Computation-Aware Event-to-Frame Reconstruction via Selective Attention
Pith reviewed 2026-06-28 01:41 UTC · model grok-4.3
The pith
An efficient recurrent event-to-frame framework uses selective context fusion and lightweight hybrid attention to achieve competitive reconstruction quality at reduced model complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
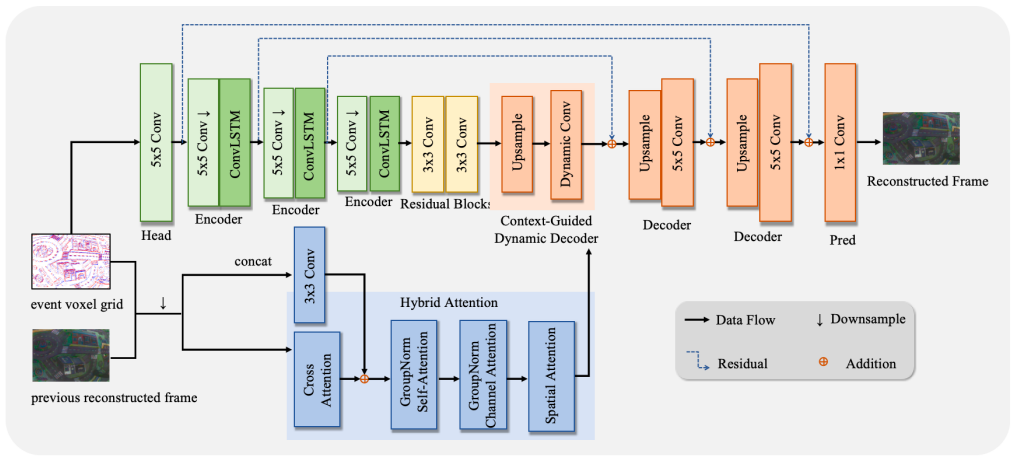
The proposed recurrent encoder-decoder architecture with selective context fusion and lightweight hybrid attention achieves competitive reconstruction performance on standard benchmarks while maintaining a favorable balance between accuracy and model complexity.
What carries the argument
Selective context fusion strategy paired with a lightweight hybrid attention mechanism inside a recurrent encoder-decoder.
If this is right
- Event streams can be fed into standard frame-based vision systems with lower compute demands.
- The architecture supports incremental processing suitable for streaming applications.
- Robustness gains appear under challenging motion and lighting without added attention overhead.
- Model complexity remains competitive, enabling deployment where resources are limited.
Where Pith is reading between the lines
- The same selective fusion pattern might reduce compute in other asynchronous-to-synchronous vision tasks.
- Integration with downstream frame-based models could be tested by measuring end-to-end latency on embedded hardware.
- The recurrent hidden-state design suggests a path toward memory-efficient long-sequence event processing.
Load-bearing premise
The selective context fusion strategy and lightweight hybrid attention mechanism improve robustness under fast motion and illumination variations without introducing significant computational cost or accuracy loss.
What would settle it
A benchmark evaluation in which the method shows either lower reconstruction quality or higher model complexity than existing approaches would falsify the central performance claim.
Figures
read the original abstract
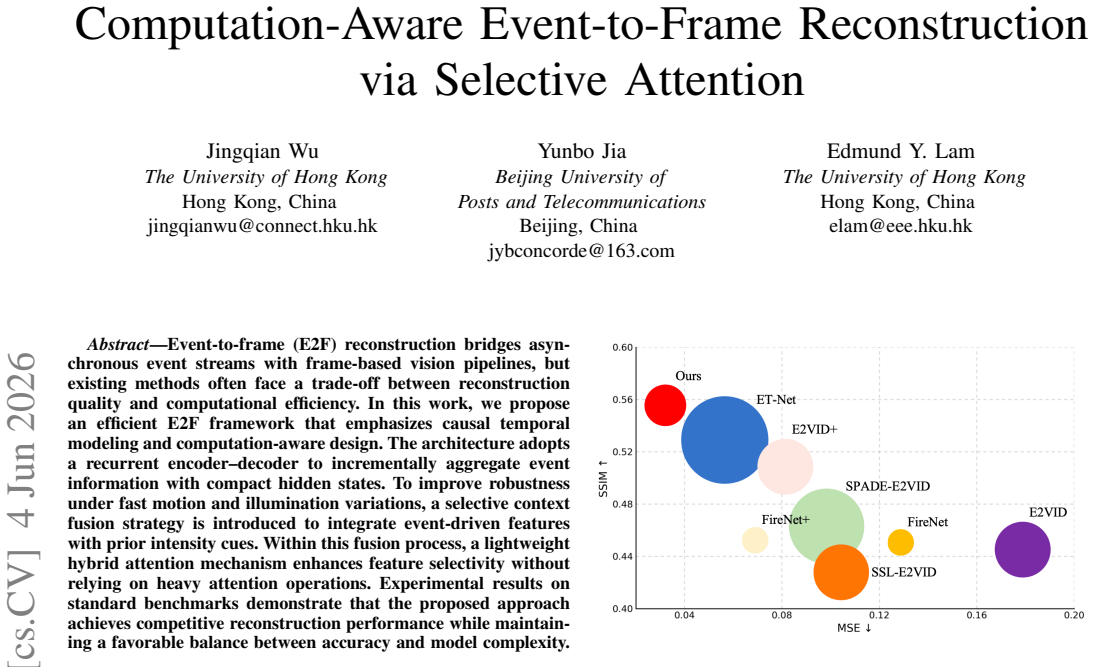
Event-to-frame (E2F) reconstruction bridges asynchronous event streams with frame-based vision pipelines, but existing methods often face a trade-off between reconstruction quality and computational efficiency. In this work, we propose an efficient E2F framework that emphasizes causal temporal modeling and computation-aware design. The architecture adopts a recurrent encoder-decoder to incrementally aggregate event information with compact hidden states. To improve robustness under fast motion and illumination variations, a selective context fusion strategy is introduced to integrate event-driven features with prior intensity cues. Within this fusion process, a lightweight hybrid attention mechanism enhances feature selectivity without relying on heavy attention operations. Experimental results on standard benchmarks demonstrate that the proposed approach achieves competitive reconstruction performance while maintaining a favorable balance between accuracy and model complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a computation-aware event-to-frame (E2F) reconstruction framework that employs a recurrent encoder-decoder for incremental causal aggregation of event streams, a selective context fusion strategy to combine event-driven features with prior intensity cues for robustness to fast motion and illumination changes, and a lightweight hybrid attention mechanism to enhance feature selectivity without heavy computation. It claims that experimental results on standard benchmarks show competitive reconstruction performance alongside a favorable accuracy-complexity trade-off.
Significance. If the experimental claims hold with concrete metrics, the work could contribute to efficient E2F methods suitable for resource-constrained vision pipelines by addressing the quality-efficiency trade-off through causal modeling and selective fusion, which are standard but practically relevant techniques in event-based vision.
major comments (1)
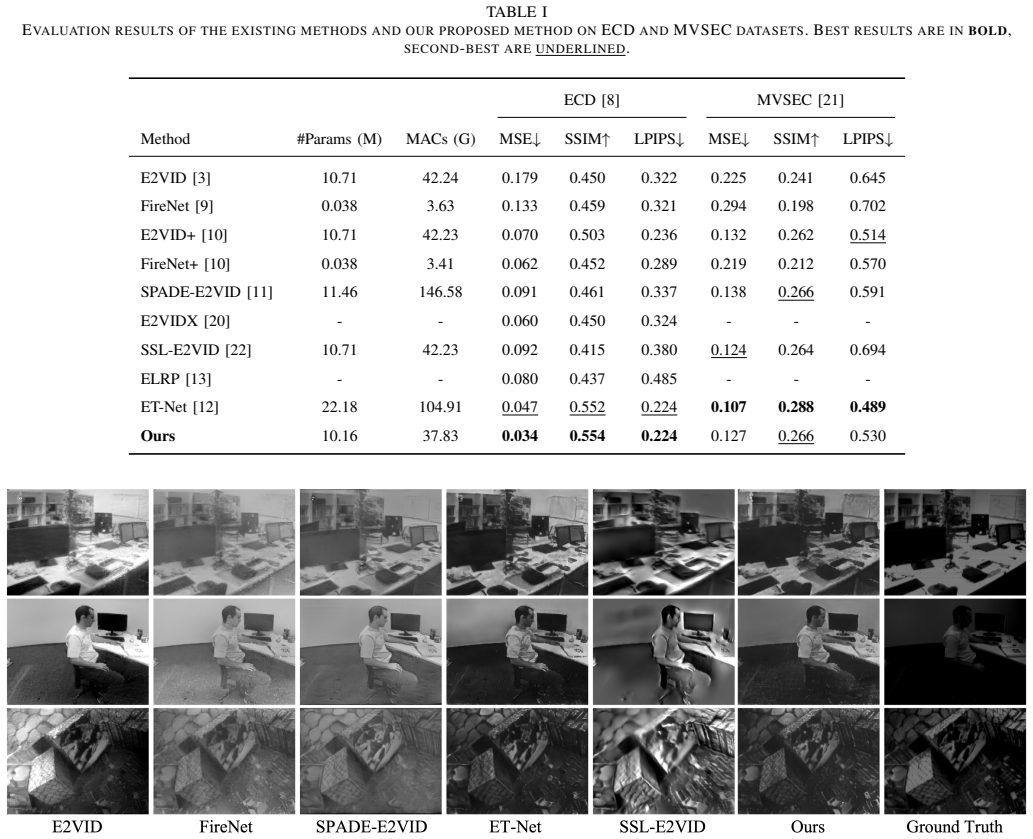
- [Abstract] Abstract: The central claim that 'experimental results on standard benchmarks demonstrate that the proposed approach achieves competitive reconstruction performance while maintaining a favorable balance between accuracy and model complexity' is presented without any quantitative numbers, specific baselines (e.g., E2VID or similar), error bars, ablation studies, or metrics such as PSNR, SSIM, or complexity measures (parameters/FLOPs). This absence makes the primary empirical support for the contribution unverifiable from the provided text and load-bearing for assessing whether the selective fusion and hybrid attention deliver the stated benefits without accuracy loss or added cost.
Simulated Author's Rebuttal
We thank the referee for the review and the opportunity to respond. We address the single major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'experimental results on standard benchmarks demonstrate that the proposed approach achieves competitive reconstruction performance while maintaining a favorable balance between accuracy and model complexity' is presented without any quantitative numbers, specific baselines (e.g., E2VID or similar), error bars, ablation studies, or metrics such as PSNR, SSIM, or complexity measures (parameters/FLOPs). This absence makes the primary empirical support for the contribution unverifiable from the provided text and load-bearing for assessing whether the selective fusion and hybrid attention deliver the stated benefits without accuracy loss or added cost.
Authors: We agree that the abstract presents the empirical claims qualitatively without specific numbers or metrics. The full manuscript contains the requested details: quantitative comparisons on standard benchmarks (including PSNR, SSIM), baselines such as E2VID, complexity measures (parameters/FLOPs), and ablation studies in the experimental section. To make the abstract self-contained and address the verifiability concern, we will revise it to incorporate key quantitative highlights supporting the accuracy-complexity trade-off and the benefits of selective fusion and hybrid attention. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes an architectural framework (recurrent encoder-decoder, selective context fusion, lightweight hybrid attention) for event-to-frame reconstruction and supports its claims solely via experimental results on standard benchmarks. No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear in the provided text. The central performance claim is externally falsifiable through benchmark evaluation and does not reduce to any input by construction, satisfying the criteria for a self-contained, non-circular argument.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
High speed and high dynamic range video with an event camera,
H. Rebecq, R. Ranftl, V . Koltun, and D. Scaramuzza, “High speed and high dynamic range video with an event camera,”IEEE transactions on pattern analysis and machine intelligence, vol. 43, no. 6, pp. 1964–1980, 2019
1964
-
[2]
SweepEvGS: Event- based 3d gaussian splatting for macro and micro radiance field rendering from a single sweep,
J. Wu, S. Zhu, C. Wang, B. Shi, and E. Y . Lam, “SweepEvGS: Event- based 3d gaussian splatting for macro and micro radiance field rendering from a single sweep,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[3]
Events-to-video: Bringing modern computer vision to event cameras,
H. Rebecq, R. Ranftl, V . Koltun, and D. Scaramuzza, “Events-to-video: Bringing modern computer vision to event cameras,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 3857–3866
2019
-
[4]
Ev-GS: Event-based gaussian splatting for efficient and accurate radiance field rendering,
J. Wu, S. Zhu, C. Wang, and E. Y . Lam, “Ev-GS: Event-based gaussian splatting for efficient and accurate radiance field rendering,” in2024 IEEE 34th International Workshop on Machine Learning for Signal Processing (MLSP). IEEE, 2024, pp. 1–6
2024
-
[5]
Dark- EvGS: Event camera as an eye for radiance field in the dark,
J. Wu, P. Duan, Z. Wang, C. Wang, B. Shi, and E. Y . Lam, “Dark- EvGS: Event camera as an eye for radiance field in the dark,”IEEE Transactions on Image Processing, 2026
2026
-
[6]
G. Gallego, T. Delbruck, G. Orchard, C. Bartolozzi, B. Taba, A. Censi, S. Leutenegger, A. J. Davison, J. Conradt, K. Daniilidis, and D. Scaramuzza, “ Event-Based Vision: A Survey ,” IEEE Transactions on Pattern Analysis & Machine Intelligence, vol. 44, no. 01, pp. 154–180, Jan. 2022. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/TPAMI.2...
-
[7]
Neuromorophic vision sensing and processing,
T. Delbruck, “Neuromorophic vision sensing and processing,” in2016 46th European Solid-State Device Research Conference (ESSDERC), 2016, pp. 7–14
2016
-
[8]
The event-camera dataset and simulator: Event-based data for pose estimation, visual odometry, and slam,
E. Mueggler, H. Rebecq, G. Gallego, T. Delbruck, and D. Scaramuzza, “The event-camera dataset and simulator: Event-based data for pose estimation, visual odometry, and slam,”The International journal of robotics research, vol. 36, no. 2, pp. 142–149, 2017
2017
-
[9]
Fast image reconstruction with an event camera,
C. Scheerlinck, H. Rebecq, D. Gehrig, N. Barnes, R. Mahony, and D. Scaramuzza, “Fast image reconstruction with an event camera,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2020, pp. 156–163
2020
-
[10]
Reducing the sim-to-real gap for event cameras,
T. Stoffregen, C. Scheerlinck, D. Scaramuzza, T. Drummond, N. Barnes, L. Kleeman, and R. Mahony, “Reducing the sim-to-real gap for event cameras,” inComputer Vision–ECCV 2020: 16th European Confer- ence, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVII 16. Springer, 2020, pp. 534–549
2020
-
[11]
Spade-e2vid: Spatially-adaptive denormalization for event-based video reconstruc- tion,
P. R. G. Cadena, Y . Qian, C. Wang, and M. Yang, “Spade-e2vid: Spatially-adaptive denormalization for event-based video reconstruc- tion,”IEEE Transactions on Image Processing, vol. 30, pp. 2488–2500, 2021
2021
-
[12]
Event-based video reconstruction using transformer,
W. Weng, Y . Zhang, and Z. Xiong, “Event-based video reconstruction using transformer,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 2563–2572
2021
-
[13]
Z. Zhang, A. J. Yezzi, and G. Gallego, “ Formulating Event- Based Image Reconstruction as a Linear Inverse Problem With Deep Regularization Using Optical Flow ,”IEEE Transactions on Pattern Analysis & Machine Intelligence, vol. 45, no. 07, pp. 8372–8389, Jul. 2023. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/TPAMI.2022.3230727
-
[14]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[15]
Event-diffusion: Event-based image reconstruction and restoration with diffusion models,
Q. Liang, X. Zheng, K. Huang, Y . Zhang, J. Chen, and Y . Tian, “Event-diffusion: Event-based image reconstruction and restoration with diffusion models,” inProceedings of the 31st ACM International Conference on Multimedia, ser. MM ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 3837–3846. [Online]. Available: https://doi.org/10.11...
-
[16]
E2vidiff: Perceptual events-to-video reconstruction using diffusion priors,
J. Liang, B. Yu, Y . Yang, Y . Han, and B. Shi, “E2vidiff: Perceptual events-to-video reconstruction using diffusion priors,” 07 2024
2024
-
[17]
UniE2F: A Unified Diffusion Framework for Event-to-Frame Reconstruction with Video Foundation Models
G. Xu, Z. Zhu, and J. Hou, “Unie2f: A unified diffusion framework for event-to-frame reconstruction with video foundation models,” 2026. [Online]. Available: https://arxiv.org/abs/2602.19202
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Loihi: A neuromorphic manycore processor with on-chip learning,
M. Davies, N. Srinivasa, T.-H. Lin, G. Chinya, Y . Cao, S. H. Choday, G. Dimou, P. Joshi, N. Imam, S. Jainet al., “Loihi: A neuromorphic manycore processor with on-chip learning,”Ieee Micro, vol. 38, no. 1, pp. 82–99, 2018
2018
-
[19]
A million spiking-neuron integrated circuit with a scalable communication network and interface,
P. A. Merolla, J. V . Arthur, R. Alvarez-Icaza, A. S. Cassidy, J. Sawada, F. Akopyan, B. L. Jackson, N. Imam, C. Guo, Y . Nakamuraet al., “A million spiking-neuron integrated circuit with a scalable communication network and interface,”Science, vol. 345, no. 6197, pp. 668–673, 2014
2014
-
[20]
E2vidx: improved bridge between conventional vision and bionic vision,
X. Hou, F. Zhang, D. Gulati, T. Tan, and W. Zhang, “E2vidx: improved bridge between conventional vision and bionic vision,”Frontiers in Neurorobotics, vol. V olume 17 - 2023, 2023
2023
-
[21]
The multivehicle stereo event camera dataset: An event camera dataset for 3d perception,
A. Z. Zhu, D. Thakur, T. ¨Ozaslan, B. Pfrommer, V . Kumar, and K. Daniilidis, “The multivehicle stereo event camera dataset: An event camera dataset for 3d perception,”IEEE Robotics and Automation Letters, vol. 3, no. 3, pp. 2032–2039, 2018
2032
-
[22]
Back to event basics: Self- supervised learning of image reconstruction for event cameras via photometric constancy,
F. Paredes-Vall ´es and G. C. de Croon, “Back to event basics: Self- supervised learning of image reconstruction for event cameras via photometric constancy,” in2021 IEEE/CVF Conference on Computer Visionand Pattern Recognition. IEEE, 2021, pp. 3445–3454
2021
-
[23]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inComputer vision–ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part v 13. Springer, 2014, pp. 740–755
2014
-
[24]
Esim: an open event camera simulator,
H. Rebecq, D. Gehrig, and D. Scaramuzza, “Esim: an open event camera simulator,” inConference on robot learning. PMLR, 2018, pp. 969– 982
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.