AsyncPatch Diffusion: spatially-flexible image generation
Pith reviewed 2026-06-27 22:31 UTC · model grok-4.3
The pith
AsyncPatch Diffusion assigns independent noise levels to different image regions in a single joint-diffusion model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
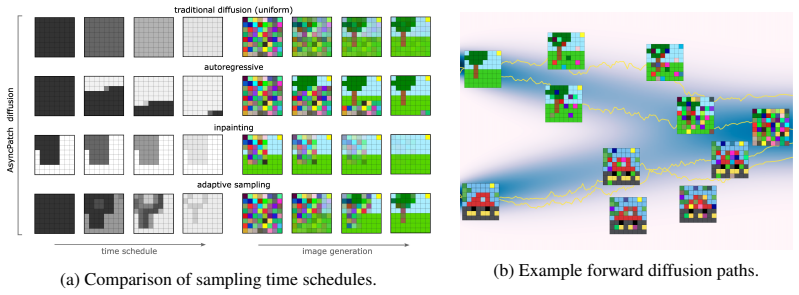
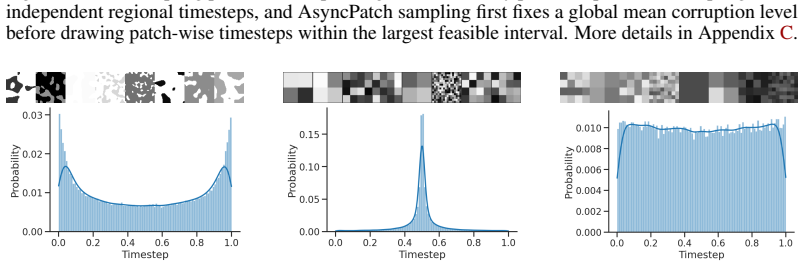
AsyncPatch Diffusion is a joint-diffusion framework that assigns distinct noise levels to separate input dimensions such as pixels or latent tokens. This asynchronous corruption defines a valid generative process and supports a richer family of spatially heterogeneous denoising trajectories; the paper proves the first valid ELBO for the process. A controlled noise-level sampler regulates both average corruption and spatial variability so that homogeneous configurations remain well represented during training.
What carries the argument
The asynchronous corruption mechanism that assigns independent noise levels to different spatial dimensions while preserving a valid joint generative process.
If this is right
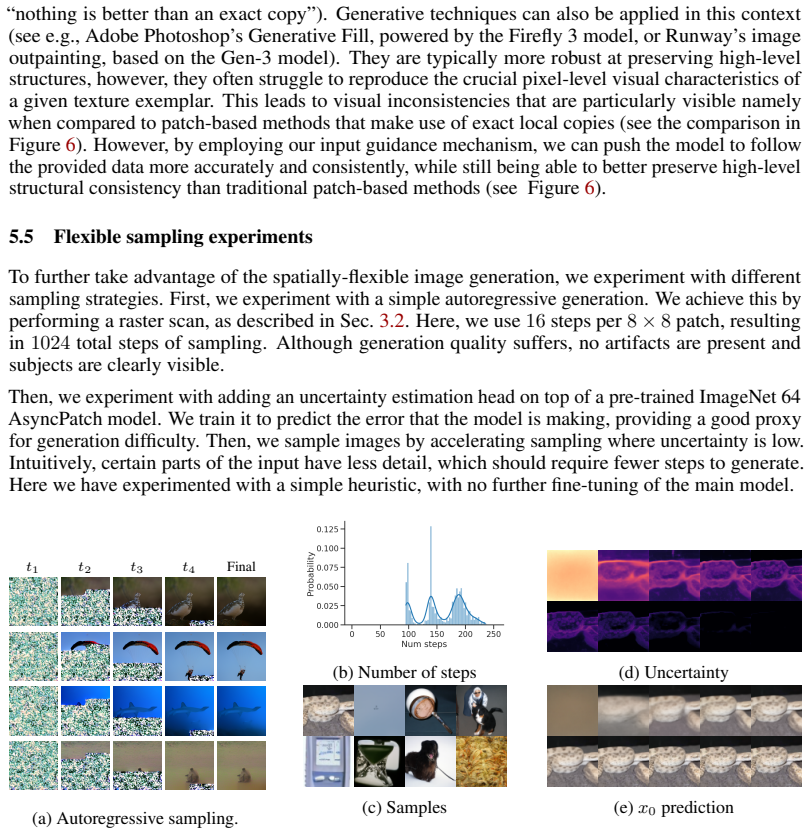
- A single pretrained model can perform inpainting by denoising unknown regions while holding known regions at low or zero noise.
- Input guidance from clean or partially corrupted regions improves texture matching and local consistency in generated areas.
- Uncertainty-guided acceleration and autoregressive sampling become native capabilities of the same model.
- Spatially adaptive generation works without any task-specific fine-tuning on standard benchmarks.
Where Pith is reading between the lines
- The framework may reduce the number of specialized models needed for conditional or region-specific image tasks.
- Extending the per-dimension noise idea to video or 3D data could allow independent temporal or depth denoising schedules.
- If the sampler generalizes, similar asynchronous corruption might apply to other generative processes such as score-based or flow models.
Load-bearing premise
The controlled noise-level sampler can balance homogeneous and heterogeneous configurations during training without degrading performance on standard uniform-noise trajectories.
What would settle it
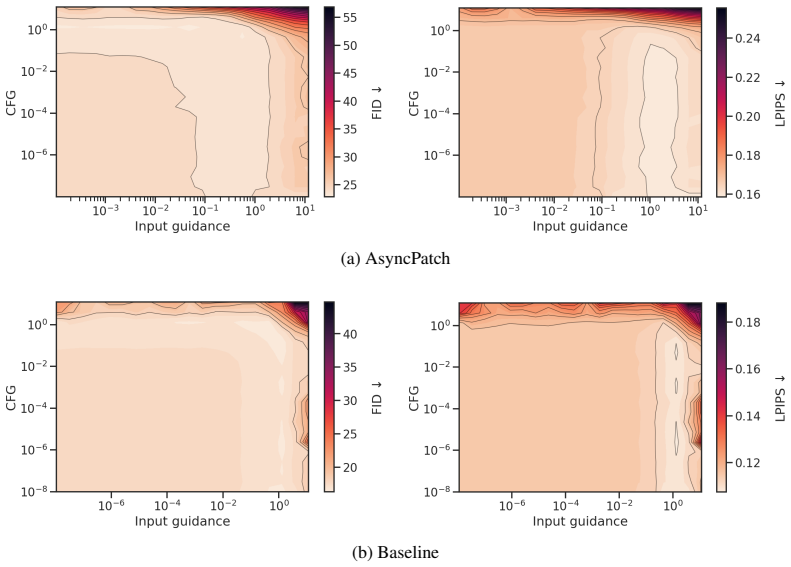
Train the AsyncPatch model on ImageNet 256 with the controlled sampler and check whether FID scores remain within a few points of a matched standard diffusion baseline under identical architecture and compute.
Figures







read the original abstract
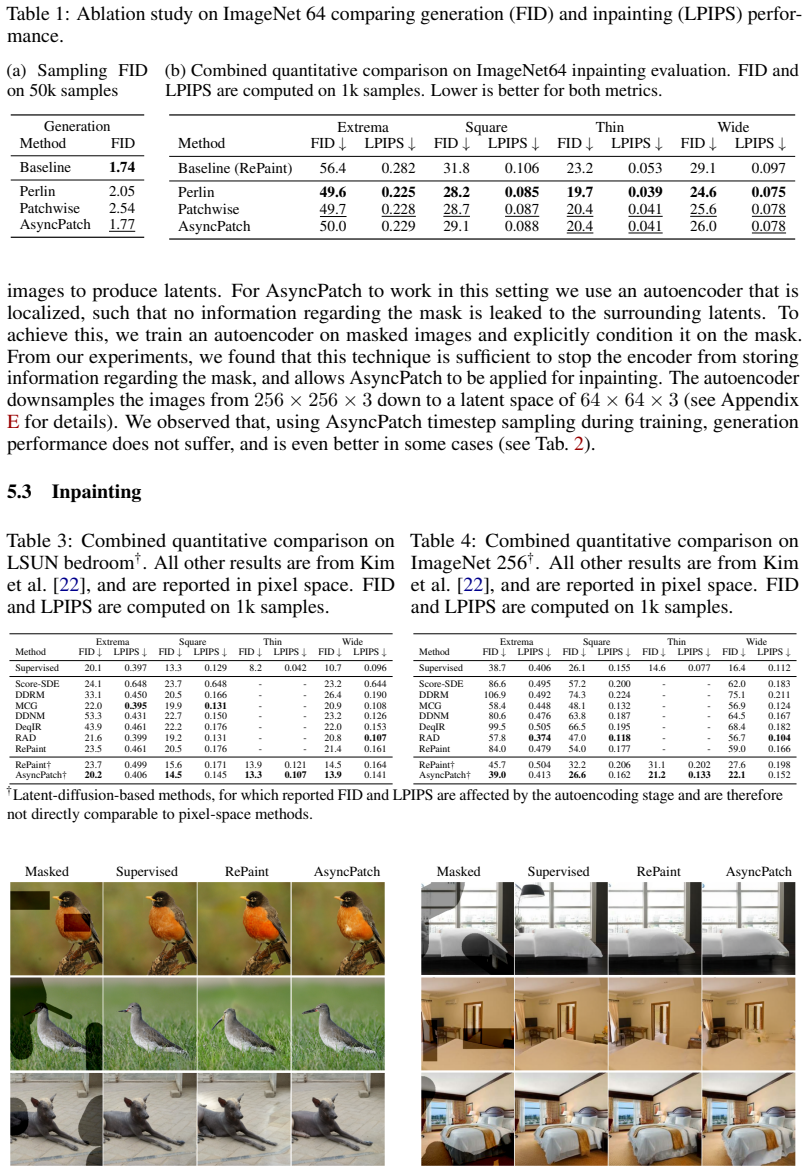
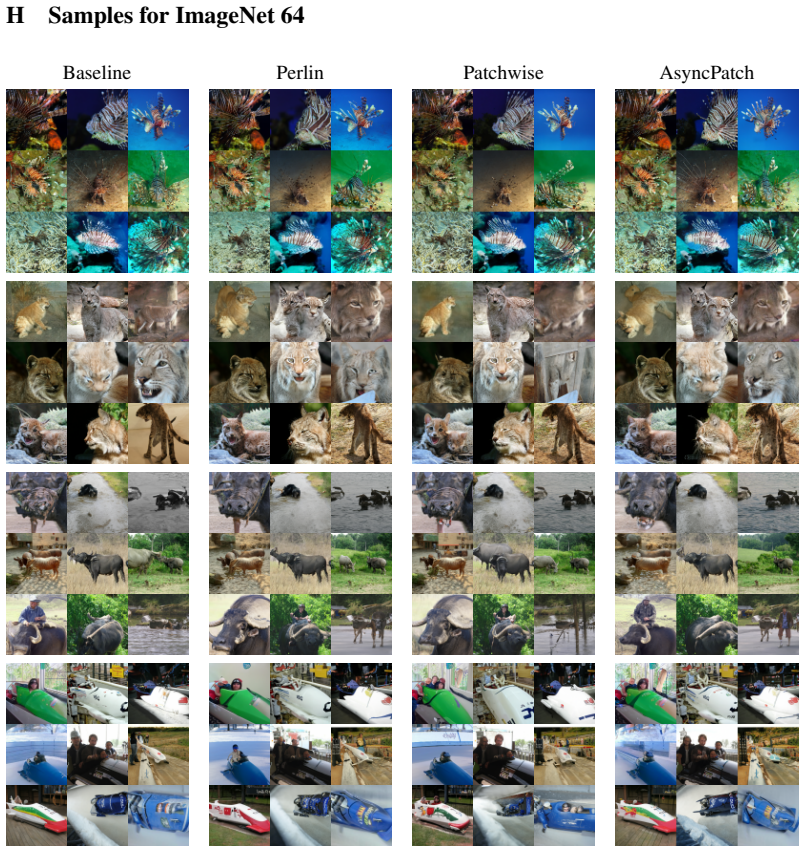
Standard diffusion models corrupt an entire sample with a single shared noise level, forcing all spatial regions to follow the same denoising trajectory. We introduce AsyncPatch Diffusion, a joint-diffusion framework that assigns distinct noise levels to different input dimensions, such as image pixels, or latent tokens. We show how this asynchronous corruption defines a valid generative process while supporting a richer family of spatially heterogeneous denoising trajectories, and prove the first valid ELBO for this process. We show that a single pretrained model can perform spatially adaptive generation, where different regions are denoised on different schedules. A key challenge is training: naive independent noise-level sampling overemphasizes highly heterogeneous configurations and underrepresents homogeneous noise levels, that are crucial during sampling. We address this with a controlled noise-level sampler that regulates both the average corruption level and its spatial variability. AsyncPatch achieves generation quality comparable to conventional diffusion on ImageNet 256 and LSUN, while being natively suited for inpainting without task-specific fine-tuning. We further introduce input guidance, which uses clean or partially corrupted regions to guide the generation of unknown regions, improving local consistency and texture matching. Finally, we demonstrate adaptive generation strategies including uncertainty-guided acceleration and autoregressive sampling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AsyncPatch Diffusion, a joint-diffusion framework assigning distinct noise levels to different input dimensions (e.g., image pixels or latent tokens). It claims this asynchronous corruption defines a valid generative process supporting spatially heterogeneous denoising trajectories, provides the first valid ELBO for the process, introduces a controlled noise-level sampler to balance training configurations, and demonstrates a single pretrained model performing spatially adaptive generation, native inpainting, input guidance, uncertainty-guided acceleration, and autoregressive sampling, with generation quality comparable to standard diffusion on ImageNet 256 and LSUN.
Significance. If the ELBO is valid and the controlled sampler preserves coverage of homogeneous trajectories without bias, the framework would enable richer spatially adaptive generation and task-agnostic inpainting in a single model, representing a meaningful extension of diffusion models for heterogeneous denoising schedules.
major comments (2)
- [Abstract] Abstract: the controlled noise-level sampler is introduced to regulate average corruption level and spatial variability, addressing the issue that naive independent sampling overemphasizes heterogeneous configurations. However, no derivation, density analysis, or ablation demonstrates that the induced training distribution maintains sufficient measure on homogeneous noise levels (uniform-t trajectories) used at inference. This is load-bearing for the claim of comparable ImageNet/LSUN quality under conventional uniform sampling.
- [Abstract] Abstract: the paper asserts a valid ELBO for the asynchronous corruption process and a new sampler, but provides no derivation details, experimental controls, or error analysis. The soundness of the central generative-process claim cannot be assessed from the given information.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the major comments point by point below, agreeing that additional details will strengthen the presentation, and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the controlled noise-level sampler is introduced to regulate average corruption level and spatial variability, addressing the issue that naive independent sampling overemphasizes heterogeneous configurations. However, no derivation, density analysis, or ablation demonstrates that the induced training distribution maintains sufficient measure on homogeneous noise levels (uniform-t trajectories) used at inference. This is load-bearing for the claim of comparable ImageNet/LSUN quality under conventional uniform sampling.
Authors: We agree that explicit verification of coverage on homogeneous trajectories is important for supporting the quality claims. The controlled sampler is intended to balance average corruption level and spatial variability to avoid overemphasizing heterogeneous cases. In the revised manuscript we will add a formal derivation of the induced training distribution, density analysis quantifying measure on uniform-t trajectories, and ablations showing that generation quality remains comparable when the sampler is used versus naive sampling. This will directly address the load-bearing concern. revision: yes
-
Referee: [Abstract] Abstract: the paper asserts a valid ELBO for the asynchronous corruption process and a new sampler, but provides no derivation details, experimental controls, or error analysis. The soundness of the central generative-process claim cannot be assessed from the given information.
Authors: The manuscript states a proof of ELBO validity for the asynchronous process. We acknowledge that the current presentation may not provide sufficient accessible details for full assessment. In revision we will expand the derivation with additional step-by-step explanations, include experimental controls that validate the ELBO under asynchronous schedules, and add error analysis to quantify approximation quality. These additions will make the soundness of the generative-process claim easier to evaluate. revision: yes
Circularity Check
No significant circularity; ELBO derivation and sampler are independent of fitted inputs
full rationale
The paper presents an explicit derivation of a valid ELBO for asynchronous per-dimension noise corruption and introduces a controlled noise-level sampler to address training distribution issues. No equations or claims reduce a prediction to a fitted parameter by construction, no self-citation chains justify core premises, and no ansatz is smuggled via prior work. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
One transformer fits all distributions in multi-modal diffusion at scale
Fan Bao, Shen Nie, Kai Xue, et al. One transformer fits all distributions in multi-modal diffusion at scale. InICML, 2023
2023
-
[2]
PatchMatch: A randomized correspondence algorithm for structural image editing.ACM Transactions on Graphics, 28(3):24, 2009
Connelly Barnes, Eli Shechtman, Adam Finkelstein, and Dan B Goldman. PatchMatch: A randomized correspondence algorithm for structural image editing.ACM Transactions on Graphics, 28(3):24, 2009
2009
-
[3]
John Wiley & Sons, 2013
Patrick Billingsley.Convergence of probability measures. John Wiley & Sons, 2013
2013
-
[4]
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22563–22575, 2023
2023
-
[5]
Generative flows on discrete state-spaces: Enabling multimodal flows with applications to protein co-design
Andrew Campbell, Jason Yim, Regina Barzilay, et al. Generative flows on discrete state-spaces: Enabling multimodal flows with applications to protein co-design. InICML, 2024
2024
-
[6]
Self-supervised flow matching for scalable multi-modal synthesis
Hila Chefer, Patrick Esser, Dominik Lorenz, Dustin Podell, Vikash Raja, Vinh Tong, Antonio Torralba, and Robin Rombach. Self-supervised flow matching for scalable multi-modal synthesis. arXiv preprint arXiv:2603.06507, 2026. doi: 10.48550/arXiv.2603.06507
-
[7]
Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion, December
Boyuan Chen, Diego Marti Monso, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion, December
- [8]
-
[9]
DiffEdit: Diffusion- based semantic image editing with mask guidance, October 2022
Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord. DiffEdit: Diffusion- based semantic image editing with mask guidance, October 2022. URL http://arxiv.org/ abs/2210.11427. arXiv:2210.11427 [cs]
arXiv 2022
-
[10]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InComputer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on, pages 248–255. IEEE, 2009
2009
-
[11]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. In Advances in Neural Information Processing Systems, 2021
2021
-
[12]
Efros and William T
Alexei A. Efros and William T. Freeman. Image Quilting for Texture Synthesis and Transfer. InSIGGRAPH Conference Proceedings, pages 341–346, 2001
2001
-
[13]
Efros and Thomas K
Alexei A. Efros and Thomas K. Leung. Texture Synthesis by Non-Parametric Sampling. In Proceedings of IEEE International Conference on Computer Vision, pages 1033–1038, 1999
1999
-
[14]
StyLit: Illumination-Guided Example-Based Stylization of 3D Renderings
Jakub Fišer, Ondˇrej Jamriška, Michal Lukáˇc, Eli Shechtman, Paul Asente, Jingwan Lu, and Daniel Sýkora. StyLit: Illumination-Guided Example-Based Stylization of 3D Renderings. ACM Transactions on Graphics, 35(4):92, 2016
2016
-
[15]
Mathis Gerdes, Max Welling, and Miranda C. N. Cheng. GUD: Generation with Unified Diffusion, October 2024. URL http://arxiv.org/abs/2410.02667. arXiv:2410.02667 [cs]
arXiv 2024
-
[16]
Gradpaint: Gradient-guided inpainting with diffusion models.Computer Vision and Image Understanding, 244:103928, 2025
Asya Grechka, Guillaume Couairon, and Matthieu Cord. Gradpaint: Gradient-guided inpainting with diffusion models.Computer Vision and Image Understanding, 244:103928, 2025
2025
-
[17]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in neural information processing systems, volume 33, pages 6840–6851, 2020
2020
-
[18]
Video diffusion models.Advances in Neural Information Processing Systems, 35:5733–5747, 2022
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, Tim Salimans, and others. Video diffusion models.Advances in Neural Information Processing Systems, 35:5733–5747, 2022
2022
-
[19]
Peter Holderrieth, Marton Havasi, Jason Yim, Neta Shaul, Itai Gat, Tommi Jaakkola, Brian Karrer, Ricky T. Q. Chen, and Yaron Lipman. Generator matching: Generative modeling with arbitrary markov processes. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025. 10
2025
-
[20]
A variational perspective on diffusion- based generative models and score matching.Advances in Neural Information Processing Systems, 34:22863–22876, 2021
Chin-Wei Huang, Jae Hyun Lim, and Aaron C Courville. A variational perspective on diffusion- based generative models and score matching.Advances in Neural Information Processing Systems, 34:22863–22876, 2021
2021
-
[21]
Self Tuning Texture Optimization.Computer Graphics Forum, 34(2):349–360, 2015
Alexandre Kaspar, Boris Neubert, Dani Lischinski, Mark Pauly, and Johannes Kopf. Self Tuning Texture Optimization.Computer Graphics Forum, 34(2):349–360, 2015
2015
-
[22]
A versatile diffusion transformer with mixture of noise levels for audiovisual generation
Gunwoo Kim, Alejandro Martinez, Yu-Chuan Su, et al. A versatile diffusion transformer with mixture of noise levels for audiovisual generation. InNeurIPS, 2024
2024
-
[23]
RAD: Region-Aware Diffusion Models for Image Inpainting, December 2024
Sora Kim, Sungho Suh, and Minsik Lee. RAD: Region-Aware Diffusion Models for Image Inpainting, December 2024. URL http://arxiv.org/abs/2412.09191. arXiv:2412.09191 [cs]
arXiv 2024
-
[24]
Woojin Kim and Jaeyoung Do. Don’t Let It Fade: Preserving Edits in Diffusion Language Models via Token Timestep Allocation, October 2025. URL http://arxiv.org/abs/2510. 26200. arXiv:2510.26200 [cs]
arXiv 2025
-
[25]
DiffWave: a versatile diffusion model for audio synthesis
Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. DiffWave: a versatile diffusion model for audio synthesis. InInternational conference on learning representations, 2021
2021
-
[26]
Essa, Aaron F
Vivek Kwatra, Irfan A. Essa, Aaron F. Bobick, and Nipun Kwatra. Texture optimization for example-based synthesis.ACM Transactions on Graphics, 24(3):795–802, 2005
2005
-
[27]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space, June 2025
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Müller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. FLUX.1 Kontext: Flow Matching for In-Context Image ...
Pith/arXiv arXiv 2025
-
[28]
Omniflow: Any-to-any generation with multi-modal rectified flows
Shufan Li, Konstantinos Kallidromitis, Akash Gokul, Zichun Liao, Yusuke Kato, Kazuki Kozuka, and Aditya Grover. Omniflow: Any-to-any generation with multi-modal rectified flows. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[29]
RePaint: Inpainting using Denoising Diffusion Probabilistic Models, August 2022
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. RePaint: Inpainting using Denoising Diffusion Probabilistic Models, August 2022. URL http://arxiv.org/abs/2201.09865. arXiv:2201.09865 [cs]
arXiv 2022
-
[30]
Hd-painter: high-resolution and prompt-faithful text-guided image in- painting with diffusion models
Hayk Manukyan, Andranik Sargsyan, Barsegh Atanyan, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Hd-painter: high-resolution and prompt-faithful text-guided image in- painting with diffusion models. InThe Thirteenth International Conference on Learning Representations, 2023
2023
-
[31]
Badr Moufad, Navid Bagheri Shouraki, Alain Oliviero Durmus, Thomas Hirtz, Eric Moulines, Jimmy Olsson, and Yazid Janati. Efficient zero-shot inpainting with decoupled diffusion guidance.arXiv preprint arXiv:2512.18365, 2025
Pith/arXiv arXiv 2025
-
[32]
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models, March 2022. URL http://arxiv.org/abs/2112. 10741. arXiv:2112.10741 [cs]
Pith/arXiv arXiv 2022
-
[33]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[34]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InAAAI Conference on Artificial Intelligence, 2018
2018
-
[35]
DreamFusion: Text-to-3D using 2D diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. DreamFusion: Text-to-3D using 2D diffusion. InInternational conference on learning representations, 2023. 11
2023
-
[36]
Kevin Rojas, Yuchen Zhu, Sichen Zhu, Felix X.-F. Ye, and Molei Tao. Diffuse Everything: Multimodal Diffusion Models on Arbitrary State Spaces, June 2025. URL http://arxiv. org/abs/2506.07903. arXiv:2506.07903 [cs]
arXiv 2025
-
[37]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[38]
Mm-diffusion: Learning multi-modal diffusion models for joint audio and video generation
Ludan Ruan, Yiyang Ma, Huan Yang, Huiguo He, Bei Liu, Jianlong Fu, Nicholas Jing Yuan, Qin Jin, and Baining Guo. Mm-diffusion: Learning multi-modal diffusion models for joint audio and video generation. InCVPR, 2023
2023
-
[39]
Rolling Diffusion Models, September 2024
David Ruhe, Jonathan Heek, Tim Salimans, and Emiel Hoogeboom. Rolling Diffusion Models, September 2024. URLhttp://arxiv.org/abs/2402.09470. arXiv:2402.09470 [cs]
arXiv 2024
-
[40]
Palette: Image-to-image diffusion models
Chitwan Saharia, William Chan, Huiwen Chang, Chris Lee, Jonathan Ho, Tim Salimans, David Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. InACM SIGGRAPH 2022 conference proceedings, pages 1–10, 2022
2022
-
[41]
Denoising, fast and slow: Difficulty-aware adaptive sampling for image generation
Johannes Schusterbauer, Ming Gui, Yusong Li, Pingchuan Ma, Felix Krause, and Björn Om- mer. Denoising, fast and slow: Difficulty-aware adaptive sampling for image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026
2026
-
[42]
Large-scale text-to-image model with inpainting is a zero-shot subject-driven image generator
Chaehun Shin, Jooyoung Choi, Heeseung Kim, and Sungroh Yoon. Large-scale text-to-image model with inpainting is a zero-shot subject-driven image generator. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7986–7996, 2025
2025
-
[43]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265, 2015
2015
-
[44]
History-Guided Video Diffusion, July 2025
Kiwhan Song, Boyuan Chen, Max Simchowitz, Yilun Du, Russ Tedrake, and Vincent Sitzmann. History-Guided Video Diffusion, July 2025. URL http://arxiv.org/abs/2502.06764. arXiv:2502.06764 [cs]
Pith/arXiv arXiv 2025
-
[45]
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lem- pitsky. Resolution-robust Large Mask Inpainting with Fourier Convolutions.arXiv preprint arXiv:2109.07161, 2021
arXiv 2021
-
[46]
Unified multimodal discrete diffusion.arXiv preprint arXiv:2503.20853, 2025
Alexander Swerdlow, Mihir Prabhudesai, Siddharth Gandhi, Deepak Pathak, and Katerina Fragkiadaki. Unified multimodal discrete diffusion.arXiv preprint arXiv:2503.20853, 2025. doi: 10.48550/arXiv.2503.20853
-
[47]
De novo design of protein structure and function with RFdiffusion.Nature, 620(7976):1089–1100, 2023
Joseph L Watson, David Juergens, Nathaniel R Bennett, Brian L Trippe, Jason Yim, Helen E Eisenach, Woody Ahern, Andrew J Borst, Robert J Ragotte, Lukas F Milles, and others. De novo design of protein structure and function with RFdiffusion.Nature, 620(7976):1089–1100, 2023
2023
-
[48]
Spatial reasoning with denoising models
Christopher Wewer, Bart Pogodzinski, Bernt Schiele, and Jan Eric Lenssen. Spatial reasoning with denoising models. InInternational Conference on Machine Learning, 2025. doi: 10. 48550/arXiv.2502.21075
arXiv 2025
-
[49]
AR-Diffusion: Auto-Regressive Diffusion Model for Text Generation, December 2023
Tong Wu, Zhihao Fan, Xiao Liu, Yeyun Gong, Yelong Shen, Jian Jiao, Hai-Tao Zheng, Juntao Li, Zhongyu Wei, Jian Guo, Nan Duan, and Weizhu Chen. AR-Diffusion: Auto-Regressive Diffusion Model for Text Generation, December 2023. URL http://arxiv.org/abs/2305. 09515. arXiv:2305.09515 [cs]
arXiv 2023
-
[50]
Turbofill: adapting few-step text- to-image model for fast image inpainting
Liangbin Xie, Daniil Pakhomov, Zhonghao Wang, Zongze Wu, Ziyan Chen, Yuqian Zhou, Haitian Zheng, Zhifei Zhang, Zhe Lin, Jiantao Zhou, et al. Turbofill: adapting few-step text- to-image model for fast image inpainting. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7613–7622, 2025. 12
2025
-
[51]
Energy-Based Diffusion Language Models for Text Generation, March 2025
Minkai Xu, Tomas Geffner, Karsten Kreis, Weili Nie, Yilun Xu, Jure Leskovec, Stefano Ermon, and Arash Vahdat. Energy-Based Diffusion Language Models for Text Generation, March 2025. URLhttp://arxiv.org/abs/2410.21357. arXiv:2410.21357 [cs]
arXiv 2025
-
[52]
Fisher Yu, Yinda Zhang, Shuran Song, Ari Seff, and Jianxiong Xiao. LSUN: construction of a large-scale image dataset using deep learning with humans in the loop.CoRR, abs/1506.03365, 2015. 13 A Proofs of the Lemmas A.1 Proof Lemma 1 Before we begin the proof, we must setup the basic definition and a preliminary Lemma. Definition: Generalized Denoising Sco...
Pith/arXiv arXiv 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.