Regret Minimization in Single-Dimensional Contract-Design with Binary Actions
Pith reviewed 2026-06-27 23:11 UTC · model grok-4.3
The pith
In online contract design with binary actions and single-dimensional types, the principal achieves tight Θ(T^{2/3}) regret against adversarial sequences, independent of the number of outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the online principal-agent problem with binary actions and single-dimensional types reduces to one-dimensional threshold optimization. Against adversarial type sequences this yields tight Θ(T^{2/3}) regret independent of outcome count m through non-uniform discretization. For a single fixed hidden type, stochastic binary search to learn the type followed by commitment to a robustified near-optimal contract produces tight ilde{Θ}(√T) regret.
What carries the argument
reduction to a one-dimensional threshold optimization problem combined with non-uniform discretization for the non-Lipschitz payoff
If this is right
- The Θ(T^{2/3}) rate holds for any number of outcomes m and remains unchanged as m increases.
- For any fixed but unknown type the regret improves to ilde{Θ}(√T) via the explore-then-commit strategy.
- The bounds apply when the principal receives only outcome realizations and never observes the chosen action.
- The non-uniform discretization handles the non-Lipschitz structure while preserving the stated rates.
Where Pith is reading between the lines
- The independence of regret from outcome count suggests the method could scale directly to outcome spaces with thousands of elements.
- The one-dimensional reduction may extend to other principal-agent models whose type spaces admit a similar ordering or threshold structure.
- Empirical checks on synthetic instances with growing m would directly test whether the claimed independence holds in finite samples.
Load-bearing premise
The agent's action space is restricted to binary choices and types are single-dimensional costs per unit effort, which permits the reduction to one-dimensional threshold optimization.
What would settle it
An explicit instance with binary actions and single-dimensional types in which the minimax regret grows strictly faster than any constant multiple of T^{2/3} against adversarial sequences would falsify the upper bound.
Figures
read the original abstract
We study principal-agent problems in which a principal commits to an outcome-dependent payment scheme (i.e., a contract) in order to induce an agent to take a costly action leading to a favorable outcome. We consider the online extension of the classical (one-shot) principal-agent problem, in which the principal repeatedly interacts with agents by proposing contracts over multiple rounds. The principal has no information about the agents and, crucially, does not observe their actions. As a result, the principal must learn an optimal contract using only the realized outcomes observed at each round. We focus on the setting with binary actions and single-dimensional agent types, where the agent's private type represents their cost per unit-of-effort. For adversarial-type sequences, we provide tight $\Theta(T^{2/3})$ regret guarantees. Remarkably, this rate is completely independent of the number of outcomes $m$. The upper bound is based on two key components: 1) a reduction to a one-dimensional threshold optimization problem and 2) a non-uniform discretization to handle the non-Lipschitz nature of the problem. Moreover, in the case of a single (fixed) hidden type, we show that it is possible to improve the rates and provide a tight $\widetilde{\Theta}(\sqrt{T})$ regret bound. Our algorithm is based on an explore-then-commit strategy where we first approximately learn the hidden type via a stochastic binary search, and then we commit to a ``robustified'' near-optimal contract.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the online principal-agent contract design problem restricted to binary actions and single-dimensional agent types (cost per unit effort). For adversarial sequences of agent types, it claims tight Θ(T^{2/3}) regret bounds that are independent of the number of outcomes m. The upper bound proceeds by reducing the problem to one-dimensional threshold optimization followed by non-uniform discretization to manage the non-Lipschitz loss. For a single fixed hidden type, an explore-then-commit algorithm using stochastic binary search yields a tight ilde{Θ}(√T) regret bound.
Significance. If the m-independence of the Θ(T^{2/3}) bound holds, the result is significant: it decouples learning complexity from outcome-space dimension in a natural restricted setting and supplies a clean reduction plus discretization technique. The fixed-type ilde{Θ}(√T) result is a standard improvement but is cleanly realized via binary search and robustification. The paper supplies no visible proof sketches or error-bar analysis in the abstract, limiting immediate verification of the central rates.
major comments (2)
- [Abstract (discretization component)] Abstract: the claimed Θ(T^{2/3}) rate independent of m rests on the non-uniform discretization step controlling both grid cardinality and additive approximation error without m-dependence. Because outcome probabilities live in an m-dimensional simplex, it is necessary to verify explicitly that local Lipschitz constants around each threshold and the resulting per-round error term remain m-free; otherwise the final regret expression could acquire hidden m factors. This is the load-bearing step for the independence claim.
- [Abstract] Abstract: no proof sketch, error analysis, or handling of non-Lipschitz points is supplied, so the soundness of the reduction to 1D threshold optimization and the subsequent discretization cannot be checked from the given text. The central adversarial regret claim therefore requires additional technical detail to be load-bearing.
minor comments (2)
- Notation for the single-dimensional type (cost per unit effort) and the threshold formulation should be introduced with an explicit equation in the main body rather than left implicit in the abstract.
- The explore-then-commit strategy for the fixed-type case would benefit from a short paragraph clarifying how the 'robustified' contract is constructed to tolerate the approximation error from the binary search phase.
Simulated Author's Rebuttal
We thank the referee for the careful review and for recognizing the potential significance of the m-independent bound. We address the two major comments point-by-point below and propose targeted revisions to the abstract.
read point-by-point responses
-
Referee: [Abstract (discretization component)] Abstract: the claimed Θ(T^{2/3}) rate independent of m rests on the non-uniform discretization step controlling both grid cardinality and additive approximation error without m-dependence. Because outcome probabilities live in an m-dimensional simplex, it is necessary to verify explicitly that local Lipschitz constants around each threshold and the resulting per-round error term remain m-free; otherwise the final regret expression could acquire hidden m factors. This is the load-bearing step for the independence claim.
Authors: We agree this verification is essential. The manuscript establishes the m-independence by reducing to a one-dimensional threshold (Section 3) and then applying non-uniform discretization whose local spacing is chosen according to the sensitivity of the principal's loss with respect to that threshold. Because actions are binary and the type is single-dimensional, the loss depends on outcome probabilities only through a scalar effective value; the resulting local Lipschitz constants and per-round additive error are therefore bounded by quantities (maximum payment and action-cost differences) that do not grow with m. The full error analysis appears in Section 4. We will add one sentence to the abstract explicitly noting that the discretization analysis yields m-free constants. revision: yes
-
Referee: [Abstract] Abstract: no proof sketch, error analysis, or handling of non-Lipschitz points is supplied, so the soundness of the reduction to 1D threshold optimization and the subsequent discretization cannot be checked from the given text. The central adversarial regret claim therefore requires additional technical detail to be load-bearing.
Authors: Abstracts are necessarily concise, yet we accept that a slightly expanded description would improve immediate verifiability. The current abstract already states the two key components (reduction to 1D threshold optimization and non-uniform discretization for non-Lipschitz loss). We will enlarge this clause by one sentence that indicates how the discretization controls both grid size and approximation error, while still remaining within length limits. The complete technical development, including explicit handling of non-Lipschitz points via adaptive grid refinement, remains in the body of the paper. revision: yes
Circularity Check
No circularity: algorithmic reduction and discretization yield independent regret bound
full rationale
The abstract and described method reduce the problem to 1D threshold optimization followed by non-uniform discretization to obtain the Θ(T^{2/3}) bound independent of m. No equations, fitted parameters, or self-citations are shown that would make the claimed rate equivalent to its inputs by construction. The derivation is presented as arising from the algorithmic construction rather than tautological re-expression, consistent with an honest non-finding.
Axiom & Free-Parameter Ledger
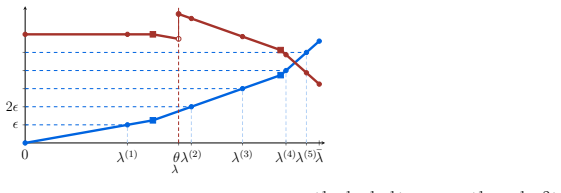
axioms (1)
- domain assumption Binary actions and single-dimensional types (cost per unit effort) allow reduction to one-dimensional threshold optimization
Reference graph
Works this paper leans on
-
[1]
Contracts with private cost per unit-of-effort
Tal Alon, Paul Dütting, and Inbal Talgam-Cohen. Contracts with private cost per unit-of-effort. InProceedings of the 22nd ACM Conference on Economics and Computation, pages 52–69, 2021
2021
-
[2]
Bayesian analysis of linear contracts
Tal Alon, Paul Duetting, Yingkai Li, and Inbal Talgam-Cohen. Bayesian analysis of linear contracts. InProceedings of the 24th ACM Conference on Economics and Computation, EC ’23, page 66, 2023
2023
-
[3]
Minimax policies for adversarial and stochastic bandits
Jean-Yves Audibert and Sébastien Bubeck. Minimax policies for adversarial and stochastic bandits. InCOLT - The 22nd Conference on Learning Theory, 2009
2009
-
[4]
Combinatorial agency.J
Moshe Babaioff, Michal Feldman, Noam Nisan, and Eyal Winter. Combinatorial agency.J. Econ. Theory, 147(3):999–1034, 2012
2012
-
[5]
Dynamic pricing with limited supply, 2015
Moshe Babaioff, Shaddin Dughmi, Robert Kleinberg, and Aleksandrs Slivkins. Dynamic pricing with limited supply, 2015
2015
-
[6]
Learning optimal contracts: How to exploit small action spaces
Francesco Bacchiocchi, Matteo Castiglioni, Alberto Marchesi, and Nicola Gatti. Learning optimal contracts: How to exploit small action spaces. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[7]
Francesco Bacchiocchi, Matteo Castiglioni, Alberto Marchesi, and Nicola Gatti. Regret min- imization for piecewise linear rewards: Contracts, auctions, and beyond.arXiv preprint arXiv:2503.01701, 2025
arXiv 2025
-
[8]
Commitment without regrets: Online learning in stackelberg security games
Maria-Florina Balcan, Avrim Blum, Nika Haghtalab, and Ariel D Procaccia. Commitment without regrets: Online learning in stackelberg security games. InProceedings of the sixteenth ACM conference on economics and computation, pages 61–78, 2015
2015
-
[9]
Maria-Florina Balcan, Martino Bernasconi, Matteo Castiglioni, Andrea Celli, Keegan Har- ris, and Zhiwei Steven Wu. Nearly-optimal bandit learning in stackelberg games with side information.arXiv preprint arXiv:2502.00204, 2025
Pith/arXiv arXiv 2025
-
[10]
Analysis of medicare pay-for-performance contracts.Available at SSRN 2839143, 2016
Hamsa Bastani, Mohsen Bayati, Mark Braverman, Ramki Gummadi, and Ramesh Johari. Analysis of medicare pay-for-performance contracts.Available at SSRN 2839143, 2016
2016
-
[11]
Evidence of upcoding in pay-for-performance programs.Management Science, 65(3):1042–1060, 2019
Hamsa Bastani, Joel Goh, and Mohsen Bayati. Evidence of upcoding in pay-for-performance programs.Management Science, 65(3):1042–1060, 2019
2019
-
[12]
Optimal rates and efficient algorithms for online bayesian persuasion
Martino Bernasconi, Matteo Castiglioni, Andrea Celli, Alberto Marchesi, Francesco Trovò, and Nicola Gatti. Optimal rates and efficient algorithms for online bayesian persuasion. In International Conference on Machine Learning, pages 2164–2183. PMLR, 2023
2023
-
[13]
No-regret learning in bilateral trade via global budget balance
Martino Bernasconi, Matteo Castiglioni, Andrea Celli, and Federico Fusco. No-regret learning in bilateral trade via global budget balance. InProceedings of the 56th Annual ACM Symposium on Theory of Computing, pages 247–258, 2024
2024
-
[14]
Regret-minimizing contracts: Agency under uncertainty.arXiv preprint arXiv:2402.13156, 2024
Martino Bernasconi, Matteo Castiglioni, and Alberto Marchesi. Regret-minimizing contracts: Agency under uncertainty.arXiv preprint arXiv:2402.13156, 2024
arXiv 2024
-
[15]
Martino Bernasconi, Matteo Castiglioni, and Andrea Celli. Single-dimensional contract design: Efficient algorithms and learning.arXiv preprint arXiv:2502.11661, 2025
arXiv 2025
-
[16]
Learning optimal commitment to overcome insecurity.Advances in Neural Information Processing Systems, 27, 2014
Avrim Blum, Nika Haghtalab, and Ariel D Procaccia. Learning optimal commitment to overcome insecurity.Advances in Neural Information Processing Systems, 27, 2014
2014
-
[17]
Concentration inequalities
Stéphane Boucheron, Gábor Lugosi, and Olivier Bousquet. Concentration inequalities. In Summer school on machine learning, pages 208–240. Springer, 2003
2003
-
[18]
Optimum statistical estimation with strategic data sources
Yang Cai, Constantinos Daskalakis, and Christos Papadimitriou. Optimum statistical estimation with strategic data sources. InConference on Learning Theory, pages 280–296. PMLR, 2015. 11
2015
-
[19]
Online bayesian persua- sion.Advances in neural information processing systems, 33:16188–16198, 2020
Matteo Castiglioni, Andrea Celli, Alberto Marchesi, and Nicola Gatti. Online bayesian persua- sion.Advances in neural information processing systems, 33:16188–16198, 2020
2020
-
[20]
Multi-receiver online bayesian persuasion
Matteo Castiglioni, Alberto Marchesi, Andrea Celli, and Nicola Gatti. Multi-receiver online bayesian persuasion. InInternational Conference on Machine Learning, pages 1314–1323. PMLR, 2021
2021
-
[21]
Bayesian agency: Linear versus tractable contracts.Artificial Intelligence, 307, 2022
Matteo Castiglioni, Alberto Marchesi, and Nicola Gatti. Bayesian agency: Linear versus tractable contracts.Artificial Intelligence, 307, 2022
2022
-
[22]
Designing menus of contracts effi- ciently: The power of randomization.Artificial Intelligence, 318:103881, 2023
Matteo Castiglioni, Alberto Marchesi, and Nicola Gatti. Designing menus of contracts effi- ciently: The power of randomization.Artificial Intelligence, 318:103881, 2023
2023
-
[23]
A reduction from multi-parameter to single-parameter bayesian contract design
Matteo Castiglioni, Junjie Chen, Minming Li, Haifeng Xu, and Song Zuo. A reduction from multi-parameter to single-parameter bayesian contract design. InProceedings of the 2025 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 1795–1836. SIAM, 2025
2025
-
[24]
Market making without regret.arXiv preprint arXiv:2411.13993, 2024
Nicolo Cesa-Bianchi, Tommaso Cesari, Roberto Colomboni, Luigi Foscari, and Vinayak Pathak. Market making without regret.arXiv preprint arXiv:2411.13993, 2024
arXiv 2024
-
[25]
Regret analysis of bilateral trade with a smoothed adversary.Journal of Machine Learning Research, 25(234):1–36, 2024
Nicolò Cesa-Bianchi, Tommaso Cesari, Roberto Colomboni, Federico Fusco, and Stefano Leonardi. Regret analysis of bilateral trade with a smoothed adversary.Journal of Machine Learning Research, 25(234):1–36, 2024
2024
-
[26]
Are bounded contracts learnable and approximately optimal? InProceedings of the 25th ACM Conference on Economics and Computation, pages 315–344, 2024
Yurong Chen, Zhaohua Chen, Xiaotie Deng, and Zhiyi Huang. Are bounded contracts learnable and approximately optimal? InProceedings of the 25th ACM Conference on Economics and Computation, pages 315–344, 2024
2024
-
[27]
Learning approximately optimal contracts
Alon Cohen, Argyrios Deligkas, and Moran Koren. Learning approximately optimal contracts. InAlgorithmic Game Theory: 15th International Symposium, SAGT 2022, Colchester, UK, September 12–15, 2022, Proceedings, page 331–346, Berlin, Heidelberg, 2022. Springer-Verlag
2022
-
[28]
Blockchain disruption and smart contracts.The Review of Financial Studies, 32(5):1754–1797, 2019
Lin William Cong and Zhiguo He. Blockchain disruption and smart contracts.The Review of Financial Studies, 32(5):1754–1797, 2019
2019
-
[29]
Simple versus optimal contracts
Paul Dütting, Tim Roughgarden, and Inbal Talgam-Cohen. Simple versus optimal contracts. InProceedings of the 2019 ACM Conference on Economics and Computation, pages 369–387, 2019
2019
-
[30]
The complexity of contracts.SIAM Journal on Computing, 50(1):211–254, 2021
Paul Dutting, Tim Roughgarden, and Inbal Talgam-Cohen. The complexity of contracts.SIAM Journal on Computing, 50(1):211–254, 2021
2021
-
[31]
Multi-agent contracts
Paul Dütting, Tomer Ezra, Michal Feldman, and Thomas Kesselheim. Multi-agent contracts. In Proceedings of the 55th Annual ACM Symposium on Theory of Computing, pages 1311–1324, 2023
2023
-
[32]
Optimal no-regret learning for one-sided lipschitz functions
Paul Dütting, Guru Guruganesh, Jon Schneider, and Joshua Ruizhi Wang. Optimal no-regret learning for one-sided lipschitz functions. InInternational Conference on Machine Learning, pages 8836–8850. PMLR, 2023
2023
-
[33]
Algorithmic contract theory: A survey.Foundations and Trends® in Theoretical Computer Science, 16(3-4):211–412, 2024
Paul Dütting, Michal Feldman, Inbal Talgam-Cohen, et al. Algorithmic contract theory: A survey.Foundations and Trends® in Theoretical Computer Science, 16(3-4):211–412, 2024
2024
-
[34]
The pseudo-dimension of contracts
Paul Dütting, Michal Feldman, Tomasz Ponitka, and Ermis Soumalias. The pseudo-dimension of contracts. InProceedings of the 26th ACM Conference on Economics and Computation, pages 514–539, 2025
2025
-
[35]
Michal Feldman. Combinatorial contract design: Recent progress and emerging frontiers.arXiv preprint arXiv:2510.15065, 2025
arXiv 2025
-
[36]
Contracts under moral hazard and adverse selection
Guru Guruganesh, Jon Schneider, and Joshua R Wang. Contracts under moral hazard and adverse selection. InProceedings of the 22nd ACM Conference on Economics and Computation, pages 563–582, 2021. 12
2021
-
[37]
Incomplete contracting and ai alignment
Dylan Hadfield-Menell and Gillian K Hadfield. Incomplete contracting and ai alignment. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, pages 417–422, 2019
2019
-
[38]
Adaptive contract design for crowdsourcing markets: Bandit algorithms for repeated principal-agent problems.Journal of Artificial Intelligence Research, 55:317–359, 2016
Chien-Ju Ho, Aleksandrs Slivkins, and Jennifer Wortman Vaughan. Adaptive contract design for crowdsourcing markets: Bandit algorithms for repeated principal-agent problems.Journal of Artificial Intelligence Research, 55:317–359, 2016
2016
-
[39]
Estimating effects of incentive contracts in online labor platforms.Management Science, 69(4):2106–2126, 2023
Nur Kaynar and Auyon Siddiq. Estimating effects of incentive contracts in online labor platforms.Management Science, 69(4):2106–2126, 2023
2023
-
[40]
The value of knowing a demand curve: Bounds on regret for online posted-price auctions
Robert Kleinberg and Tom Leighton. The value of knowing a demand curve: Bounds on regret for online posted-price auctions. In44th Annual IEEE Symposium on Foundations of Computer Science, 2003. Proceedings., pages 594–605. IEEE, 2003
2003
-
[41]
Learning with good feature representations in bandits and in rl with a generative model
Tor Lattimore, Csaba Szepesvari, and Gellert Weisz. Learning with good feature representations in bandits and in rl with a generative model. InInternational conference on machine learning, pages 5662–5670. PMLR, 2020
2020
-
[42]
Learning and approximating the optimal strategy to commit to
Joshua Letchford, Vincent Conitzer, and Kamesh Munagala. Learning and approximating the optimal strategy to commit to. InAlgorithmic Game Theory: Second International Symposium, SAGT 2009, pages 250–262. Springer, 2009
2009
-
[43]
Learning optimal strategies to commit to
Binghui Peng, Weiran Shen, Pingzhong Tang, and Song Zuo. Learning optimal strategies to commit to. InProceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 2149–2156, 2019
2019
-
[44]
Delegated classification.Advances in Neural Information Processing Systems, 36:13200–13236, 2023
Eden Saig, Inbal Talgam-Cohen, and Nir Rosenfeld. Delegated classification.Advances in Neural Information Processing Systems, 36:13200–13236, 2023
2023
-
[45]
Incentivizing quality text generation via statistical contracts.Advances in Neural Information Processing Systems, 37:51196–51222, 2024
Eden Saig, Ohad Einav, and Inbal Talgam-Cohen. Incentivizing quality text generation via statistical contracts.Advances in Neural Information Processing Systems, 37:51196–51222, 2024
2024
-
[46]
Adaptive contracts for cost-effective ai delegation.arXiv preprint arXiv:2603.17212, 2026
Eden Saig, Tamar Garbuz, Ariel D Procaccia, Inbal Talgam-Cohen, and Jamie Tucker-Foltz. Adaptive contracts for cost-effective ai delegation.arXiv preprint arXiv:2603.17212, 2026
arXiv 2026
-
[47]
Introduction to multi-armed bandits.Foundations and Trends® in Machine Learning, 12(1-2):1–286, 2019
Aleksandrs Slivkins. Introduction to multi-armed bandits.Foundations and Trends® in Machine Learning, 12(1-2):1–286, 2019
2019
-
[48]
Ander Artola Velasco, Stratis Tsirtsis, Nastaran Okati, and Manuel Gomez-Rodriguez. Is your llm overcharging you? tokenization, transparency, and incentives.arXiv preprint arXiv:2505.21627, 2025
Pith/arXiv arXiv 2025
-
[49]
TX t=1 U P (pt, b(θt, pt) # =OPT−max p∈P (ϵ) TX t=1 U P (p, b(θt, p)) + max p∈P (ϵ) TX t=1 U P (p, b(θt, p))−E
Banghua Zhu, Stephen Bates, Zhuoran Yang, Yixin Wang, Jiantao Jiao, and Michael I Jordan. The sample complexity of online contract design. InProceedings of the 24th ACM Conference on Economics and Computation, pages 1188–1188, 2023. 13 A Proof of Theorem 1 In this section we prove Theorem 1. This section is structured as follows. First, in Section A.1, we...
2023
-
[50]
If b(θ1, p⋆
=a 2, then, the null contract must be an optimal contract for θ1 as all the other contracts that induce a2 cannot yield larger utility to the principal. If b(θ1, p⋆
-
[51]
Either b(θ1,¯p) =a1, and again we have that the null contract must be an optimal contract forθ 1, orb(θ 1,¯p) =a2
=a 1, instead, there are two cases. Either b(θ1,¯p) =a1, and again we have that the null contract must be an optimal contract forθ 1, orb(θ 1,¯p) =a2. In this case: F ⊤ a1(r−p ⋆ 1)−F ⊤ a2 r≤(F a1 −F a2)⊤r≤ ∥F a1 −F a2 ∥1, which concludes the proof. 24 C.2 Statistical Test In this section, we prove results regarding the statistical test that we use in Algo...
-
[52]
Note that in both instances it is optimal to put a zero payment on the second outcomeω 2
The two instances only differ by the type θ and in particular, in the first instance θ0 = 40ϵ 1 ϵ +8 and θ1 = 24ϵ 1 ϵ +8. Note that in both instances it is optimal to put a zero payment on the second outcomeω 2. Letx=p ω1 be the payment on the first outcome. Note that an agent of type θ plays action a1 if and only if ( 1 2 + 4ϵ)x−θ≥ x 2 , and thus if and ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.