Beyond Individual Personas: Aligning Synthetic Dialogue to Population-Level Behavior Distributions
Pith reviewed 2026-06-27 21:31 UTC · model grok-4.3
The pith
GroupPersona aligns synthetic dialogue corpora to reference population behavior distributions by conditioning on behavioral groups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
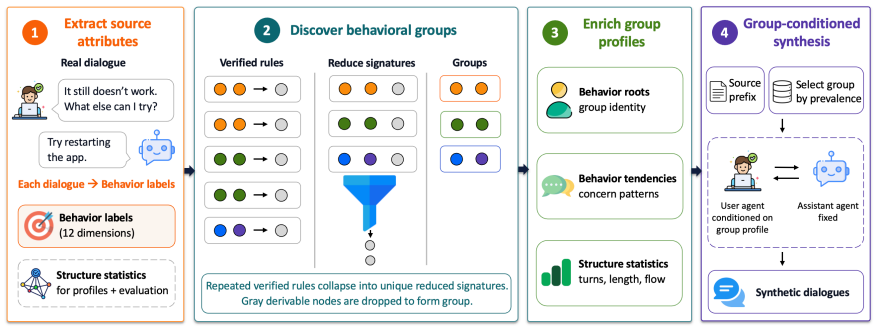
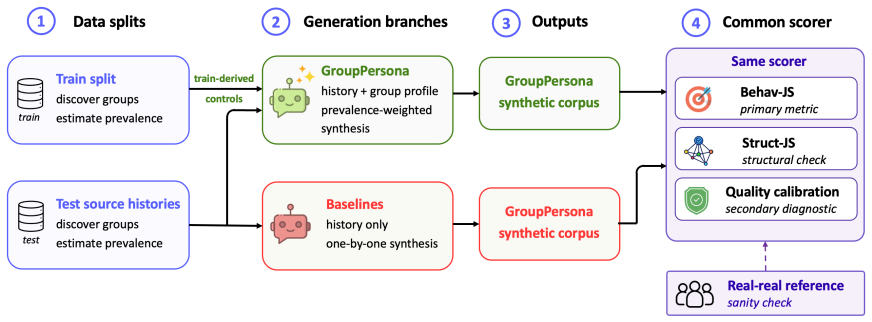
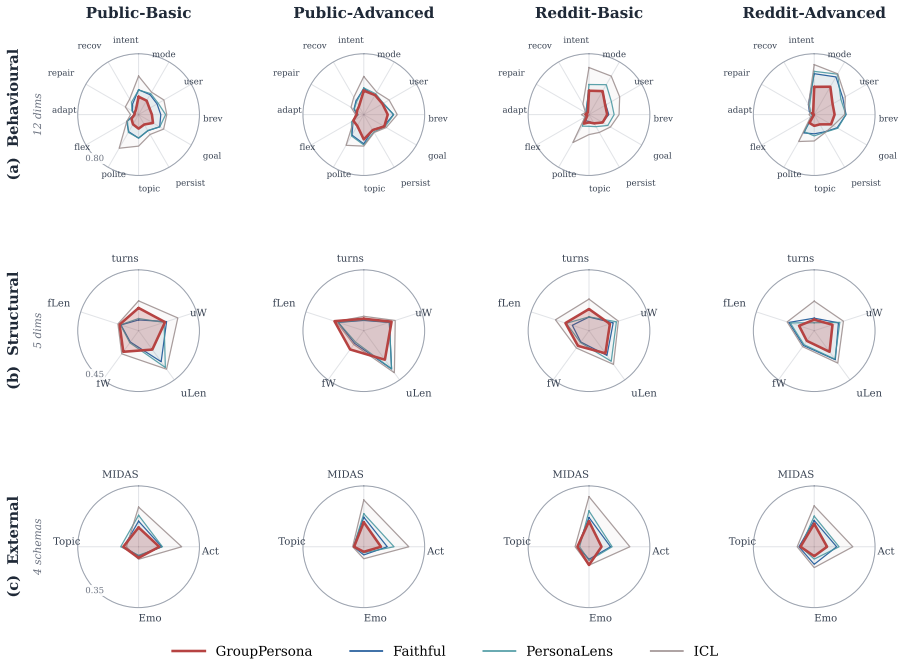
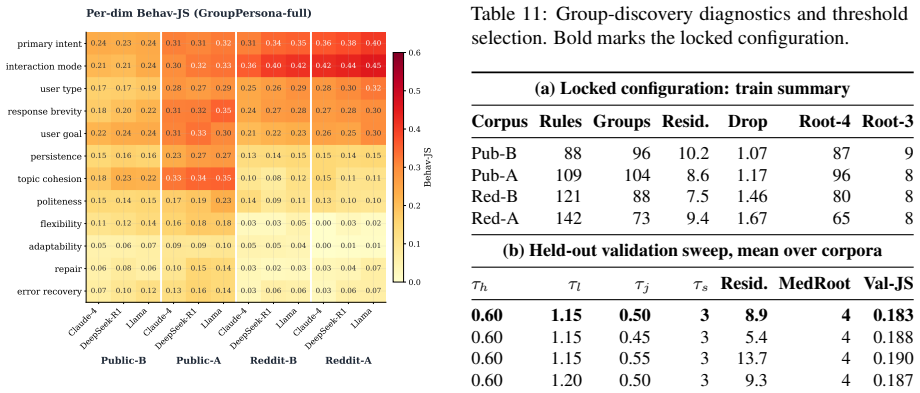
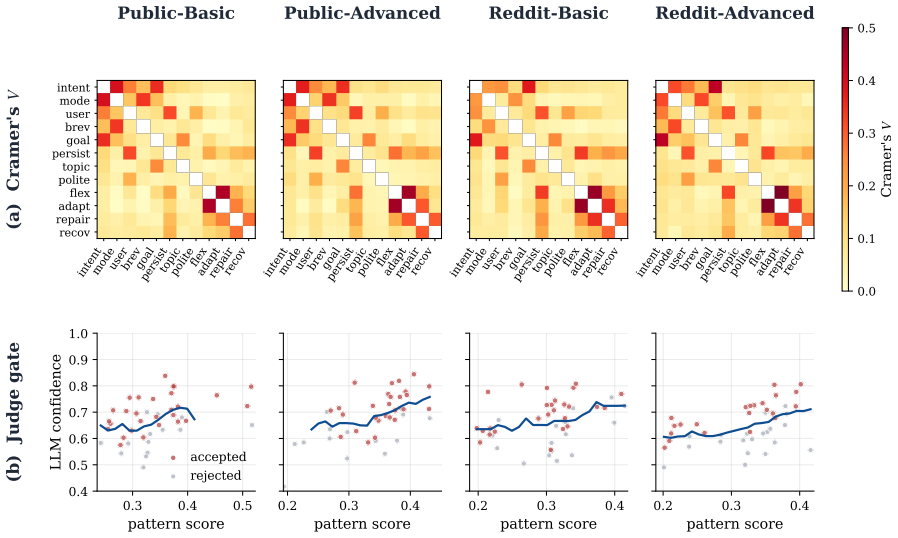
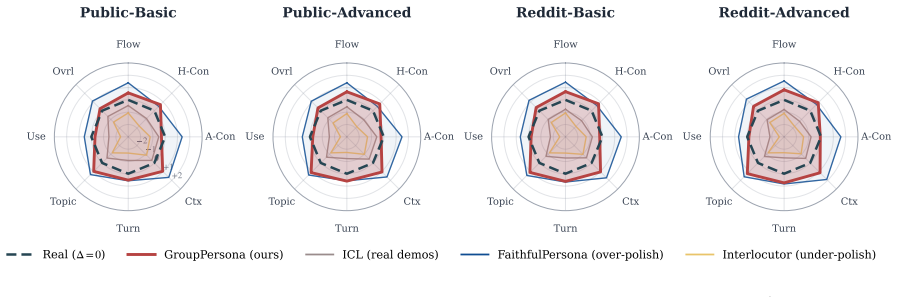
GroupPersona turns population statistics into generation controls: it separates each dialogue's core behavioral signature from predictable side effects, and uses the resulting behavioral groups to condition user agents on the interaction patterns that define the reference population. It lowers Jensen-Shannon divergence between synthetic and reference distributions over 12 behavior attributes from 0.234 to 0.177, a 24.4% reduction, while achieving best or tied-best results on all four corpora and reducing mean absolute deviation from reference-conversation quality scores to 0.63.
What carries the argument
GroupPersona framework, which separates each dialogue's core behavioral signature from predictable side effects to form groups that condition generation on reference population patterns.
If this is right
- Synthetic corpora achieve a 24.4 percent reduction in Jensen-Shannon divergence to reference distributions across 12 behavior attributes.
- The method is best or tied-best on every one of the four corpora tested, covering assistant-style and Reddit-derived sources in both structure-preserving and variation-enhanced forms.
- Mean absolute deviation from reference-conversation quality scores falls to 0.63 versus 0.91 for the next-best approach.
- Structural properties of the dialogues remain aligned with the reference while the behavior distribution improves.
Where Pith is reading between the lines
- The grouping approach could extend to other text generation domains where population-level statistics matter more than individual sample realism.
- If the core-versus-side-effect separation holds, it offers a diagnostic for why single-persona methods produce mismatched aggregates.
- Improved distribution match might yield better downstream results when the synthetic data trains models for user simulation or evaluation.
- The technique could reduce reliance on large reference corpora by focusing generation on a small set of representative behavioral clusters.
Load-bearing premise
Separating each dialogue's core behavioral signature from predictable side effects produces groups that validly represent the reference population's interaction patterns without distorting the target distribution.
What would settle it
Applying GroupPersona to a new reference corpus and finding no reduction in Jensen-Shannon divergence on the 12 behavior attributes below the strongest baseline, or an increase in deviation from reference quality scores, would falsify the alignment claim.
Figures
read the original abstract
Synthetic dialogue corpora are increasingly used as proxies for target dialogue data, yet persona-grounded generators optimize individual conversations rather than corpus composition, yielding locally plausible dialogues with distorted population-level behavior mixes. We introduce GroupPersona, a framework that aligns synthetic dialogue corpora to the behavior distribution of a reference corpus. GroupPersona turns population statistics into generation controls: it separates each dialogue's core behavioral signature from predictable side effects, and uses the resulting behavioral groups to condition user agents on the interaction patterns that define the reference population. We evaluate GroupPersona on four corpora crossing two dialogue sources, assistant-style and Reddit-derived, with two construction variants: structure-preserving and variation-enhanced. GroupPersona lowers Jensen-Shannon divergence between synthetic and reference distributions over 12 behavior attributes from 0.234 to 0.177 relative to the strongest average baseline, a 24.4% reduction, and is best or tied-best on all four corpora while preserving structural alignment. It also achieves the closest calibration to reference-conversation quality scores, reducing mean absolute deviation from the reference-conversation profile to 0.63 versus 0.91 for the next-best baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GroupPersona, a framework that aligns synthetic dialogue corpora to population-level behavior distributions from a reference corpus. It does so by separating each dialogue's core behavioral signature from predictable side effects and using the resulting groups to condition user agents. Evaluated on four corpora (crossing assistant-style and Reddit-derived sources with structure-preserving and variation-enhanced variants), GroupPersona reduces Jensen-Shannon divergence on 12 behavior attributes from 0.234 to 0.177 (24.4% reduction) relative to the strongest average baseline, is best or tied-best on all corpora while preserving structural alignment, and achieves closer calibration to reference-conversation quality scores (MAD reduced to 0.63 from 0.91).
Significance. If the reported empirical gains hold, the work offers a practical approach to mitigating the population-level distortion common in persona-grounded synthetic dialogue generation. The consistent outperformance across two dialogue sources and two construction variants, combined with dual evaluation on distributional match (JSD) and quality calibration, indicates potential utility for downstream tasks requiring representative synthetic data. The method is presented as an empirical framework without self-referential fitting or circular derivations, which supports the credibility of the deltas.
minor comments (2)
- Abstract: the phrase 'strongest average baseline' is used without naming the specific baselines or their implementations; adding this detail would improve immediate interpretability of the 24.4% reduction claim even before the methods section.
- The abstract states results on '12 behavior attributes' and 'reference-conversation quality scores' but does not list the attributes or the quality metric; a brief enumeration or reference to the relevant table/definition would aid readers.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of GroupPersona, the recognition of its empirical gains across corpora, and the recommendation for minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper introduces GroupPersona as an empirical framework that extracts behavioral groups from reference corpora and conditions generation on them, then reports measured improvements in Jensen-Shannon divergence and calibration against external baselines across four corpora. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described method. The central results are presented as outcomes of evaluation rather than identities or forced consequences of the method's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Population statistics from a reference corpus can be turned into reliable generation controls via behavioral groups
invented entities (1)
-
GroupPersona framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 1993 ACM SIGMOD International Conference on Management of Data, pages 207–216
Mining association rules between sets of items in large databases. InProceedings of the 1993 ACM SIGMOD International Conference on Management of Data, pages 207–216. Rakesh Agrawal and Ramakrishnan Srikant. 1994. Fast algorithms for mining association rules. InProceed- ings of the 20th International Conference on Very Large Data Bases, pages 487–499. Jas...
arXiv 1993
-
[2]
Tatsunori B
Frequent pattern mining: current status and future directions.Data Mining and Knowledge Dis- covery, 15(1):55–86. Tatsunori B. Hashimoto, Hugh Zhang, and Percy Liang
-
[3]
Unifying Human and Statistical Evaluation for Natural Language Generation. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Hu- man Language Technologies, Volume 1 (Long and Short Papers), pages 1689–1701, Minneapolis, Min- nesota. Association for Computational Linguistics. Ari Holtzman, ...
Pith/arXiv arXiv 2019
-
[4]
InProceedings of the 2nd Workshop on Natural Language Processing for Conversational AI, pages 109–117, Online
MultiWOZ 2.2: A Dialogue Dataset with Ad- ditional Annotation Corrections and State Tracking Baselines. InProceedings of the 2nd Workshop on Natural Language Processing for Conversational AI, pages 109–117, Online. Association for Computa- tional Linguistics. Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston. 2018. Per...
2018
-
[5]
The single intent that drives the majority of the user’s turns; tie-break by the opening request
primary_intent_type∈ {Task, Info-seeking, Chitchat, Music, Reminder, Alarm, Smart_Home}. The single intent that drives the majority of the user’s turns; tie-break by the opening request
-
[6]
Command = imperative one- shot; QA = question → answer pattern; Multi-turn = ≥3 back-and-forth turns building on prior context
interaction_mode∈ {Command-style, QA-style, Multi-turn_Dialog-style}. Command = imperative one- shot; QA = question → answer pattern; Multi-turn = ≥3 back-and-forth turns building on prior context
-
[7]
Power = exploits advanced options; One-shot = ends after one exchange; Tasker = follows a task plan; Casual = informal, low engagement
user_type∈ {Power_User, One-shot_User, Tasker, Casual}. Power = exploits advanced options; One-shot = ends after one exchange; Tasker = follows a task plan; Casual = informal, low engagement
-
[8]
Me- dian user-utterance word count: Short ≤6 , Medium 7–20, Long≥21
response_brevity∈ {Short, Medium, Long}. Me- dian user-utterance word count: Short ≤6 , Medium 7–20, Long≥21
-
[9]
Tasker = single goal pursued to com- pletion; Explorer = probing/learning; Goal-switcher = ≥2goal changes; Chatter = social, no goal
user_goal_profile∈ {Tasker, Explorer, Goal- switcher, Chatter}. Tasker = single goal pursued to com- pletion; Explorer = probing/learning; Goal-switcher = ≥2goal changes; Chatter = social, no goal
-
[10]
After a failed/unhelpful system reply: High = retries ≥3× ; Medium = 1–2 retries; Low = abandons
persistence_level∈ {High, Medium, Low}. After a failed/unhelpful system reply: High = retries ≥3× ; Medium = 1–2 retries; Low = abandons
-
[11]
High = one topic; Medium = related topics; Fragmented =≥2unrelated topics
topic_cohesion∈ {High, Medium, Fragmented}. High = one topic; Medium = related topics; Fragmented =≥2unrelated topics
-
[12]
please/thanks
politeness_strategy∈ {Direct, Polite, Formal, Friendly}. Direct = imperative, no marker; Polite = “please/thanks”; Formal = third-person/honorifics; Friendly = casual greetings, emotive language
-
[13]
Adaptive = reformulates after misunderstanding; Static = repeats verbatim or gives up
interaction_flexibility∈ {Adaptive, Static}. Adaptive = reformulates after misunderstanding; Static = repeats verbatim or gives up
-
[14]
High = tone/style shifts to match system; Low = constant tone regardless
persona_adaptability∈ {High, Low}. High = tone/style shifts to match system; Low = constant tone regardless
-
[15]
After a breakdown: Rephrase = restates differ- ently; Clarify = adds info / asks back; Ignore = moves on; Retry = repeats identically
repair_behavior∈ {Rephrase, Clarify, Ignore, Retry}. After a breakdown: Rephrase = restates differ- ently; Clarify = adds info / asks back; Ignore = moves on; Retry = repeats identically
-
[16]
primary_intent_type
error_recovery_style∈ {Clarification_Request, Repetition, Restart, Task_Abandonment}. Dominant strategy when the system errs: ask for clarification, repeat, restart conversation, or abandon the task. Output format. { "primary_intent_type": "...", "interaction_mode": "...", "user_type": "...", "response_brevity": "...", "user_goal_profile": "...", "persist...
2020
-
[17]
( primary_intent_type=Chitchat) AND ( user_type=Casual) ⇒ (user_goal_profile=Chatter)
defines 23 per-turn dialogue-act categories, including statement, opinion, complaint, command, open-ended question, yes-no question, thanks, apol- ogy, and closing. The unit of analysis is the user turn, so the scored distribution is the corpus-level marginal over user turns. MIDAS partially over- laps our schema through interaction mode, primary intent, ...
arXiv 1940
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.