DALE-CT: Depth-Aware Foundation Models for Computed Tomography
Pith reviewed 2026-06-27 21:59 UTC · model grok-4.3
The pith
A 2D slice-based CT model trained from scratch reaches 0.833 macro AUROC matching 3D vision-language models on abnormality detection
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
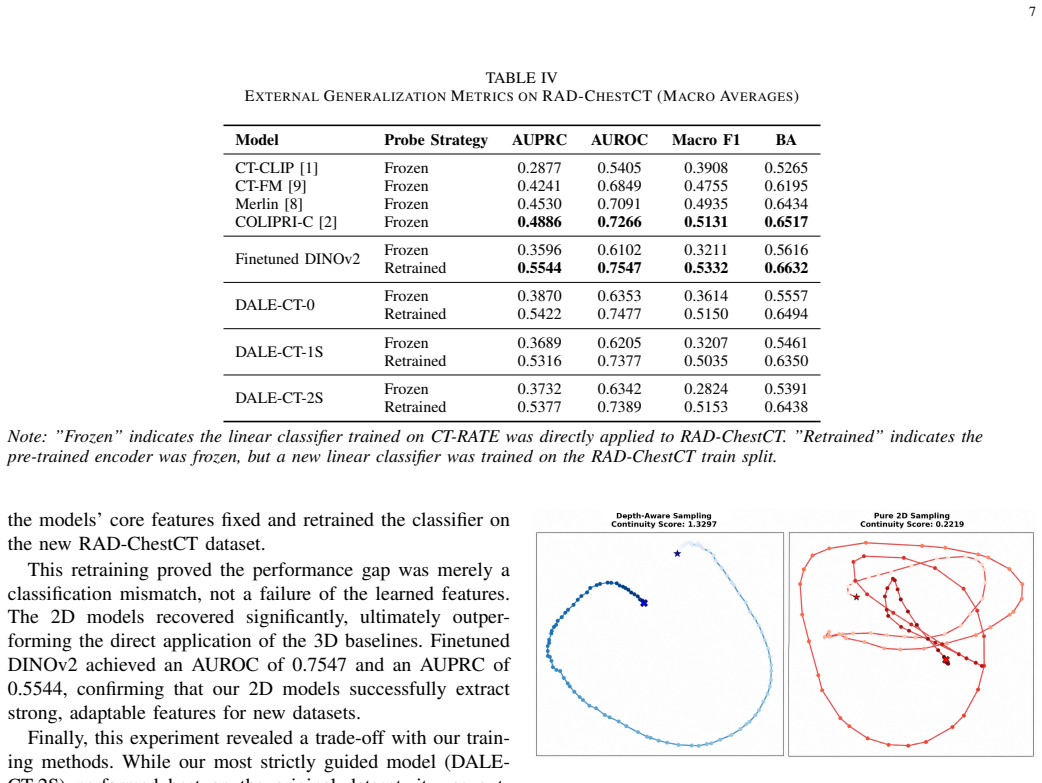
DALE-CT-2S, trained with the dual-supervised depth-aware strategy on the CT-RATE dataset, reaches a macro AUROC of 0.833 under linear-probe MIL evaluation for multi-abnormality detection, matching the performance of current state-of-the-art 3D vision-language models despite training from scratch on less data and without any textual supervision.
What carries the argument
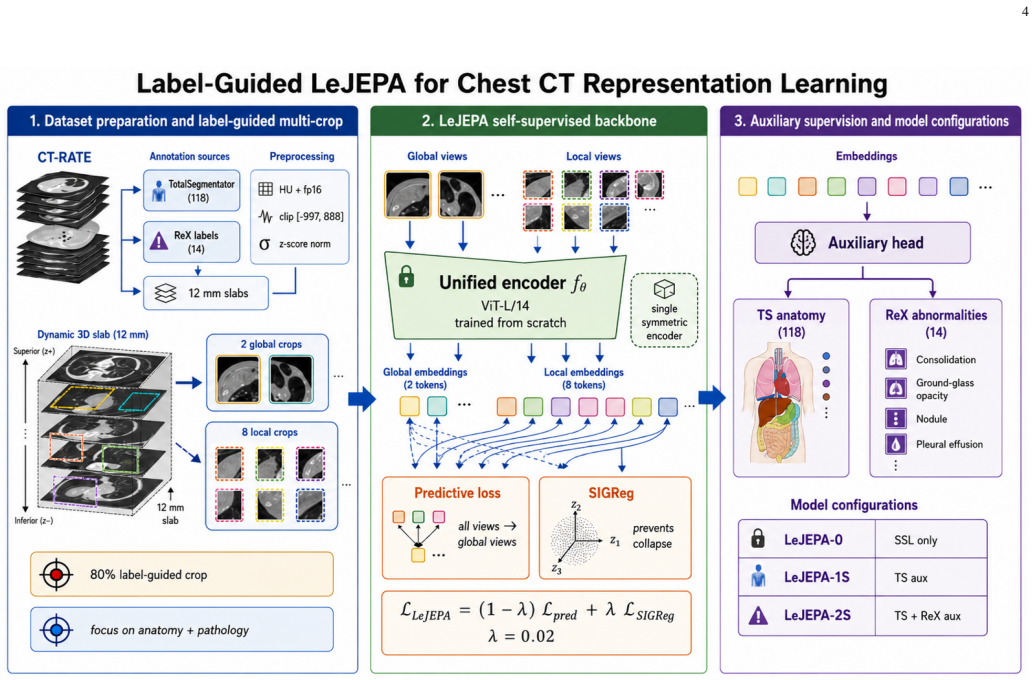
The novel 3D depth-aware pre-training strategy that anchors 2D LeJEPA representations with dense auxiliary supervision from automated anatomical masks and human-annotated abnormalities.
If this is right
- 2D slice architectures become viable flexible alternatives to native 3D models for CT volume processing.
- High downstream detection performance is attainable without large textual corpora or language-model integration.
- Training entirely from scratch on moderate data volumes can approach results of continually pre-trained 3D models.
- Dual supervision from masks and annotations measurably improves representation quality for abnormality detection.
Where Pith is reading between the lines
- The same depth-aware auxiliary signals could improve 2D handling of other volumetric scans such as MRI.
- Lower data requirements may allow training of custom models on smaller institutional or rare-disease datasets.
- Public release of weights and code makes direct testing on new abnormality classes or clinical pipelines straightforward.
- Lightweight 3D post-processing could be added later to close any remaining gap with full 3D models.
Load-bearing premise
That 2D slice processing plus the depth-aware pre-training strategy supplies enough volumetric spatial context for multi-abnormality detection to reach parity with native 3D models.
What would settle it
A native 3D model trained on the same CT-RATE data and supervision signals that substantially exceeds 0.833 macro AUROC would show the 2D approach misses critical 3D context.
Figures
read the original abstract
Recent breakthroughs in self-supervised learning (SSL), such as the Latent-Euclidean Joint-Embedding Predictive Architecture (LeJEPA), alongside successes in integrating visual encoders with language models, have driven the demand for adaptable, high-capacity vision encoders in Computed Tomography (CT). In this work, we explore 2D slice-based architectures as a flexible alternative to native 3D models for processing volumetric CT data. Using the CT-RATE dataset, we trained DALE-CT (Depth-Aware Latent-Euclidean Computed Tomography), a 2D model family built entirely from scratch using LeJEPA, and compared its performance against a continually pre-trained DINOv2 baseline. To enhance representation quality, we developed a novel 3D depth-aware pre-training strategy anchored by dense auxiliary supervision from both automated anatomical masks and human-annotated abnormalities. Under linear probe evaluation with Multiple Instance Learning (MIL) for multi-abnormality detection, the frozen backbone of this dual-supervised model (DALE-CT-2S) achieves a Macro AUROC of 0.833. This performance demonstrates near-parity with state-of-the-art 3D vision-language models, achieved entirely from scratch with significantly less data and no textual supervision. To ensure reproducibility, all training code, evaluation scripts, and model weights have been made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DALE-CT, a family of 2D slice-based models for CT volumes trained from scratch on the CT-RATE dataset using LeJEPA self-supervised learning. A novel depth-aware pre-training strategy is proposed that incorporates dense auxiliary supervision from automated anatomical masks and human-annotated abnormalities. The central empirical result is that the frozen dual-supervised backbone (DALE-CT-2S) achieves a Macro AUROC of 0.833 under linear probing with Multiple Instance Learning for multi-abnormality detection, reported as near-parity with state-of-the-art 3D vision-language models while using less data and no textual supervision. All code, evaluation scripts, and model weights are released publicly.
Significance. If the reported performance holds and the depth-aware component is shown to be responsible, the result would be significant for the field: it would establish that carefully supervised 2D slice encoders can deliver competitive volumetric CT performance without native 3D architectures or language supervision, at lower data and compute cost. The public release of code and weights is a clear strength that supports reproducibility and follow-on work.
major comments (2)
- [Abstract] Abstract: The claim that the depth-aware pre-training strategy (LeJEPA plus automated masks and abnormality annotations) supplies the inter-slice volumetric context needed for 2D slices to reach near-parity with native 3D models is load-bearing for the central result, yet the manuscript supplies neither an ablation isolating this component versus standard slice-wise LeJEPA nor any explicit mechanism describing how depth information is injected into the 2D encoder.
- [Abstract] Abstract: The Macro AUROC of 0.833 is presented without statistical tests, confidence intervals, variance across runs, or a table of direct numerical comparisons against the specific 3D vision-language baselines referenced, preventing assessment of whether the near-parity conclusion is robust.
minor comments (2)
- [Abstract] The abstract states the model was trained 'entirely from scratch with significantly less data' but provides no quantitative comparison of dataset size or compute against the referenced 3D VL models.
- No training curves, hyperparameter details, or ablation tables are referenced in the supplied text, which would be needed to substantiate the contribution of the dual-supervision signals.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of results and claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the depth-aware pre-training strategy (LeJEPA plus automated masks and abnormality annotations) supplies the inter-slice volumetric context needed for 2D slices to reach near-parity with native 3D models is load-bearing for the central result, yet the manuscript supplies neither an ablation isolating this component versus standard slice-wise LeJEPA nor any explicit mechanism describing how depth information is injected into the 2D encoder.
Authors: We agree that an explicit ablation isolating the depth-aware component from standard LeJEPA would strengthen the central claim. We will add this ablation to the revised manuscript. The mechanism for injecting depth information is the use of dense 3D anatomical masks and abnormality annotations as auxiliary supervision targets during pre-training; these targets are derived from the full volume and thereby encourage the 2D encoder to learn representations that respect inter-slice relationships. We will expand the methods section to describe this process more explicitly. revision: yes
-
Referee: [Abstract] Abstract: The Macro AUROC of 0.833 is presented without statistical tests, confidence intervals, variance across runs, or a table of direct numerical comparisons against the specific 3D vision-language baselines referenced, preventing assessment of whether the near-parity conclusion is robust.
Authors: We acknowledge that the current presentation lacks the requested statistical details and direct comparisons. In the revision we will report confidence intervals, standard deviation across multiple runs, and a table with numerical results against the referenced 3D baselines to allow readers to assess the robustness of the near-parity claim. revision: yes
Circularity Check
No circularity: central result is measured AUROC on held-out data
full rationale
The paper's primary claim is an empirical Macro AUROC of 0.833 obtained via linear-probe evaluation with MIL on held-out CT-RATE data for the frozen DALE-CT-2S backbone. This is a direct performance measurement against external labels, not an output of any equation or fitted parameter defined inside the paper. The pre-training description (LeJEPA with auxiliary anatomical masks) supplies the model weights but does not contain a derivation chain in which the reported AUROC reduces to a self-referential fit or self-citation. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the supplied text; the result remains falsifiable on independent test data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Generalist foundation models from a multimodal dataset for 3d computed tomography,
I. E. Hamamci, S. Er, C. Wang, F. Almas, A. G. Simsek, S. N. Esirgun, I. Dogan, O. F. Durugol, B. Hou, S. Shit, W. Dai, M. Xu, H. Reynaud, M. F. Dasdelen, B. Wittmann, T. Amiranashvili, E. Simsar, M. Simsar, E. B. Erdemir, A. Alanbay, A. Sekuboyina, B. Lafci, A. Kaplan, Z. Lu, M. Polacin, B. Kainz, C. Bluethgen, K. Batmanghelich, M. K. Ozdemir, and B. Men...
-
[2]
Comprehensive language-image pre-training for 3d medical image understanding,
T. Wald, I. E. Hamamci, Y . Gao, S. Bond-Taylor, H. Sharma, M. Ilse, C. Lo, O. Melnichenko, A. Schwaighofer, N. C. F. Codella, M. T. Wetscherek, K. H. Maier-Hein, P. Korfiatis, V . Salvatelli, J. Alvarez-Valle, and F. P ´erez-Garc´ıa, “Comprehensive language-image pre-training for 3d medical image understanding,” 2026. [Online]. Available: https://arxiv.o...
arXiv 2026
-
[3]
Exploring scalable medical image encoders beyond text supervision,
F. P ´erez-Garc´ıa, H. Sharma, S. Bond-Taylor, K. Bouzid, V . Salvatelli, M. Ilse, S. Bannur, D. C. Castro, A. Schwaighofer, M. P. Lungren, M. T. Wetscherek, N. Codella, S. L. Hyland, J. Alvarez-Valle, and O. Oktay, “Exploring scalable medical image encoders beyond text supervision,” Nature Machine Intelligence, vol. 7, no. 1, p. 119–130, Jan. 2025. [Onli...
-
[4]
V . Bumgardner, M. A. Klusty, M. S. Gokmen, and E. W. Dam- ron, “Curriculum-driven 3d ct report generation via language-free visual grafting and zone-constrained compression,”arXiv preprint arXiv:2603.23308, 2026
arXiv 2026
-
[5]
Lejepa: Provable and scalable self- supervised learning without the heuristics,
R. Balestriero and Y . LeCun, “Lejepa: Provable and scalable self- supervised learning without the heuristics,” 2025. [Online]. Available: https://arxiv.org/abs/2511.08544
Pith/arXiv arXiv 2025
-
[6]
Totalsegmentator: Robust segmentation of 104 anatomic structures in ct images,
J. Wasserthal, H.-C. Breit, M. T. Meyer, M. Pradella, D. Hinck, A. W. Sauter, T. Heye, D. T. Boll, J. Cyriac, S. Yang, M. Bach, and M. Segeroth, “Totalsegmentator: Robust segmentation of 104 anatomic structures in ct images,”Radiology: Artificial Intelligence, vol. 5, no. 5,
-
[7]
Radiology: Artificial Intelligence (2023)
[Online]. Available: http://dx.doi.org/10.1148/ryai.230024
-
[8]
Rexgroundingct: A 3d chest ct dataset for segmentation of findings from free-text reports,
M. Baharoon, L. Luo, M. Moritz, A. Kumar, S. E. Kim, X. Zhang, M. Zhu, M. H. Alabbad, M. S. Alhazmi, N. P. Mistry, L. Bijnens, K. R. Kleinschmidt, B. Chrisler, S. Suryadevara, S. S. D. Jaliparthi, N. M. Prudlo, M. D. Marino, J. Palacio, R. Akula, D. Zhou, H.-Y . Zhou, I. E. Hamamci, S. J. Adams, H. R. AlOmaish, and P. Rajpurkar, “Rexgroundingct: A 3d ches...
arXiv 2025
-
[9]
Merlin: a computed tomography vision–language foundation model and dataset,
L. Blankemeier, A. Kumar, J. P. Cohen, J. Liu, L. Liu, D. Van Veen, S. J. S. Gardezi, H. Yu, M. Paschali, Z. Chen, J.-B. Delbrouck, E. Reis, R. Holland, C. Truyts, C. Bluethgen, Y . Wu, L. Lian, M. E. K. Jensen, S. Ostmeier, M. Varma, J. M. J. Valanarasu, Z. Fang, Z. Huo, Z. Nabulsi, D. Ardila, W.-H. Weng, E. A. Junior, N. Ahuja, J. Fries, N. H. Shah, G. ...
-
[10]
Vision foundation models for computed tomography,
S. Pai, I. Hadzic, D. Bontempi, K. Bressem, B. H. Kann, A. Fedorov, R. H. Mak, and H. J. W. L. Aerts, “Vision foundation models for computed tomography,” 2025. [Online]. Available: https://arxiv.org/abs/2501.09001
arXiv 2025
-
[11]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked autoencoders are scalable vision learners,” 2021. [Online]. Available: https://arxiv.org/abs/2111.06377
Pith/arXiv arXiv 2021
-
[12]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” 2020. [Online]. Available: https://arxiv.org/abs/2002.05709
Pith/arXiv arXiv 2020
-
[13]
Momentum contrast for unsupervised visual representation learning,
K. He, H. Fan, Y . Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” 2020. [Online]. Available: https://arxiv.org/abs/1911.05722
arXiv 2020
-
[14]
Bootstrap your own latent: A new approach to self-supervised learning,
J.-B. Grill, F. Strub, F. Altch ´e, C. Tallec, P. H. Richemond, E. Buchatskaya, C. Doersch, B. A. Pires, Z. D. Guo, M. G. Azar, B. Piot, K. Kavukcuoglu, R. Munos, and M. Valko, “Bootstrap your own latent: A new approach to self-supervised learning,” 2020. [Online]. Available: https://arxiv.org/abs/2006.07733
arXiv 2020
-
[15]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,”
-
[16]
Available: https://arxiv.org/abs/2104.14294
[Online]. Available: https://arxiv.org/abs/2104.14294
-
[17]
Vicreg: Variance-invariance- covariance regularization for self-supervised learning,
A. Bardes, J. Ponce, and Y . LeCun, “Vicreg: Variance-invariance- covariance regularization for self-supervised learning,” 2022. [Online]. Available: https://arxiv.org/abs/2105.04906
Pith/arXiv arXiv 2022
-
[18]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “Dinov2: Learning robust visual features without supe...
Pith/arXiv arXiv 2024
-
[19]
Tap-ct: 3d task- agnostic pretraining of computed tomography foundation models,
T. Veenboer, G. Yiasemis, E. Marcus, V . V . Veldhuizen, C. G. M. Snoek, J. Teuwen, and K. B. W. G. Lipman, “Tap-ct: 3d task- agnostic pretraining of computed tomography foundation models,”
-
[20]
Available: https://arxiv.org/abs/2512.00872
[Online]. Available: https://arxiv.org/abs/2512.00872
-
[21]
Evaluating general purpose vision foundation models for medical image analysis: An experimental study of dinov2 on radiology benchmarks,
M. Baharoon, W. Qureshi, J. Ouyang, Y . Xu, A. Aljouie, and W. Peng, “Evaluating general purpose vision foundation models for medical image analysis: An experimental study of dinov2 on radiology benchmarks,”
-
[22]
Available: https://arxiv.org/abs/2312.02366
[Online]. Available: https://arxiv.org/abs/2312.02366
-
[23]
Dino-lg: Enhancing vision transformers with label guidance for coronary artery calcium detection,
M. Gokmen, C. Ozcan, M. Haqueet al., “Dino-lg: Enhancing vision transformers with label guidance for coronary artery calcium detection,”Med Biol Eng Comput, vol. 64, pp. 1249–1266, 2026. [Online]. Available: https://doi.org/10.1007/s11517-026-03523-1
-
[24]
U-vlm: Hierarchical vision language modeling for report generation,
P. Shi, M. Zhang, K. Song, J. Liu, Y . Gu, and X. Zhang, “U-vlm: Hierarchical vision language modeling for report generation,” 2026. [Online]. Available: https://arxiv.org/abs/2603.00479
arXiv 2026
-
[25]
Organ-aware attention improves ct triage and classification,
L. Dahal, Y . Bhandari, G. D. Rubin, and J. Y . Lo, “Organ-aware attention improves ct triage and classification,” 2026. [Online]. Available: https://arxiv.org/abs/2601.13385
arXiv 2026
-
[26]
Janus: Anatomy- conditioned gating for robust ct triage under distribution shift,
L. Dahal, Y . Bhandari, G. Rubin, and J. Y . Lo, “Janus: Anatomy- conditioned gating for robust ct triage under distribution shift,” 2026. [Online]. Available: https://arxiv.org/abs/2605.13813
Pith/arXiv arXiv 2026
-
[27]
Finetuned-dinov2-chest-ct,
Institute for Biomedical Informatics Center for Applied AI (IBI- CAAI), “Finetuned-dinov2-chest-ct,” https://huggingface.co/IBI-CAAI/ Finetuned-DINOv2-Chest-CT, 2026
2026
-
[28]
Vision transformers need registers,
T. Darcet, M. Oquab, J. Mairal, and P. Bojanowski, “Vision transformers need registers,” 2024. [Online]. Available: https://arxiv.org/abs/2309. 16588
2024
-
[29]
Dino-mx: A modular & flexible framework for self-supervised learning,
M. S. Gokmen and C. Bumgardner, “Dino-mx: A modular & flexible framework for self-supervised learning,” 2025. [Online]. Available: https://arxiv.org/abs/2511.01610
arXiv 2025
-
[30]
Guided-chest-ct-lejepa-0,
Institute for Biomedical Informatics Center for Applied AI (IBI- CAAI), “Guided-chest-ct-lejepa-0,” https://huggingface.co/IBI-CAAI/ Guided-Chest-CT-LeJEPA-0, 2026
2026
-
[31]
Guided-chest-ct-lejepa-1s,
——, “Guided-chest-ct-lejepa-1s,” https://huggingface.co/IBI-CAAI/ Guided-Chest-CT-LeJEPA-1S, 2026
2026
-
[32]
Guided-chest-ct-lejepa-2s,
——, “Guided-chest-ct-lejepa-2s,” https://huggingface.co/IBI-CAAI/ Guided-Chest-CT-LeJEPA-2S, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.