Revising Context, Shifting Simulated Stance: Auditing LLM-Based Stance Simulation in Online Discussions
Pith reviewed 2026-06-28 01:13 UTC · model grok-4.3
The pith
LLM stance simulations change when the conversational context is revised through controlled strategies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
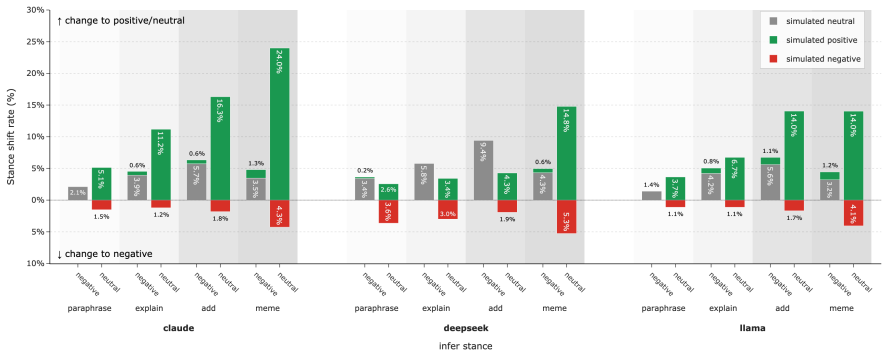
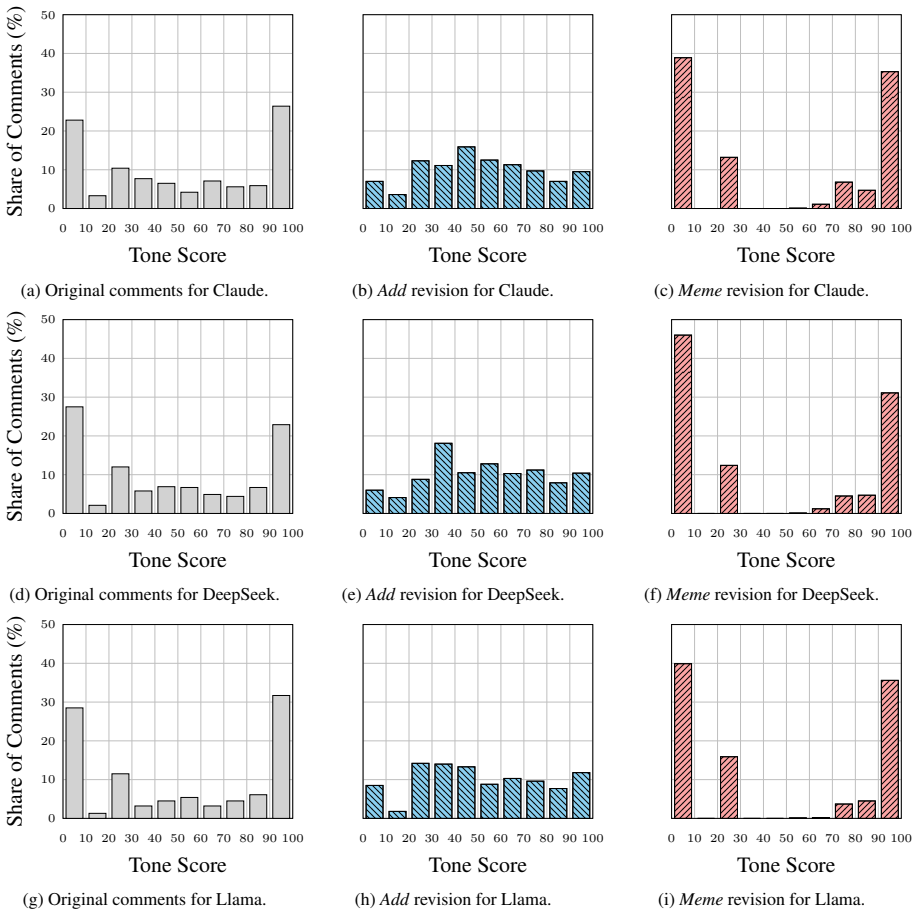
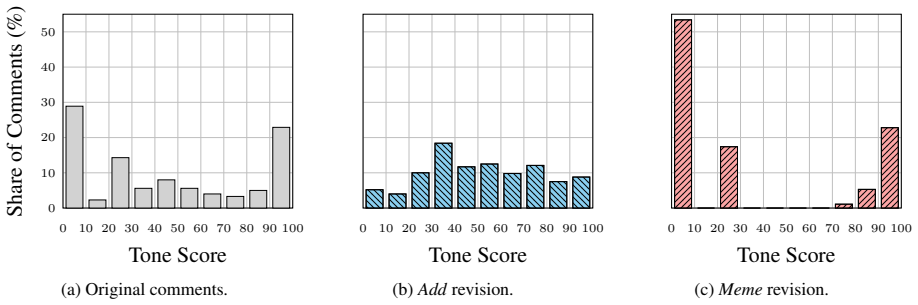
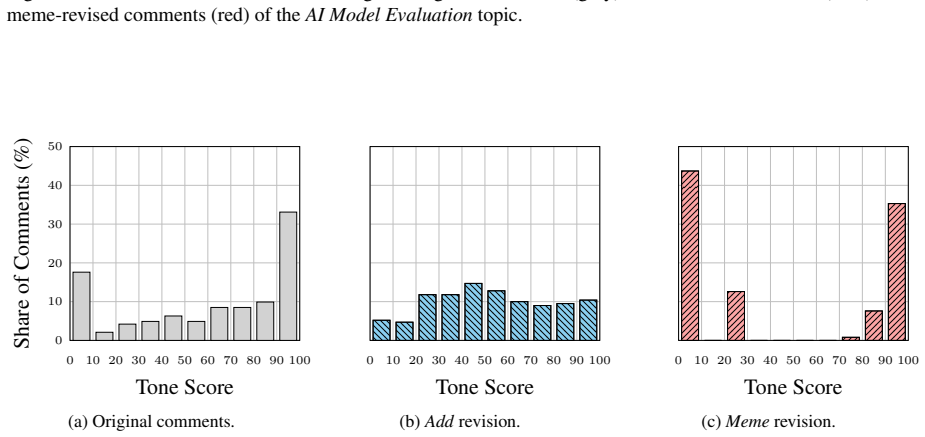
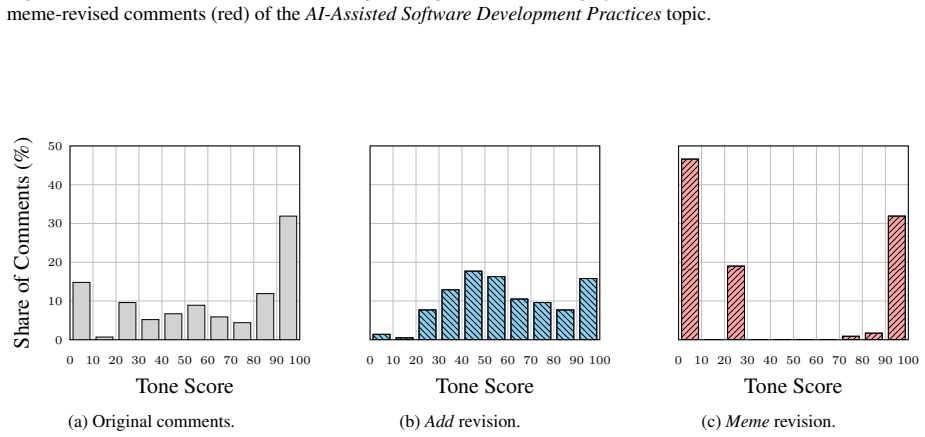
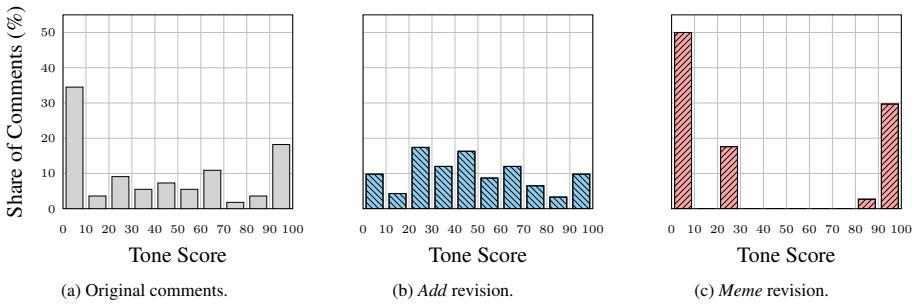
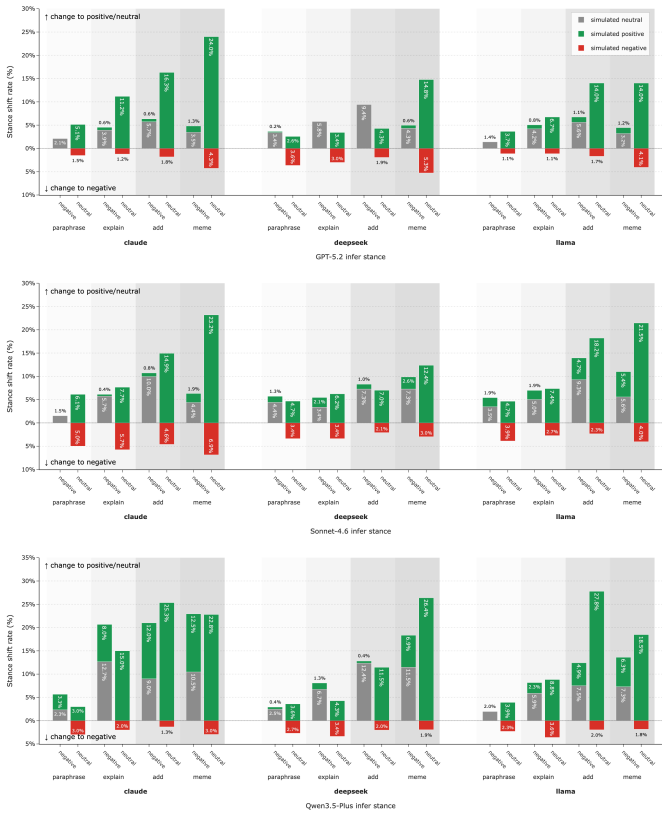
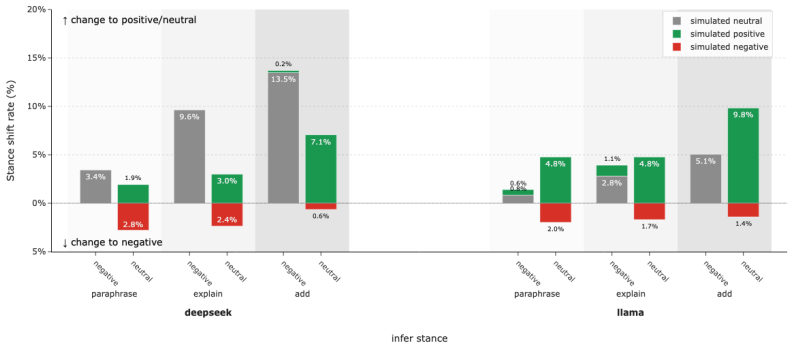
The paper establishes that applying controlled revision strategies to the conversational context leads to effective and robust stance transitions in LLM-based simulations of user stances, with similar results for text-only and multimodal approaches incorporating memes, and consistent across different polarization-preference mechanisms.
What carries the argument
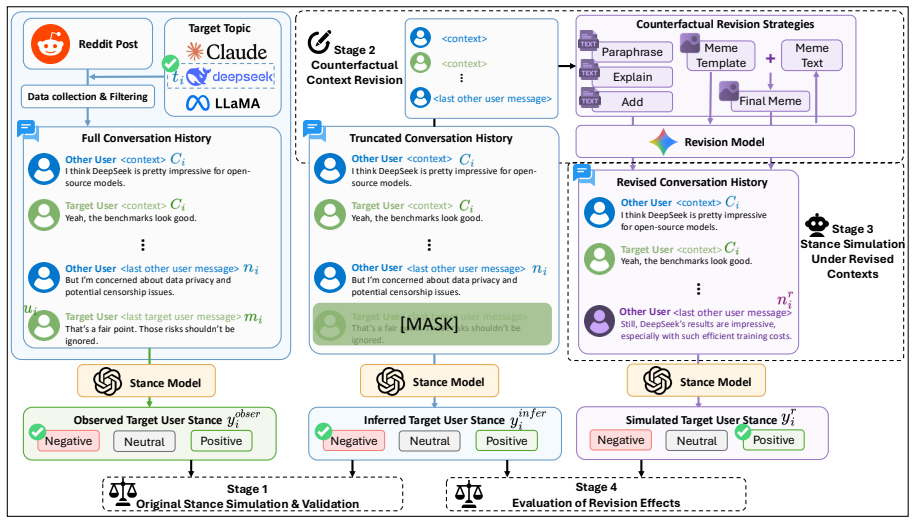
The counterfactual context revision framework, which infers initial stance, revises context, and re-simulates to measure shifts.
If this is right
- LLM simulations of stances are sensitive to context revisions even when changes are controlled.
- Multimodal context with memes produces stance transitions comparable to text revisions.
- The approach provides a way to audit context sensitivity in stance simulation.
- Using LLMs for online opinion dynamics carries risks due to this sensitivity.
Where Pith is reading between the lines
- If true, it implies that LLMs may prioritize recent context over any inferred user profile in simulations.
- This could extend to other simulation tasks like predicting responses in different domains.
- Researchers might need to develop methods to make simulations more invariant to minor context changes.
- It connects to broader issues of LLM robustness in social science applications.
Load-bearing premise
That the controlled revision strategies isolate context effects without introducing changes that legitimately alter the topic or the simulated user's underlying stance.
What would settle it
Finding that stance simulations remain unchanged despite the context revisions, or that the revisions actually change the topic in ways that justify stance shifts.
Figures


read the original abstract
Large language models are increasingly used to simulate social media users and infer how individuals may respond to online discussions. However, it remains unclear whether these simulations reflect precise user-specific beliefs or whether they are highly sensitive to semantically independent changes in conversational contexts. In this work, we study counterfactual context revision as a framework for auditing LLM-based stance simulation. Given an original online conversation, we first infer a target user's stance toward a specific topic. We then apply controlled revision strategies to the conversational context and simulate the user's stance again under the revised context. We compare text-only revision strategies with a multimodal one that incorporates meme-based context and evaluate two main effectiveness metrics, i.e., average directional stance shift and stance transition rate. The results reveal effective and robust stance transitions in both text-only and multimodal strategies across different polarization-preference mechanisms. Our study contributes an evaluation framework for understanding the context sensitivity of LLM-based stance simulation. More broadly, it highlights both the promise and risk of using LLMs to simulate online opinion dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a counterfactual context revision framework to audit LLM-based stance simulation in online discussions. Given original conversations, it infers a target user's stance on a topic, applies controlled text-only and multimodal (meme-inclusive) revisions to the context, re-simulates the stance, and evaluates two metrics: average directional stance shift and stance transition rate. Results are reported across different polarization-preference mechanisms, claiming effective and robust stance transitions in both revision types. The work positions this as an evaluation framework highlighting both promise and risks of LLM opinion dynamics simulations.
Significance. If the isolation of context effects is rigorously demonstrated, the framework would provide a useful auditing tool for assessing context sensitivity in LLM user simulations, an area of growing importance in computational social science and NLP. The explicit comparison of text-only versus multimodal strategies and the use of multiple polarization mechanisms are strengths that could support more reliable claims about robustness. The contribution lies in the auditing methodology rather than in new theoretical derivations or large-scale empirical benchmarks.
major comments (2)
- [§3] §3 (Revision Strategies): The description of the controlled revision strategies does not specify enforcement mechanisms (e.g., embedding similarity thresholds, human topic-consistency ratings, or pre/post fact checklists) to ensure revisions change only conversational framing while preserving the original topic and all stance-relevant facts. This is load-bearing for the central claim that measured shifts reflect context sensitivity rather than legitimate updates from altered content.
- [§4] §4 (Results): The reported effectiveness and robustness of stance transitions lack accompanying details on sample sizes, statistical significance tests, variance across runs, or ablation controls for the directional shift and transition rate metrics. Without these, the quantitative support for 'effective and robust' across mechanisms cannot be fully assessed.
minor comments (2)
- [Abstract] Abstract: The phrasing 'semantically independent changes' is used without a precise operational definition; a brief clarification of what counts as semantic independence would improve readability.
- [Related Work] Related Work: The discussion of prior stance detection and simulation work could benefit from explicit citations to recent benchmarks on LLM context sensitivity (e.g., in conversational AI or social simulation literature) to better situate the novelty of the auditing framework.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify key areas where additional methodological detail and statistical reporting will strengthen the manuscript. We respond to each major comment below and commit to revisions that address the concerns without altering the core claims or findings.
read point-by-point responses
-
Referee: [§3] §3 (Revision Strategies): The description of the controlled revision strategies does not specify enforcement mechanisms (e.g., embedding similarity thresholds, human topic-consistency ratings, or pre/post fact checklists) to ensure revisions change only conversational framing while preserving the original topic and all stance-relevant facts. This is load-bearing for the central claim that measured shifts reflect context sensitivity rather than legitimate updates from altered content.
Authors: We agree that the current description in §3 lacks sufficient detail on enforcement mechanisms, which is necessary to rigorously support the isolation of context effects. The manuscript relies on carefully engineered prompts intended to preserve topic and facts, but does not document verification procedures. We will revise §3 to add explicit enforcement mechanisms, including embedding-based similarity thresholds for topic preservation, author-conducted pre/post fact checklists applied to all revisions, and human topic-consistency ratings on a sampled subset. These additions will be presented as a dedicated paragraph on revision controls. revision: yes
-
Referee: [§4] §4 (Results): The reported effectiveness and robustness of stance transitions lack accompanying details on sample sizes, statistical significance tests, variance across runs, or ablation controls for the directional shift and transition rate metrics. Without these, the quantitative support for 'effective and robust' across mechanisms cannot be fully assessed.
Authors: We acknowledge that the results section would be strengthened by including the requested quantitative details to allow full evaluation of the metrics. We will expand §4 to report the sample sizes used in the experiments, results from statistical significance tests on the directional shift and transition rate metrics, variance or standard deviation across multiple runs, and descriptions of ablation controls (e.g., comparisons against non-contextual baselines). These elements will be integrated into the existing result tables and accompanying text. revision: yes
Circularity Check
No circularity; empirical evaluation framework is self-contained
full rationale
The paper describes an empirical auditing method that infers user stances from conversations, applies controlled textual or multimodal revisions to context, and measures resulting shifts in LLM-simulated stances via directional shift and transition rate metrics. No equations, parameter fitting, derivations, or predictions appear. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes that reduce the central claims to prior inputs by construction. The evaluation relies on external LLM behavior and falsifiable metrics that are independent of the revision inputs, satisfying the criteria for a non-circular experimental study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In Proceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 337–371
Using large language models to simulate mul- tiple humans and replicate human subject studies. In Proceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 337–371. PMLR. Anthropic. 2025. Introducing claude haiku 4.5. Model release announcement. Official release page states API use a...
2025
-
[2]
Out of one, many: Using language mod- els to simulate human samples.Political Analysis, 31(3):337–351. Ryan L. Boyd, Ashwini Ashokkumar, Sarah Seraj, and James W. Pennebaker. 2022.The Development and Psychometric Properties of LIWC-22. The University of Texas at Austin, Austin, TX. Yun-Shiuan Chuang, Agam Goyal, Nikunj Harlalka, Siddharth Suresh, Robert H...
2022
-
[3]
Fabrizio Gilardi, Meysam Alizadeh, and Maël Kubli
Large language models empowered agent- based modeling and simulation: a survey and per- spectives.Humanities and Social Sciences Commu- nications, 11:1259. Fabrizio Gilardi, Meysam Alizadeh, and Maël Kubli
-
[4]
ChatGPT outperforms crowd workers for text-annotation tasks.Proceedings of the National Academy of Sciences, 120(30):e2305016120. Google. 2025. Gemini models. Google AI for Devel- opers documentation. Lists gemini-3-flash-preview, latest update December 2025, knowledge cutoff Jan- uary 2025; accessed 2026-05-26. Maarten Grootendorst. 2022. BERTopic: Neura...
Pith/arXiv arXiv 2025
-
[5]
Learning the difference that makes a differ- ence with counterfactually-augmented data.arXiv preprint arXiv:1909.12434. Douwe Kiela, Hamed Firooz, Aravind Mohan, Vedanuj Goswami, Amanpreet Singh, Pratik Ringshia, and Davide Testuggine. 2020. The hateful memes chal- lenge: Detecting hate speech in multimodal memes. InAdvances in Neural Information Processi...
arXiv 1909
-
[6]
Zhongyi Qiu, Hanjia Lyu, Wei Xiong, and Jiebo Luo
Excitements and concerns in the post-chatgpt era: Deciphering public perception of ai through social media analysis.Telematics and Informatics, 92:102158. Zhongyi Qiu, Hanjia Lyu, Wei Xiong, and Jiebo Luo
-
[7]
Can llms simulate social media engagement? a study on action-guided response generation.arXiv preprint arXiv:2502.12073. Qwen Team. 2026. Qwen3.5-397B-A17B. Hugging Face model card. Official model card; states that Qwen3.5-Plus is the hosted version corresponding to Qwen3.5-397B-A17B; accessed 2026-05-26. Paul Röttger, Valentin Hofmann, Valentina Pyatkin,...
arXiv 2026
-
[8]
Analyze the concerns , objections , or negative signals expressed by the target user
-
[9]
Identify opportunities where additional arguments could constructively address or counter those concerns
-
[10]
Revise ONLY the last message so that it : - adds ** new but reasonable arguments ** not previously mentioned in the conversation - remains factually accurate ( no false claims ) - stays consistent with the conversational context - responds directly to the target user's concerns - uses a tone that is respectful , clear , and non - manipulative - is aimed a...
-
[11]
You may introduce new reasoning or perspectives , but you must NOT introduce unverifiable facts
-
[12]
Do NOT modify earlier messages
-
[13]
Only output the revised message
Do NOT contradict anything stated earlier in the conversation . Only output the revised message . Do not include anything else . < conversation transcript below > { conv_transcript } < last message below > { last_message } G.4 Meme Prompt Prompt 4: Meme Text Generation You will be given a multi - party conversation about target_model } and a meme template...
-
[14]
Read the conversation to understand the context and the concerns of the TARGET USER
-
[15]
Act as if you are the last [ OTHER USER ] and come up with a reply to change the TARGET USER's stance to positive
-
[16]
Adapt that reply into concise , punchy meme text format that fits the structure and humor style of the given template
-
[17]
top_text
Based on the meme template's structure , determine the appropriate text positions ( e . g . " top_text " , " bottom_text " , " panel_1 " , " panel_2 " , " caption " , " left " , " right " , etc .) and output a JSON object where each key represents a text position in the template and each value is the corresponding meme text . - Use position names that nat...
-
[18]
stance
Do not include any explanation or extra output , only the JSON . < conversation transcript below > { conv_transcript } Prompt 5: Meme Generation Add the text to the meme template according to the following instructions : f "{ meme_context } Only add the text at the specified location according to the instructions ; DO NOT change anything else in the image...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.