VideoSEG-O3: A Multi-turn Reinforcement Learning Framework for Reasoning Video Object Segmentation
Pith reviewed 2026-06-27 22:55 UTC · model grok-4.3
The pith
VideoSEG-O3 introduces the first multi-turn reinforcement learning framework for reasoning video object segmentation that iteratively refines outputs by selecting critical time intervals and keyframes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
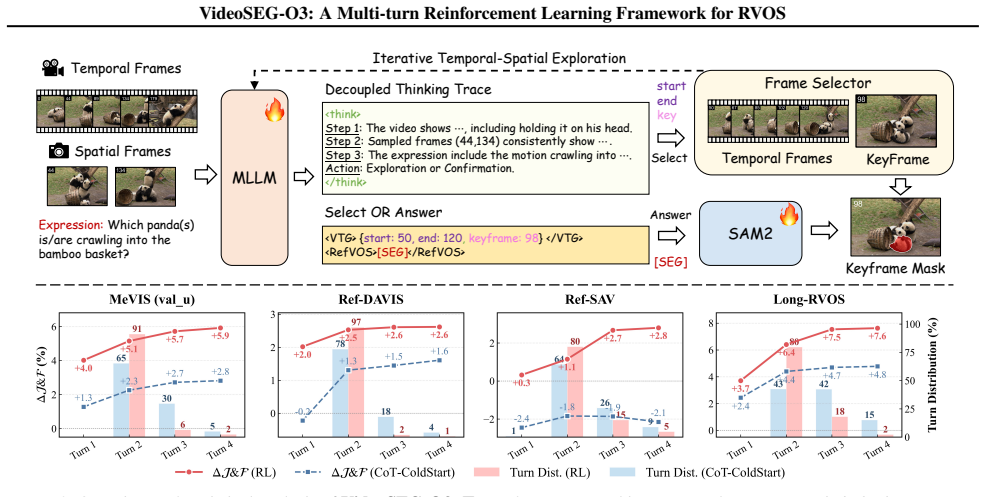
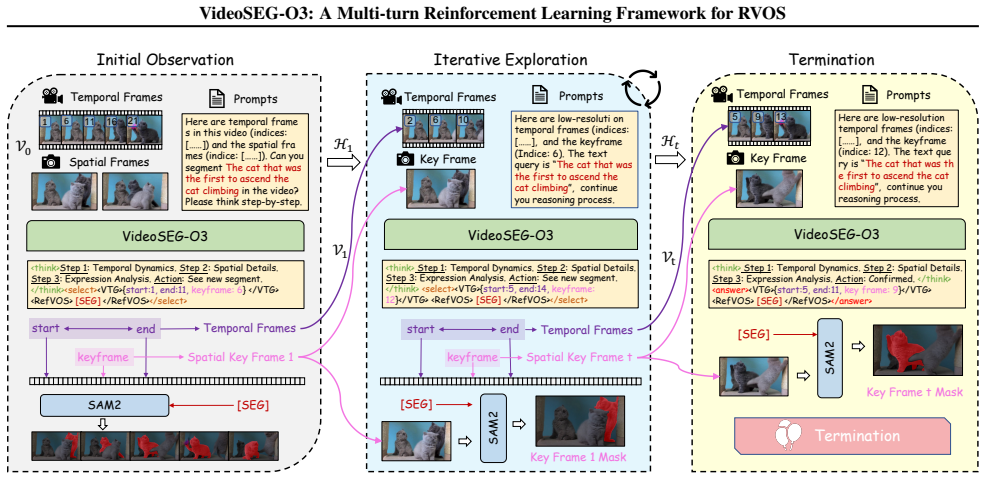
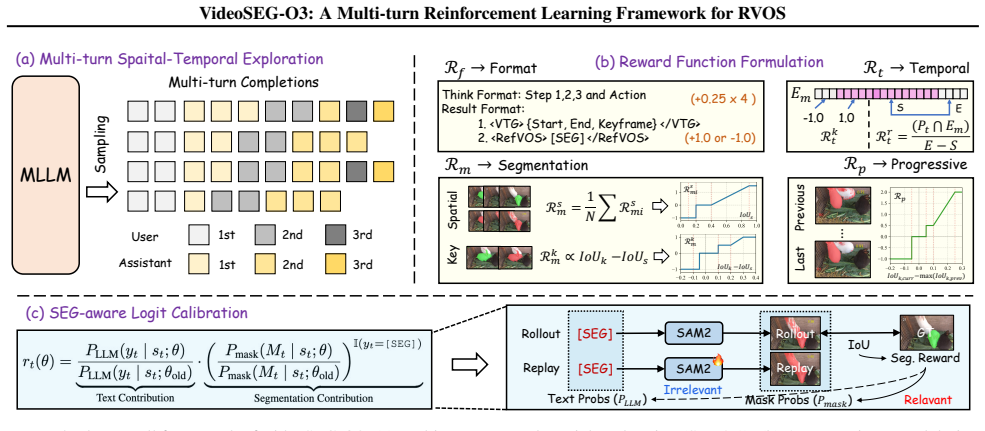
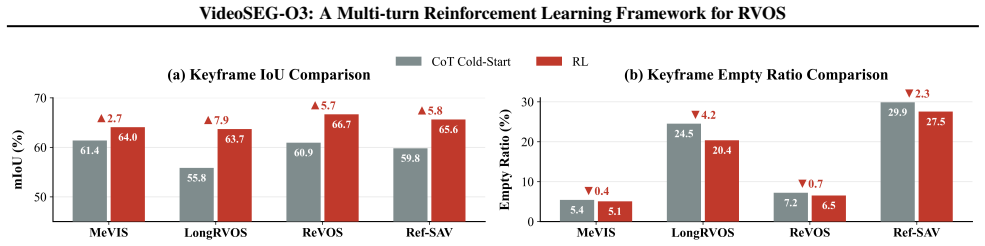
VideoSEG-O3 is the first multi-turn reinforcement learning framework for RVOS that emulates the human coarse-to-fine cognitive process through a multi-turn temporal-spatial chain-of-thought, SEG-aware logit calibration that integrates pixel-wise segmentation feedback into token-level logits, a decoupled thinking trace that decomposes reasoning into temporal, spatial, and linguistic dimensions, and the VTS-CoT cold-start dataset of comprehensive reasoning trajectories.
What carries the argument
multi-turn temporal-spatial chain-of-thought combined with SEG-aware logit calibration, which lets the policy adjust token probabilities using direct pixel-wise segmentation feedback rather than text-only signals.
If this is right
- The policy can now perceive and act on segmentation quality beyond the text probability of the [SEG] token during reinforcement learning.
- Reasoning trajectories decompose hierarchically into temporal, spatial, and linguistic components via the decoupled thinking trace.
- Training can begin from a specialized cold-start dataset VTS-CoT that supplies complete multi-turn reasoning paths.
- The framework supports active acquisition of visual evidence in long or intricate videos rather than relying solely on fixed initial inputs.
Where Pith is reading between the lines
- The same iterative selection of intervals and keyframes could extend to other video tasks that require progressive refinement of spatial or temporal focus.
- If the logit calibration generalizes, similar feedback loops might improve reinforcement learning in domains where output quality can be measured at a finer granularity than the action tokens themselves.
- The decoupled trace structure suggests a template for making chain-of-thought reasoning more interpretable by separating concerns that are currently entangled in single-pass models.
Load-bearing premise
That feeding pixel-wise segmentation quality back into token-level logits through SEG-aware logit calibration will let the reinforcement learning policy improve its decisions on the basis of actual segmentation accuracy.
What would settle it
A controlled comparison on long videos with ambiguous references showing that a single-turn baseline achieves equal or higher segmentation accuracy without the iterative interval and keyframe selection steps.
Figures

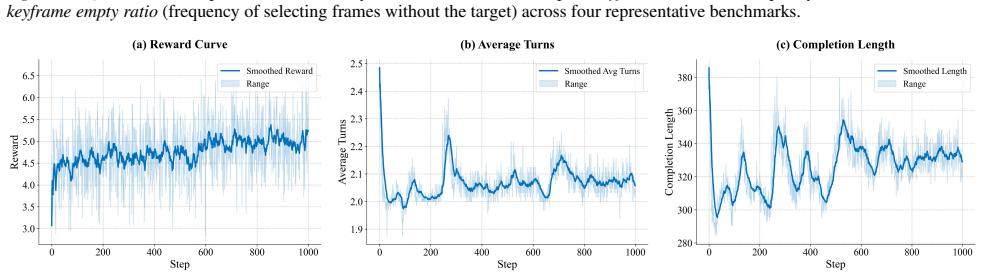

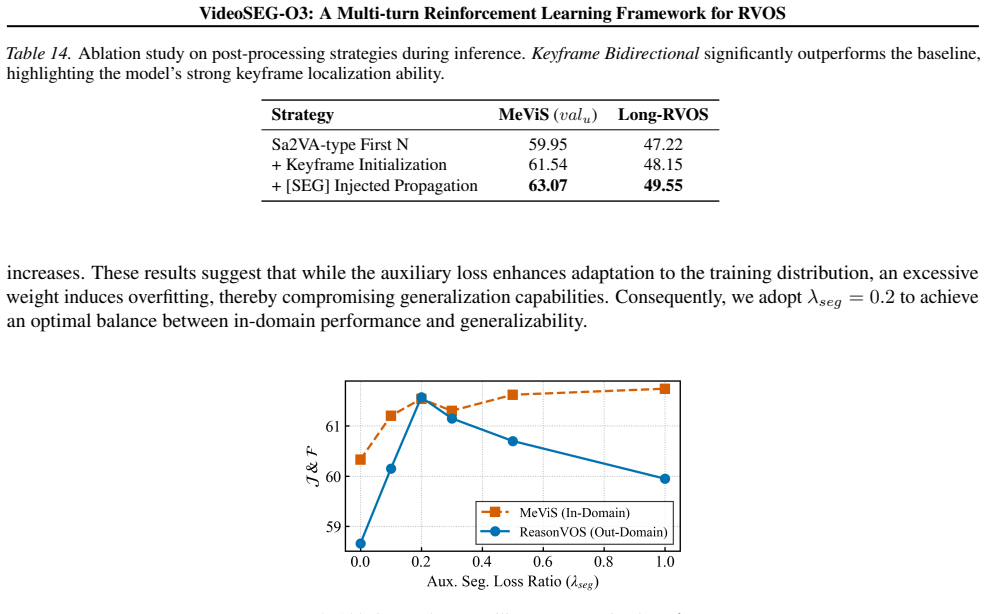



read the original abstract
Reasoning Video Object Segmentation (RVOS) demands a sophisticated integration of temporal dynamics, spatial details, and linguistic reasoning to achieve precise pixel-level localization. Existing methods are limited to reasoning over fixed initial inputs and lack the capacity to actively acquire further visual evidence, which is often essential for resolving complex references in long or intricate videos. To address this, we propose \textbf{VideoSEG-O3}, the first multi-turn reinforcement learning framework for RVOS that emulates the human \textit{``coarse-to-fine''} cognitive process. It employs a \textit{multi-turn temporal-spatial chain-of-thought} to capture fine-grained details by iteratively pinpointing critical intervals and keyframes. Additionally, to enable the policy to perceive segmentation quality beyond mere text probability of \texttt{[SEG]} during the RL stage, we introduce \textit{SEG-aware logit calibration}, which integrates pixel-wise segmentation feedback directly into the token-level logits. Furthermore, we design a \textit{decoupled thinking trace} to hierarchically decompose the reasoning process into temporal, spatial, and linguistic dimensions, and construct \textbf{VTS-CoT}, a specialized cold-start dataset featuring comprehensive reasoning trajectories. The code and models will be released at https://github.com/Dmmm1997/VideoSEG-O3.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VideoSEG-O3 as the first multi-turn reinforcement learning framework for Reasoning Video Object Segmentation (RVOS). It introduces a multi-turn temporal-spatial chain-of-thought process to emulate human coarse-to-fine cognition by iteratively identifying critical intervals and keyframes in videos. Additional contributions include SEG-aware logit calibration to incorporate pixel-wise segmentation feedback into token-level logits during RL training, a decoupled thinking trace that decomposes reasoning hierarchically across temporal, spatial, and linguistic dimensions, and the VTS-CoT cold-start dataset containing comprehensive reasoning trajectories. The work targets limitations in prior RVOS methods that rely on fixed initial inputs without active visual evidence acquisition.
Significance. If validated, the framework could meaningfully advance RVOS research by enabling iterative, evidence-seeking reasoning in complex or long videos, moving beyond single-pass approaches. The SEG-aware logit calibration and decoupled thinking trace offer potentially reusable ideas for integrating dense visual signals into RL policies for vision-language tasks, and the VTS-CoT dataset could serve as a useful resource for training multi-turn models. Code and model release supports reproducibility.
major comments (3)
- [Abstract] Abstract/Contributions paragraph: the central claim that SEG-aware logit calibration 'integrates pixel-wise segmentation feedback directly into the token-level logits' to allow perception of segmentation quality beyond [SEG] text probability is load-bearing for the RL stage, yet the abstract (and any corresponding method description) provides no formulation, pseudocode, or derivation showing how the calibration is computed or why it avoids reducing to a fitted parameter from the same data.
- [Method] Method section on multi-turn temporal-spatial chain-of-thought: the description of iteratively pinpointing intervals and keyframes is presented without an explicit algorithm, state transition, or reward formulation; this makes it impossible to verify whether the multi-turn process is internally consistent or reduces to standard single-turn RL with added turns.
- [Experiments] Experiments (or lack thereof): the abstract and provided text contain no quantitative results, ablation studies, or baseline comparisons; without these, the effectiveness claims for the new components cannot be assessed and the soundness of the overall contribution remains unverified.
minor comments (2)
- [Abstract] Abstract: the phrase 'the first multi-turn reinforcement learning framework' should be supported by an explicit literature comparison in §2 rather than asserted.
- [Abstract] Notation: 'VTS-CoT' and 'decoupled thinking trace' are introduced without immediate expansion or reference to their definitions in later sections.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and additions.
read point-by-point responses
-
Referee: [Abstract] Abstract/Contributions paragraph: the central claim that SEG-aware logit calibration 'integrates pixel-wise segmentation feedback directly into the token-level logits' to allow perception of segmentation quality beyond [SEG] text probability is load-bearing for the RL stage, yet the abstract (and any corresponding method description) provides no formulation, pseudocode, or derivation showing how the calibration is computed or why it avoids reducing to a fitted parameter from the same data.
Authors: We agree that the abstract and method description as presented lack the explicit formulation. In the revised manuscript we will add the full mathematical derivation of SEG-aware logit calibration, including the precise update rule that combines pixel-wise segmentation metrics with token logits, along with pseudocode and an explanation of why the mechanism is not reducible to a data-fitted scalar. revision: yes
-
Referee: [Method] Method section on multi-turn temporal-spatial chain-of-thought: the description of iteratively pinpointing intervals and keyframes is presented without an explicit algorithm, state transition, or reward formulation; this makes it impossible to verify whether the multi-turn process is internally consistent or reduces to standard single-turn RL with added turns.
Authors: We acknowledge the need for a formal specification. The revised manuscript will include an explicit algorithm box, state-transition equations, and the per-turn reward formulation that distinguishes the multi-turn evidence-acquisition loop from single-turn RL. revision: yes
-
Referee: [Experiments] Experiments (or lack thereof): the abstract and provided text contain no quantitative results, ablation studies, or baseline comparisons; without these, the effectiveness claims for the new components cannot be assessed and the soundness of the overall contribution remains unverified.
Authors: This observation is correct for the text provided to the referee. The revised version will contain a full experimental section with quantitative results on standard RVOS benchmarks, ablations isolating each proposed component (multi-turn CoT, SEG-aware calibration, decoupled trace), and comparisons against relevant baselines. revision: yes
Circularity Check
No significant circularity detected
full rationale
The manuscript presents VideoSEG-O3 as a newly constructed multi-turn RL framework for RVOS, together with auxiliary components (multi-turn temporal-spatial CoT, SEG-aware logit calibration, decoupled thinking trace, VTS-CoT dataset). No equations, fitted parameters, predictions, or uniqueness theorems appear in the supplied text. All load-bearing elements are introduced as design choices rather than derived from quantities defined inside the same paper or from self-citations that reduce the central claim to an input. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
invented entities (2)
-
SEG-aware logit calibration
no independent evidence
-
decoupled thinking trace
no independent evidence
Reference graph
Works this paper leans on
-
[1]
•Stage II: Chain-of-Thought Cold-Start
(0.6K), Ref-SA V (Yuan et al., 2025a) (37K), and Long-RVOS (Liang et al., 2025a) (2.2K). •Stage II: Chain-of-Thought Cold-Start. – Objective:To elicit multi-step reasoning, enable tool usage, and standardize the format for multi-turn interactions. – Datasets (VTS-CoT):We constructed a proprietary dataset (VTS-CoT, 6K samples) via GPT-assisted labeling. So...
2024
-
[2]
(In-Domain), alongside zero-shot benchmarks onReasonVOS(Bai et al., 2024) andGroundMoRe(Deng et al.,
2024
-
[3]
Performance is measured using standard metrics: J (average Intersection over Union, IoU), F (boundary F-measure), andJ&F(the average ofJandF)
(Out-Domain). Performance is measured using standard metrics: J (average Intersection over Union, IoU), F (boundary F-measure), andJ&F(the average ofJandF). Table 6.The three-stage training pipeline of VideoSEG-O3, detailing the specific capabilities developed and the datasets utilized at each stage. Stage Capability Training Datasets Stage I: SFTVideo QA...
2024
-
[4]
(1.7K) A.2. Training Details The training of VideoSEG-O3 is hierarchically structured into three stages: supervised fine-tuning (SFT), Chain-of-Thought (CoT) cold-start, and Reinforcement Learning (RL). This section provides the exhaustive hyperparameter configurations for each phase. A.2.1. STAGEI (SFT)ANDSTAGEII (COT COLD-START) The transition from Stag...
2025
-
[5]
Each dataset introduces unique challenges to ensure the complexity and generalization capability of VTS-CoT
Diverse Data Curation.We aggregate a diverse collection of video clips from three representative benchmarks: ReVOS, Long-RVOS, and MeViS. Each dataset introduces unique challenges to ensure the complexity and generalization capability of VTS-CoT. Specifically, ReVOS focuses on reasoning-intensive scenarios, MeViS emphasizes complex motion and expression u...
-
[6]
Following the initial annotation, we implement a rigorous filtering protocol to retain high-quality samples
Temporal Labeling and Mask Quality Assessment.We design a specialized prompt (see Table 10) to guide the Qwen3VL-235B-A30B-Instruct (Bai et al., 2025) model in performing precise temporal labeling and evaluating mask fidelity. Following the initial annotation, we implement a rigorous filtering protocol to retain high-quality samples. To ensure annotation ...
2025
-
[7]
This process is executed by the ERNIE-45-VL-424B-A47B model using the prompt detailed in Table 11
Temporal Candidation.Leveraging the refined temporal annotations from the previous stage, we generate three top-ranked candidate temporal intervals. This process is executed by the ERNIE-45-VL-424B-A47B model using the prompt detailed in Table 11. To encourage the generation of diverse yet plausible temporal proposals, we deliberately employ a low-resolut...
-
[8]
Decoupled CoT Construction.With the high-quality temporal annotations and candidate intervals established, we utilize the prompt presented in Table 12 to instruct the Qwen3VL-235B-A30B-Thinking (Bai et al., 2025) model in synthesizing the final reasoning chains. To maximize the diversity and coverage of the generated Chain-of-Thought (CoT) data, we apply ...
2025
-
[9]
Temporal Localization:Identify the most semantic-relevant time interval [tstart, tend] and a representative keyframe tkey that best aligns with theTarget Query
-
[10]
start frame
Mask Fidelity Assessment:Evaluate theCandidate Masks. Determine if the green contours accurately and consistently capture the target object described in the query. Constraints & Rules: • Temporal Duration:The selected window must capture the core event without being excessive. The duration ∆t=t end −t start must satisfy: 5<∆t <0.5×T total •Index Validity:...
-
[11]
Primary Selection (S 1):Identify the single most relevant segment in the entire video
-
[12]
Find the best matching segment in the remaining video parts (V\S 1)
Secondary Selection (S2):Mask the time range of S1. Find the best matching segment in the remaining video parts (V\S 1)
-
[13]
start frame
Tertiary Selection (S 3):Mask the time ranges of bothS 1 andS 2. Find the best match in (V\(S 1 ∪S 2)). Constraints & Rules: •Relevance Ranking:Output must be sorted by semantic relevance:Rel(S 1)> Rel(S 2)> Rel(S 3). •Non-Overlapping:Segments must be mutually exclusive: Si ∩S j =∅,∀i̸=j •Duration Constraints:For any segmentS i with duration∆t i: 0.1×T to...
-
[14]
Phase 1 (Initialization):Analyze global context and text to form a hypothesis.Constraint:Y ou cannot access specific segment details yet.Action:Request Segment 0
-
[15]
Verify if the target matches
Phase 2 (Verification Loop):Analyze specific frames requested in the previous step. Verify if the target matches. Action:Request next segment OR Confirm final target. Input Data: •Global:Referring Expression, Total Video Length, Sampled Frame Indices. •Input Segments:Sequence of temporal segments (start/end/keyframe). •Visual Cues:Red Numbers (Frame Indic...
-
[16]
-Step 2 (Local Spatial):Inspect Sampled Frames
First Item (Global Analysis): -Step 1 (Global Temporal):Analyze low-res global context for candidates. -Step 2 (Local Spatial):Inspect Sampled Frames. -Step 3 (Alignment):Correlate visual cues with text constraints. -Action:RequestInput Segment [0]
-
[17]
The car at the very front at the beginning
Subsequent Items (Verification Loop for Segmentk): -Step 1 (Segment Temporal):Analyze motion in the requested interval. -Step 2 (Segment Spatial):Verify visual attributes in the requestedkey frame. -Step 3 (Refinement):Compare specific evidence against text. -Action:Justify checkingSegment [k+1]OR ConfirmFinal Segment. Constraints & Rules: •Information Is...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.