PromptPrint: Behavioral Biometrics Through Natural Language Prompting in LLMs
Pith reviewed 2026-06-28 00:57 UTC · model grok-4.3
The pith
Short prompts to LLMs carry stable lexical signals that identify individual users.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
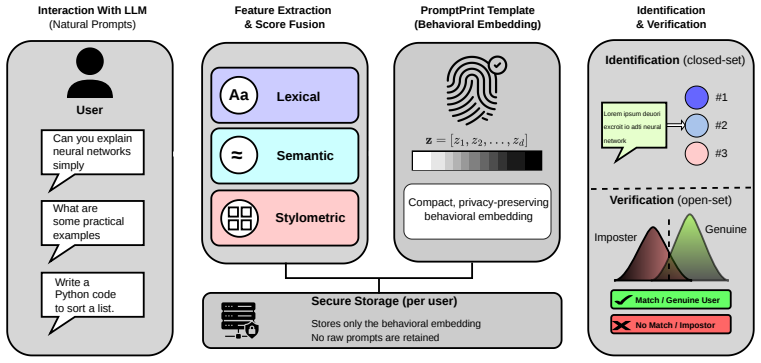
Prompt-based identity, defined as the hypothesis that a user's habitual vocabulary, syntax, and discourse patterns in short LLM prompts form a learnable behavioral biometric, is established through strong identification performance on a dataset of 20,680 real prompts from 1,034 users, with lexical features proving most effective.
What carries the argument
Lexical stability hypothesis, the claim that identity is primarily encoded in surface-level word choice rather than abstract intent, which is supported by lexical representations outperforming semantic encoders.
If this is right
- Lexical representations significantly outperform semantic encoders for user identification.
- Stylometric features show users are highly distinctive across the population yet inconsistent across contexts.
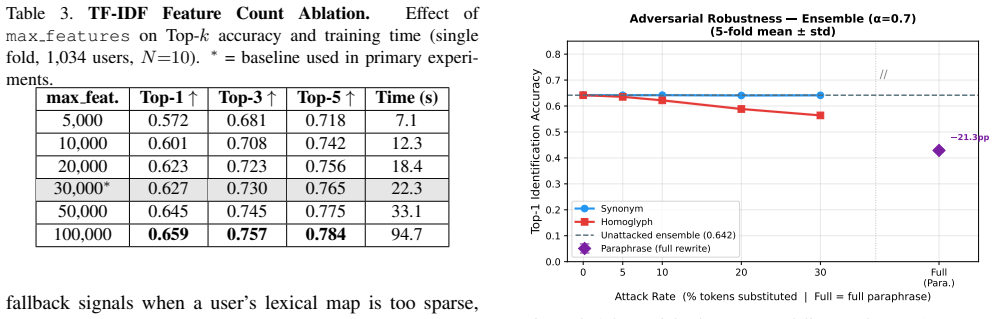
- Identity signals are robust to minor lexical perturbations but degrade under semantic paraphrasing.
- Prompt-based identity enables strong identification performance at scale.
Where Pith is reading between the lines
- This approach could enable new forms of user authentication or tracking in LLM platforms based on prompt history.
- Privacy concerns arise if prompt data can be used to link anonymous interactions to individuals.
- Future work might explore whether task-specific prompts reduce the biometric signal compared to free-form ones.
Load-bearing premise
The collected prompts represent natural, habitual user behavior from distinct individuals whose lexical patterns remain stable enough to serve as an identifiable biometric signal independent of task context or data collection artifacts.
What would settle it
Demonstrating that identification accuracy drops to chance levels when the same users provide prompts in new contexts or after paraphrasing would falsify the viability of prompt-based identity as a biometric.
Figures

read the original abstract
Authorship attribution research has traditionally focused on long-form, expressive texts; however, interactions with large language models (LLMs) are typically brief and task-driven prompts. This raises a fundamental question: do such prompts contain a stable, author-identifiable, and distinctive signal? We introduce PromptPrint, a systematic study of prompt-based identity, the hypothesis that a user's habitual vocabulary, syntax, and discourse patterns form a learnable behavioral biometric. Using 20,680 real prompts from 1,034 users, we establish three key findings. First, lexical representations significantly outperform semantic encoders, supporting the "lexical stability hypothesis": identity is primarily encoded in surface-level word choice rather than abstract intent. Second, stylometric features exhibit a "uniqueness-consistency paradox": users are highly distinctive across the population, yet behaviorally inconsistent across contexts. Third, adversarial analysis reveals a clear vulnerability spectrum: identity signals are robust to minor lexical perturbations but degrade substantially under semantic paraphrasing. Overall, our results demonstrate strong identification performance at scale, establishing prompt-based identity as a viable behavioral biometric. This work introduces a new perspective on user modeling in LLM interactions, with important implications for security and privacy. Data and code will be released upon the acceptance of our work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PromptPrint as a study of prompt-based identity, hypothesizing that users' brief, task-driven LLM prompts encode stable, author-identifiable lexical and stylometric signals usable as behavioral biometrics. It reports results from 20,680 real prompts by 1,034 users supporting three findings: lexical representations outperform semantic encoders (lexical stability hypothesis); stylometric features show a uniqueness-consistency paradox (high distinctiveness but low cross-context consistency); and identity signals are robust to minor perturbations but vulnerable to semantic paraphrasing. The work concludes that these results establish strong identification performance at scale and prompt-based identity as a viable biometric, with implications for security and privacy.
Significance. If the empirical claims are supported by properly documented cross-context evaluation and statistical validation, the work would be significant as the first large-scale demonstration of behavioral biometrics in short, task-driven LLM prompts, extending authorship attribution beyond long-form text and highlighting both opportunities and risks for user modeling in LLM platforms. The planned release of data and code is a positive contribution to reproducibility.
major comments (3)
- [Abstract] Abstract: The three key findings are asserted without any reported performance metrics (e.g., accuracy, F1, AUC), baselines, statistical tests, or evaluation protocol details. This absence is load-bearing because the central claim of 'strong identification performance at scale' cannot be assessed or reproduced from the provided information.
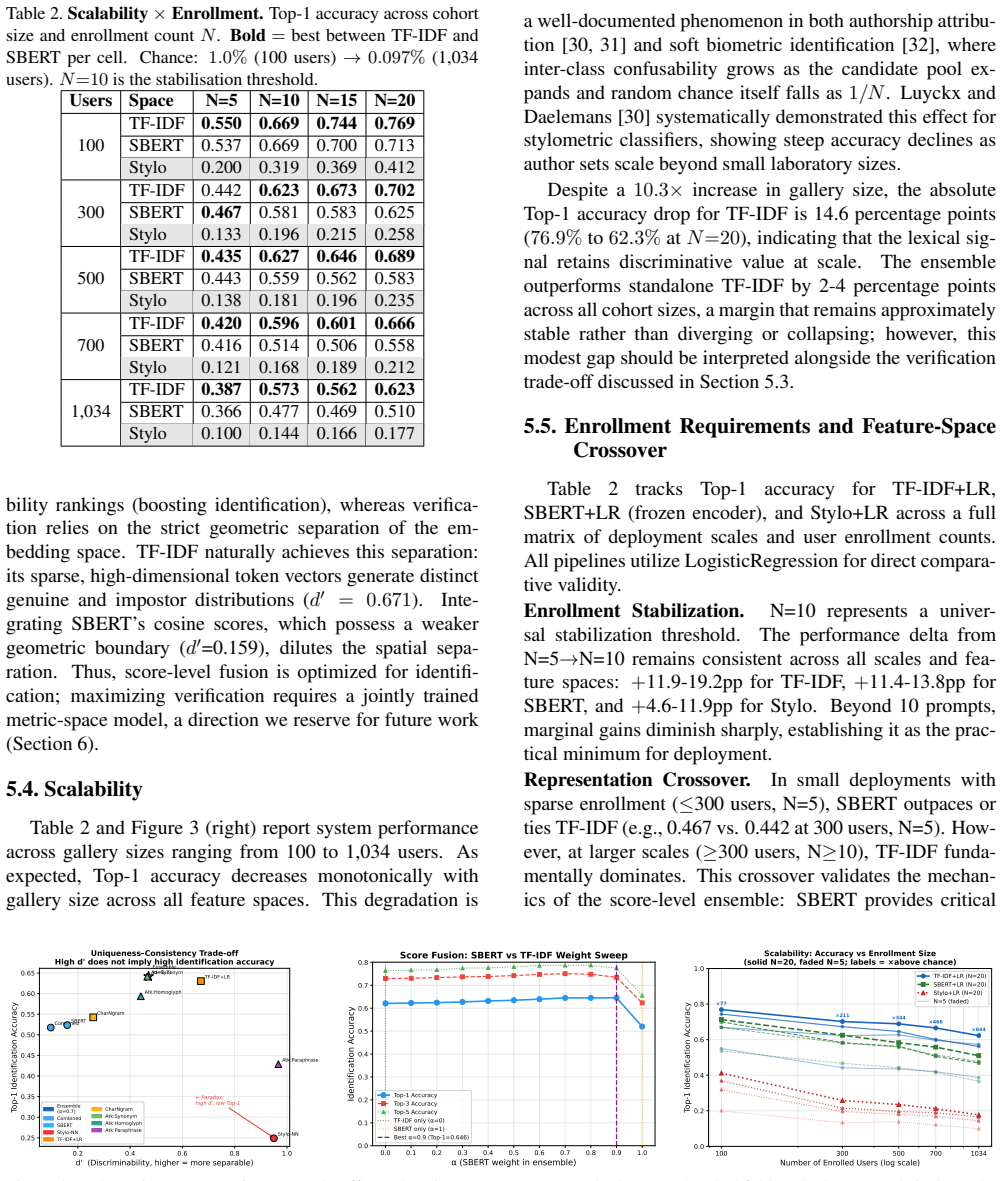
- [Abstract] Abstract (data and findings paragraph): No description is given of how the 20,680 prompts were collected, whether they are balanced across tasks/contexts, how user identities were verified as distinct, or whether identification was evaluated with cross-context splits versus within-context splits. This directly bears on the stress-test concern that task/context dependence may inflate accuracy beyond stable user biometrics, especially given the paper's own report of the uniqueness-consistency paradox.
- [Abstract] Abstract: The uniqueness-consistency paradox is presented as a finding yet the conclusion asserts prompt-based identity as a 'viable behavioral biometric.' The inconsistency across contexts appears to undermine the stability required for biometric use; the manuscript must clarify how this paradox is reconciled with the viability claim, including any quantitative consistency metrics.
minor comments (1)
- [Abstract] The abstract states 'Data and code will be released upon the acceptance of our work' but provides no link or repository placeholder for reviewers to inspect during review.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which highlight important areas for improving the clarity and completeness of our abstract. We agree that several details are missing from the abstract and will make revisions to address these concerns while preserving the core contributions of the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: The three key findings are asserted without any reported performance metrics (e.g., accuracy, F1, AUC), baselines, statistical tests, or evaluation protocol details. This absence is load-bearing because the central claim of 'strong identification performance at scale' cannot be assessed or reproduced from the provided information.
Authors: We agree with the referee that the abstract should include key performance metrics to substantiate the claims. The full manuscript reports detailed results including accuracy, F1, and AUC from our identification experiments, along with baselines and statistical validation. We will revise the abstract to include representative metrics and a brief mention of the evaluation protocol to make the claims assessable. revision: yes
-
Referee: [Abstract] Abstract (data and findings paragraph): No description is given of how the 20,680 prompts were collected, whether they are balanced across tasks/contexts, how user identities were verified as distinct, or whether identification was evaluated with cross-context splits versus within-context splits. This directly bears on the stress-test concern that task/context dependence may inflate accuracy beyond stable user biometrics, especially given the paper's own report of the uniqueness-consistency paradox.
Authors: The referee correctly identifies that the abstract omits these important details. The manuscript describes the dataset as real prompts from users, with collection details in the Data section, and evaluations include both within and cross-context analyses to address the paradox. We will expand the abstract to briefly describe the data source, note the use of cross-context splits, and mention user identity verification to mitigate concerns about inflation of performance. revision: yes
-
Referee: [Abstract] Abstract: The uniqueness-consistency paradox is presented as a finding yet the conclusion asserts prompt-based identity as a 'viable behavioral biometric.' The inconsistency across contexts appears to undermine the stability required for biometric use; the manuscript must clarify how this paradox is reconciled with the viability claim, including any quantitative consistency metrics.
Authors: We appreciate this point and will clarify the reconciliation in the revised abstract. The paradox highlights that while users are distinctive, consistency varies by context; however, our results show sufficient stability in many scenarios for biometric viability, supported by quantitative metrics on consistency (e.g., intra-user similarity scores across contexts). We will add these metrics and explain that viability holds particularly for applications with contextual controls or when combined with other signals. revision: yes
Circularity Check
Empirical study with no circular derivations or load-bearing self-citations
full rationale
This is a purely empirical paper reporting identification results from analysis of 20,680 collected user prompts. No equations, theoretical derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description. The central claims rest on direct data analysis outcomes rather than any reduction to inputs by construction, satisfying the criteria for a self-contained empirical study with no significant circularity.
Axiom & Free-Parameter Ledger
invented entities (1)
-
prompt-based identity
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey of modern authorship attribution methods,
E. Stamatatos, “A survey of modern authorship attribution methods,”Journal of the American Society for information Science and Technology, vol. 60, no. 3, pp. 538–556, 2009
2009
-
[2]
Authorship attri- bution in the wild,
M. Koppel, J. Schler, and S. Argamon, “Authorship attri- bution in the wild,”Language Resources and Evaluation, vol. 45, no. 1, pp. 83–94, 2011
2011
-
[3]
Authorship at- tribution using probabilistic context-free grammars,
S. Raghavan, A. Kovashka, and R. Mooney, “Authorship at- tribution using probabilistic context-free grammars,” inPro- ceedings of the ACL 2010 conference short papers, pp. 38– 42, 2010
2010
-
[4]
Bertaa: Bert fine-tuning for authorship attribution,
M. Fabien, E. Villatoro-Tello, P. Motlicek, and S. Parida, “Bertaa: Bert fine-tuning for authorship attribution,” inPro- ceedings of the 17th International Conference on Natural Language Processing (ICON), pp. 127–137, 2020
2020
-
[5]
Authorship attribution in the era of llms: Problems,
B. Huang, C. Chen, and K. Shu, “Authorship attribution in the era of llms: Problems,”Methodologies, and Challenges. doi, vol. 10, 2025
2025
-
[6]
Learning universal authorship representations,
R. A. Rivera-Soto, O. E. Miano, J. Ordonez, B. Y . Chen, A. Khan, M. Bishop, and N. Andrews, “Learning universal authorship representations,” inProceedings of the 2021 Con- ference on Empirical Methods in Natural Language Process- ing, pp. 913–919, 2021
2021
-
[7]
Authentication via keystroke dy- namics,
F. Monrose and A. Rubin, “Authentication via keystroke dy- namics,” inProceedings of the 4th ACM Conference on Com- puter and Communications Security, pp. 48–56, 1997
1997
-
[8]
On continuous user au- thentication via typing behavior,
J. Roth, X. Liu, and D. Metaxas, “On continuous user au- thentication via typing behavior,”IEEE Transactions on Im- age Processing, vol. 23, no. 10, pp. 4611–4624, 2014
2014
-
[9]
A new biometric technology based on mouse dynamics,
A. A. E. Ahmed and I. Traore, “A new biometric technology based on mouse dynamics,”IEEE Transactions on depend- able and secure computing, vol. 4, no. 3, pp. 165–179, 2007
2007
-
[10]
Touchalytics: On the applicability of touchscreen input as a behavioral biometric for continuous authentication,
M. Frank, R. Biedert, E. Ma, I. Martinovic, and D. Song, “Touchalytics: On the applicability of touchscreen input as a behavioral biometric for continuous authentication,”IEEE transactions on information forensics and security, vol. 8, no. 1, pp. 136–148, 2012
2012
-
[11]
Gait recognition using linear time normalization,
N. V . Boulgouris, K. N. Plataniotis, and D. Hatzinakos, “Gait recognition using linear time normalization,”Pattern Recog- nition, vol. 39, no. 5, pp. 969–979, 2006
2006
-
[12]
Universal and transferable adversar- ial attacks on aligned language models,
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversar- ial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
Pith/arXiv arXiv 2023
-
[13]
Ignore previous prompt: At- tack techniques for language models,
F. Perez and I. Ribeiro, “Ignore previous prompt: At- tack techniques for language models,”arXiv preprint arXiv:2211.09527, 2022
Pith/arXiv arXiv 2022
-
[14]
Extracting training data from large language models,
N. Carlini, F. Tramer, E. Wallace, M. Jagielski, A. Herbert- V oss, K. Lee, A. Roberts, T. Brown, D. Song, U. Erlingsson, et al., “Extracting training data from large language models,” in30th USENIX security symposium (USENIX Security 21), pp. 2633–2650, 2021
2021
-
[15]
Robust de-anonymization of large sparse datasets,
A. Narayanan and V . Shmatikov, “Robust de-anonymization of large sparse datasets,” in2008 IEEE Symposium on Secu- rity and Privacy (sp 2008), pp. 111–125, IEEE, 2008
2008
-
[16]
How unique is your web browser?,
P. Eckersley, “How unique is your web browser?,” inInterna- tional Symposium on Privacy Enhancing Technologies Sym- posium, pp. 1–18, Springer, 2010
2010
-
[17]
Beyond memorization: Violating privacy via inference with large language models,
R. Staab, M. Vero, M. Balunovi ´c, and M. Vechev, “Beyond memorization: Violating privacy via inference with large language models,”arXiv preprint arXiv:2310.07298, 2023
arXiv 2023
-
[18]
On the state of the art in authorship attribution and authorship verification,
J. Tyo, B. Dhingra, and Z. C. Lipton, “On the state of the art in authorship attribution and authorship verification,”arXiv preprint arXiv:2209.06869, 2022
arXiv 2022
-
[19]
Same author or just same topic? towards content-independent style rep- resentations,
A. Wegmann, M. Schraagen, and D. Nguyen, “Same author or just same topic? towards content-independent style rep- resentations,” inProceedings of the 7th Workshop on Repre- sentation Learning for NLP, pp. 249–268, 2022
2022
-
[20]
Wildchat: 1m chatgpt interaction logs in the wild,
W. Zhao, X. Ren, J. Hessel, C. Cardie, Y . Choi, and Y . Deng, “Wildchat: 1m chatgpt interaction logs in the wild,”arXiv preprint arXiv:2405.01470, 2024
Pith/arXiv arXiv 2024
-
[21]
A statistical interpretation of term speci- ficity and its application in retrieval,
K. Sparck Jones, “A statistical interpretation of term speci- ficity and its application in retrieval,”Journal of documenta- tion, vol. 28, no. 1, pp. 11–21, 1972
1972
-
[22]
Text embeddings by weakly-supervised contrastive pre-training,
L. Wang, N. Yang, X. Huang, B. Jiao, L. Yang, D. Jiang, R. Majumder, and F. Wei, “Text embeddings by weakly-supervised contrastive pre-training,”arXiv preprint arXiv:2212.03533, 2022
Pith/arXiv arXiv 2022
-
[23]
S. Bird, E. Klein, and E. Loper,Natural language process- ing with Python: analyzing text with the natural language toolkit. ” O’Reilly Media, Inc.”, 2009
2009
-
[24]
Catastrophic interference in connectionist networks: The sequential learning problem,
M. McCloskey and N. J. Cohen, “Catastrophic interference in connectionist networks: The sequential learning problem,” inPsychology of learning and motivation, vol. 24, pp. 109– 165, Elsevier, 1989
1989
-
[25]
Decoupled weight decay regu- larization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regu- larization,”arXiv preprint arXiv:1711.05101, 2017
Pith/arXiv arXiv 2017
-
[26]
Liblinear: A library for large linear classification,
R.-E. Fan, K.-W. Chang, C.-J. Hsieh, X.-R. Wang, and C.- J. Lin, “Liblinear: A library for large linear classification,” the Journal of machine Learning research, vol. 9, pp. 1871– 1874, 2008
2008
-
[27]
Fellbaum,WordNet: An electronic lexical database
C. Fellbaum,WordNet: An electronic lexical database. MIT press, 1998
1998
-
[28]
Pegasus: Pre- training with extracted gap-sentences for abstractive summa- rization,
J. Zhang, Y . Zhao, M. Saleh, and P. Liu, “Pegasus: Pre- training with extracted gap-sentences for abstractive summa- rization,” inInternational conference on machine learning, pp. 11328–11339, PMLR, 2020
2020
-
[29]
Mining the blogosphere: Age, gender and the varieties of self-expression,
S. Argamon, M. Koppel, J. W. Pennebaker, and J. Schler, “Mining the blogosphere: Age, gender and the varieties of self-expression,”First Monday, 2007
2007
-
[30]
The effect of author set size and data size in authorship attribution,
K. Luyckx and W. Daelemans, “The effect of author set size and data size in authorship attribution,”Literary and linguis- tic Computing, vol. 26, no. 1, pp. 35–55, 2011
2011
-
[31]
Reduce & at- tribute: Two-step authorship attribution for large-scale prob- lems,
M. Tschuggnall, B. Murauer, and G. Specht, “Reduce & at- tribute: Two-step authorship attribution for large-scale prob- lems,” inProceedings of the 23rd Conference on Computa- tional Natural Language Learning (CoNLL), pp. 951–960, 2019
2019
-
[32]
What else does your biometric data reveal? a survey on soft biometrics,
A. Dantcheva, P. Elia, and A. Ross, “What else does your biometric data reveal? a survey on soft biometrics,”IEEE Transactions on Information Forensics and Security, vol. 11, no. 3, pp. 441–467, 2015
2015
-
[33]
Inertial sensor-based gait recog- nition: A review,
S. Sprager and M. B. Juric, “Inertial sensor-based gait recog- nition: A review,”Sensors, vol. 15, no. 9, pp. 22089–22127, 2015
2015
-
[34]
Active authentication on mobile devices via stylometry, application usage, web browsing, and gps location,
L. Fridman, S. Weber, R. Greenstadt, and M. Kam, “Active authentication on mobile devices via stylometry, application usage, web browsing, and gps location,”IEEE Systems Jour- nal, vol. 11, no. 2, pp. 513–521, 2016
2016
-
[35]
Isolating authorship from content with seman- tic embeddings and contrastive learning,
J. Huertas-Tato, A. Gir ´on-Jim´enez, A. Mart ´ın, and D. Ca- macho, “Isolating authorship from content with seman- tic embeddings and contrastive learning,”arXiv preprint arXiv:2411.18472, 2024
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.