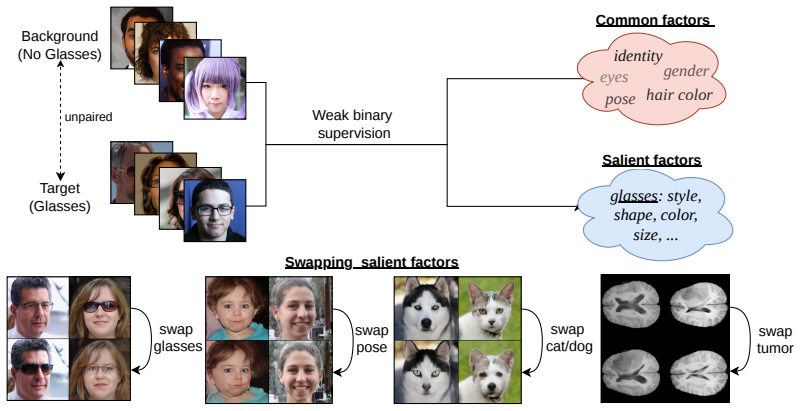
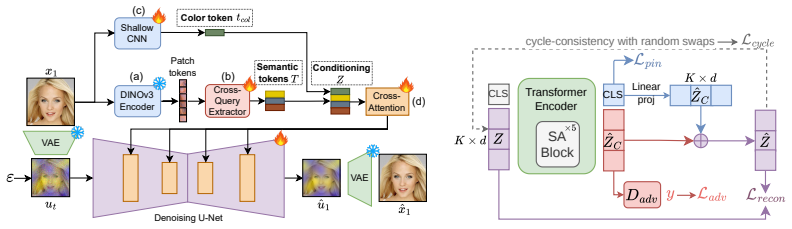
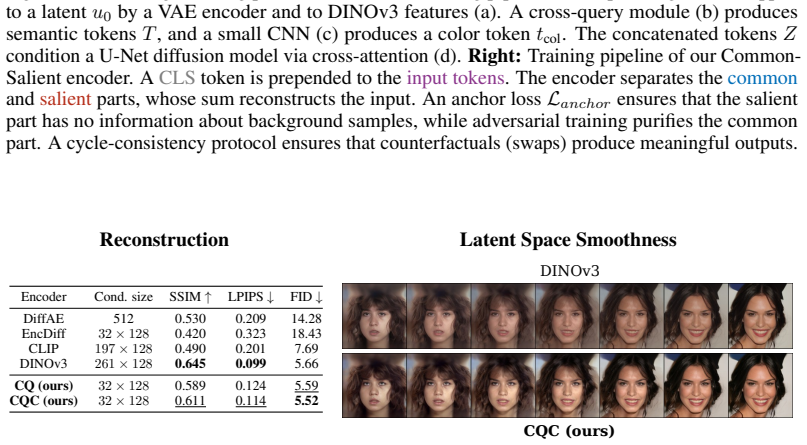
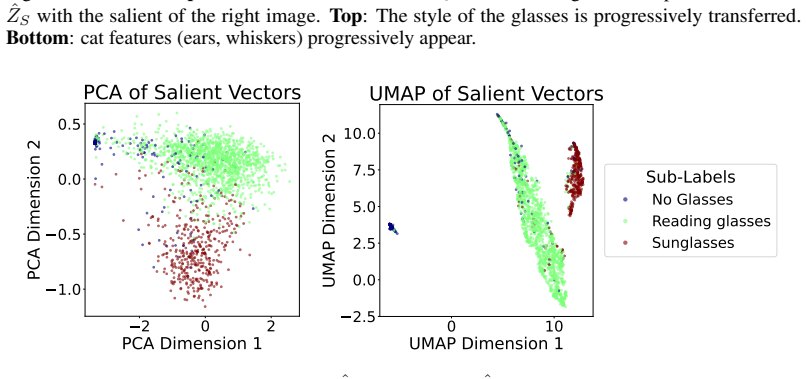
By training a prompt-free image-conditioned diffusion model and decomposing its conditioning into common and salient factors using weak supervision, contrastive decomposition is performed while preserving generation quality. The additive contrastive factorization commonly assumed in prior work is proven identifiable under mild conditions. This factorization enables targeted operations such as swapping or interpolating only the salient factor.
What carries the argument
Conditioning decomposition in an image-conditioned diffusion model that isolates common and salient factors, with the identifiability of the additive contrastive factorization.
If this is right
- High-fidelity image generation and edition remain possible during contrastive decomposition.
- Targeted edits are achieved by swapping or interpolating only the salient factor.
- The approach extends contrastive analysis to domains where prior generative methods were limited by image quality.
Where Pith is reading between the lines
- The identifiability result may support similar factorizations in conditioning mechanisms of other generative models.
- The weak supervision step for decomposition could be tested with stronger or weaker signals to measure robustness.
- The framework suggests applications in editing tasks that require changing only distribution-specific attributes while preserving shared structure.
Load-bearing premise
The data must follow an additive contrastive factorization model and the mild conditions for identifiability must hold in the image domains tested.
What would settle it
A controlled pair of image distributions where multiple distinct decompositions into common and salient factors produce identical observed data would falsify the identifiability claim.
Figures




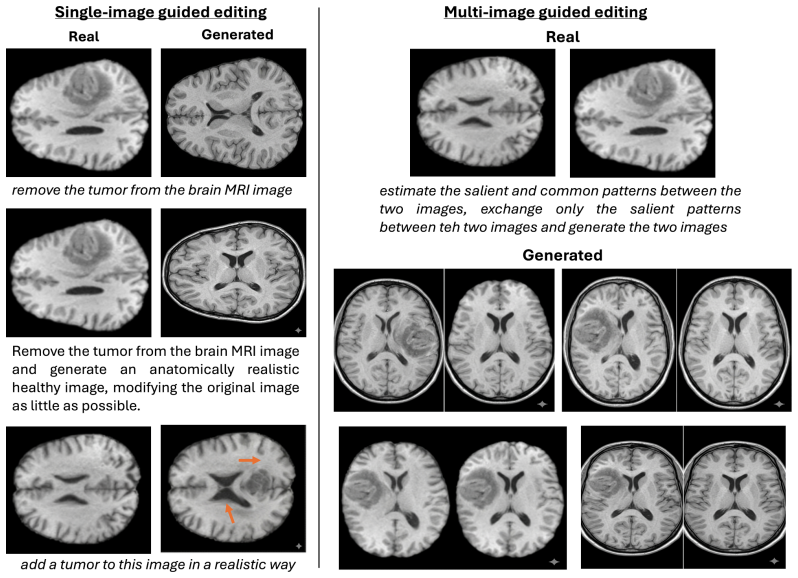

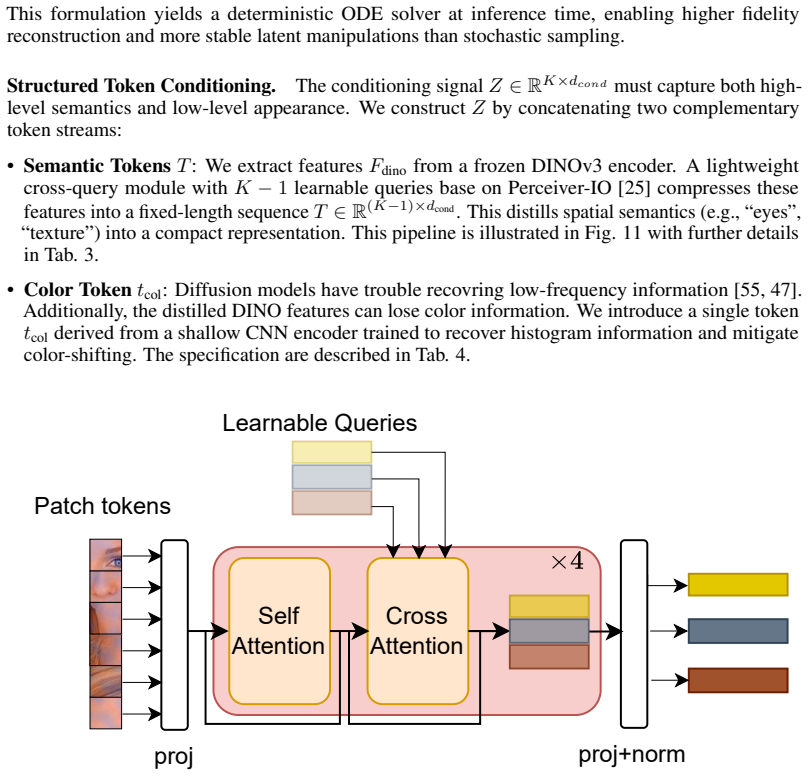


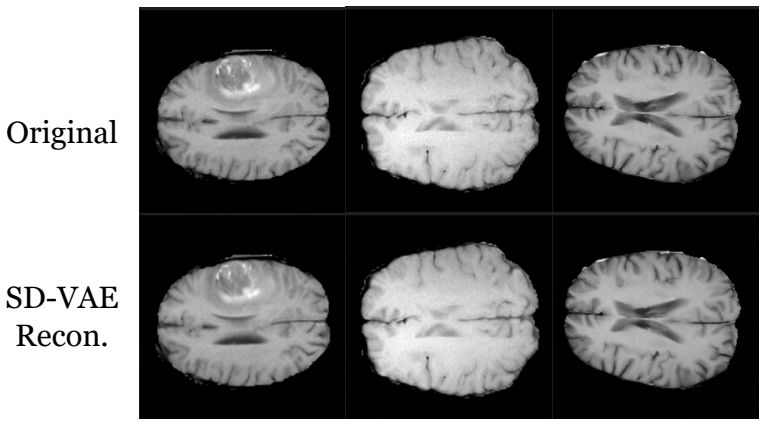







read the original abstract
Contrastive Analysis aims to separate factors that are common between two data distributions from those that are salient to only one of them. Existing contrastive methods are based on generative models (e.g., VAEs or GANs) that often suffer from limited reconstruction and image quality, which hampers effective latent factor separation and limits their applicability to high-fidelity image generation and edition. We propose a novel conditioning framework for diffusion models that enables contrastive decomposition without compromising generation quality. We first train a prompt-free, image-conditioned diffusion model, and then learn to decompose the conditioning into a common and a salient factor, using weak supervision. We prove that the additive contrastive factorization, commonly assumed in prior work, is identifiable under mild conditions. This factorization enables targeted operations by swapping or interpolating only the salient factor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Diff-CA, a conditioning framework for diffusion models to perform contrastive analysis by separating common factors (shared across distributions) from salient factors (unique to one). It first trains a prompt-free image-conditioned diffusion model, then decomposes the conditioning into common and salient factors via weak supervision. The central claim is a proof that the additive contrastive factorization (commonly assumed in prior work) is identifiable under mild conditions, enabling targeted editing operations such as swapping or interpolating only the salient factor while preserving generation quality.
Significance. If the identifiability result holds under the stated mild conditions and the weak supervision details are made explicit with supporting experiments, the work would meaningfully advance contrastive analysis by integrating it with high-fidelity diffusion models, overcoming the reconstruction and quality limitations of prior VAE- and GAN-based approaches.
major comments (2)
- [Abstract] Abstract: the claim that 'we prove that the additive contrastive factorization... is identifiable under mild conditions' is presented without the derivation, explicit statement of the mild conditions, error analysis, or experimental validation that those conditions hold in the tested image domains; this renders the central claim unverifiable from the provided text.
- The weak supervision procedure for decomposing the conditioning into common and salient factors is described at a high level but the precise form of supervision, loss terms, and how it interacts with the diffusion training objective are unspecified, which is load-bearing for reproducibility and for confirming that the factorization remains identifiable in practice.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below, clarifying the location of the proof and details in the manuscript while committing to revisions for improved clarity and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'we prove that the additive contrastive factorization... is identifiable under mild conditions' is presented without the derivation, explicit statement of the mild conditions, error analysis, or experimental validation that those conditions hold in the tested image domains; this renders the central claim unverifiable from the provided text.
Authors: The full derivation of the identifiability result, including the explicit mild conditions (additive factorization with weak supervision on paired distributions), is provided in Section 3, along with the complete proof. Experimental validation that the conditions hold for the tested image domains, including quantitative checks, appears in Section 4. We agree the abstract is too concise to include these elements. In revision we will expand the abstract to state the mild conditions explicitly, while keeping error analysis in the experiments section due to space limits. revision: yes
-
Referee: The weak supervision procedure for decomposing the conditioning into common and salient factors is described at a high level but the precise form of supervision, loss terms, and how it interacts with the diffusion training objective are unspecified, which is load-bearing for reproducibility and for confirming that the factorization remains identifiable in practice.
Authors: We agree the current description is high-level. Section 3.2 specifies the weak supervision (using weak labels on paired samples indicating shared vs. unique factors), the exact loss terms (contrastive decomposition losses added to the diffusion denoising objective), and their interaction. To improve reproducibility we will revise Section 3.2 to include the full loss equations, hyperparameter settings, and additional pseudocode showing how the decomposition is trained jointly with the diffusion model. revision: yes
Circularity Check
No significant circularity: identifiability result presented as independent proof
full rationale
The paper's central claim is a mathematical proof that the additive contrastive factorization is identifiable under mild conditions. This is described as independent of the training procedure and not derived from fitted parameters or self-citations. No load-bearing steps reduce by construction to inputs, self-definitions, or author-specific uniqueness theorems. The derivation is self-contained as a standard identifiability argument.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Data follows an additive contrastive factorization into common and salient factors
Reference graph
Works this paper leans on
-
[1]
Contrastive Variational Autoencoder Enhances Salient Features
Abubakar Abid and James Zou. Contrastive variational autoencoder enhances salient features.arXiv preprint arXiv:1902.04601, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[2]
Exploring patterns enriched in a dataset with contrastive principal component analysis.Nature communications, 9(1):2134, 2018
Abubakar Abid, Martin J Zhang, Vivek K Bagaria, and James Zou. Exploring patterns enriched in a dataset with contrastive principal component analysis.Nature communications, 9(1):2134, 2018
2018
-
[3]
Domain intersection and domain difference
Sagie Benaim, Michael Khaitov, Tomer Galanti, and Lior Wolf. Domain intersection and domain difference. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3453–3462, 2019
2019
-
[4]
Domain separation networks
Konstantinos Bousmalis, George Trigeorgis, Nathan Silberman, Dilip Krishnan, and Dumitru Erhan. Domain separation networks. InAdvances in Neural Information Processing Systems, 2016
2016
-
[5]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18392–18402, 2023
2023
-
[6]
Double infogan for contrastive analysis
Florence Carton, Robin Louiset, and Pietro Gori. Double infogan for contrastive analysis. InInternational Conference on Artificial Intelligence and Statistics, pages 172–180. PMLR, 2024. 10
2024
-
[7]
Infogan: Interpretable representation learning by information maximizing generative adversarial nets.Advances in neural information processing systems, 29, 2016
Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, and Pieter Abbeel. Infogan: Interpretable representation learning by information maximizing generative adversarial nets.Advances in neural information processing systems, 29, 2016
2016
-
[8]
Stargan v2: Diverse image synthesis for multiple domains
Yunjey Choi, Youngjung Uh, Jaejun Yoo, and Jung-Woo Ha. Stargan v2: Diverse image synthesis for multiple domains. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020
2020
-
[9]
In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4685–4694, 2019. doi: 10.1109/CVPR.2019.00482
-
[10]
Lightweight face recognition challenge
Jiankang Deng, Jia Guo, Debing Zhang, Yafeng Deng, Xiangju Lu, and Song Shi. Lightweight face recognition challenge. In2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), pages 2638–2646, 2019. doi: 10.1109/ICCVW.2019.00322
-
[11]
Integrating Prior Knowledge in Contrastive Learning with Kernel
Benoit Dufumier, Carlo Alberto Barbano, Robin Louiset, Edouard Duchesnay, and Pietro Gori. Integrating Prior Knowledge in Contrastive Learning with Kernel. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[12]
What to align in multimodal contrastive learning? InInternational Conference on Learning Representations (ICLR), 2025
Benoit Dufumier, Javiera Castillo-Navarro, Devis Tuia, and Jean-Philippe Thiran. What to align in multimodal contrastive learning? InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[13]
Learning robust represen- tations via multi-view information bottleneck
Marco Federici, Anjan Dutta, Patrick Forré, Nate Kushman, and Zeynep Akata. Learning robust represen- tations via multi-view information bottleneck. InInternational Conference on Learning Representations, 2020
2020
-
[14]
Unsupervised domain adaptation by backpropagation
Yaroslav Ganin and Victor Lempitsky. Unsupervised domain adaptation by backpropagation. InInterna- tional conference on machine learning, pages 1180–1189. PMLR, 2015
2015
-
[15]
Image-to-image translation for cross- domain disentanglement
Abel Gonzalez-Garcia, Joost van de Weijer, and Yoshua Bengio. Image-to-image translation for cross- domain disentanglement. InAdvances in Neural Information Processing Systems, 2018
2018
-
[16]
Nano banana pro: Advanced visual reasoning and editing with gemini 3 pro im- age
Google DeepMind. Nano banana pro: Advanced visual reasoning and editing with gemini 3 pro im- age. Technical report, Google, November 2025. URL https://ai.google.dev/gemini-api/docs/ image-generation
2025
-
[17]
Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020
2020
-
[18]
Saga: Learning signal-aligned distributions for improved text-to-image generation, 2025
Paul Grimal, Michaël Soumm, Hervé Le Borgne, Olivier Ferret, and Akihiro Sugimoto. Saga: Learning signal-aligned distributions for improved text-to-image generation, 2025. URL https://arxiv.org/ abs/2508.13866
-
[19]
Initno: Boosting text-to-image diffusion models via initial noise optimization
Xiefan Guo, Jinlin Liu, Miaomiao Cui, Jiankai Li, Hongyu Yang, and Di Huang. Initno: Boosting text-to-image diffusion models via initial noise optimization. InCVPR, 2024
2024
-
[20]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[21]
Learning Common and Salient Generative Factors Between Two Image Datasets, 2025
Yunlong He, Gwilherm Lesné, Ziqian Liu, Michaël Soumm, and Pietro Gori. Learning Common and Salient Generative Factors Between Two Image Datasets, 2025
2025
-
[22]
Prompt-to- prompt image editing with cross-attention control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-or. Prompt-to- prompt image editing with cross-attention control. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[23]
beta-vae: Learning basic visual concepts with a constrained variational framework
Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-vae: Learning basic visual concepts with a constrained variational framework. InInternational conference on learning representations, 2017
2017
-
[24]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[25]
Perceiver IO: A General Architecture for Structured Inputs & Outputs
Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, et al. Perceiver io: A general architecture for structured inputs & outputs.arXiv preprint arXiv:2107.14795, 2021. 11
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
Training-free content injection using h-space in diffusion models
Jaeseok Jeong, Mingi Kwon, and Youngjung Uh. Training-free content injection using h-space in diffusion models. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5151–5161, 2024
2024
-
[27]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019
2019
-
[28]
The brain tumor segmentation (brats) challenge 2023: Focus on pediatrics (cbtn-connect-dipgr-asnr-miccai brats-peds)
Anahita Fathi Kazerooni, Nastaran Khalili, Xinyang Liu, Debanjan Haldar, Zhifan Jiang, Syed Muhammed Anwar, Jake Albrecht, Maruf Adewole, Udunna Anazodo, Hannah Anderson, et al. The brain tumor segmentation (brats) challenge 2023: Focus on pediatrics (cbtn-connect-dipgr-asnr-miccai brats-peds). ArXiv, pages arXiv–2305, 2024
2023
-
[29]
Michael Kleinman, Alessandro Achille, Stefano Soatto, and Jonathan C. Kao. Gács–körner common information variational autoencoder. InAdvances in Neural Information Processing Systems, 2023
2023
-
[30]
Diffusion models already have a semantic latent space
Mingi Kwon, Jaeseok Jeong, and Youngjung Uh. Diffusion models already have a semantic latent space. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[31]
Dranet: Disentangling representation and adaptation networks for unsupervised cross-domain adaptation
Seunghun Lee, Sunghyun Cho, and Sunghoon Im. Dranet: Disentangling representation and adaptation networks for unsupervised cross-domain adaptation. InCVPR, pages 15252–15261, 2021
2021
-
[32]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In Proceedings of International Conference on Computer Vision (ICCV), 2015
2015
-
[34]
Challenging common assumptions in the unsupervised learning of disentangled representations
Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar Raetsch, Sylvain Gelly, Bernhard Schölkopf, and Olivier Bachem. Challenging common assumptions in the unsupervised learning of disentangled representations. Ininternational conference on machine learning, pages 4114–4124. PMLR, 2019
2019
-
[35]
UCSL : A Machine Learning Expectation-Maximization Framework for Unsupervised Clustering Driven by Supervised Learning
Robin Louiset, Pietro Gori, Benoit Dufumier, Josselin Houenou, Antoine Grigis, and Edouard Duchesnay. UCSL : A Machine Learning Expectation-Maximization Framework for Unsupervised Clustering Driven by Supervised Learning. InMachine Learning and Knowledge Discovery in Databases. Research Track, 2021
2021
-
[36]
Sepvae: a contrastive vae to separate pathological patterns from healthy ones
Robin Louiset, Edouard Duchesnay, Grigis Antoine, Benoit Dufumier, and Pietro Gori. Sepvae: a contrastive vae to separate pathological patterns from healthy ones. In Ninon Burgos, Caroline Petitjean, Maria Vakalopoulou, Stergios Christodoulidis, Pierrick Coupe, Hervé Delingette, Carole Lartizien, and Diana Mateus, editors,Proceedings of The 7nd Internatio...
-
[37]
URLhttps://proceedings.mlr.press/v250/louiset24a.html
-
[38]
Separating common from salient patterns with contrastive representation learning
Robin Louiset, Edouard Duchesnay, Antoine Grigis, and Pietro Gori. Separating common from salient patterns with contrastive representation learning. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=30N3bNAiw3
2024
-
[39]
Automatic Discovery of Disease Subgroups by Contrasting with Healthy Controls.Data Mining and Knowledge Discovery, 2026
Robin Louiset, Edouard Duchesnay, Benoit Dufumier, Antoine Grigis, and Pietro Gori. Automatic Discovery of Disease Subgroups by Contrasting with Healthy Controls.Data Mining and Knowledge Discovery, 2026
2026
-
[40]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6038–6047, 2023
2023
-
[41]
Understanding the latent space of diffusion models through the lens of riemannian geometry.Advances in Neural Information Processing Systems, 36:24129–24142, 2023
Yong-Hyun Park, Mingi Kwon, Jaewoong Choi, Junghyo Jo, and Youngjung Uh. Understanding the latent space of diffusion models through the lens of riemannian geometry.Advances in Neural Information Processing Systems, 36:24129–24142, 2023
2023
-
[42]
Zero-shot image-to-image translation
Gaurav Parmar, Krishna Kumar Singh, Richard Zhang, Yijun Li, Jingwan Lu, and Jun-Yan Zhu. Zero-shot image-to-image translation. InACM SIGGRAPH 2023 conference proceedings, pages 1–11, 2023
2023
-
[43]
Diffusion autoencoders: Toward a meaningful and decodable representation
Konpat Preechakul, Nattanat Chatthee, Suttisak Wizadwongsa, and Supasorn Suwajanakorn. Diffusion autoencoders: Toward a meaningful and decodable representation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10619–10629, 2022. 12
2022
-
[44]
Shared Independent Component Analysis for Multi-Subject Neuroimaging
Hugo Richard, Pierre Ablin, Bertrand Thirion, Alexandre Gramfort, and Aapo Hyvarinen. Shared Independent Component Analysis for Multi-Subject Neuroimaging. InNeurIPS, volume 34, pages 29962–29971, 2021
2021
-
[45]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[46]
Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500–22510, 2023
2023
-
[47]
Learning disentangled representations via mutual information estimation
Eduardo Hugo Sánchez, Mathieu Serrurier, and Mathias Ortner. Learning disentangled representations via mutual information estimation. InEuropean Conference on Computer Vision (ECCV), 2020
2020
-
[48]
Color alignment in diffusion
Ka Chun Shum, Binh-Son Hua, Duc Thanh Nguyen, and Sai-Kit Yeung. Color alignment in diffusion. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 28446–28455, 2025
2025
-
[49]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Contrastive multiview coding
Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive multiview coding. InECCV, pages 776–794, 2020
2020
-
[51]
Improving and generalizing flow-based generative models with minibatch optimal transport.Transactions on Machine Learning Research, 2024
Alexander Tong, Kilian FATRAS, Nikolay Malkin, Guillaume Huguet, Yanlei Zhang, Jarrid Rector-Brooks, Guy Wolf, and Yoshua Bengio. Improving and generalizing flow-based generative models with minibatch optimal transport.Transactions on Machine Learning Research, 2024. ISSN 2835-8856
2024
-
[52]
Deep variational canonical correlation analysis
Weiran Wang, Xinchen Yan, Honglak Lee, and Karen Livescu. Deep variational canonical correlation analysis. InInternational Conference on Learning Representations (ICLR), 2017
2017
-
[53]
Moment matching deep contrastive latent variable models.arXiv preprint arXiv:2202.10560, 2022
Ethan Weinberger, Nicasia Beebe-Wang, and Su-In Lee. Moment matching deep contrastive latent variable models.arXiv preprint arXiv:2202.10560, 2022
-
[54]
Diffusion model with cross attention as an inductive bias for disentanglement.Advances in Neural Information Processing Systems, 37:82465–82492, 2024
Tao Yang, Cuiling Lan, Yan Lu, and Nanning Zheng. Diffusion model with cross attention as an inductive bias for disentanglement.Advances in Neural Information Processing Systems, 37:82465–82492, 2024
2024
-
[55]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Anti-exposure bias in diffusion models
Junyu Zhang, Daochang Liu, Eunbyung Park, Shichao Zhang, and Chang Xu. Anti-exposure bias in diffusion models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=MtDd7rWok1
2025
-
[57]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
2023
-
[58]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representation autoencoders.arXiv preprint arXiv:2510.11690, 2025. 13 Appendix A: Broader Impact Our method has the potential to significantly impact domains such as medical imaging, where diffusion-based models combined with contrastive analysis could help identify subtl...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
eyes and mouth
The learning rate is warmed up from 10−6 to 10−4 for 5000 steps, then kept constant at 10−4 for the rest of the training. All models are trained in mixed precision with bfloat16. Training was performed on a single NVIDIA H100 GPU, equipped with an Intel Xeon Platinum 8468 CPU with 24 active cores (workers). Training takes about 48 hours on this configurat...
2032
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.