Unification of Closed-Open Industrial Detection Scenarios: New Large-Scale Benchmarks,Challenges and Baselines
Pith reviewed 2026-06-27 20:06 UTC · model grok-4.3
The pith
A new million-sample benchmark unifies open-vocabulary and closed-set industrial defect detection, and RTVPNet adapts vision-language models to it with automatic domain projection and prompt refinement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
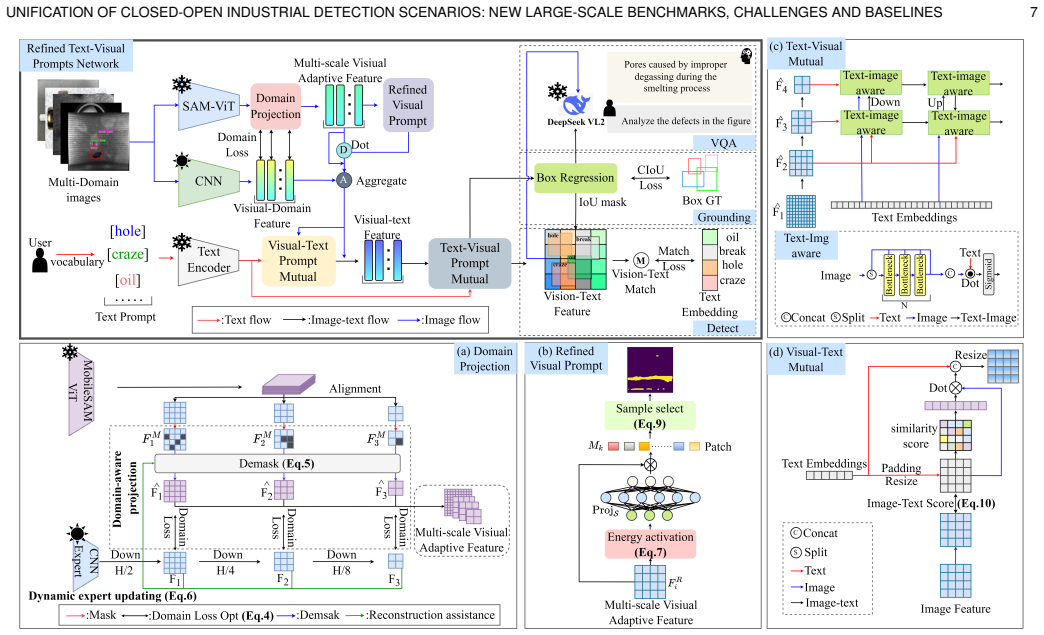
The central claim is that expert-assisted domain projection, energy-based sparse sampling, and bidirectional text-visual interaction together allow a refined text-visual prompt network to adapt large vision-language models to industrial defect detection, achieving state-of-the-art results on the first unified open-closed benchmark of more than one million samples across 351 subcategories.
What carries the argument
RTVPNet, whose expert-assisted domain projection adapts general vision models, energy-based sparse sampling generates refined visual prompts, and bidirectional text-visual interaction improves cross-modal alignment.
If this is right
- LVLMs can now be pre-trained on large industrial data that covers both open-vocabulary and closed-set detection.
- Manual prompt engineering is no longer required for fine-grained industrial inspection tasks.
- The same architecture improves results on standard natural-image benchmarks such as LVIS and COCO.
- A single model can switch between open and closed detection modes in factory settings without retraining.
Where Pith is reading between the lines
- The same projection and sampling approach could be tested on other narrow domains such as medical imaging or satellite analysis.
- The benchmark size may allow systematic study of how defect rarity affects open-vocabulary performance.
- Real-time factory deployment would require measuring whether the reported efficiency holds under continuous video streams.
Load-bearing premise
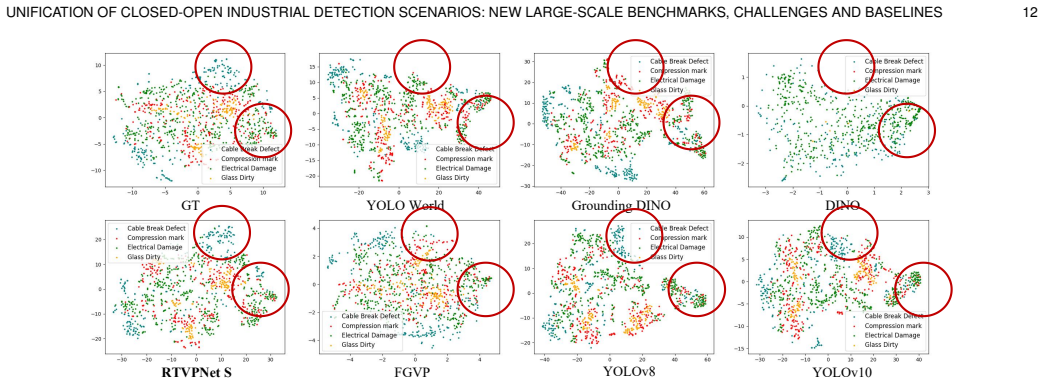
The three proposed components and the new benchmark produce real generalization across industrial scenes rather than overfitting to the collected data or the chosen 29 scenes.
What would settle it
Performance of RTVPNet falling below existing baselines when evaluated on an industrial dataset drawn from scenes and defect types completely outside the 29 scenes and 351 subcategories in MMIOC-1M.
Figures







read the original abstract
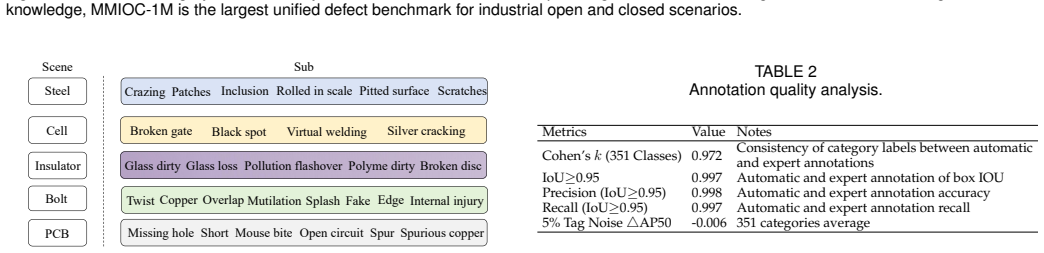
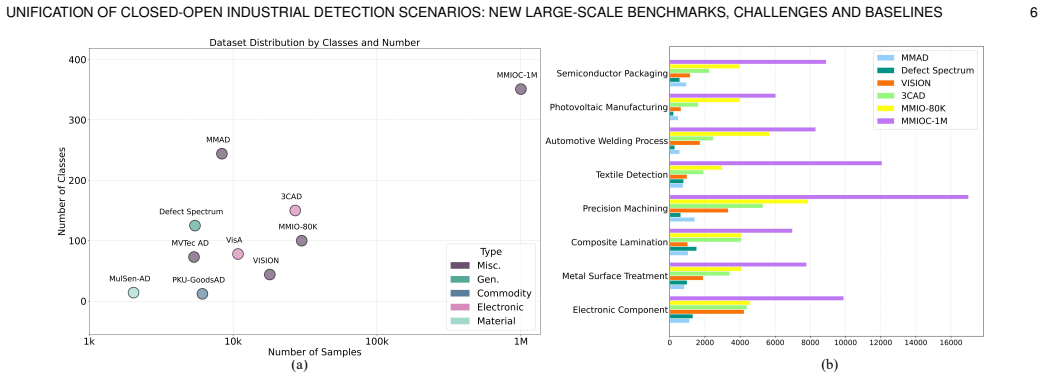
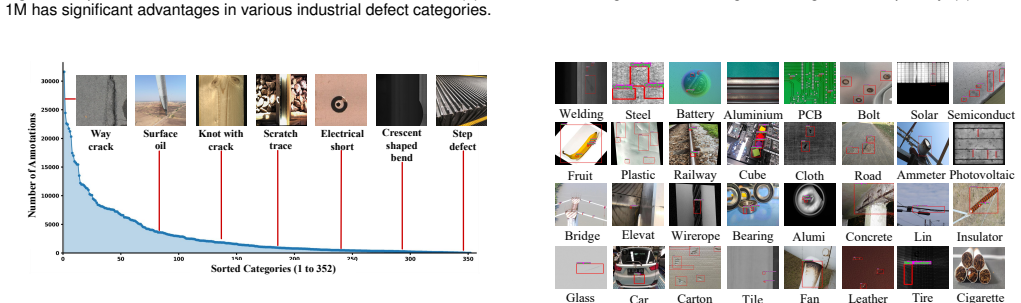
Large-scale Visual-Language Models (LVLMs) have achieved remarkable success in natural visual tasks, yet their application to industrial defect detection remains challenging due to two fundamental limitations: (i) the scarcity of large-scale industrial datasets that cover diverse defect categories across multiple domains, and (ii) the reliance on manual prompts (points, boxes, masks) that introduce subjective noise and lack text-visual interaction for fine-grained understanding. To address these challenges, we introduce a Large-Scale Multi-Modal Industrial Open-Closed benchmark (MMIOC-1M) containing over one million samples across $14$ super-categories, $29$ industrial scenes, and $351$ defect subcategories. To our knowledge, MMIOC-1M is the first unified largest benchmark supporting both open-vocabulary and closed-set industrial detection, providing valuable pre-training data for LVLMs in industrial scenarios. Furthermore, we propose a Refined Text-Visual Prompt Network (RTVPNet) that incorporates three key innovations: (1) an expert-assisted domain projection mechanism that enables rapid adaptation of general vision models to industrial domains, (2) an energy-based sparse sampling strategy that automatically generates refined visual prompts without manual intervention, and (3) a bidirectional text-visual interaction module that enhances cross-modal semantic alignment and understanding. Extensive experiments demonstrate that RTVPNet achieves state-of-the-art performance on MMIOC-1M, LVIS, and COCO benchmarks while maintaining computational efficiency. The dataset and code are available at https://github.com/hellozzk/MMIO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the MMIOC-1M benchmark containing over one million samples across 14 super-categories, 29 industrial scenes, and 351 defect subcategories to support both open-vocabulary and closed-set industrial defect detection. It proposes RTVPNet incorporating expert-assisted domain projection, energy-based sparse sampling, and bidirectional text-visual interaction, claiming that this model achieves state-of-the-art performance on MMIOC-1M as well as on the LVIS and COCO benchmarks while remaining computationally efficient. The dataset and code are released publicly.
Significance. If the results hold, the work supplies the first large-scale unified benchmark for industrial scenarios and a concrete adaptation strategy for LVLMs that avoids manual prompts. Public release of data and code is a clear strength that could accelerate research on domain-specific vision-language applications in manufacturing.
major comments (1)
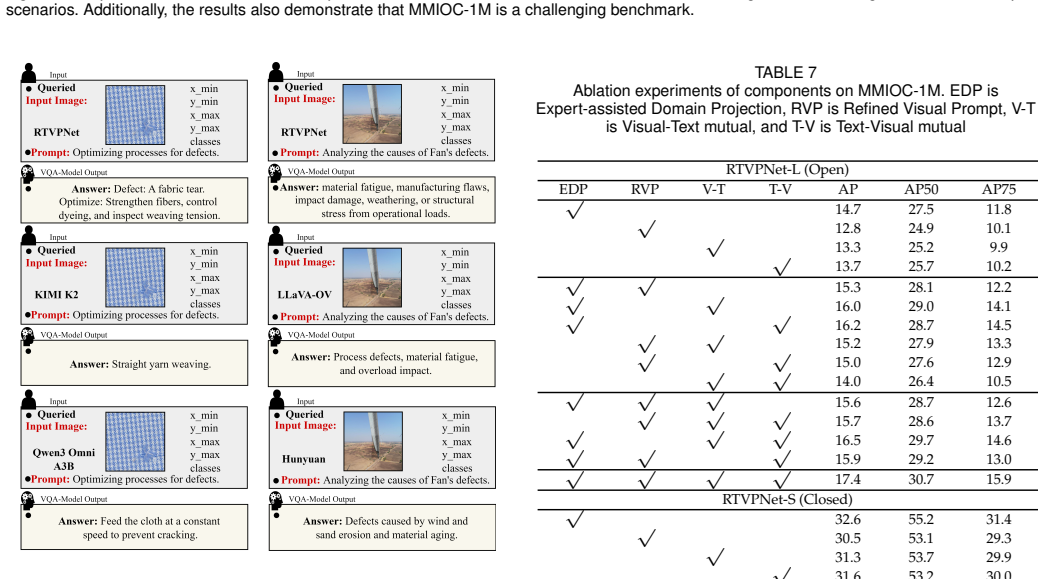
- [Abstract / Experiments] The headline SOTA claim on LVIS and COCO rests on the assertion that the three RTVPNet components produce measurable gains outside the industrial domain. The abstract states that 'extensive experiments demonstrate' this performance but supplies no ablation tables, performance deltas, or component-removal results on LVIS/COCO; without such evidence the generalization step remains unsecured.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the generalization claims require stronger supporting evidence and will revise the manuscript to address this.
read point-by-point responses
-
Referee: [Abstract / Experiments] The headline SOTA claim on LVIS and COCO rests on the assertion that the three RTVPNet components produce measurable gains outside the industrial domain. The abstract states that 'extensive experiments demonstrate' this performance but supplies no ablation tables, performance deltas, or component-removal results on LVIS/COCO; without such evidence the generalization step remains unsecured.
Authors: We acknowledge the validity of this observation. The current manuscript presents component ablations and performance deltas primarily on the MMIOC-1M benchmark (Tables 3-5 and associated figures), while LVIS and COCO results focus on overall SOTA comparisons. To secure the generalization claim, we will add new ablation tables in the revised version showing the effect of removing each RTVPNet component (domain projection, sparse sampling, bidirectional interaction) on LVIS and COCO, including quantitative deltas relative to the full model. revision: yes
Circularity Check
No circularity: empirical benchmark and model proposal with external validation
full rationale
The paper introduces the MMIOC-1M dataset and RTVPNet architecture (with expert-assisted projection, energy-based sampling, and bidirectional interaction) then reports empirical results on MMIOC-1M plus the independent external benchmarks LVIS and COCO. No derivation chain, first-principles predictions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on measured performance rather than any reduction of outputs to inputs by construction, satisfying the self-contained-against-external-benchmarks criterion for score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yolov7: Trainable bag-of-freebies sets new state-of- the-art for real-time object detectors,
C.-Y. Wang, “Yolov7: Trainable bag-of-freebies sets new state-of- the-art for real-time object detectors,” inCVPR, 2023, pp. 7464– 7475
2023
-
[2]
Yolox: Exceeding yolo series in 2021,
Z. Ge and S. Liu, “Yolox: Exceeding yolo series in 2021,”arXiv preprint arXiv:2107.08430, 2021
Pith/arXiv arXiv 2021
-
[3]
Yolov6: A single-stage object detection framework for industrial applications,
C. Li and L. Li, “Yolov6: A single-stage object detection framework for industrial applications,”arXiv preprint arXiv:2209.02976, 2022
arXiv 2022
-
[4]
Available: https://github.com/ultralytics/yolov8, 2023
ultralytics, “Yolov8,”[Online]. Available: https://github.com/ultralytics/yolov8, 2023
2023
-
[5]
Liteyolo-id: A lightweight object detection network for insulator defect detection,
D. Li and Y. Lu, “Liteyolo-id: A lightweight object detection network for insulator defect detection,”IEEE Trans. on Instru. and Measure., vol. 73, pp. 1–12, 2024
2024
-
[6]
Segment anything,
A. Kirillov and E. Mintun, “Segment anything,” inICCV, October 2023, pp. 4015–4026
2023
-
[7]
X. Zhao and W. Ding, “Fast segment anything,” 2023. [Online]. Available: https://arxiv.org/abs/2306.12156
arXiv 2023
-
[8]
Faster segment anything: Towards lightweight sam for mobile applications,
C. Zhang, “Faster segment anything: Towards lightweight sam for mobile applications,”arXiv preprint arXiv:2306.14289, 2023
Pith/arXiv arXiv 2023
-
[9]
Visual instruction tuning,
H. Liu and C. Li, “Visual instruction tuning,” vol. 36, 2024
2024
-
[10]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection,
S. Liu and Z. Zeng, “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” inECCV. Springer, 2024, pp. 38–55
2024
-
[11]
S2dbft: Spectral-spatial dual-branch fusion trans- former for hyperspectral image classification,
Y. Zhang, Z. Wang, M. Huang, M. Li, J. Zhang, S. Wang, J. Zhang, and H. Zhang, “S2dbft: Spectral-spatial dual-branch fusion trans- former for hyperspectral image classification,”IEEE Transactions on Geoscience and Remote Sensing, 2025
2025
-
[12]
Implementation of motion estimation based on heterogeneous parallel computing system with opencl,
J. Zhang, J.-F. Nezan, and J.-G. Cousin, “Implementation of motion estimation based on heterogeneous parallel computing system with opencl,” in2012 IEEE 14th International Conference on High Performance Computing and Communication & 2012 IEEE 9th Inter- national Conference on Embedded Software and Systems. IEEE, 2012, pp. 41–45
2012
-
[13]
3d octave and 2d vanilla mixed convolutional neural network for hyperspectral image classification with limited samples,
Y. Feng, J. Zheng, M. Qin, C. Bai, and J. Zhang, “3d octave and 2d vanilla mixed convolutional neural network for hyperspectral image classification with limited samples,”Remote Sensing, vol. 13, no. 21, p. 4407, 2021. UNIFICATION OF CLOSED-OPEN INDUSTRIAL DETECTION SCENARIOS: NEW LARGE-SCALE BENCHMARKS, CHALLENGES AND BASELINES 17
2021
-
[14]
Learning vertex representations for bipartite networks,
M. Gao, X. He, L. Chen, T. Liu, J. Zhang, and A. Zhou, “Learning vertex representations for bipartite networks,”IEEE transactions on knowledge and data engineering, vol. 34, no. 1, pp. 379–393, 2020
2020
-
[15]
Multi-granularity episodic contrastive learning for few-shot learning,
P . Zhu, Z. Zhu, Y. Wang, J. Zhang, and S. Zhao, “Multi-granularity episodic contrastive learning for few-shot learning,”Pattern Recog- nition, vol. 131, p. 108820, 2022
2022
-
[16]
A novel ground-based cloud image segmentation method by using deep transfer learning,
Z. Zhou, F. Zhang, H. Xiao, F. Wang, X. Hong, K. Wu, and J. Zhang, “A novel ground-based cloud image segmentation method by using deep transfer learning,”IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2021
2021
-
[17]
Ensemble meteorological cloud classifica- tion meets internet of dependable and controllable things,
J. Zhang, P . Liu, F. Zhang, H. Iwabuchi, A. A. d. H. e Ayres, V . H. C. De Albuquerqueet al., “Ensemble meteorological cloud classifica- tion meets internet of dependable and controllable things,”IEEE Internet of Things Journal, vol. 8, no. 5, pp. 3323–3330, 2020
2020
-
[18]
Automated cca-mwf algorithm for unsuper- vised identification and removal of eog artifacts from eeg,
M. Miao, W. Hu, B. Xu, J. Zhang, J. J. Rodrigues, and V . H. C. De Albuquerque, “Automated cca-mwf algorithm for unsuper- vised identification and removal of eog artifacts from eeg,”IEEE Journal of Biomedical and Health Informatics, vol. 26, no. 8, pp. 3607– 3617, 2021
2021
-
[19]
Supervised learning based discrete hashing for image retrieval,
Q. Ma, C. Bai, J. Zhang, Z. Liu, and S. Chen, “Supervised learning based discrete hashing for image retrieval,”Pattern Recognition, vol. 92, pp. 156–164, 2019
2019
-
[20]
Clothing sale forecasting by a composite gru–prophet model with an attention mechanism,
Y. Li, Y. Yang, K. Zhu, and J. Zhang, “Clothing sale forecasting by a composite gru–prophet model with an attention mechanism,” IEEE Transactions on Industrial Informatics, vol. 17, no. 12, pp. 8335– 8344, 2021
2021
-
[21]
Distilled large language model-driven dynamic sparse expert activation mechanism,
Q. Chen, Z. Zhang, Z. Zhang, K. Zhang, D. Li, W. Wang, J. Zhang, and C. Liu, “Distilled large language model-driven dynamic sparse expert activation mechanism,”Applied Soft Computing, p. 114037, 2025
2025
-
[22]
Dual-path aggregation transformer network for super-resolution with images occlusions and variabil- ity,
Q. Chen, L. Wang, Z. Zhang, X. Wang, W. Liu, B. Xia, H. Ding, J. Zhang, S. Xu, and X. Wang, “Dual-path aggregation transformer network for super-resolution with images occlusions and variabil- ity,”Engineering Applications of Artificial Intelligence, vol. 139, no. PartA, 2025
2025
-
[23]
Kftd: Koopman- fourier time-differentiable network for continuous ocean spa- tiotemporal forecasting,
Q. Chen, Z. Zhang, H. Liu, J. Zhang, and C. Bai, “Kftd: Koopman- fourier time-differentiable network for continuous ocean spa- tiotemporal forecasting,” inProceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, 2026, pp. 94–103
2026
-
[24]
A novel dataset and lightweight distillation baseline for highlight transparent object detection,
Z. Zhang, G. Li, H. Zhang, Q. Chen, Q. Zhang, J. Wan, M. Xiong, C. Bai, D. Li, W. Zhanget al., “A novel dataset and lightweight distillation baseline for highlight transparent object detection,” International Journal of Computer Vision, vol. 134, no. 4, p. 157, 2026
2026
-
[25]
Idd- net: Industrial defect detection method based on deep-learning,
Z. Zhang, M. Zhou, H. Wan, M. Li, G. Li, and D. Han, “Idd- net: Industrial defect detection method based on deep-learning,” Engineering Applications of Artificial Intelligence, vol. 123, p. 106390, 2023
2023
-
[26]
Zero-shot learning in industrial scenarios: New large-scale benchmark, challenges and baseline,
Z. Zhang, Q. Chen, M. Xiong, S. Ding, Z. Su, X. Yao, Y. Sun, C. Bai, and J. Zhang, “Zero-shot learning in industrial scenarios: New large-scale benchmark, challenges and baseline,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 10, 2025, pp. 10 357–10 366
2025
-
[27]
Representation learning based on co- evolutionary combined with probability distribution optimization for precise defect location,
J. Zhang, Z. Zhang, Q. Chen, G. Li, W. Li, S. Ding, M. Xiong, W. Zhang, and S. Chen, “Representation learning based on co- evolutionary combined with probability distribution optimization for precise defect location,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 7, pp. 11 989–12 003, 2024
2024
-
[28]
Unification of closed-open industrial detection scenarios: New large-scale benchmarks, challenges and baselines,
Z. Zhang, J. Zhang, Q. Chen, G. Li, D. Chen, S. Jing, H. Wang, D. Li, C. Liu, C. Baiet al., “Unification of closed-open industrial detection scenarios: New large-scale benchmarks, challenges and baselines,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[29]
Distillation-based fabric anomaly detection,
S. Thomine and H. Snoussi, “Distillation-based fabric anomaly detection,”Textile Research Journal, vol. 94, no. 5-6, pp. 552–565, 2024
2024
-
[30]
Deep learning for medical anomaly detection–a survey,
T. Fernando and H. Gammulle, “Deep learning for medical anomaly detection–a survey,”ACM Computing Surveys (CSUR), vol. 54, no. 7, pp. 1–37, 2021
2021
-
[31]
Fdsnet: An accurate real-time surface defect segmentation network,
J. Zhang and R. Ding, “Fdsnet: An accurate real-time surface defect segmentation network,” inICASSP, 2022, pp. 3803–3807
2022
-
[32]
Matcher: Segment anything with one shot us- ing all-purpose feature matching,
Y. Liu and M. Zhu, “Matcher: Segment anything with one shot us- ing all-purpose feature matching,”arXiv preprint arXiv:2305.13310, 2023
arXiv 2023
-
[33]
Personalize segment anything model with one shot,
R. Zhang and Z. Jiang, “Personalize segment anything model with one shot,”arXiv preprint arXiv:2305.03048, 2023
arXiv 2023
-
[34]
Aggregated residual transformations for deep neural networks,
S. Xie and R. Girshick, “Aggregated residual transformations for deep neural networks,” inCVPR, July 2017
2017
-
[35]
Deep residual learning for image recogni- tion,
K. He and X. Zhang, “Deep residual learning for image recogni- tion,” inCVPR, 2016, pp. 770–778
2016
-
[36]
Cpt: Colorful prompt tuning for pre-trained vision-language models,
Y. Yao and A. Zhang, “Cpt: Colorful prompt tuning for pre-trained vision-language models,”AI Open, vol. 5, pp. 30–38, 2024
2024
-
[37]
Reclip: A strong zero-shot baseline for referring expression comprehension,
S. Subramanian, “Reclip: A strong zero-shot baseline for referring expression comprehension,”arXiv preprint arXiv:2204.05991, 2022
arXiv 2022
-
[38]
How to efficiently adapt large segmentation model (sam) to medical images,
X. Hu and X. Xu, “How to efficiently adapt large segmentation model (sam) to medical images,”arXiv preprint arXiv:2306.13731, 2023
arXiv 2023
-
[39]
Cocoopter: Pre-train, prompt, and fine-tune the vision-language model for few-shot image classification,
J. Yan and Y. Xie, “Cocoopter: Pre-train, prompt, and fine-tune the vision-language model for few-shot image classification,”Int. J. Multi. Inform. Retri., vol. 12, no. 2, p. 27, 2023
2023
-
[40]
Yolo-world: Real-time open-vocabulary object detection,
T. Cheng and L. Song, “Yolo-world: Real-time open-vocabulary object detection,” inCVPR, 2024, pp. 16 901–16 911
2024
-
[41]
LVIS: A dataset for large vocabulary instance segmentation,
A. Gupta and P . Doll ´ar, “LVIS: A dataset for large vocabulary instance segmentation,”CoRR, vol. abs/1908.03195, 2019
arXiv 1908
-
[42]
Microsoft coco: Common objects in context,
T.-Y. Lin and M. Maire, “Microsoft coco: Common objects in context,” inECCV, D. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, Eds., vol. 8693, 2014, pp. 740–755
2014
-
[43]
Zero-shot learning in industrial scenarios: New large-scale benchmark, challenges and baseline,
Z. Zhang and Q. Chen, “Zero-shot learning in industrial scenarios: New large-scale benchmark, challenges and baseline,” inAAAI, vol. 39, no. 10, Apr. 2025, pp. 10 357–10 366. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/33124
2025
-
[44]
X. Jiang and J. Li, “Mmad: The first-ever comprehensive bench- mark for multimodal large language models in industrial anomaly detection,”arXiv preprint arXiv:2410.09453, 2024
arXiv 2024
-
[45]
Defect spectrum: a granular look of large- scale defect datasets with rich semantics,
S. Yang and Z. Chen, “Defect spectrum: a granular look of large- scale defect datasets with rich semantics,” inECCV. Springer, 2024, pp. 187–203
2024
-
[46]
Vision datasets: A benchmark for vision-based industrial inspection,
H. Bai and S. Mou, “Vision datasets: A benchmark for vision-based industrial inspection,”arXiv preprint arXiv:2306.07890, 2023
arXiv 2023
-
[47]
Pku-goodsad: A supermarket goods dataset for unsupervised anomaly detection and segmentation,
J. Zhang and R. Ding, “Pku-goodsad: A supermarket goods dataset for unsupervised anomaly detection and segmentation,” IEEE Robot. and Auto. Lett., vol. 9, no. 3, pp. 2008–2015, 2024
2008
-
[48]
Mvtec ad–a comprehensive real- world dataset for unsupervised anomaly detection,
P . Bergmann and M. Fauser, “Mvtec ad–a comprehensive real- world dataset for unsupervised anomaly detection,” inCVPR, 2019, pp. 9592–9600
2019
-
[49]
Spot-the-difference self-supervised pre- training for anomaly detection and segmentation,
Y. Zou and J. Jeong, “Spot-the-difference self-supervised pre- training for anomaly detection and segmentation,” inECCV. Springer, 2022, pp. 392–408
2022
-
[50]
Real-iad: A real-world multi-view dataset for benchmarking versatile industrial anomaly detection,
C. Wang and W. Zhu, “Real-iad: A real-world multi-view dataset for benchmarking versatile industrial anomaly detection,” in CVPR, 2024, pp. 22 883–22 892
2024
-
[51]
Multi-sensor object anomaly detection: Uni- fying appearance, geometry, and internal properties,
W. Li and B. Zheng, “Multi-sensor object anomaly detection: Uni- fying appearance, geometry, and internal properties,” inCVPR, 2025, pp. 9984–9993
2025
-
[52]
3cad: A large-scale real-world 3c product dataset for unsupervised anomaly detection,
E. Yang and P . Xing, “3cad: A large-scale real-world 3c product dataset for unsupervised anomaly detection,” inAAAI, vol. 39, no. 9, 2025, pp. 9175–9183
2025
-
[53]
Pixel-level contrastive pretrainer for indus- trial image representation,
B. Zhu and Y. Chen, “Pixel-level contrastive pretrainer for indus- trial image representation,”IEEE Trans. on Instru. and Measure., vol. 73, 2024
2024
-
[54]
Vt-adl: A vision transformer network for image anomaly detection and localization,
P . Mishra and R. Verk, “Vt-adl: A vision transformer network for image anomaly detection and localization,” inISIE. IEEE, 2021, pp. 01–06
2021
-
[55]
J. Achiam and S. Adler, “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[56]
Learning transferable visual models from natural language supervision,
A. Radford and J. W. Kim, “Learning transferable visual models from natural language supervision,” inICML. PMLR, 2021, pp. 8748–8763
2021
-
[57]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,
J. Li and D. Li, “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” inICML. PMLR, 2023, pp. 19 730–19 742
2023
-
[58]
Application of segment anything model for civil infrastructure defect assessment,
M. Ahmadi and A. G. Lonbar, “Application of segment anything model for civil infrastructure defect assessment,”arXiv preprint arXiv:2304.12600, 2023
arXiv 2023
-
[59]
Medical sam adapter: Adapting segment anything model for medical image segmentation,
J. Wu and Z. Wang, “Medical sam adapter: Adapting segment anything model for medical image segmentation,”Medical image analysis, vol. 102, p. 103547, 2025
2025
-
[60]
Y. Xu and J. Tang, “Eviprompt: A training-free evidential prompt generation method for segment anything model in medical im- ages,”arXiv preprint arXiv:2311.06400, 2023
arXiv 2023
-
[61]
Adaptershadow: Adapting seg- ment anything model for shadow detection,
L. Jie and H. Zhang, “Adaptershadow: Adapting seg- ment anything model for shadow detection,”arXiv preprint arXiv:2311.08891, 2023. UNIFICATION OF CLOSED-OPEN INDUSTRIAL DETECTION SCENARIOS: NEW LARGE-SCALE BENCHMARKS, CHALLENGES AND BASELINES 18
arXiv 2023
-
[62]
Autoprompt: Eliciting knowledge from language models with automatically generated prompts,
T. Shin and Y. Razeghi, “Autoprompt: Eliciting knowledge from language models with automatically generated prompts,”arXiv preprint arXiv:2010.15980, 2020
arXiv 2010
-
[63]
Fine-grained visual prompting,
L. Yang and Y. Wang, “Fine-grained visual prompting,”NeurIPS, vol. 36, 2024
2024
-
[64]
Vrp-sam: Sam with visual reference prompt,
Y. Sun and J. Chen, “Vrp-sam: Sam with visual reference prompt,” inCVPR, 2024, pp. 23 565–23 574
2024
-
[65]
Yolo-uniow: Efficient universal open-world object detection,
L. Liu and J. Feng, “Yolo-uniow: Efficient universal open-world object detection,”arXiv preprint arXiv:2412.20645, 2024
arXiv 2024
-
[66]
Relational proxies: Fine-grained relationships as zero-shot discriminators,
A. Chaudhuri and M. Mancini, “Relational proxies: Fine-grained relationships as zero-shot discriminators,”IEEE Trans. on Pattern Anal. and Mach. Intell., 2024
2024
-
[67]
Segment anything is not always perfect: An investigation of sam on different real-world applications,
W. Ji and J. Li, “Segment anything is not always perfect: An investigation of sam on different real-world applications,”Machine Intelligence Research, vol. 21, pp. 617–630, 2024
2024
-
[68]
Masked autoencoders are scalable vision learners,
K. He and X. Chen, “Masked autoencoders are scalable vision learners,” inCVPR, 2022, pp. 16 000–16 009
2022
-
[69]
Distance-iou loss: Faster and better learning for bounding box regression,
Z. Zheng and P . Wang, “Distance-iou loss: Faster and better learning for bounding box regression,” inAAAI, vol. 34, no. 07, 2020, pp. 12 993–13 000
2020
-
[70]
Representation learning with contrastive predictive coding,
A. v. d. Oord and Y. Li, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[71]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,
D. Guo and D. Yang, “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[72]
Y. He and H. Su, “A light-weight framework for open-set object detection with decoupled feature alignment in joint space,” 2024. [Online]. Available: https://arxiv.org/abs/2412.14680
arXiv 2024
-
[73]
Mamba-yolo-world: Marrying yolo-world with mamba for open-vocabulary detection,
H. Wang and Q. He, “Mamba-yolo-world: Marrying yolo-world with mamba for open-vocabulary detection,” inICASSP, 2025, pp. 1–5
2025
-
[74]
S. Bai and K. Chen, “Qwen2.5-vl technical report,” 2025. [Online]. Available: arXivpreprintarXiv:2502.13923
Pith/arXiv arXiv 2025
-
[75]
J. Xu and Z. Guo, “Qwen3-omni technical report,” 2025. [Online]. Available: arXivpreprintarXiv:2505.09388
Pith/arXiv arXiv 2025
-
[76]
Large-scale visual language model boosted by contrast domain adaptation for intelligent industrial visual monitoring,
H. Wang and C. Li, “Large-scale visual language model boosted by contrast domain adaptation for intelligent industrial visual monitoring,”IEEE Trans. on Indus. Infor., vol. 20, no. 12, pp. 14 114– 14 123, 2024
2024
-
[77]
Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models,
F. Li, “Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models,” 2025. [Online]. Available: arXivpreprintarXiv:2407.07895
Pith/arXiv arXiv 2025
-
[78]
Llava-onevision: Easy visual task transfer,
B. Li and Y. Zhang, “Llava-onevision: Easy visual task transfer,”
-
[79]
Available: arXivpreprintarXiv:2408.03326
[Online]. Available: arXivpreprintarXiv:2408.03326
-
[80]
Yolov11: An overview of the key architectural enhancements,
R. Khanam and M. Hussain, “Yolov11: An overview of the key architectural enhancements,” 2024. [Online]. Available: https://arxiv.org/abs/2410.17725
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.