Unsupervised Continual Clustering via Forward-Backward Knowledge Distillation
Pith reviewed 2026-06-27 22:31 UTC · model grok-4.3
The pith
Forward-backward distillation lets a teacher network learn new clusters while retaining old structures without past data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
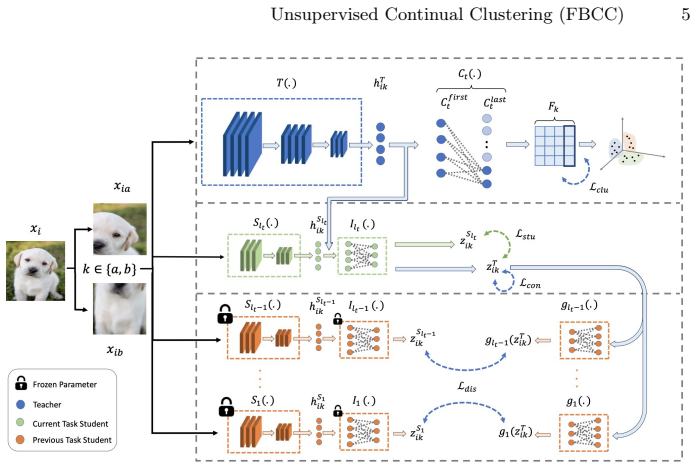
FBCC employs a continual teacher network with a clustering projector and lightweight task-specific students. Through a dual-phase forward-backward distillation process, the teacher learns new clusters while preserving previously discovered cluster structure without storing past data.
What carries the argument
Dual-phase forward-backward knowledge distillation between the continual teacher network and the task-specific student networks.
If this is right
- Clustering accuracy on each new task exceeds that of standard continual-learning baselines.
- Catastrophic forgetting of earlier cluster assignments is reduced without any stored past examples.
- Memory and privacy concerns from replay buffers are avoided while still supporting sequential tasks.
- The same teacher can be updated across multiple benchmark datasets without task-specific retraining from scratch.
Where Pith is reading between the lines
- The approach could be tested on streaming image or sensor data where cluster boundaries evolve gradually over months.
- If the teacher-student separation scales, longer task sequences might become feasible before performance degrades.
- The method might combine with other unsupervised objectives such as contrastive losses to further stabilize representations.
Load-bearing premise
The backward distillation step can keep earlier cluster assignments stable using only the current data and the student models.
What would settle it
Measure clustering accuracy on the first task after many later tasks arrive; if accuracy falls sharply while a replay baseline stays high, the preservation claim does not hold.
Figures
read the original abstract
Unsupervised Continual Learning (UCL) aims to enable neural networks to learn sequential tasks without labels or access to past data. A major challenge in this setting is Catastrophic Forgetting, where models forget previously learned tasks upon learning new ones. This challenge is amplified in UCL due to the absence of labels to guide learning and memory retention. Existing mitigation strategies, such as knowledge distillation and replay buffers, often raise memory and privacy concerns. Moreover, current UCL methods largely overlook clustering-specific objectives. To fill this gap, we introduce Unsupervised Continual Clustering (UCC) and propose Forward-Backward Knowledge Distillation for Continual Clustering (FBCC). FBCC employs a continual teacher network with a clustering projector and lightweight task-specific students. Through a dual-phase forward-backward distillation process, the teacher learns new clusters while preserving previously discovered cluster structure without storing past data. FBCC represents a pioneering approach to UCC, demonstrating improved clustering performance across sequential tasks. Experiments on four benchmark datasets demonstrate that FBCC consistently outperforms existing continual learning baselines in clustering accuracy while significantly reducing catastrophic forgetting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Unsupervised Continual Clustering (UCC) setting and proposes Forward-Backward Knowledge Distillation for Continual Clustering (FBCC). FBCC maintains a continual teacher network equipped with a clustering projector alongside lightweight task-specific student networks; a dual-phase forward-backward distillation procedure is claimed to allow the teacher to acquire new clusters on the current task while the backward pass from students preserves previously discovered cluster structure in the shared projector, all without storing past data or labels. Experiments on four benchmark datasets are reported to show consistent gains in clustering accuracy and reduced catastrophic forgetting relative to existing continual-learning baselines.
Significance. If the preservation mechanism can be shown to hold without access to past data, the work would address a genuine gap in unsupervised continual learning by avoiding replay buffers and label supervision. The introduction of the UCC setting itself is a useful framing, and the dual-phase distillation architecture is a concrete proposal that could be built upon.
major comments (3)
- [§3.2] §3.2 (Backward Distillation Phase): The only retention signal described is the distillation loss computed on current-task data; no explicit pseudo-label consistency term, centroid regularization, or frozen projector components are introduced that would prevent representation drift for old clusters when the shared teacher parameters are updated. This leaves the central claim that prior cluster structure is locked in place without past data dependent on an unverified empirical outcome rather than a construction that guarantees retention.
- [§4.2, Table 2] §4.2 (Experimental Setup) and Table 2: The reported clustering accuracy improvements are presented without ablation isolating the contribution of the backward pass versus the forward pass alone, nor are error bars or statistical significance tests provided across the four datasets. Without these controls it is difficult to attribute the reduction in forgetting specifically to the proposed dual-phase mechanism.
- [§3.1] §3.1 (Architecture): The task-specific students are described as lightweight, yet the paper does not specify whether their parameters are discarded after each task or retained; if the latter, the memory footprint claim relative to replay-based baselines requires explicit quantification.
minor comments (2)
- [Abstract] The abstract states that FBCC 'significantly reduc[es] catastrophic forgetting' but the main text should define the precise forgetting metric (e.g., average accuracy drop or normalized mutual information change) used in the tables.
- [§3] Notation for the clustering projector and the forward vs. backward losses should be introduced once in §3 and used consistently thereafter to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the UCC setting and FBCC method. We address each major comment below, proposing revisions to strengthen the manuscript where the points identify gaps in clarity or evidence.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Backward Distillation Phase): The only retention signal described is the distillation loss computed on current-task data; no explicit pseudo-label consistency term, centroid regularization, or frozen projector components are introduced that would prevent representation drift for old clusters when the shared teacher parameters are updated. This leaves the central claim that prior cluster structure is locked in place without past data dependent on an unverified empirical outcome rather than a construction that guarantees retention.
Authors: We agree that the retention mechanism relies on the backward distillation loss applied solely to current-task data and does not include additional explicit terms such as pseudo-label consistency or frozen components. The design intends for the student-to-teacher backward pass to enforce consistency on the shared projector by construction, as the students are optimized to match the teacher's current clustering while the teacher incorporates new clusters. However, this is indeed an empirical outcome rather than a formal guarantee. We will revise §3.2 to explicitly state this reliance and add a short discussion of why drift is mitigated in practice, along with a new experiment measuring projector stability across tasks. revision: partial
-
Referee: [§4.2, Table 2] §4.2 (Experimental Setup) and Table 2: The reported clustering accuracy improvements are presented without ablation isolating the contribution of the backward pass versus the forward pass alone, nor are error bars or statistical significance tests provided across the four datasets. Without these controls it is difficult to attribute the reduction in forgetting specifically to the proposed dual-phase mechanism.
Authors: The referee correctly identifies the absence of an ablation separating forward-only from full forward-backward distillation, as well as the lack of error bars and significance testing. We will add these in a revised §4.2 and updated Table 2: an ablation study across all datasets, results reported as mean ± std over 5 random seeds, and paired t-tests for key comparisons. This will allow direct attribution of gains to the dual-phase mechanism. revision: yes
-
Referee: [§3.1] §3.1 (Architecture): The task-specific students are described as lightweight, yet the paper does not specify whether their parameters are discarded after each task or retained; if the latter, the memory footprint claim relative to replay-based baselines requires explicit quantification.
Authors: The task-specific student parameters are discarded after each task completes, preserving the memory-efficiency claim. We will revise §3.1 to state this explicitly and add a memory-footprint comparison table (parameters and storage) against replay baselines to quantify the advantage. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and context describe FBCC as a novel dual-phase distillation architecture for unsupervised continual clustering, with the teacher-student setup claimed to enable new cluster learning while retaining prior structure via distillation loss on current data only. No equations, parameter-fitting procedures, self-citations, or uniqueness theorems are quoted that would allow reduction of any prediction or preservation claim to an input by construction. The central mechanism is presented as an empirical outcome of the proposed forward-backward process rather than a self-referential definition or renamed known result. Absent load-bearing self-citations or fitted-input predictions in the text, the method description remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
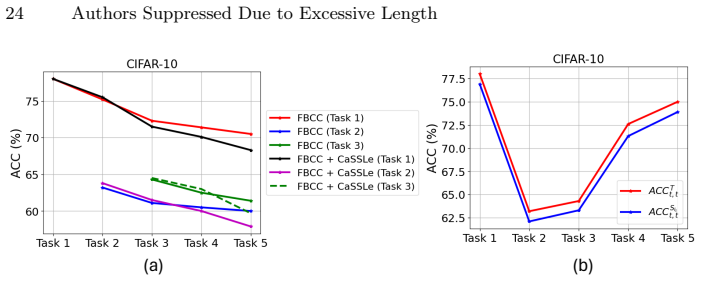
Works this paper leans on
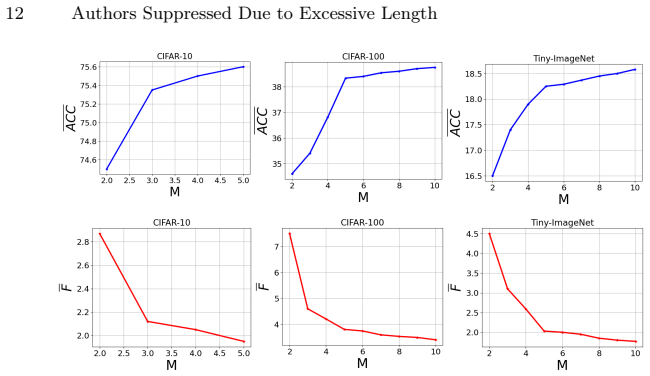
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
Aghasanli, A., Li, Y., Angelov, P.: Prototype-based continual learning with label- free replay buffer and cluster preservation loss. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). pp. 6545–6554 (2025)
2025
-
[2]
Entropy24(4), 551 (2022)
Albelwi, S.: Survey on self-supervised learning: auxiliary pretext tasks and con- trastive learning methods in imaging. Entropy24(4), 551 (2022)
2022
-
[3]
In: Proceedings of the European Conference on Computer Vision (ECCV) (September 2018)
Aljundi, R., Babiloni, F., Elhoseiny, M., Rohrbach, M., Tuytelaars, T.: Memory aware synapses: Learning what (not) to forget. In: Proceedings of the European Conference on Computer Vision (ECCV) (September 2018)
2018
-
[4]
PeerJ Computer Science7, e474 (2021)
Alkhulaifi, A., Alsahli, F., Ahmad, I.: Knowledge distillation in deep learning and its applications. PeerJ Computer Science7, e474 (2021)
2021
-
[5]
In: International Conference on Learning Representations (ICLR) (2022)
Arani, E., Sarfraz, F., Zonooz, B.: Learning fast, learning slow: A general contin- ual learning method based on complementary learning system. In: International Conference on Learning Representations (ICLR) (2022)
2022
-
[6]
IEEE Transactions on Neural Networks and Learning Systems34(12), 9992–10003 (2022)
Ashfahani, A., Pratama, M.: Unsupervised continual learning in streaming envi- ronments. IEEE Transactions on Neural Networks and Learning Systems34(12), 9992–10003 (2022)
2022
-
[7]
In: Proceedings of the IEEE/CVF International conference on computer vision
Cha, H., Lee, J., Shin, J.: Co2l: Contrastive continual learning. In: Proceedings of the IEEE/CVF International conference on computer vision. pp. 9516–9525 (2021)
2021
-
[8]
arXiv preprint arXiv:2002.05709 (2020)
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. arXiv preprint arXiv:2002.05709 (2020)
Pith/arXiv arXiv 2002
-
[9]
arXiv preprint arXiv:2103.05484 (2021)
Dang, Z., Deng, C., Yang, X., Huang, H.: Doubly contrastive deep clustering. arXiv preprint arXiv:2103.05484 (2021)
arXiv 2021
-
[10]
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet full (fall 2011 release)
2011
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Fini, E., Da Costa, V.G.T., Alameda-Pineda, X., Ricci, E., Alahari, K., Mairal, J.: Self-supervised models are continual learners. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9621–9630 (2022)
2022
-
[12]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Gomez-Villa, A., Twardowski, B., Wang, K., van de Weijer, J.: Plasticity-optimized complementary networks for unsupervised continual learning. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 1690–1700 (2024)
2024
-
[13]
In: Proceedings of the 26th International Joint Conference on Artificial Intelligence
Guo, X., Gao, L., Liu, X., Yin, J.: Improved deep embedded clustering with local structure preservation. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence. p. 1753–1759. IJCAI’17, AAAI Press (2017)
2017
-
[14]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016) Unsupervised Continual Clustering (FBCC) 15
2016
-
[15]
1314–1324 (2019)
Howard, A.G., Sandler, M., Chu, G., Chen, L.C., Chen, B., Tan, M., Wang, W., Zhu, Y., Pang, R., Vasudevan, V., Le, Q.V., Adam, H.: Searching for mobilenetv3 pp. 1314–1324 (2019)
2019
-
[16]
In: 2014 22nd International Conference on Pattern Recognition
Huang, P., Huang, Y., Wang, W., Wang, L.: Deep embedding network for cluster- ing. In: 2014 22nd International Conference on Pattern Recognition. pp. 1532–1537 (2014)
2014
-
[18]
arXiv preprint arXiv:1602.07360 (2016)
Iandola, F.N., Han, S., Moskewicz, M.W., Ashraf, K., Dally, W.J., Keutzer, K.: Squeezenet: Alexnet-level accuracy with 50x fewer parameters and< 0.5 mb model size. arXiv preprint arXiv:1602.07360 (2016)
Pith/arXiv arXiv 2016
-
[19]
In: Proceedings of the 34th Interna- tional Conference on Neural Information Processing Systems
Jung, S., Ahn, H., Cha, S., Moon, T.: Continual learning with node-importance based adaptive group sparse regularization. In: Proceedings of the 34th Interna- tional Conference on Neural Information Processing Systems. NIPS’20, Curran Associates Inc., Red Hook, NY, USA (2020)
2020
-
[20]
Krizhevsky, A., Nair, V., Hinton, G.: Cifar-10 (canadian institute for advanced research),http://www.cs.toronto.edu/~kriz/cifar.html
-
[22]
In: Proc
Li, J., Ji, Z., Wang, G., Wang, Q., Gao, F.: Learning from students: Online con- trastive distillation network for general continual learning. In: Proc. 31st Int. Joint Conf. Artif. Intell. pp. 3215–3221 (2022)
2022
-
[23]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, Y., Hu, P., Liu, Z., Peng, D., Zhou, J.T., Peng, X.: Contrastive clustering. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 35, pp. 8547– 8555 (2021)
2021
-
[24]
International Journal of Computer Vision130(9), 2205–2221 (2022)
Li, Y., Yang, M., Peng, D., Li, T., Huang, J., Peng, X.: Twin contrastive learning for online clustering. International Journal of Computer Vision130(9), 2205–2221 (2022)
2022
-
[25]
In: 2022 IEEE International Conference on Multimedia and Expo (ICME)
Lin, Z., Wang, Y., Lin, H.: Continual contrastive learning for image classification. In: 2022 IEEE International Conference on Multimedia and Expo (ICME). pp. 1–6. IEEE (2022)
2022
-
[26]
In: Proceedings of the European conference on computer vision (ECCV)
Ma, N., Zhang, X., Zheng, H.T., Sun, J.: Shufflenet v2: Practical guidelines for efficient cnn architecture design. In: Proceedings of the European conference on computer vision (ECCV). pp. 116–131 (2018)
2018
-
[27]
arXiv preprint arXiv:2110.06976 (2021)
Madaan, D., Yoon, J., Li, Y., Liu, Y., Hwang, S.J.: Representational continuity for unsupervised continual learning. arXiv preprint arXiv:2110.06976 (2021)
arXiv 2021
-
[28]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Mai, Z., Li, R., Kim, H., Sanner, S.: Supervised contrastive replay: Revisiting the nearest class mean classifier in online class-incremental continual learning. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 3589–3599 (2021)
2021
-
[29]
In: Proceedings of the AAAI Conference on Artificial In- telligence (2019)
Paik, I., Oh, S., Kwak, T., Kim, I.: Overcoming catastrophic forgetting by neuron- level plasticity control. In: Proceedings of the AAAI Conference on Artificial In- telligence (2019)
2019
-
[30]
Poulakakis-Daktylidis, S., Jamali-Rad, H.: Beclr: Batch enhanced contrastive few- shot learning (2024), arXiv:2402.02444
arXiv 2024
-
[31]
Neu- rocomputing404, 381–400 (2020) 16 Authors Suppressed Due to Excessive Length
Ramapuram, J., Gregorova, M., Kalousis, A.: Lifelong generative modeling. Neu- rocomputing404, 381–400 (2020) 16 Authors Suppressed Due to Excessive Length
2020
-
[32]
In: Advances in Neural Information Processing Systems (NeurIPS 2019) (2019)
Rao, D., Visin, F., Rusu, A.A., Teh, Y.W., Pascanu, R., Hadsell, R.: Continual un- supervised representation learning. In: Advances in Neural Information Processing Systems (NeurIPS 2019) (2019)
2019
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Rim, P., Park, H., Gangopadhyay, S., Zeng, Z., Chung, Y., Wong, A.: Protodepth: Unsupervised continual depth completion with prototypes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6304–6316 (2025)
2025
-
[34]
Rusu, A.A., Rabinowitz, N.C., Desjardins, G., Soyer, H., Kirkpatrick, J., Kavukcuoglu, K., Pascanu, R., Hadsell, R.: Progressive neural networks (2022)
2022
-
[35]
In: The Twelfth International Conference on Learning Representations (2024)
Rypeść, G., Cygert, S., Khan, V., Trzcinski, T., Zieliński, B.M., Twardowski, B.: Divide and not forget: Ensemble of selectively trained experts in continual learning. In: The Twelfth International Conference on Learning Representations (2024)
2024
-
[36]
TechRxiv (2022)
Sadeghi,M.,Armanfard,N.:Deepmulti-representationlearningfordataclustering. TechRxiv (2022)
2022
-
[37]
IEEE Access (2025)
Sadeghi, M., Soleimani, S., Armanfard, N.: Deep clustering with self-supervision using pairwise similarities. IEEE Access (2025)
2025
-
[38]
In: 2021 IEEE International Conference on Image Processing (ICIP)
Sadeghi, M., Armanfard, N.: Idecf: Improved deep embedding clustering with deep fuzzy supervision. In: 2021 IEEE International Conference on Image Processing (ICIP). pp. 1009–1013 (2021)
2021
-
[39]
The 34th British Machine Vision Conference (BMVC) (2023)
Sadeghi, M., Hojjati, H., Armanfard, N.: C3: Cross-instance guided contrastive clustering. The 34th British Machine Vision Conference (BMVC) (2023)
2023
-
[40]
Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence (2021)
Smith, J., Taylor, C., Baer, S., Dovrolis, C.: Unsupervised progressive learning and the stam architecture. Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence (2021)
2021
-
[41]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Sun, H., Zhang, Y., Xu, L., Jin, S., Luo, P., Qian, C., Liu, W., Chen, Y.: Unsuper- vised continual domain shift learning with multi-prototype modeling. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10131–10141 (2025)
2025
-
[42]
Nature Machine Intelligence5(12), 1356–1368 (2023)
Wang, L., Zhang, X., Li, Q., Zhang, M., Su, H., Zhu, J., Zhong, Y.: Incorporating neuro-inspired adaptability for continual learning in artificial intelligence. Nature Machine Intelligence5(12), 1356–1368 (2023)
2023
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, L., Yang, K., Li, C., Hong, L., Li, Z., Zhu, J.: Ordisco: Effective and effi- cient usage of incremental unlabeled data for semi-supervised continual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5383–5392 (2021)
2021
-
[44]
arXiv preprint arXiv:2302.00487 (2023)
Wang, L., Zhang, X., Su, H., Zhu, J.: A comprehensive survey of continual learning: Theory, method and application. arXiv preprint arXiv:2302.00487 (2023)
arXiv 2023
-
[45]
In: 2017 10th International Symposium on Computational Intelligence and Design (ISCID)
Wang, X., Wang, L.: Research on intrusion detection based on feature extraction of autoencoder and the improved k-means algorithm. In: 2017 10th International Symposium on Computational Intelligence and Design (ISCID). vol. 2, pp. 352–
2017
-
[46]
In: IEEE International Conference on Data Mining (ICDM)
Wang, Z., Wang, X., Zhang, S.: Mostream: A modular and self-optimizing data stream clustering algorithm. In: IEEE International Conference on Data Mining (ICDM). pp. 500–509 (2024)
2024
-
[47]
In: Advances in Neural Information Processing Systems (NeurIPS 2018) (2018)
Wu, C., Herranz, L., Liu, X., Wang, Y., van de Weijer, J., Raducanu, B.: Memory replay gans: Learning to generate images from new categories without forgetting. In: Advances in Neural Information Processing Systems (NeurIPS 2018) (2018)
2018
-
[48]
Engineering Applications of Artificial Intelligence133, 108612 (2024) Unsupervised Continual Clustering (FBCC) 17
Wu, W., Wang, W., Jia, X., Feng, X.: Transformer autoencoder for k-means ef- ficient clustering. Engineering Applications of Artificial Intelligence133, 108612 (2024) Unsupervised Continual Clustering (FBCC) 17
2024
-
[49]
In: Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48
Xie, J., Girshick, R., Farhadi, A.: Unsupervised deep embedding for clustering analysis. In: Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48. p. 478–487. ICML’16, JMLR.org (2016)
2016
-
[50]
In: Proceedings of the 34th Interna- tional Conference on Machine Learning (ICML)
Yang, B., Fu, X., Sidiropoulos, N.D., Hong, M.: Towards k-means-friendly spaces: Simultaneous deep learning and clustering. In: Proceedings of the 34th Interna- tional Conference on Machine Learning (ICML). pp. 3861–3870 (2017)
2017
-
[51]
Engineering Applications of Artificial Intelligence162, 112317 (2025)
Yang, Z., Li, K., Huang, Z., Xu, Z., Zhu, X., Xiao, Y.: A combined perspective self-supervised contrastive learning framework for human activity recognition in- tegrating instance prediction and clustering. Engineering Applications of Artificial Intelligence162, 112317 (2025)
2025
-
[52]
In: International Conference on Learning Representations (ICLR) (2022)
Yoon, J., Madaan, D., Yang, E., Hwang, S.J.: Online coreset selection for rehearsal- based continual learning. In: International Conference on Learning Representations (ICLR) (2022)
2022
-
[53]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Yu, X., Rosing, T., Guo, Y.: Evolve: Enhancing unsupervised continual learning with multiple experts. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 2366–2377 (2024)
2024
-
[54]
reliable
Yu, X., Guo, Y., Gao, S., Rosing, T.: Scale: Online self-supervised lifelong learn- ing without prior knowledge. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2483–2494 (2023) 18 Authors Suppressed Due to Excessive Length A Implementation Details In Section 4.3 of the main manuscript, we demonstrate that consid...
2023
-
[55]
This approach is commonly adopted in continual learning research [11], [25], and [27]
In the first setting, referred to as Case 1, we randomly select 10 tasks. This approach is commonly adopted in continual learning research [11], [25], and [27]. In the second setting, or Case 2, we ensure that each task contains data samples from two distinct super-classes within the CIFAR-100 dataset. Unsupervised Continual Clustering (FBCC) 25 We apply ...
-
[56]
Algorithms CIFAR-100 ACC(↑)F(↓) Case 1 38.73 3.62 Case 2 39.49 3.38 T able 7.FBCC computational and memory efficiency comparison against existing UCL
The best result for continual learning algorithms in each column is highlighted in bold. Algorithms CIFAR-100 ACC(↑)F(↓) Case 1 38.73 3.62 Case 2 39.49 3.38 T able 7.FBCC computational and memory efficiency comparison against existing UCL. AlgorithmsTotal Training Time (s)Max GPU Memory (MB)Model Size (MB)Trainable Parameters (m) CCL 25133.49 1221.85 164....
2088
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.