Modelling Opinion Dynamics at Scale with Deep MARL
Pith reviewed 2026-06-27 20:06 UTC · model grok-4.3
The pith
High conformity in large social media networks reduces collective accuracy and promotes agents that lie to fit in.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
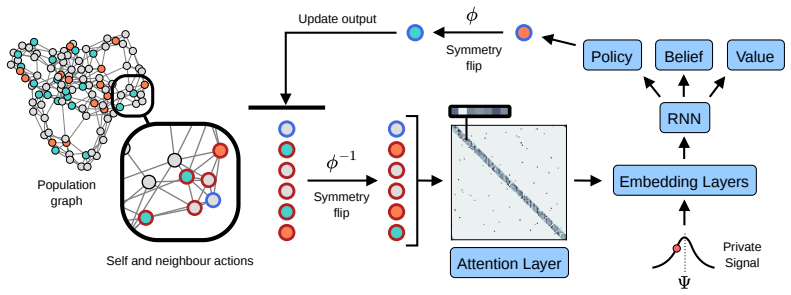
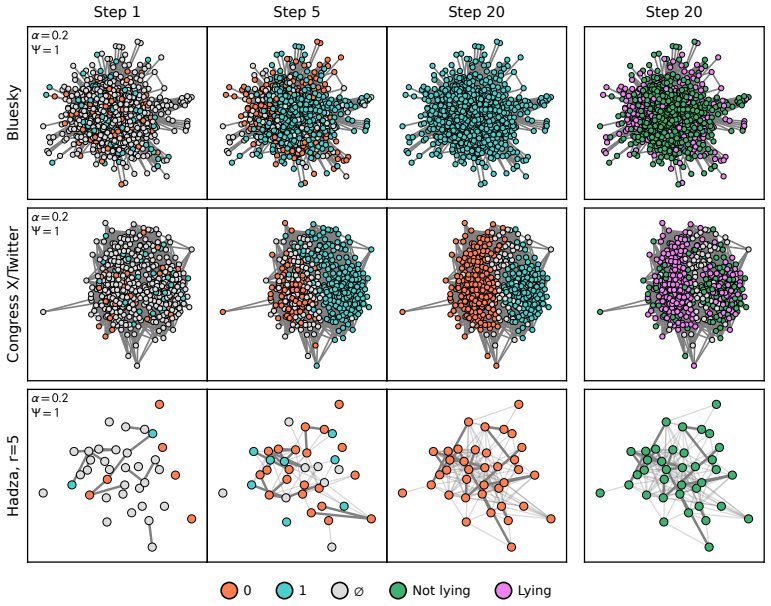
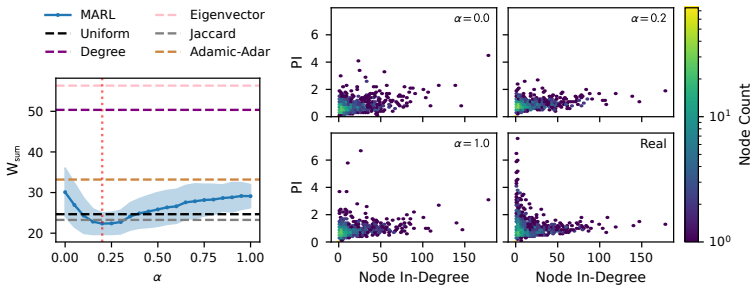
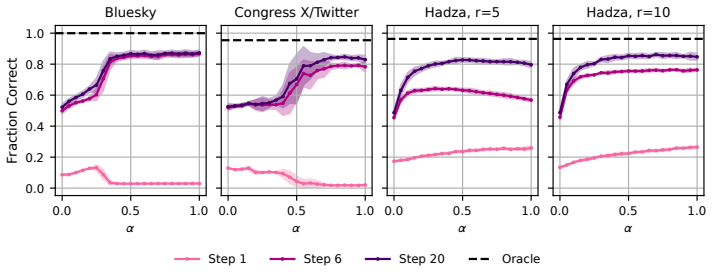
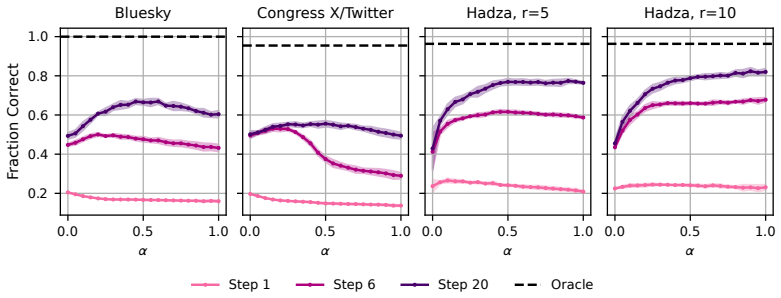
A GPU-accelerated consensus and truth-finding game trained with deep MARL and extended other-play produces agent behaviors that, when an attention layer is trained on Bluesky graph topology alone, recover realistic importance rankings; the same model shows that high conformity in large populations lowers collective accuracy and favors dishonest agents, whereas in small dynamic populations conformity can raise agreement.
What carries the argument
The GPU-accelerated consensus and truth-finding game with extended other-play, whose learned attention layer recovers agent importance from graph topology.
If this is right
- High conformity reduces collective accuracy in large networks.
- High conformity promotes dishonest agents that lie to fit in large networks.
- Small dynamic networks are less harmed by high conformity.
- Conformity can improve collective agreement in small dynamic networks.
- A mismatch between evolved conformity and large online environments may contribute to misinformation.
Where Pith is reading between the lines
- Platform designs that reduce conformity pressure could raise the accuracy of shared information.
- Simulations of this kind could be used to test network interventions before deployment.
- The approach opens the possibility of studying how network size and change rate interact with learned social rules.
Load-bearing premise
The behaviors that emerge from the MARL consensus game with extended other-play correspond to real human opinion dynamics.
What would settle it
A direct measurement on the Bluesky network or similar data showing that higher conformity does not correlate with lower collective accuracy or increased dishonesty would falsify the main claim.
Figures

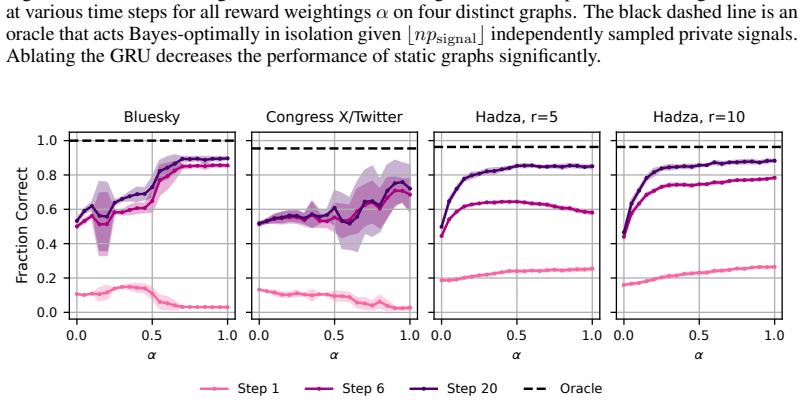
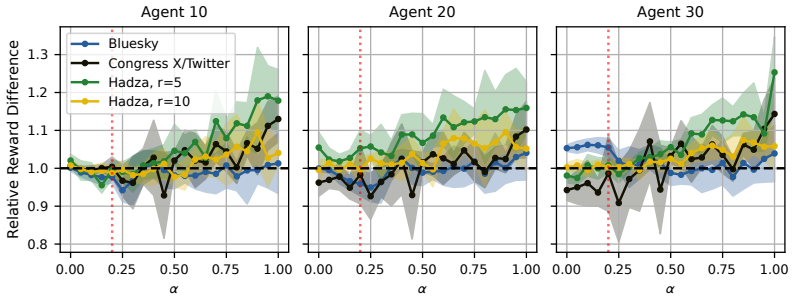
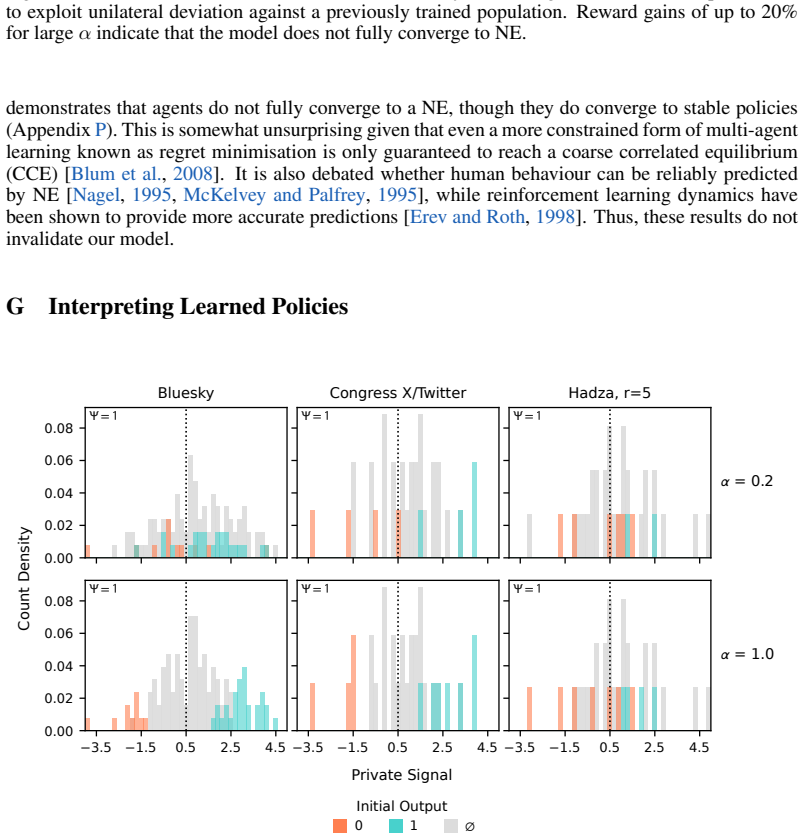
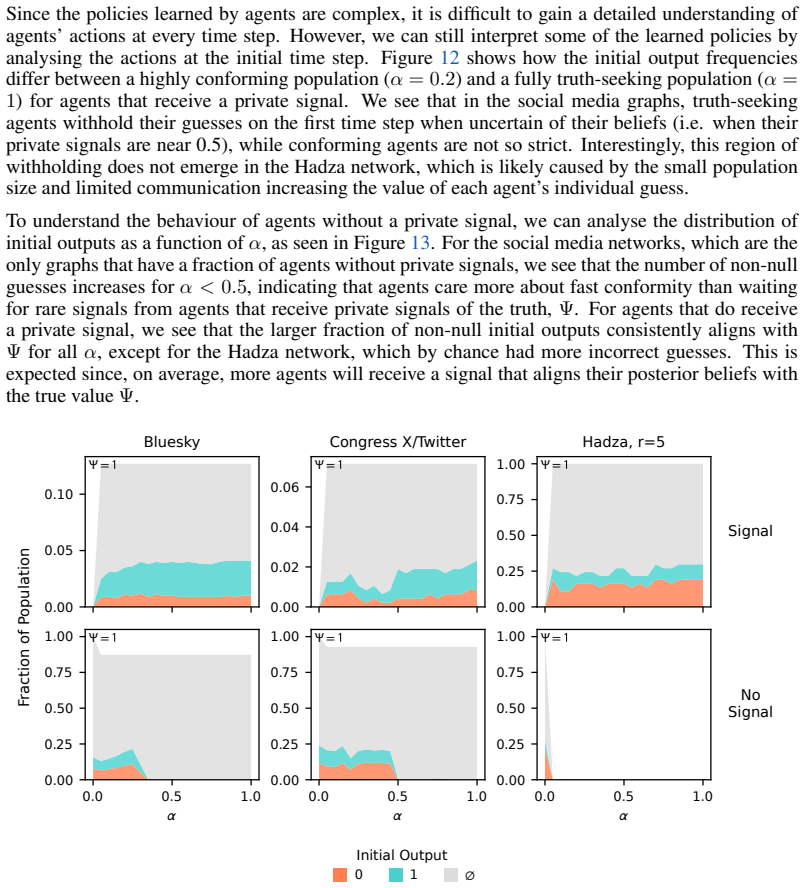
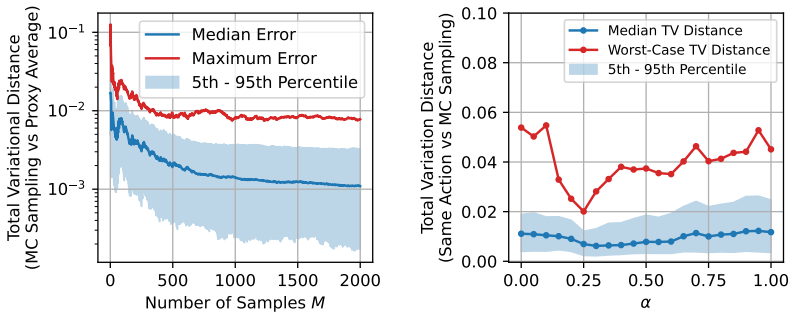
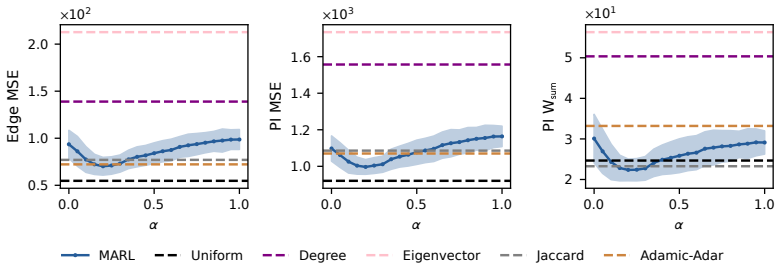
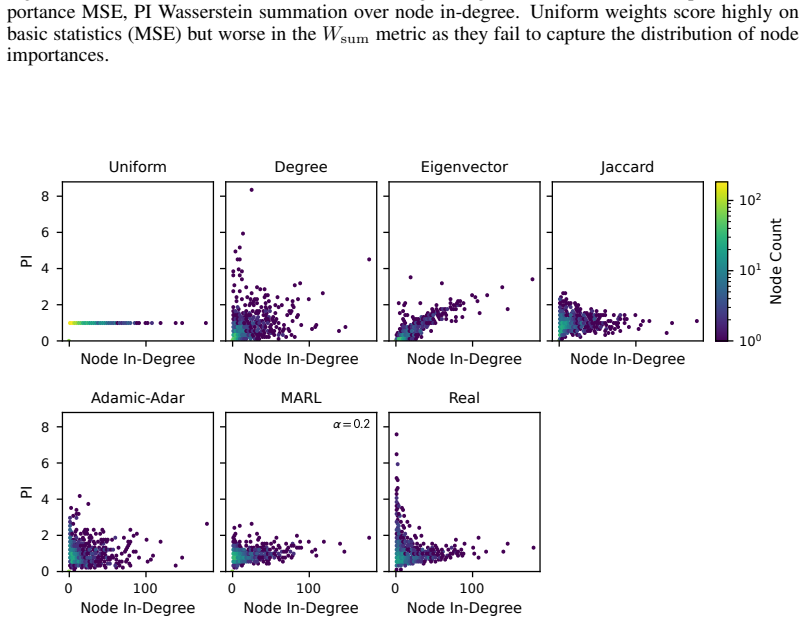
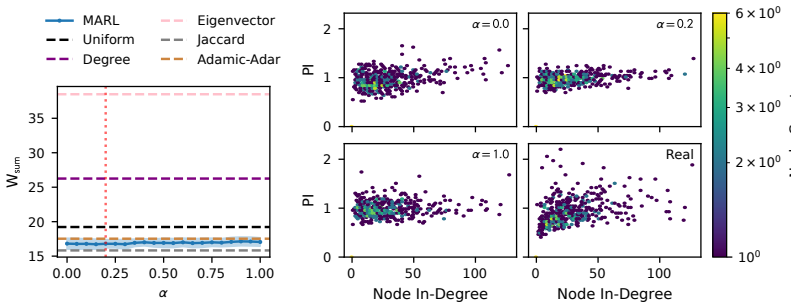
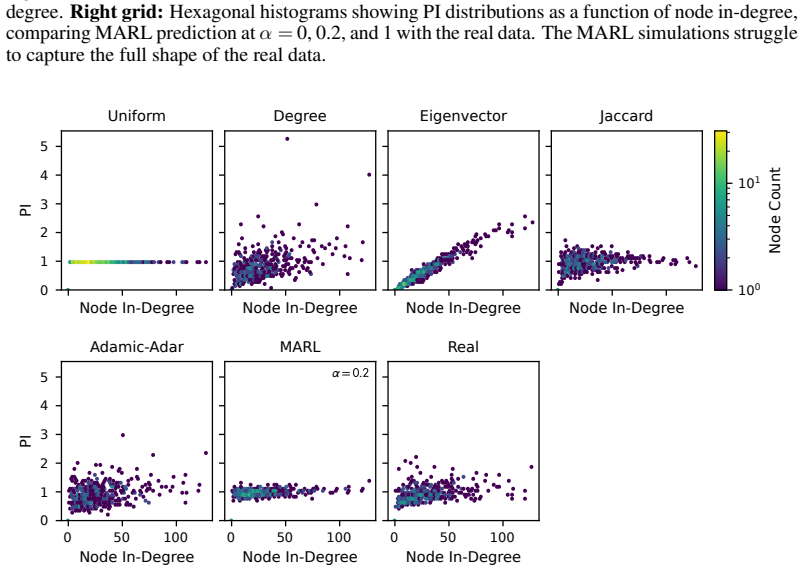
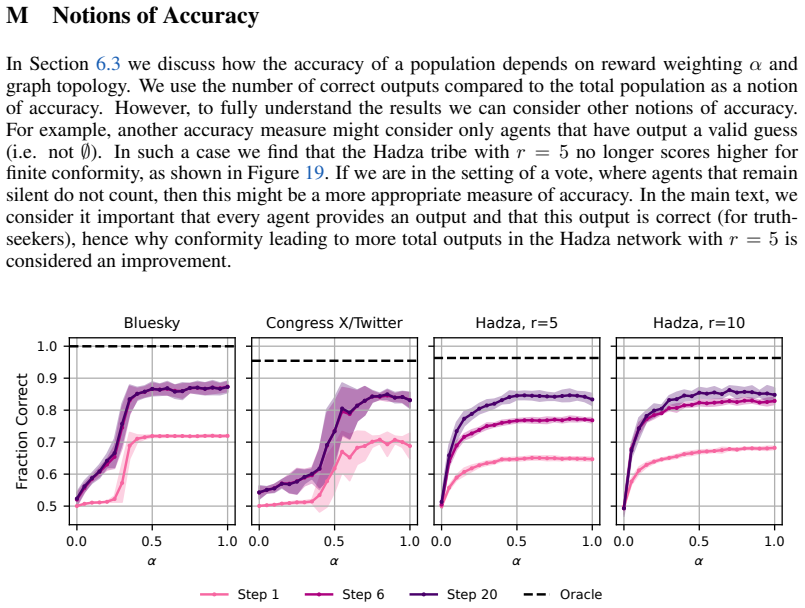
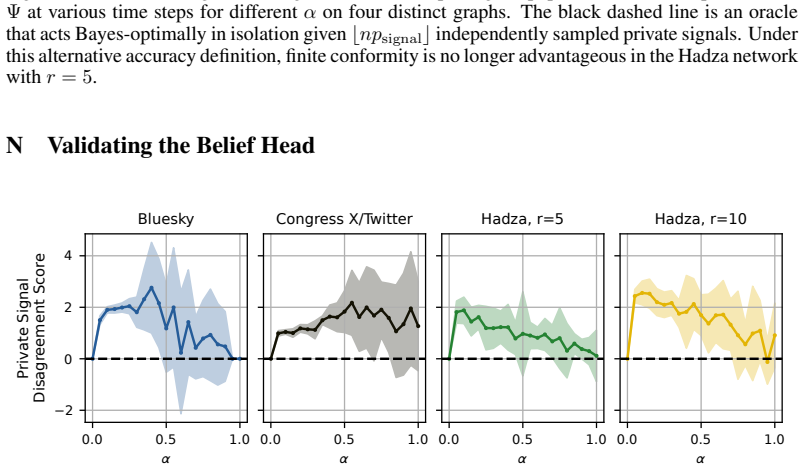
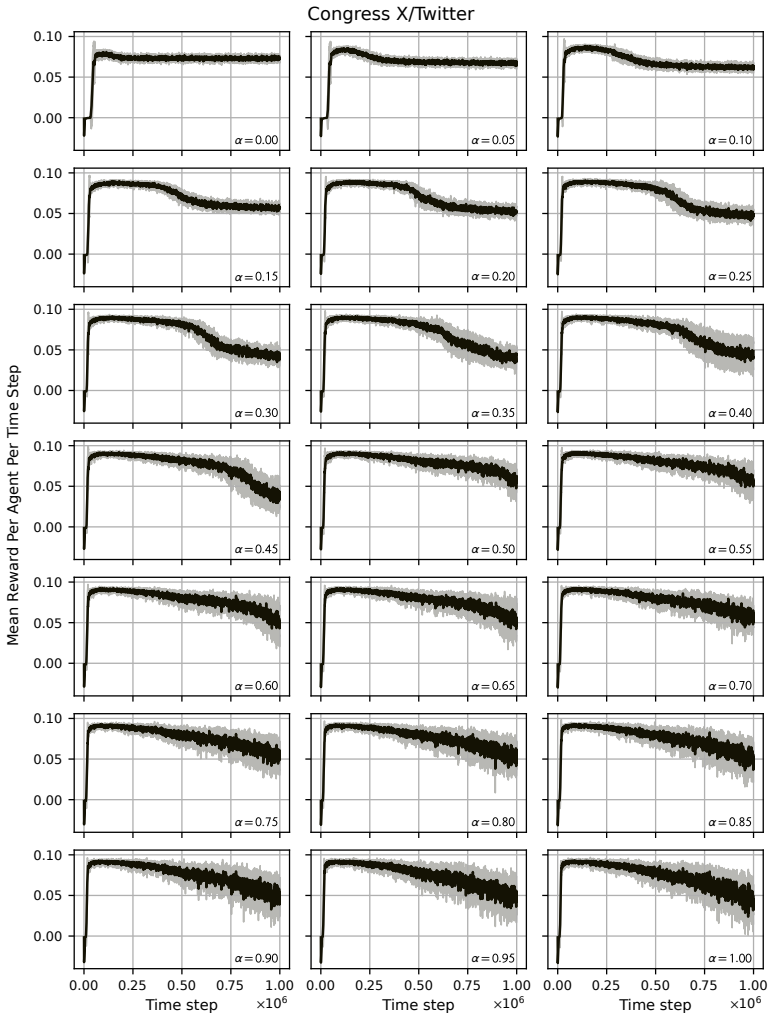
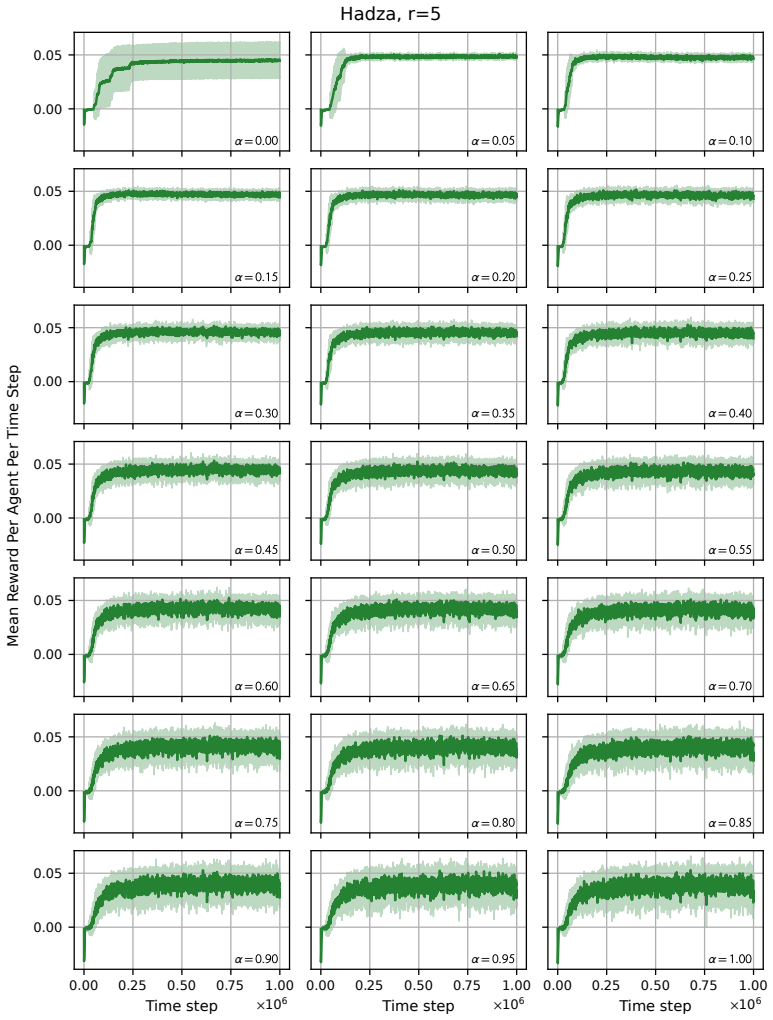
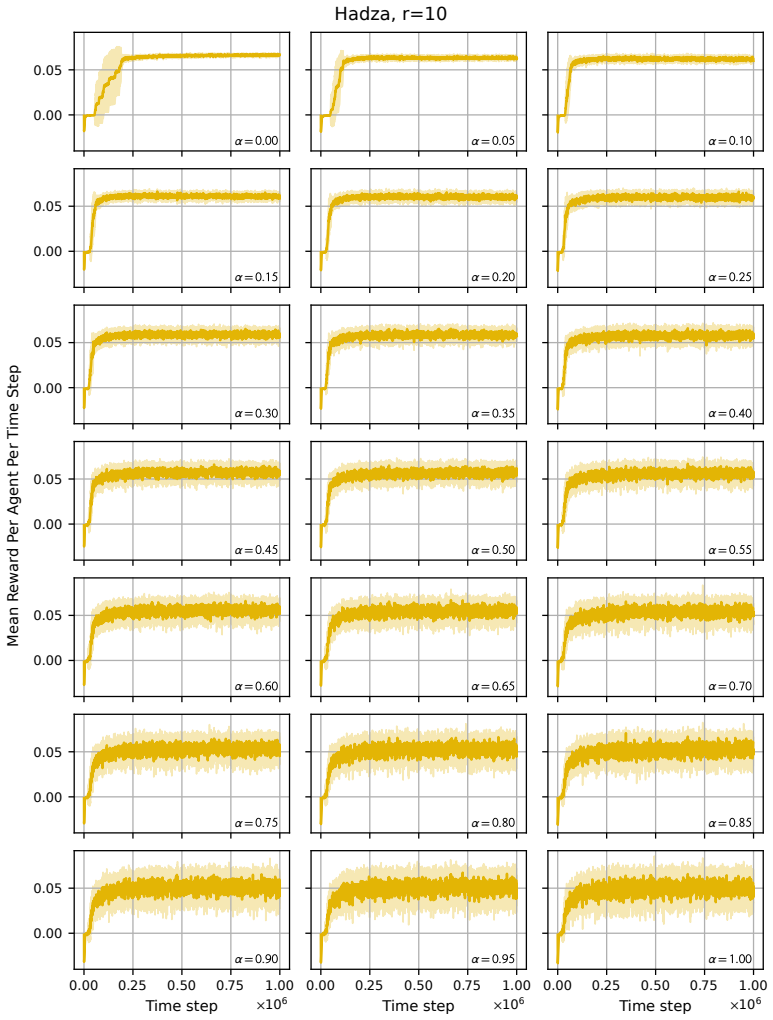
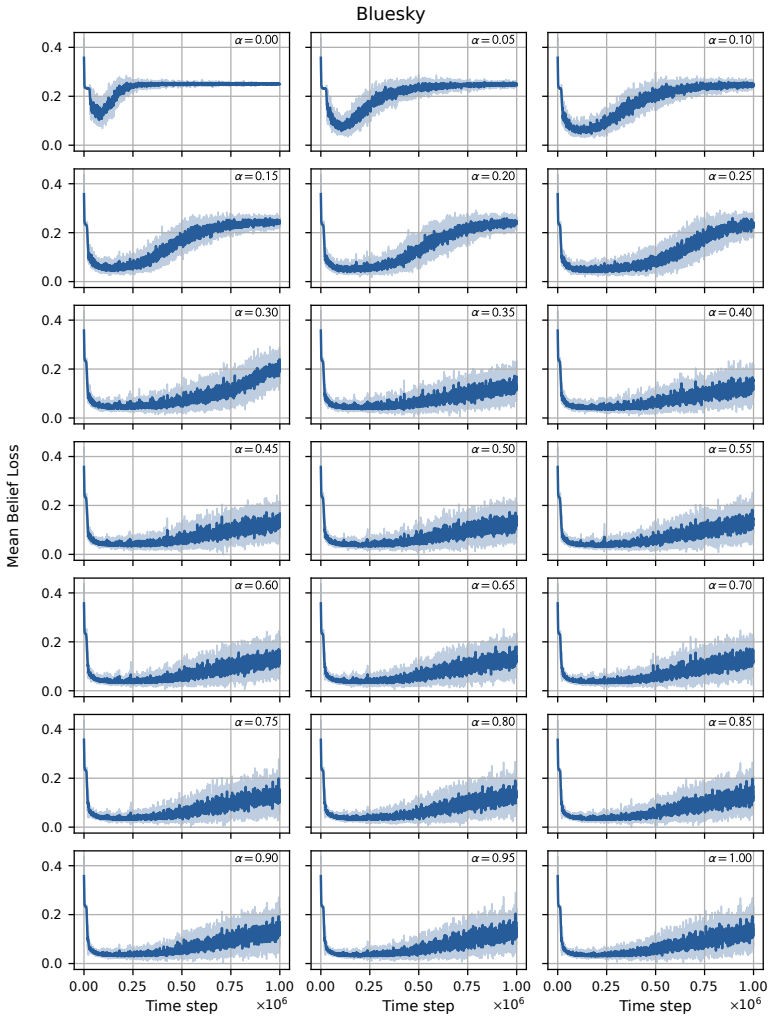
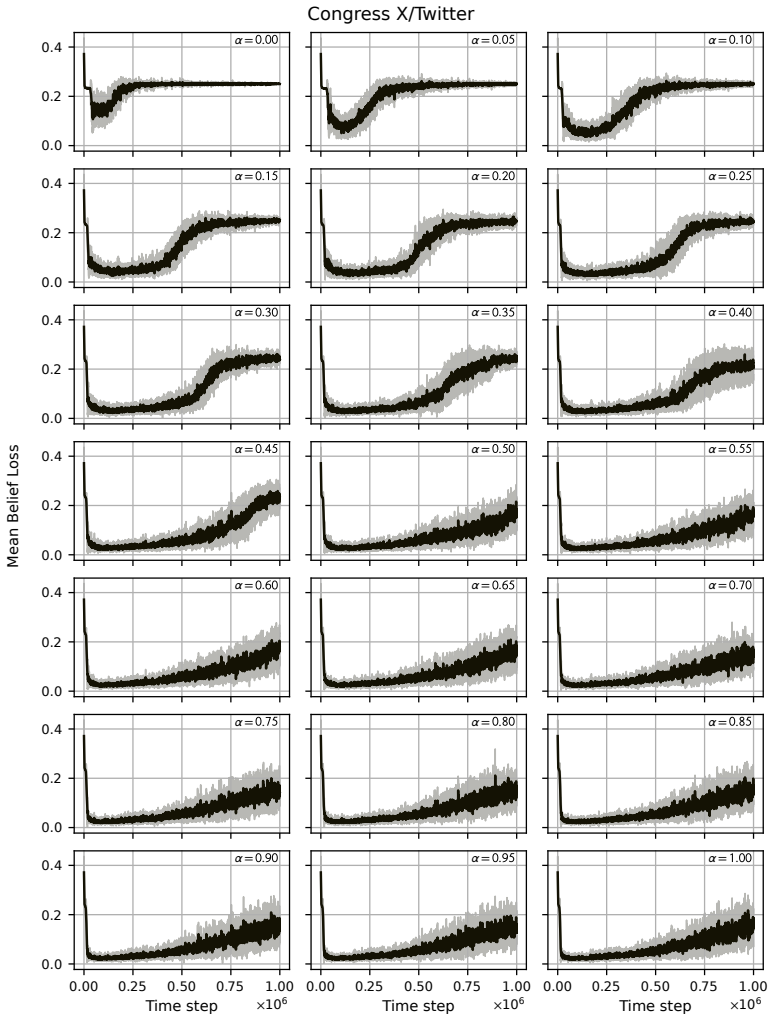
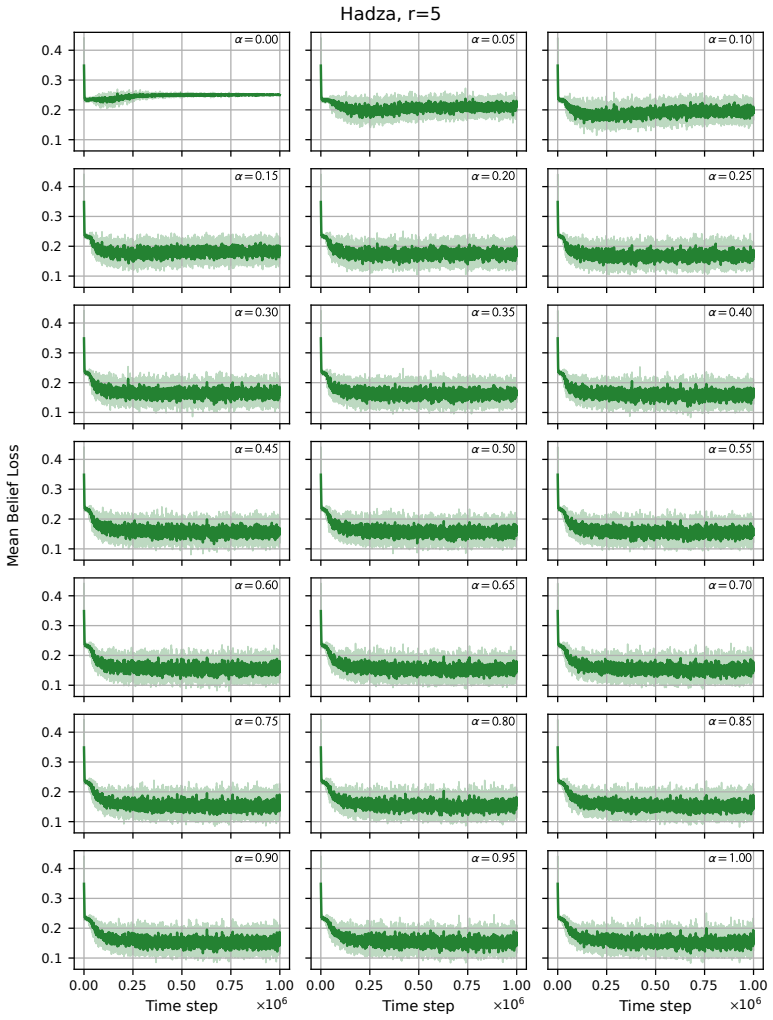
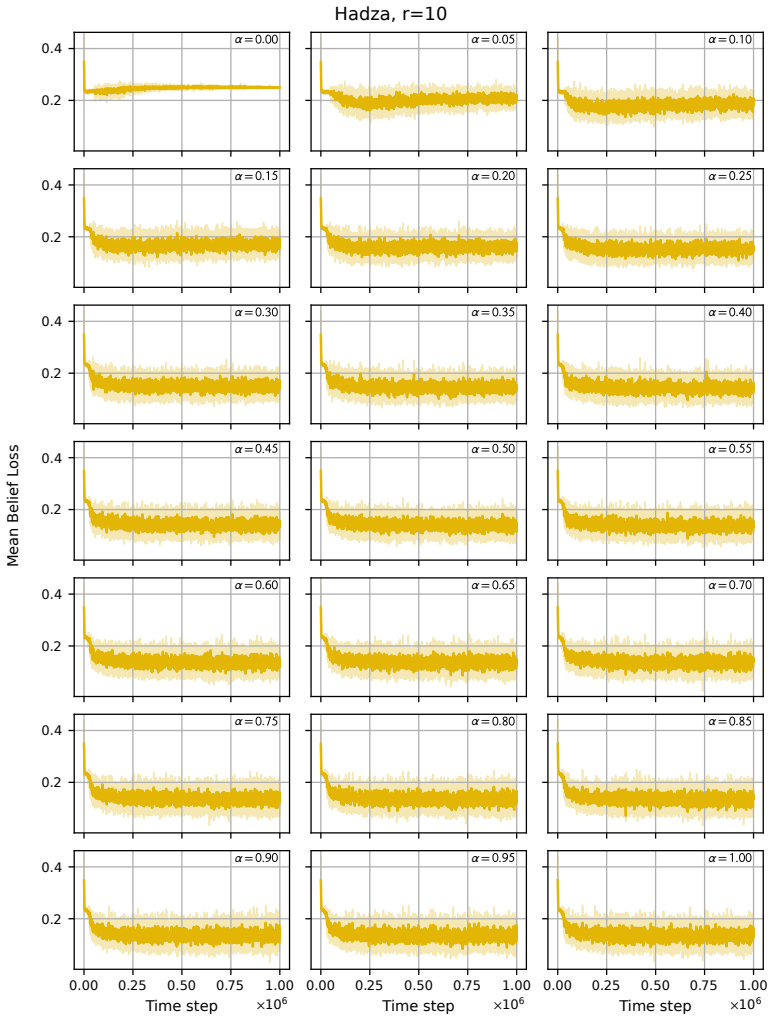
read the original abstract
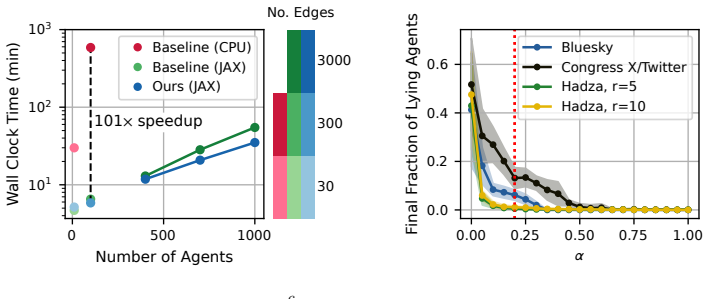
Modelling opinion dynamics typically relies on hand-crafted local interaction rules to study emergent macroscopic phenomena such as consensus and polarisation. In contrast, multi-agent reinforcement learning (MARL) enables agents to learn such behaviours directly by optimising simple rewards. To explore the potential of MARL for opinion dynamics, we introduce a GPU-accelerated consensus and truth-finding game that scales to populations of up to 1000 agents, comparable to many real-world social sub-networks. To prevent unrealistic conventions, we extend other-play to general-sum social interactions. We next validate our model on a subset of the Bluesky network by recovering agent importance structures from graph topology alone via a learned attention layer, finding that highly conforming populations most closely match human data. In large social media networks such high levels of conformity significantly reduce collective accuracy and promote dishonest agents that lie to fit in. By contrast, small, dynamic hunter-gatherer networks are less affected; here, conformity can even improve collective agreement. This suggests a mismatch between evolved human conformity heuristics and modern social media environments as a potential contributor to misinformation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a GPU-accelerated MARL consensus and truth-finding game that scales to 1000 agents. Agents learn opinion-update behaviors by optimizing rewards, with an extension of other-play to general-sum interactions to avoid unrealistic conventions. Validation on a Bluesky subgraph recovers agent importance structures via a learned attention layer, with highly conforming populations matching human data on this metric. Results indicate that high conformity in large networks reduces collective accuracy and promotes dishonest agents, while small dynamic networks are less affected and may benefit from conformity; this is interpreted as an evolutionary mismatch contributing to misinformation.
Significance. If the model produces behaviors that correspond to human opinion dynamics, the work offers a scalable alternative to hand-crafted rules for studying emergent phenomena like consensus and polarization, with potential implications for understanding misinformation in social media. The GPU scaling and attention-based recovery of network structures are technical strengths. However, the significance is constrained because the reported validation is limited to topological recovery rather than behavioral or outcome-level correspondence with human data.
major comments (2)
- [Validation on Bluesky network] Validation section (Bluesky experiment): recovery of agent importance structures from graph topology alone is shown to match human data most closely under high conformity. This metric does not test whether the learned conformity levels, truth-telling vs. lying equilibria, or collective accuracy outcomes reproduce patterns from human opinion-dynamics experiments. The central claims about reduced accuracy and promoted dishonesty in large networks therefore rest on an unanchored simulation-to-human mapping.
- [Results on network size and conformity] Results on network-size effects: the reported contrast between large social-media networks and small hunter-gatherer networks (conformity harming vs. helping collective accuracy) is load-bearing for the evolutionary-mismatch interpretation, yet no direct comparison to empirical human data on these outcomes is provided.
minor comments (1)
- [Abstract and validation] The abstract and validation description would benefit from explicit statement of the quantitative match metric (e.g., correlation or rank agreement) between the attention-derived importance and human data.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the technical contributions of the GPU scaling and attention mechanism. We address the two major comments point by point below, clarifying the scope of our validation and the basis for our interpretations while agreeing to strengthen the manuscript's caveats.
read point-by-point responses
-
Referee: Validation section (Bluesky experiment): recovery of agent importance structures from graph topology alone is shown to match human data most closely under high conformity. This metric does not test whether the learned conformity levels, truth-telling vs. lying equilibria, or collective accuracy outcomes reproduce patterns from human opinion-dynamics experiments. The central claims about reduced accuracy and promoted dishonesty in large networks therefore rest on an unanchored simulation-to-human mapping.
Authors: We agree that the Bluesky validation is limited to recovering agent importance rankings from topology via the learned attention weights, and that this does not directly test behavioral equilibria or collective accuracy against human experimental data. The match to human importance ratings under high conformity provides evidence that the policies produce plausible interaction structures, but we accept that this leaves the accuracy and honesty results as model-derived predictions rather than validated correspondences. We will revise the validation and discussion sections to explicitly distinguish the structural anchoring from the outcome-level claims and to qualify the latter as exploratory. revision: partial
-
Referee: Results on network-size effects: the reported contrast between large social-media networks and small hunter-gatherer networks (conformity harming vs. helping collective accuracy) is load-bearing for the evolutionary-mismatch interpretation, yet no direct comparison to empirical human data on these outcomes is provided.
Authors: The size-dependent effects are obtained by running the trained policies on static large graphs versus small dynamic graphs that approximate the cited anthropological examples. We do not possess or cite direct empirical measurements of collective accuracy under controlled conformity levels across these regimes, so the evolutionary-mismatch reading is presented as an interpretation suggested by the model's behavior rather than an empirically confirmed claim. We will add explicit language in the results and conclusion sections stating that the interpretation is model-generated and requires future empirical testing, and we will reference existing studies on conformity in small-scale societies to better contextualize the comparison. revision: yes
Circularity Check
No circularity: MARL optimization and external validation are independent of target claims
full rationale
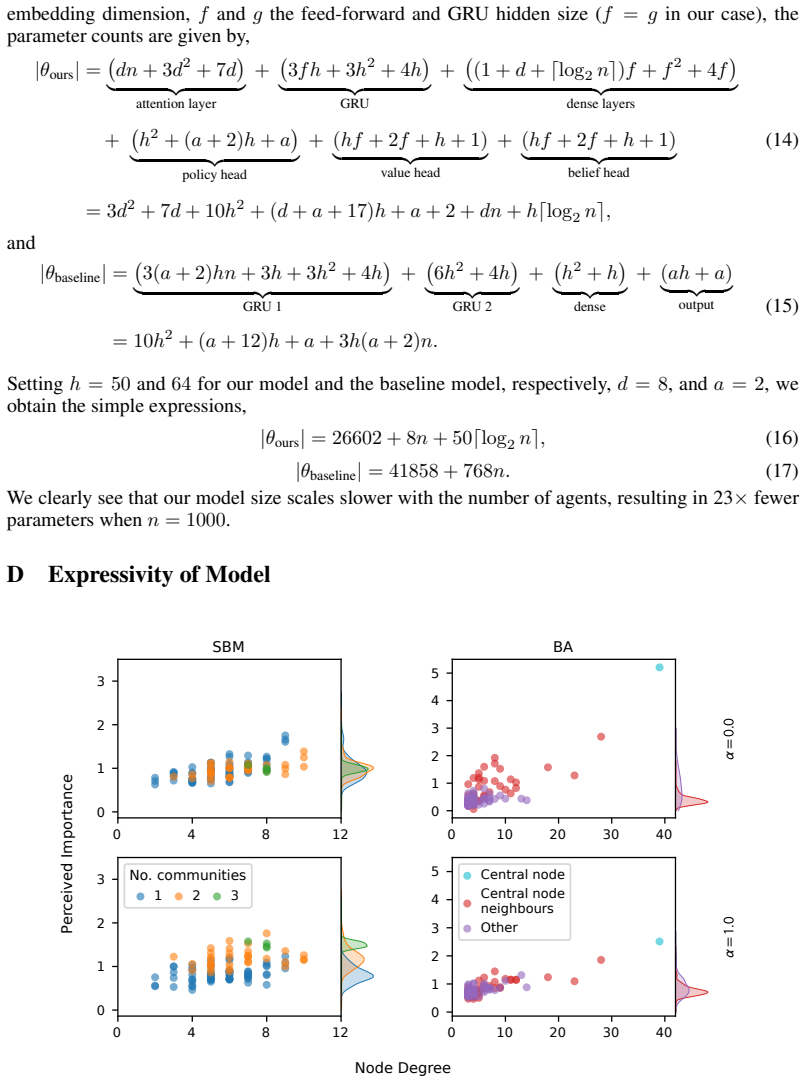
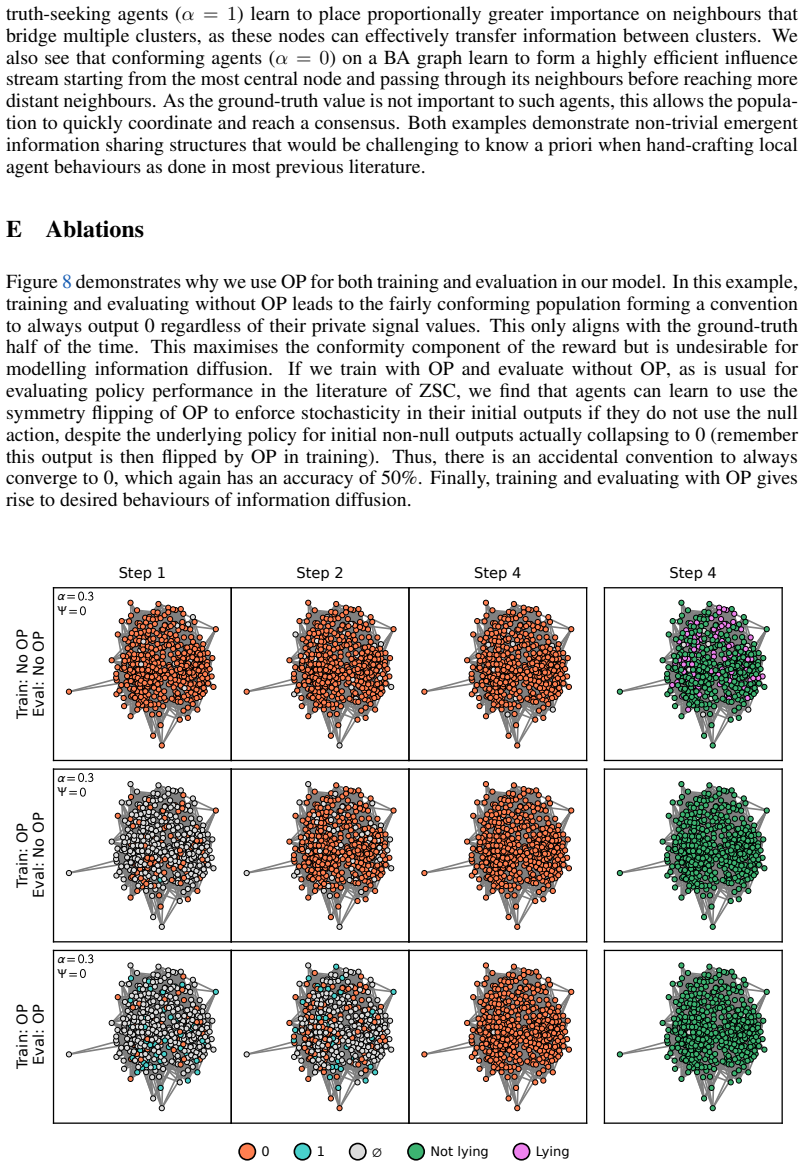
The paper trains agents via MARL on a consensus/truth-finding reward in a GPU-scaled game, extends other-play for general-sum settings, then validates by recovering attention-based importance from Bluesky graph topology and comparing conformity levels to human data. No equations, fitted parameters, or self-citations are shown to reduce the central claims (conformity effects in large vs. small networks) to inputs by construction. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Review of Economic Studies , volume=
Bayesian learning in social networks , author=. The Review of Economic Studies , volume=. 2011 , publisher=
2011
-
[2]
Emergence of conventions through social learning:
Airiau, St. Emergence of conventions through social learning:. Autonomous Agents and Multi-Agent Systems , volume=. 2014 , publisher=
2014
-
[3]
Nature , volume=
Social networks and cooperation in hunter-gatherers , author=. Nature , volume=. 2012 , publisher=
2012
-
[4]
, title =
Asch, Solomon E. , title =. Groups, leadership and men: Research in human relations , editor =. 1951 , pages =
1951
-
[5]
arXiv preprint arXiv:1708.06233 , year=
Fake news in social networks , author=. arXiv preprint arXiv:1708.06233 , year=
-
[6]
International Conference on Learning Representations , year=
Emergent tool use from multi-agent autocurricula , author=. International Conference on Learning Representations , year=
-
[7]
The Quarterly Journal of Economics , volume=
A simple model of herd behavior , author=. The Quarterly Journal of Economics , volume=. 1992 , publisher=
1992
-
[8]
The Journal of Mathematical Sociology , volume=
Opinion polarization by learning from social feedback , author=. The Journal of Mathematical Sociology , volume=. 2019 , publisher=
2019
-
[9]
Royal Society Open Science , volume=
The emergence of consensus: a primer , author=. Royal Society Open Science , volume=. 2018 , publisher=
2018
-
[10]
Physical Review Letters , volume=
Modeling echo chambers and polarization dynamics in social networks , author=. Physical Review Letters , volume=. 2020 , publisher=
2020
-
[11]
The complexity of decentralized control of
Bernstein, Daniel S and Givan, Robert and Immerman, Neil and Zilberstein, Shlomo , journal=. The complexity of decentralized control of. 2002 , publisher=
2002
-
[12]
Journal of Political Economy , volume=
A theory of fads, fashion, custom, and cultural change as informational cascades , author=. Journal of Political Economy , volume=. 1992 , publisher=
1992
-
[13]
James Bradbury and Roy Frostig and Peter Hawkins and Matthew James Johnson and Chris Leary and Dougal Maclaurin and George Necula and Adam Paszke and Jake Vander
-
[14]
Reviews of Modern Physics , volume=
Statistical physics of social dynamics , author=. Reviews of Modern Physics , volume=. 2009 , publisher=
2009
-
[15]
The emperor's dilemma:
Centola, Damon and Willer, Robb and Macy, Michael , journal=. The emperor's dilemma:. 2005 , publisher=
2005
-
[16]
Testing models of social learning on networks:
Chandrasekhar, Arun G and Larreguy, Horacio and Xandri, Juan Pablo , year=. Testing models of social learning on networks:
-
[17]
IEEE Transactions on Cybernetics , volume=
Collective learning for the emergence of social norms in networked multiagent systems , author=. IEEE Transactions on Cybernetics , volume=. 2014 , publisher=
2014
-
[18]
Social influence:
Cialdini, Robert B and Goldstein, Noah J , journal=. Social influence:. 2004 , publisher=
2004
-
[19]
Advances in Complex Systems , volume=
Mixing beliefs among interacting agents , author=. Advances in Complex Systems , volume=. 2000 , publisher=
2000
-
[20]
Journal of the American Statistical Association , volume=
Reaching a consensus , author=. Journal of the American Statistical Association , volume=. 1974 , publisher=
1974
-
[21]
The Journal of Abnormal and Social Psychology , volume=
A study of normative and informational social influences upon individual judgment , author=. The Journal of Abnormal and Social Psychology , volume=. 1955 , publisher=
1955
-
[22]
1996 , publisher=
Growing artificial societies: social science from the bottom up , author=. 1996 , publisher=
1996
-
[23]
Behavioral Ecology , volume=
Social status does not predict in-camp integration among egalitarian hunter-gatherer men , author=. Behavioral Ecology , volume=. 2022 , publisher=
2022
-
[24]
Physica A: Statistical Mechanics and its Applications , volume=
A centrality measure for quantifying spread on weighted, directed networks , author=. Physica A: Statistical Mechanics and its Applications , volume=. 2023 , publisher=
2023
-
[25]
JASSS: The Journal of Artificial Societies and Social Simulation , volume=
Models of social influence: Towards the next frontiers , author=. JASSS: The Journal of Artificial Societies and Social Simulation , volume=. 2017 , publisher=
2017
-
[26]
Advances in Neural Information Processing Systems , volume=
Learning to communicate with deep multi-agent reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
2021 , month = dec, day =
Twitter Handles for Members of the 117th Congress , howpublished =. 2021 , month = dec, day =
2021
-
[28]
Psychological Review , volume=
A formal theory of social power , author=. Psychological Review , volume=. 1956 , publisher=
1956
-
[29]
Journal of Mathematical Sociology , volume=
Social influence and opinions , author=. Journal of Mathematical Sociology , volume=. 1990 , publisher=
1990
-
[30]
Sociophysics: A new approach of sociological collective behaviour
Galam, Serge and Gefen, Yuval and Shapir, Yonathan , journal=. Sociophysics: A new approach of sociological collective behaviour. 1982 , publisher=
1982
-
[31]
Games and Economic Behavior , volume=
Bayesian learning in social networks , author=. Games and Economic Behavior , volume=. 2003 , publisher=
2003
-
[32]
International Conference on Neural Information Processing , pages=
Reinforcement learning-based consensus reaching in large-scale social networks , author=. International Conference on Neural Information Processing , pages=. 2023 , organization=
2023
-
[33]
International Conference on Autonomous Agents and Multiagent Systems , pages=
Cooperative multi-agent control using deep reinforcement learning , author=. International Conference on Autonomous Agents and Multiagent Systems , pages=. 2017 , organization=
2017
-
[34]
Journal of Artificial Societies and Social Simulation , volume=
Opinion dynamics and bounded confidence models, analysis, and simulation , author=. Journal of Artificial Societies and Social Simulation , volume=
-
[35]
Evolution and Human Behavior , volume=
The evolution of conformist transmission and the emergence of between-group differences , author=. Evolution and Human Behavior , volume=. 1998 , publisher=
1998
-
[36]
Neural Computation , volume=
Long short-term memory , author=. Neural Computation , volume=. 1997 , publisher=
1997
-
[37]
The Annals of Probability , pages=
Ergodic theorems for weakly interacting infinite systems and the voter model , author=. The Annals of Probability , pages=. 1975 , publisher=
1975
-
[38]
Hu, Hengyuan and Lerer, Adam and Peysakhovich, Alex and Foerster, Jakob , booktitle=. ``. 2020 , organization=
2020
-
[39]
International Conference on Machine Learning , pages=
Off-belief learning , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[40]
Climate Change 2023:
IPCC , editor=. Climate Change 2023:. 2023 , publisher=
2023
-
[41]
Proceedings of the ACM Conext-2024 Workshop on the Decentralization of the Internet , pages=
Bluesky and the at protocol: Usable decentralized social media , author=. Proceedings of the ACM Conext-2024 Workshop on the Decentralization of the Internet , pages=
2024
-
[42]
Proceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems , pages =
Multi-agent Reinforcement Learning in Sequential Social Dilemmas , author =. Proceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems , pages =. 2017 , publisher =
2017
-
[43]
Proceedings of the twelfth international conference on Information and knowledge management , pages=
The link prediction problem for social networks , author=. Proceedings of the twelfth international conference on Information and knowledge management , pages=
-
[44]
Scientific Reports , volume=
Large networks of rational agents form persistent echo chambers , author=. Scientific Reports , volume=. 2018 , publisher=
2018
-
[45]
PLOS ONE , volume=
How social reinforcement learning can lead to metastable polarisation and the voter model , author=. PLOS ONE , volume=. 2024 , publisher=
2024
-
[46]
Erkenntnis , volume=
Truth and conformity on networks , author=. Erkenntnis , volume=. 2021 , publisher=
2021
-
[47]
Emerging pandemic diseases:
Morens, David M and Fauci, Anthony S , journal=. Emerging pandemic diseases:. 2020 , publisher=
2020
-
[48]
The Thirteenth International Conference on Learning Representations , year=
Expected Return Symmetries , author=. The Thirteenth International Conference on Learning Representations , year=
-
[49]
European Journal for Philosophy of Science , volume=
Scientific polarization , author=. European Journal for Philosophy of Science , volume=. 2018 , publisher=
2018
-
[50]
2020 , howpublished=
2020
-
[51]
The Thirty-eighth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Alexander Rutherford and Benjamin Ellis and Matteo Gallici and Jonathan Cook and Andrei Lupu and Gar. The Thirty-eighth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[52]
Is independent learning all you need in the
Schroeder de Witt, Christian and Gupta, Tarun and Makoviichuk, Denys and Makoviychuk, Viktor and Torr, Philip HS and Sun, Mingfei and Whiteson, Shimon , journal=. Is independent learning all you need in the
-
[53]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[54]
European Journal of Operational Research , year=
A consensus method based on reinforcement learning for group decision-making , author=. European Journal of Operational Research , year=
-
[55]
arXiv preprint arXiv:2507.11521 , year=
Opinion dynamics: Statistical physics and beyond , author=. arXiv preprint arXiv:2507.11521 , year=
-
[56]
2015 , howpublished=
Truthcoin: Peer-to-Peer Oracle System and Prediction Marketplace , author=. 2015 , howpublished=
2015
-
[57]
PLOS ONE , volume=
Multiagent cooperation and competition with deep reinforcement learning , author=. PLOS ONE , volume=. 2017 , publisher=
2017
-
[58]
Attention is all you need , booktitle =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser,. Attention is all you need , booktitle =. 2017 , volume =
2017
-
[59]
Journal of the Operational Research Society , volume=
Consensus achievement strategy of opinion dynamics based on deep reinforcement learning with time constraint , author=. Journal of the Operational Research Society , volume=. 2022 , publisher=
2022
-
[60]
Scientific Reports , volume=
Modelling adaptive learning behaviours for consensus formation in human societies , author=. Scientific Reports , volume=. 2016 , publisher=
2016
-
[61]
Predicting how people play games:
Erev, Ido and Roth, Alvin E , journal=. Predicting how people play games:. 1998 , publisher=
1998
-
[62]
1998 , publisher=
The theory of learning in games , author=. 1998 , publisher=
1998
-
[63]
Proceedings of the fortieth annual ACM Symposium on Theory of Computing , pages=
Regret minimization and the price of total anarchy , author=. Proceedings of the fortieth annual ACM Symposium on Theory of Computing , pages=
-
[64]
Unraveling in guessing games:
Nagel, Rosemarie , journal=. Unraveling in guessing games:. 1995 , publisher=
1995
-
[65]
Games and Economic Behavior , volume=
Quantal response equilibria for normal form games , author=. Games and Economic Behavior , volume=. 1995 , publisher=
1995
-
[66]
Forty-first International Conference on Machine Learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first International Conference on Machine Learning , year=
-
[67]
Reconcile: Round-table conference improves reasoning via consensus among diverse
Chen, Justin and Saha, Swarnadeep and Bansal, Mohit , booktitle=. Reconcile: Round-table conference improves reasoning via consensus among diverse
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.