Covariance Shrinkage via Stochastic Interpolation
Pith reviewed 2026-06-27 22:11 UTC · model grok-4.3
The pith
Covariance shrinkage arises as empirical risk minimization over stochastic interpolants between distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
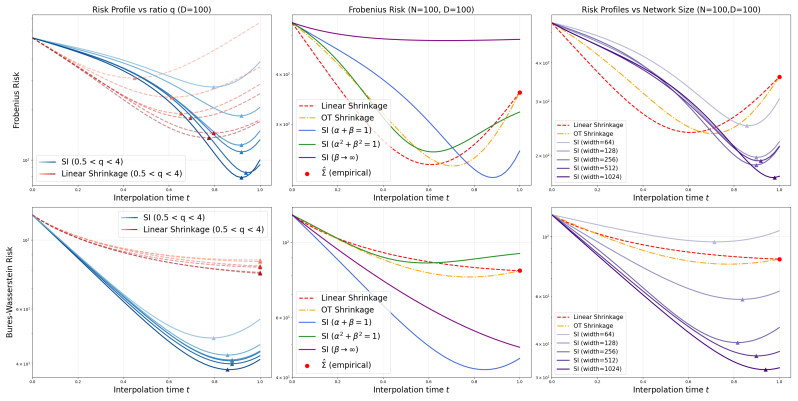
Recasting shrinkage as empirical risk minimization over a parametric stochastic interpolant recovers known estimators as special cases and shows that risk can be reduced through the interpolant schedule, through couplings such as optimal transport solutions realized by non-linear flow maps that free the covariance from the empirical eigenbasis, and through early stopping of the integrated vector field. A neural estimator of the interpolant is proposed with an upper bound on quadratic risk expressed via the approximation error.
What carries the argument
Parametric stochastic interpolant between source and target distributions, with covariance controlled by schedule, couplings, and flow maps.
If this is right
- Known shrinkage estimators appear as particular choices of schedule or linear flow.
- Couplings from optimal transport lower empirical risk compared to independence assumptions.
- Non-linear flow maps allow regularization outside the empirical eigenbasis.
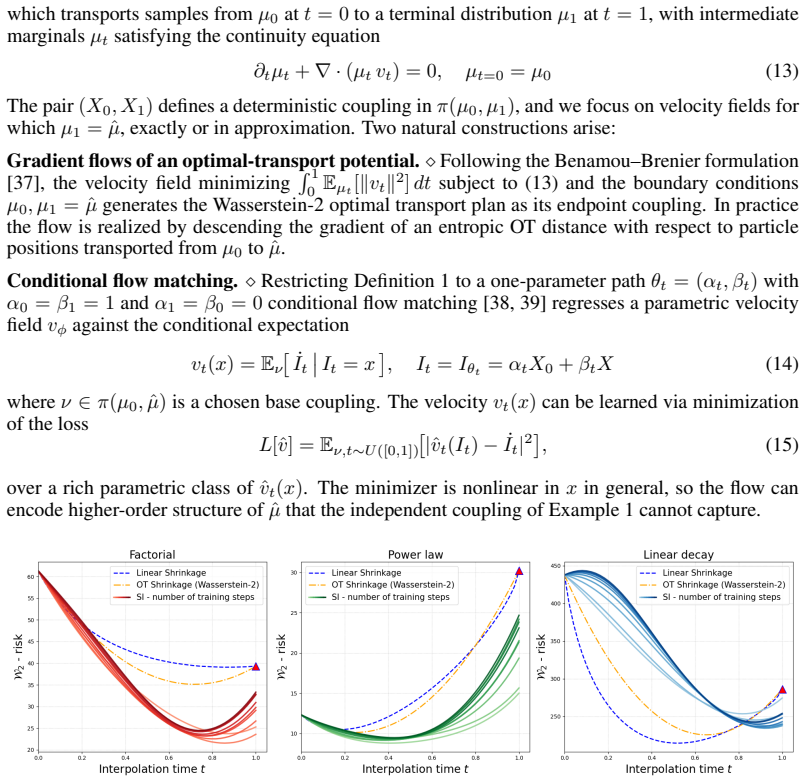
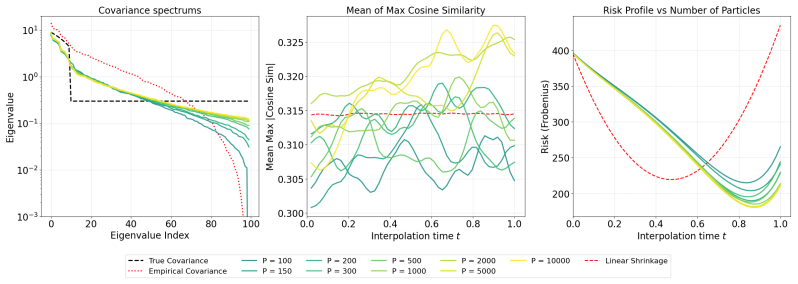
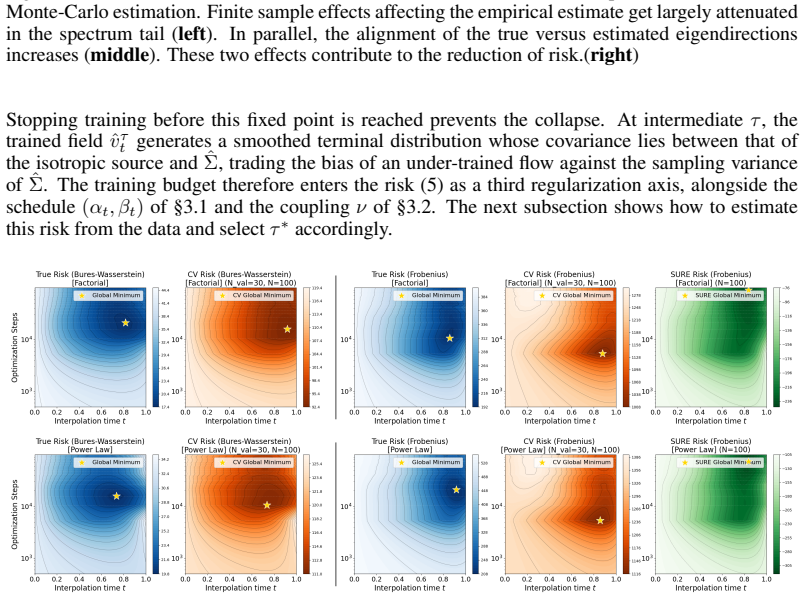
- Early stopping supplies an additional bias-variance trade-off.
- The neural estimator comes with a risk bound controlled by approximation error to the true interpolant.
Where Pith is reading between the lines
- The formalism may extend to other high-dimensional matrix estimation tasks by defining suitable source-target interpolants.
- Neural flow maps could scale the method to regimes where classical shrinkage is limited by eigenvector misalignment.
- The separation of regularization mechanisms suggests connections to iterative algorithms that already use path-based or early-stopped estimation.
Load-bearing premise
Specific coupling structures and non-linear flow maps can be realized to free the interpolant covariance from the eigenbasis of the empirical estimate.
What would settle it
Compare the neural interpolant estimator against classical shrinkage on synthetic data whose true covariance eigenvectors are unrelated to the sample eigenvectors; failure to improve when using the proposed couplings would falsify the claim of regularization independent of the eigenbasis.
Figures
read the original abstract
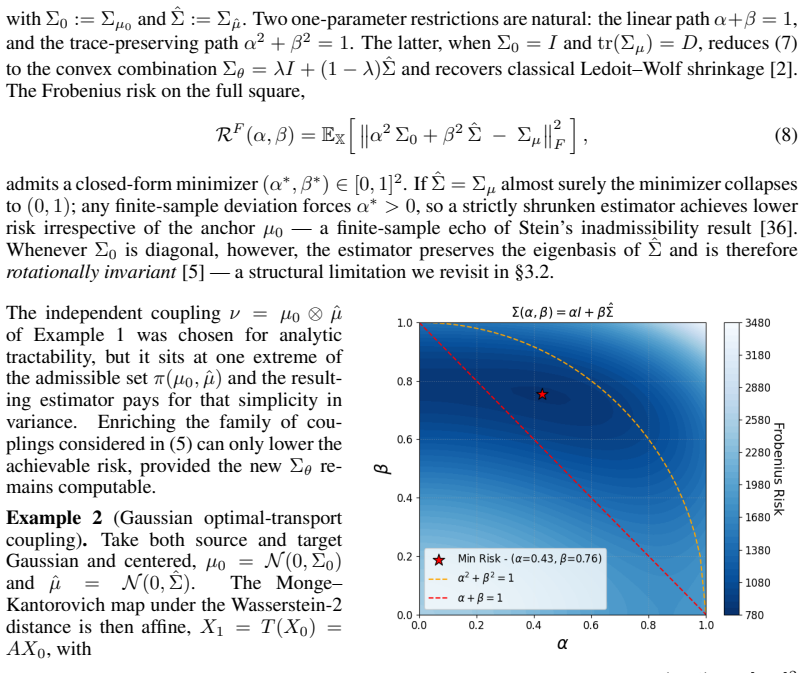
We recast classical shrinkage of high-dimensional covariance estimators as empirical risk minimization over a parametric stochastic interpolant between a source and a target distribution. This formalism recovers known shrinkage estimators as special cases and reveals three distinct mechanisms for reducing statistical risk: (i) Scheduling: the interpolant schedule determines the class of admissible covariances, and hence the achievable risk. (ii) Flow maps and couplings: whereas naive constructions amount to assuming independence between the distributions, specific coupling structures (e.g., solutions of optimal transport problems) can lower the empirical risk. Moreover, non-linear flow maps realizing such couplings free the interpolant covariance from the eigenbasis of the empirical estimate, enabling eigenvector regularization. (iii) Early stopping: estimators defined by integrating a regressed vector field afford an additional bias-variance trade-off through approximation of the true interpolant distribution. We then propose a neural estimator of the interpolant, together with an upper bound on its quadratic risk in terms of the interpolant approximation error, and validate both on synthetic experiments. Finally, we apply the estimator to real neuroimaging data, demonstrating the additional regularization power this approach offers in practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper recasts classical covariance shrinkage as empirical risk minimization over a parametric stochastic interpolant between source and target distributions. It recovers known shrinkage estimators as special cases and identifies three mechanisms for risk reduction: (i) scheduling of the interpolant, (ii) choice of couplings (e.g., optimal transport) and non-linear flow maps that purportedly decouple the interpolant covariance from the empirical eigenbasis, and (iii) early stopping via integration of a regressed vector field. A neural estimator of the interpolant is proposed along with an upper bound on its quadratic risk expressed in terms of approximation error; the approach is validated on synthetic data and applied to neuroimaging covariance estimation.
Significance. If the central derivations hold, the work supplies a unified view that recovers classical estimators while isolating distinct regularization pathways, with the risk bound and neural implementation providing concrete tools for high-dimensional covariance estimation. Explicit recovery of known cases and the provision of a falsifiable risk bound tied to approximation error are strengths. The potential for eigenvector regularization via flow maps, if rigorously shown to be independent of scheduling, would add meaningful new capability beyond standard shrinkage.
major comments (3)
- [Abstract / mechanism (ii) derivation] Abstract and the section deriving the three mechanisms: the assertion that non-linear flow maps realizing OT couplings free the interpolant covariance from the eigenbasis of the empirical estimate (thereby enabling eigenvector regularization independent of schedule) is load-bearing for the claim of three distinct mechanisms, yet the manuscript supplies neither the explicit form of the resulting interpolant covariance matrix under a general non-linear map nor the condition that guarantees schedule-independence. If the covariance remains diagonal in the empirical eigenbasis for arbitrary schedules, mechanism (ii) reduces to (i) or (iii).
- [Risk bound derivation] Section presenting the quadratic risk bound: the bound is stated in terms of interpolant approximation error, but it is unclear whether the derivation accounts for the choice of coupling or flow map; if the bound is derived under an independence assumption between source and target, it does not support the stronger claim that OT couplings yield additional risk reduction beyond scheduling.
- [Synthetic experiments] Experimental section (synthetic validation): the reported gains from the neural estimator must be shown to arise from the flow-map/coupling mechanism rather than from schedule tuning or early stopping alone; without an ablation that isolates the eigenbasis-decoupling effect, the empirical support for the central claim remains incomplete.
minor comments (2)
- [Preliminaries] Notation for the interpolant schedule and flow map parameters should be introduced with explicit definitions before their use in the risk bound to avoid ambiguity.
- [Real-data application] The neuroimaging application would benefit from a quantitative comparison table against standard shrinkage baselines (Ledoit-Wolf, etc.) with reported effect sizes rather than qualitative statements of 'additional regularization power.'
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which have identified opportunities to strengthen the clarity and empirical support of our work. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / mechanism (ii) derivation] Abstract and the section deriving the three mechanisms: the assertion that non-linear flow maps realizing OT couplings free the interpolant covariance from the eigenbasis of the empirical estimate (thereby enabling eigenvector regularization independent of schedule) is load-bearing for the claim of three distinct mechanisms, yet the manuscript supplies neither the explicit form of the resulting interpolant covariance matrix under a general non-linear map nor the condition that guarantees schedule-independence. If the covariance remains diagonal in the empirical eigenbasis for arbitrary schedules, mechanism (ii) reduces to (i) or (iii).
Authors: We agree that an explicit derivation would improve the manuscript. In the revision we will add a proposition that derives the closed-form interpolant covariance for a general non-linear flow map realizing an OT coupling. The resulting expression shows that the covariance is not constrained to the empirical eigenbasis when the map is non-linear. We will also state the precise condition (non-linearity of the flow map with respect to the empirical eigen-coordinates) under which the eigenvector regularization is independent of the schedule. This establishes mechanism (ii) as distinct from (i) and (iii). revision: yes
-
Referee: [Risk bound derivation] Section presenting the quadratic risk bound: the bound is stated in terms of interpolant approximation error, but it is unclear whether the derivation accounts for the choice of coupling or flow map; if the bound is derived under an independence assumption between source and target, it does not support the stronger claim that OT couplings yield additional risk reduction beyond scheduling.
Authors: The quadratic risk bound is derived for arbitrary couplings and flow maps; the approximation-error term is independent of the coupling, while the coupling affects only the base risk that the bound is taken with respect to. To remove any ambiguity we will revise the section to explicitly note that the derivation does not invoke an independence assumption and to separate the base-risk term (which depends on the chosen coupling) from the excess-risk term controlled by the approximation error. This preserves the claim that OT couplings can yield additional reduction beyond scheduling alone. revision: yes
-
Referee: [Synthetic experiments] Experimental section (synthetic validation): the reported gains from the neural estimator must be shown to arise from the flow-map/coupling mechanism rather than from schedule tuning or early stopping alone; without an ablation that isolates the eigenbasis-decoupling effect, the empirical support for the central claim remains incomplete.
Authors: We agree that an ablation isolating the flow-map and coupling contribution is required. In the revised manuscript we will add synthetic experiments that fix both the schedule and the early-stopping criterion while varying only the coupling (independent versus OT) and the flow-map class (linear versus non-linear). The resulting risk curves will directly quantify the additional reduction attributable to eigenbasis decoupling. revision: yes
Circularity Check
No significant circularity; new formalism and risk bound are independent of fitted inputs.
full rationale
The paper recasts covariance shrinkage as ERM over a parametric stochastic interpolant, recovers known estimators as special cases, and states an upper bound on quadratic risk explicitly in terms of the interpolant approximation error (external to the estimator). No equations or claims in the abstract reduce by construction to self-defined quantities, fitted parameters renamed as predictions, or self-citation chains. The three mechanisms are presented as distinct contributions without any shown interdependence that collapses one into another by definition. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- interpolant schedule
- neural network parameters
axioms (1)
- domain assumption A stochastic interpolant between source and target distributions exists and can be parameterized so that its marginal covariances include classical shrinkage estimators.
Reference graph
Works this paper leans on
-
[1]
Marˇcenko and Leonid Pastur
V .A. Marˇcenko and Leonid Pastur. Distribution of eigenvalues for some sets of random matri- ces.Math USSR Sb, 1:457–483, 01 1967
1967
-
[2]
A well-conditioned estimator for large- dimensional covariance matrices
Olivier Ledoit and Michael Wolf. A well-conditioned estimator for large-dimensional covari- ance matrices.Journal of Multivariate Analysis, 88(2):365–411, 2004. ISSN 0047-259X. doi: https://doi.org/10.1016/S0047-259X(03)00096-4. URLhttps://www.sciencedirect. com/science/article/pii/S0047259X03000964
-
[3]
Olivier Ledoit and Michael Wolf. Analytical nonlinear shrinkage of large-dimensional covari- ance matrices.The Annals of Statistics, 48(5):3043–3065, 2020. doi: 10.1214/19-AOS1921
-
[4]
Nonparametric eigenvalue-regularized precision or covariance matrix estimator
Clifford Lam. Nonparametric eigenvalue-regularized precision or covariance matrix estimator. The Annals of Statistics, 44(3):928–953, 2016. ISSN 00905364. URLhttp://www.jstor. org/stable/43818916
arXiv 2016
-
[5]
Jo ¨el Bun, Jean-Philippe Bouchaud, and Marc Potters. Cleaning large correlation matrices: Tools from random matrix theory.Physics Reports, 666:1–109, 2017. ISSN 0370-1573. doi: https://doi.org/10.1016/j.physrep.2016.10.005. URLhttps://www.sciencedirect.com/ science/article/pii/S0370157316303337. Cleaning large correlation matrices: tools from random matr...
-
[6]
Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 26(209): 1–80, 2025
Michael Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 26(209): 1–80, 2025
2025
-
[7]
Estimation with quadratic loss
William James, Charles Stein, et al. Estimation with quadratic loss. InProceedings of the fourth Berkeley symposium on mathematical statistics and probability, volume 1, pages 361–
-
[8]
University of California Press, 1961
1961
-
[9]
Arthur E. Hoerl and Robert W. Kennard. Ridge regression: Biased estimation for nonorthog- onal problems.Technometrics, 12(1):55–67, 1970. ISSN 00401706. URLhttp://www. jstor.org/stable/1267351
arXiv 1970
-
[10]
Robert Tibshirani. Regression shrinkage and selection via the Lasso.Journal of the Royal Sta- tistical Society: Series B (Methodological), 58(1):267–288, 1996. doi: 10.1111/j.2517-6161. 1996.tb02080.x
-
[11]
Journal of the Royal Statistical Society: Series B (Statistical Methodology) , author =
Hui Zou and Trevor Hastie. Regularization and variable selection via the elastic net.Journal of the Royal Statistical Society Series B: Statistical Methodology, 67(2):301–320, 04 2005. ISSN 1369-7412. doi: 10.1111/j.1467-9868.2005.00503.x. URLhttps://doi.org/10.1111/j. 1467-9868.2005.00503.x
-
[12]
Hui Zou. The adaptive lasso and its oracle properties.Journal of the American Statistical Association, 101(476):1418–1429, 2006. ISSN 01621459. URLhttp://www.jstor.org/ stable/27639762
arXiv 2006
-
[13]
Robust and sparse bridge regression.Statistics and Its Interface, 4, 01 2009
Bin Li and Qingzhao Yu. Robust and sparse bridge regression.Statistics and Its Interface, 4, 01 2009. doi: 10.4310/SII.2009.v2.n4.a9
-
[14]
Concave 1-norm group selection.Biostatistics, 16(2):252– 267, 04 2015
Dingfeng Jiang and Jian Huang. Concave 1-norm group selection.Biostatistics, 16(2):252– 267, 04 2015. ISSN 1465-4644. doi: 10.1093/biostatistics/kxu050. URLhttps://doi.org/ 10.1093/biostatistics/kxu050
-
[15]
Taras Bodnar, Arjun K. Gupta, and Nestor Parolya. Direct shrinkage estimation of large dimensional precision matrix.Journal of Multivariate Analysis, 146:223–236, 2016. ISSN 0047-259X. doi: https://doi.org/10.1016/j.jmva.2015.09.010. URLhttps://www. sciencedirect.com/science/article/pii/S0047259X15002249. Special Issue on Sta- tistical Models and Methods ...
-
[16]
A constrained l1 minimization approach to sparse preci- sion matrix estimation, 2011
Tony Cai, Weidong Liu, and Xi Luo. A constrained l1 minimization approach to sparse preci- sion matrix estimation, 2011. URLhttps://arxiv.org/abs/1102.2233. 10
Pith/arXiv arXiv 2011
-
[17]
Man-Chung Yue, Yves Rychener, Daniel Kuhn, and Viet Anh Nguyen. A geometric unifica- tion of distributionally robust covariance estimators: Shrinking the spectrum by inflating the ambiguity set.arXiv preprint arXiv:2405.20124, 2024
arXiv 2024
-
[18]
van Dyk and Xiao-Li Meng
David A. van Dyk and Xiao-Li Meng. The art of data augmentation.Journal of Computational and Graphical Statistics, 10:1 – 50, 2001. URLhttps://api.semanticscholar.org/ CorpusID:121929631
2001
-
[19]
Data augmentation: A comprehensive survey of modern approaches.Array, 16:100258, 2022
Alhassan Mumuni and Fuseini Mumuni. Data augmentation: A comprehensive survey of modern approaches.Array, 16:100258, 2022. ISSN 2590-0056. doi: https://doi.org/10.1016/ j.array.2022.100258. URLhttps://www.sciencedirect.com/science/article/pii/ S2590005622000911
arXiv 2022
-
[20]
Connor Shorten and Taghi Khoshgoftaar. A survey on image data augmentation for deep learning.Journal of Big Data, 6, 07 2019. doi: 10.1186/s40537-019-0197-0
-
[21]
Data augmentation for deep graph learning: A survey, 2022
Kaize Ding, Zhe Xu, Hanghang Tong, and Huan Liu. Data augmentation for deep graph learning: A survey, 2022. URLhttps://arxiv.org/abs/2202.08235
arXiv 2022
-
[22]
Text data augmentation for deep learn- ing.Journal of Big Data, 8, 07 2021
Connor Shorten, Taghi Khoshgoftaar, and Borko Furht. Text data augmentation for deep learn- ing.Journal of Big Data, 8, 07 2021. doi: 10.1186/s40537-021-00492-0
-
[23]
Training with noise is equivalent to tikhonov regularization.Neural compu- tation, 7(1):108–116, 1995
Chris M Bishop. Training with noise is equivalent to tikhonov regularization.Neural compu- tation, 7(1):108–116, 1995
1995
-
[24]
A kernel theory of modern data augmentation
Tri Dao, Albert Gu, Alexander Ratner, Virginia Smith, Chris De Sa, and Christopher Re. A kernel theory of modern data augmentation. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 1528–1537. PMLR, 09–15 Jun 2019. URL h...
2019
-
[25]
Shuxiao Chen, Edgar Dobriban, and Jane H. Lee. A group-theoretic framework for data augmentation.Journal of Machine Learning Research, 21(245):1–71, 2020. URLhttp: //jmlr.org/papers/v21/20-163.html
2020
-
[26]
Dyer, and Vidya Muthukumar
Chi-Heng Lin, Chiraag Kaushik, Eva L. Dyer, and Vidya Muthukumar. The good, the bad and the ugly sides of data augmentation: An implicit spectral regularization perspective.J. Mach. Learn. Res., 25:91:1–91:85, 2022. URLhttps://api.semanticscholar.org/CorpusID: 252815719
2022
-
[27]
Dreaming more data: Class-dependent distributions over diffeomorphisms for learned data augmentation
Søren Hauberg, Oren Freifeld, Anders Boesen Lindbo Larsen, John Fisher, and Lars Hansen. Dreaming more data: Class-dependent distributions over diffeomorphisms for learned data augmentation. In Arthur Gretton and Christian C. Robert, editors,Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, volume 51 ofProceedings...
2016
-
[28]
Data Augmentation Generative Adversarial Networks
Antreas Antoniou, Amos Storkey, and Harrison Edwards. Data augmentation generative ad- versarial networks. 11 2017. doi: 10.48550/arXiv.1711.04340
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1711.04340 2017
-
[29]
Alexander J. Ratner, Henry R. Ehrenberg, Zeshan Hussain, Jared Dunnmon, and Christopher R´e. Learning to compose domain-specific transformations for data augmentation, 2017. URL https://arxiv.org/abs/1709.01643
Pith/arXiv arXiv 2017
-
[30]
Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V
Ekin D. Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V . Le. Autoaug- ment: Learning augmentation policies from data, 2019. URLhttps://arxiv.org/abs/ 1805.09501
Pith/arXiv arXiv 2019
-
[31]
Randaugment: Prac- tical automated data augmentation with a reduced search space
Ekin Dogus Cubuk, Barret Zoph, Jon Shlens, and Quoc Le. Randaugment: Prac- tical automated data augmentation with a reduced search space. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural In- formation Processing Systems, volume 33, pages 18613–18624. Curran Associates, Inc.,
-
[32]
URLhttps://proceedings.neurips.cc/paper_files/paper/2020/file/ d85b63ef0ccb114d0a3bb7b7d808028f-Paper.pdf. 11
2020
-
[33]
Synthetic data for portfolios: A throw of the dice will never abolish chance, 2025
Adil Rengim Cetingoz and Charles-Albert Lehalle. Synthetic data for portfolios: A throw of the dice will never abolish chance, 2025. URLhttps://arxiv.org/abs/2501.03993
arXiv 2025
-
[34]
Model collapse demystified: The case of regression
Elvis Dohmatob, Yunzhen Feng, and Julia Kempe. Model collapse demystified: The case of regression. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Sys- tems, volume 37, pages 46979–47013. Curran Associates, Inc., 2024. doi: 10.52202/ 079017-1490. URLhttps://proceedings...
2024
-
[35]
Few-shot learning with enhancements to data augmentation and feature extraction.IEEE transactions on neural networks and learning systems, 36(4):6655–6668, 2024
Yourun Zhang, Maoguo Gong, Jianzhao Li, Kaiyuan Feng, and Mingyang Zhang. Few-shot learning with enhancements to data augmentation and feature extraction.IEEE transactions on neural networks and learning systems, 36(4):6655–6668, 2024
2024
-
[36]
Non-asymptotic analysis of data augmen- tation for precision matrix estimation, 2025
Lucas Morisset, Adrien Hardy, and Alain Durmus. Non-asymptotic analysis of data augmen- tation for precision matrix estimation, 2025. URLhttps://arxiv.org/abs/2510.02119
arXiv 2025
-
[37]
Zhenshan Zhang, Wenjie Xu, Haitao Zou, and Shichao Yi. Data augmentation for doa estimation using wasserstein gan with gradient penalty.Digital Signal Processing, 179: 106039, 2026. ISSN 1051-2004. doi: https://doi.org/10.1016/j.dsp.2026.106039. URL https://www.sciencedirect.com/science/article/pii/S1051200426001582
-
[38]
Inadmissibility of the usual estimator for the mean of a multivariate normal distribution
Charles Stein. Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. InProceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, volume 1, pages 197–206, Berkeley, 1956. University of California Press
1956
-
[39]
Numerische Mathematik , author =
Jean-David Benamou and Yann Brenier. A computational fluid mechanics solution to the Monge–Kantorovich mass transfer problem.Numerische Mathematik, 84(3):375–393, 2000. doi: 10.1007/s002110050002
-
[40]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InInternational Conference on Learning Representations, 2023
2023
-
[41]
Building normalizing flows with stochastic interpolants
Michael Samuel Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. InProceedings of the Eleventh International Conference on Learning Represen- tations, 2023. URLhttps://arxiv.org/abs/2209.15571
Pith/arXiv arXiv 2023
-
[42]
A. Di Martino, C.-G. Yan, Q. Li, E. Denio, F. X. Castellanos, K. Alaerts, J. S. Anderson, M. Assaf, S. Y . Bookheimer, M. Dapretto, B. Deen, S. Delmonte, I. Dinstein, B. Ertl-Wagner, D. A. Fair, L. Gallagher, D. P. Kennedy, C. L. Keown, C. Keysers, J. E. Lainhart, C. Lord, B. Luna, V . Menon, N. J. Minshew, C. S. Monk, S. Mueller, R.-A. M¨uller, M. B. Neb...
-
[43]
R. C. Craddock, G. A. James, P. E. Holtzheimer, X. P. Hu, and H. S. Mayberg. A whole brain fMRI atlas generated via spatially constrained spectral clustering.Human Brain Mapping, 33 (8):1914–1928, 2012. doi: 10.1002/hbm.21333. 12 A Theoretical Details A.1 Effect of conditional couplings on Frobenius risk Let us keep the same construction forI(X, θ)as in D...
-
[44]
To bound Equation (35), we must bound the operator norm ofD xu(s, x)
= Z t 0 d ds u(s, Iθ s )ds = Z t 0 ∂su(s, Iθ s ) +D xu(s, Iθ s ) ˙I θ s ds = Z t 0 ∂su(s, Iθ s ) +D xu(s, Iθ s ) vθ s(I θ s ) ds(34) Substituting the transport equation identity∂ su(s, Iθ s ) =−D xu(s, Iθ s )[vs(I θ s )]from Equation (32) into the integral, the partial derivative∂ suelegantly cancels out, leaving only the residual of the vector fields: I ...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.