UniQL: Towards Dialect-Universal Benchmarking for Text-to-SQL
Pith reviewed 2026-06-27 19:51 UTC · model grok-4.3
The pith
UniQL aligns 1534 questions with executable SQL across 16 dialects to measure cross-dialect generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
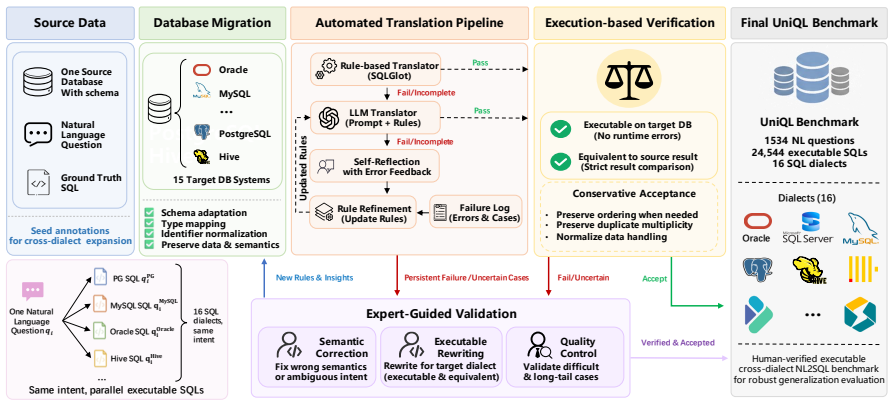
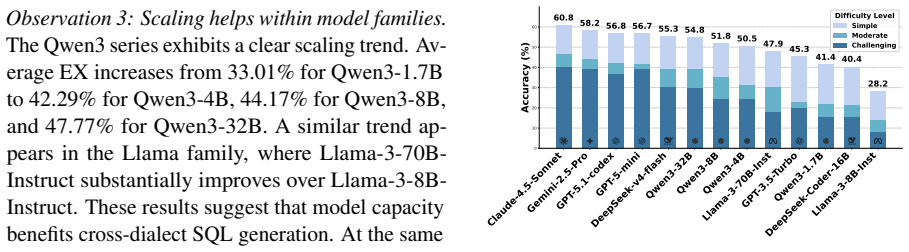
UniQL supplies 1534 natural language questions aligned to 24544 dialect-specific SQL queries spanning 16 SQL dialects. All queries share identical intents, schemas, and database contents, and were produced by a pipeline of database migration, SQL translation, execution-guided verification, iterative rule summarization, and human validation. Evaluation on multiple LLMs reveals substantial accuracy variation across dialects together with limited transfer from success on SQLite to other systems.
What carries the argument
The hybrid pipeline of database migration, SQL translation, execution-guided verification, iterative rule summarization, and human validation that produces semantically equivalent queries across dialects.
If this is right
- Model accuracy on SQLite does not reliably predict accuracy on other dialects.
- Text-to-SQL methods must incorporate explicit dialect handling to reach uniform performance.
- Future benchmarks should maintain aligned schemas and contents across multiple dialects rather than treating each dialect in isolation.
Where Pith is reading between the lines
- Training or adaptation procedures that expose models to multiple dialects simultaneously may reduce the observed performance variation.
- Real-world text-to-SQL systems deployed against heterogeneous database backends will require dialect-specific post-processing or routing until generalization improves.
Load-bearing premise
The hybrid pipeline produces queries that are semantically equivalent across dialects without systematic translation errors or selection bias.
What would settle it
Demonstrating a non-negligible fraction of UniQL query pairs that produce different results when executed on their respective dialect databases would falsify the claimed equivalence.
Figures
read the original abstract
Existing text-to-SQL benchmarks are largely centered on SQLite, making it difficult to evaluate whether models can generalize across heterogeneous SQL dialects. However, real-world database systems differ substantially in syntax, functions, type systems, and execution semantics, so the same natural language intent often requires dialect-specific SQL realizations. We introduce UniQL, a human-verified benchmark for cross-dialect text-to-SQL evaluation. UniQL aligns 1,534 natural language questions with executable SQL annotations across 16 SQL dialects, yielding 24,544 dialect-specific queries. All dialects share the same intents, aligned schemas and database contents, enabling controlled evaluation of dialect generalization. UniQL is constructed through a hybrid pipeline combining database migration, SQL translation, execution-guided verification, iterative rule summarization, and human validation. Experiments on both open-source and closed-source LLMs show that current models remain far from dialect-universal, with substantial performance variation across database systems and limited transfer from SQLite success to other dialects. These findings highlight the need for aligned cross-dialect benchmarks and more dialect-aware text-to-SQL methods. Code and data are available at https://github.com/JerryGao818/UniQL
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniQL, a benchmark aligning 1,534 natural language questions to executable SQL across 16 dialects (yielding 24,544 queries) via a hybrid pipeline of database migration, SQL translation, execution-guided verification, iterative rule summarization, and human validation. All dialects share identical intents, schemas, and data. Experiments on open- and closed-source LLMs demonstrate substantial cross-dialect performance variation and limited transfer from SQLite success, arguing that current models are far from dialect-universal and that aligned cross-dialect benchmarks are needed.
Significance. If the alignments hold, the work is significant for exposing a real gap in text-to-SQL evaluation: most existing benchmarks are SQLite-centric while production systems differ in syntax, functions, and semantics. The public code and data release supports reproducibility and enables follow-on work on dialect-aware methods.
major comments (2)
- [§3 (pipeline description)] Construction pipeline (abstract and §3): the central claim that the 24,544 queries are semantically equivalent across dialects rests on the hybrid pipeline, yet no inter-annotator agreement, human-validation rejection rates, translation error rates, or post-validation execution-match statistics are reported. Without these quantities the observed performance gaps could arise from undetected alignment artifacts rather than model limitations.
- [§4 (experiments)] Experimental results (§4): the headline finding of 'limited transfer from SQLite success to other dialects' requires that every NL question maps to executable, semantically identical SQL in all 16 dialects on identical schemas; the absence of the validation metrics above makes this transfer claim difficult to interpret.
minor comments (2)
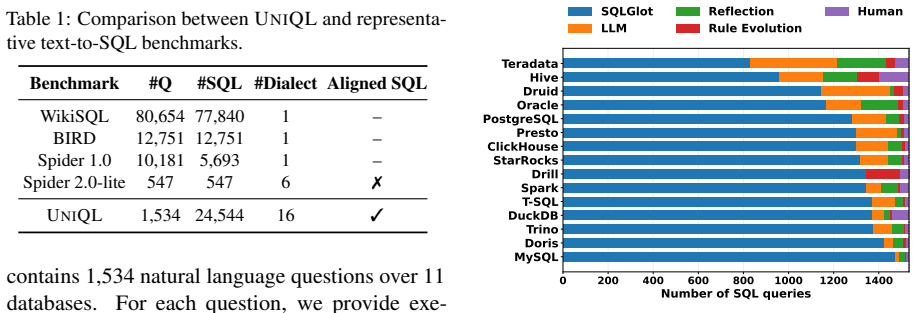
- [Abstract] Abstract: the arithmetic 1,534 × 16 = 24,544 is correct and should be stated explicitly when first introducing the query count.
- [Results tables] Table/figure captions: ensure every table or figure reporting per-dialect accuracies also states the exact number of queries evaluated per dialect so readers can assess statistical power.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies a key area for strengthening the presentation of our validation process. We address each major comment below and commit to revisions that will incorporate the requested quantitative details without altering the core claims or methodology.
read point-by-point responses
-
Referee: [§3 (pipeline description)] Construction pipeline (abstract and §3): the central claim that the 24,544 queries are semantically equivalent across dialects rests on the hybrid pipeline, yet no inter-annotator agreement, human-validation rejection rates, translation error rates, or post-validation execution-match statistics are reported. Without these quantities the observed performance gaps could arise from undetected alignment artifacts rather than model limitations.
Authors: We agree that the absence of these specific quantitative metrics limits the ability to fully assess alignment quality. The original manuscript describes the hybrid pipeline (database migration, SQL translation, execution-guided verification, iterative rule summarization, and human validation) but does not report the requested statistics. In the revised version we will add a new subsection (or appendix) providing: (1) inter-annotator agreement computed on a sampled subset of annotations, (2) human-validation rejection rates, (3) translation error rates observed during the automated steps, and (4) post-validation execution-match statistics across dialects. These additions will directly support the claim of semantic equivalence and reduce the possibility that performance gaps arise from undetected artifacts. revision: yes
-
Referee: [§4 (experiments)] Experimental results (§4): the headline finding of 'limited transfer from SQLite success to other dialects' requires that every NL question maps to executable, semantically identical SQL in all 16 dialects on identical schemas; the absence of the validation metrics above makes this transfer claim difficult to interpret.
Authors: We concur that the transfer claim is more interpretable when accompanied by explicit validation metrics. Once the statistics outlined in our response to the first comment are added, we will update §4 to reference these numbers when discussing the limited transfer from SQLite. We will also add a brief clarification in the experimental setup that the pipeline (including execution-guided verification and human validation) was applied uniformly to ensure every question has executable, semantically aligned SQL across all 16 dialects on identical schemas. This will make the headline finding more robust. revision: yes
Circularity Check
No circularity: benchmark construction and empirical measurement are self-contained
full rationale
The paper presents a dataset construction pipeline (migration, translation, verification, human validation) followed by empirical evaluation of LLMs on the resulting benchmark. No equations, fitted parameters, predictions, or first-principles derivations are claimed. The central claim (models show cross-dialect performance gaps) is a direct measurement on externally produced model outputs, not a reduction to the construction inputs by definition or self-citation. No load-bearing self-citations or ansatzes are present in the provided text. This matches the default case of an empirical benchmark paper with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SQL translation and migration can preserve query semantics and execution results for the selected natural language intents across the 16 dialects
Reference graph
Works this paper leans on
-
[1]
基于深度学习的数据库自然语言接口综述 , year =
-
[2]
2024 , url =
Eosphoros-Ai/. 2024 , url =
2024
-
[3]
, year =
Abhyankar, Nikhil and Gupta, Vivek and Roth, Dan and Reddy, Chandan K. , year =. H-. arXiv , url =
-
[4]
2025 , journal =
Semantic. 2025 , journal =
2025
-
[5]
, year =
Ascoli, Benjamin and Kandikonda, Ram and Choi, Jinho D. , year =. arXiv , url =
-
[6]
AAAI-25 , year =
Arian Askari and Christian P. AAAI-25 , year =
-
[7]
arXiv , url =
Bai, Qiushi and Alsudais, Sadeem and Li, Chen , year =. arXiv , url =
-
[8]
and Guestrin, Carlos and Zaharia, Matei , year =
Biswal, Asim and Patel, Liana and Jha, Siddarth and Kamsetty, Amog and Liu, Shu and Gonzalez, Joseph E. and Guestrin, Carlos and Zaharia, Matei , year =. arXiv , url =
-
[9]
Chafik, Salmane and Ezzini, Saad and Berrada, Ismail , year =
-
[10]
Chang, Shuaichen and. How to. 2023 , journal =
2023
-
[11]
Selective
Chang, Shuaichen and. Selective. 2023 , journal =
2023
-
[12]
Text-to-
Chen, Ziru and Chen, Shijie and White, Michael and Mooney, Raymond and Payani, Ali and Srinivasa, Jayanth and Su, Yu and Sun, Huan , year =. Text-to-. arXiv , url =
-
[13]
2024 , journal =
Chen, Peter Baile and Wenz, Fabian and Zhang, Yi and Kayali, Moe and Tatbul, Nesime and Cafarella, Michael and Demiralp,. 2024 , journal =
2024
-
[14]
Chen, Si-An and Miculicich, Lesly and Eisenschlos, Julian Martin and Wang, Zifeng and Wang, Zilong and Chen, Yanfei and Fujii, Yasuhisa and Lin, Hsuan-Tien and Lee, Chen-Yu and Pfister, Tomas , year =
-
[15]
Chen, Jikai and Gan, Leilei , year =
-
[16]
2025 , journal =
Pi-. 2025 , journal =
2025
-
[17]
Dai, Yaxun and Xie, Wenxuan and Zhuang, Xialie and Yang, Tianyu and Yang, Yiying and Yang, Haiqin and Zhao, Yuhang and Chao, Pingfu and Jiang, Wenhao , year =
-
[18]
Deng, Naihao and Chen, Yulong and Zhang, Yue , year =. Recent
-
[19]
Deng, Minghang and Ramachandran, Ashwin and Xu, Canwen and Hu, Lanxiang and Yao, Zhewei and Datta, Anupam and Zhang, Hao , year =
-
[20]
Dom. Blar-. 2024 , publisher =
2024
-
[21]
, year =
Dong, Xuemei and Zhang, Chao and Ge, Yuhang and Mao, Yuren and Gao, Yunjun and et al. , year =. C3:
-
[22]
Dong, Mingwen and Kumar, Nischal Ashok and Hu, Yiqun and Chauhan, Anuj and Hang, Chung-Wei and Chang, Shuaichen and Pan, Lin and Lan, Wuwei and Zhu, Henghui and Jiang, Jiarong and Ng, Patrick and Wang, Zhiguo , year =
-
[23]
Dou, Longxu and Gao, Yan and Liu, Xuqi and Pan, Mingyang and Wang, Dingzirui and Che, Wanxiang and Zhan, Dechen and Kan, Min-Yen and Lou, Jian-Guang , year =. Towards
-
[24]
Fan, Yuankai and He, Zhenying and Ren, Tonghui and Guo, Dianjun and Chen, Lin and Zhu, Ruisi and Chen, Guanduo and Jing, Yinan and Zhang, Kai and Wang, X.Sean , year =. Gar:. 2023
2023
-
[25]
Fan, Yuankai and Ren, Tonghui and He, Zhenying and Wang, X.Sean and Zhang, Ye and Li, Xingang , year =. 2023
2023
-
[26]
Combining
Fan, Ju and Gu, Zihui and Zhang, Songyue and Zhang, Yuxin and Chen, Zui and Cao, Lei and Li, Guoliang and Madden, Samuel and Du, Xiaoyong and Tang, Nan , year =. Combining. Proceedings of the VLDB Endowment , volume =
-
[27]
Sean , year =
Fan, Yuankai and He, Zhenying and Ren, Tonghui and Huang, Can and Jing, Yinan and Zhang, Kai and Wang, X. Sean , year =. Metasql:
-
[28]
Sean , year =
Fan, Yuankai and Ren, Tonghui and Huang, Can and He, Zhenying and Wang, X. Sean , year =. Grounding
-
[29]
Feng, Yuxi and Li, Raymond and Fan, Zhenan and Carenini, Giuseppe and Pourreza, Mohammadreza and Zhang, Weiwei and Zhang, Yong , year =
-
[30]
Evaluating the
F. Evaluating the. 2024 , publisher =
2024
-
[31]
, year =
Gan, Yujian and Purver, Matthew and Woodward, John R. , year =. A. Proceedings of the 1st
-
[32]
Ganesan, Poojah and Jha, Rajat Aayush and Roth, Dan and Gupta, Vivek , year =
-
[33]
Text-to-
Gao, Dawei and Wang, Haibin and Li, Yaliang and Sun, Xiuyu and Qian, Yichen and Ding, Bolin and Zhou, Jingren , year =. Text-to-
-
[34]
2025 , eprint=
XiYan-SQL: A Novel Multi-Generator Framework For Text-to-SQL , author=. 2025 , eprint=
2025
-
[35]
Automatic Database Description Generation for
Gao, Yingqi and Luo, Zhiling , year =. Automatic Database Description Generation for
-
[36]
Extractive
Glass, Michael and Eyceoz, Mustafa and Subramanian, Dharmashankar and Rossiello, Gaetano and Vu, Long and Gliozzo, Alfio , year =. Extractive
-
[37]
Gong, Yue and Lei, Chuan and Qin, Xiao and Vaidya, Kapil and Narayanaswamy, Balakrishnan and Kraska, Tim , year =
-
[38]
2024 , publisher =
Gorti, Satya Krishna and Gofman, Ilan and Liu, Zhaoyan and Wu, Jiapeng and Vouitsis, No. 2024 , publisher =
2024
-
[39]
Guo, Jiaqi and Si, Ziliang and Wang, Yu and Liu, Qian and Fan, Ming and Lou, Jian-Guang and Yang, Zijiang and Liu, Ting , year =. Chase:. Proceedings of the 59th
-
[40]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
SQLForge: Synthesizing Reliable and Diverse Data to Enhance Text-to-SQL Reasoning in LLMs , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[41]
ST a R - SQL : Self-Taught Reasoner for Text-to- SQL
He, Mingqian and Shen, Yongliang and Zhang, Wenqi and Peng, Qiuying and Wang, Jun and Lu, Weiming. ST a R - SQL : Self-Taught Reasoner for Text-to- SQL. ACL. 2025
2025
-
[42]
Knowledge-to-
Hong, Zijin and Yuan, Zheng and Chen, Hao and Zhang, Qinggang and Huang, Feiran and Huang, Xiao , year =. Knowledge-to-
-
[43]
Hong, Zijin and Yuan, Zheng and Zhang, Qinggang and Chen, Hao and Dong, Junnan and Huang, Feiran and Huang, Xiao , year =. Next-
-
[44]
Service-Oriented
Hu, Wangsu and Tian, Jilei , year =. Service-Oriented. Findings of the
-
[45]
Exploring the
Huang, Yiming and Guo, Jiyu and Mao, Wenxin and Gao, Cuiyun and Han, Peiyi and Liu, Chuanyi and Ling, Qing , year =. Exploring the
-
[46]
Huo, Siyu and Ma, Tengfei and Chen, Jie and Chang, Maria and Wu, Lingfei and Witbrock, Michael , year =. Graph. Proceedings of the
-
[47]
Proceedings of the 2024
Katsimpras, Georgios and Paliouras, Georgios , year =. Proceedings of the 2024
2024
-
[48]
2023 , journal =
A Survey on Deep Learning Approaches for Text-to-. 2023 , journal =
2023
-
[49]
Kobayashi, Hideo and Lan, Wuwei and Shi, Peng and Chang, Shuaichen and Guo, Jiang and Zhu, Henghui and Wang, Zhiguo and Ng, Patrick , year =. You
-
[50]
Bridging the
Kong, Yonghui and Hu, Hongbing and Zhang, Dan and Chai, Siyuan and Zhang, Fan and Wang, Wei , year =. Bridging the
-
[51]
Kothyari, Mayank and Dhingra, Dhruva and Sarawagi, Sunita and Chakrabarti, Soumen , year =
-
[52]
Reinforcing
Kulkarni, Atharv and Srikumar, Vivek , year =. Reinforcing
-
[53]
Kumar, Rahul and Dibbu, Amar Raja and Harsola, Shrutendra and Subrahmaniam, Vignesh and Modi, Ashutosh , year =
-
[54]
Lan, Wuwei and Wang, Zhiguo and Chauhan, Anuj and Zhu, Henghui and Li, Alexander and Guo, Jiang and Zhang, Sheng and Hang, Chung-Wei and Lilien, Joseph and Hu, Yiqun and Pan, Lin and Dong, Mingwen and Wang, Jun and Jiang, Jiarong and Ash, Stephen and Castelli, Vittorio and Ng, Patrick and Xiang, Bing , year =
-
[55]
Lee, Jinhyuk and Chen, Anthony and Dai, Zhuyun and Dua, Dheeru and Sachan, Devendra Singh and Boratko, Michael and Luan, Yi and Arnold, S. Can. 2024 , publisher =
2024
-
[56]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Mcs-sql: Leveraging multiple prompts and multiple-choice selection for text-to-sql generation , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[57]
Overview of the
Lee, Gyubok and Kweon, Sunjun and Bae, Seongsu and Choi, Edward , year =. Overview of the
-
[58]
Lee, Jimin and Baek, Ingeol and Kim, Byeongjeong and Lee, Hwanhee , year =
-
[59]
The Thirteenth International Conference on Learning Representations , year=
Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows , author=. The Thirteenth International Conference on Learning Representations , year=
-
[60]
Li, Haoyang and Zhang, Jing and Li, Cuiping and Chen, Hong , year =
-
[61]
Li, Minghan and Zhuang, Honglei and Hui, Kai and Qin, Zhen and Lin, Jimmy and Jagerman, Rolf and Wang, Xuanhui and Bendersky, Michael , year =. Can. Proceedings of the 47th
-
[62]
Li, Haoyang and Zhang, Jing and Liu, Hanbing and Fan, Ju and Zhang, Xiaokang and Zhu, Jun and Wei, Renjie and Pan, Hongyan and Li, Cuiping and Chen, Hong , year =
-
[63]
Li, Boyan and Luo, Yuyu and Chai, Chengliang and Li, Guoliang and Tang, Nan , year =. The
-
[64]
Li, Zhaodonghui and Yuan, Haitao and Wang, Huiming and Cong, Gao and Bing, Lidong , year =
-
[65]
Findings of the
Li, Chunhui and Wang, Yifan and Wu, Zhen and Yu, Zhen and Zhao, Fei and Huang, Shujian and Dai, Xinyu , year =. Findings of the
-
[66]
Li, Zhishuai and Wang, Xiang and Zhao, Jingjing and Yang, Sun and Du, Guoqing and Hu, Xiaoru and Zhang, Bin and Ye, Yuxiao and Li, Ziyue and Zhao, Rui and Mao, Hangyu , year =
-
[67]
Li, Chaofan and Shao, Yingxia and Liu, Zheng , year =
-
[68]
Tapilot-
Li, Jinyang and Huo, Nan and Gao, Yan and Shi, Jiayi and Zhao, Yingxiu and Qu, Ge and Wu, Yurong and Ma, Chenhao and Lou, Jian-Guang and Cheng, Reynold , year =. Tapilot-
-
[69]
Li, Zhenwen and Xie, Tao , year =. Using
-
[70]
Li, Boyan and Zhang, Jiayi and Fan, Ju and Xu, Yanwei and Chen, Chong and Tang, Nan and Luo, Yuyu , year =. Alpha-
-
[71]
Li, Haoyang and Wu, Shang and Zhang, Xiaokang and Huang, Xinmei and Zhang, Jing and Jiang, Fuxin and Wang, Shuai and Zhang, Tieying and Chen, Jianjun and Shi, Rui and Chen, Hong and Li, Cuiping , title =. 2025 , issue_date =. doi:10.14778/3749646.3749723 , journal =
-
[72]
Li, Jinyang and Li, Xiaolong and Qu, Ge and Jacobsson, Per and Qin, Bowen and Hui, Binyuan and Si, Shuzheng and Huo, Nan and Xu, Xiaohan and Zhang, Yue and Tang, Ziwei and Li, Yuanshuai and Widjaja, Florensia and Zhu, Xintong and Zhou, Feige and Huang, Yongfeng and Papakonstantinou, Yannis and Ozcan, Fatma and Ma, Chenhao and Cheng, Reynold , year =
-
[73]
SCIENTIA SINICA Informationis , volume =
梁, 清源 and 朱, 琪豪 and 孙, 泽宇 and 张, 路 and 张, 文杰 and 熊, 英飞 and 梁, 广泰 and 郁, 莲 , year =. SCIENTIA SINICA Informationis , volume =
-
[74]
Augmenting
Liu, Qi and Ye, Zihuiwen and Yu, Tao and Song, Linfeng and Blunsom, Phil , year =. Augmenting. Findings of the
-
[75]
, year =
Liu, Aiwei and Hu, Xuming and Wen, Lijie and Yu, Philip S. , year =. A Comprehensive Evaluation of
-
[76]
Divide and
Liu, Xiping and Tan, Zhao , year =. Divide and
-
[77]
Uncovering and
Liu, Yan and Gao, Yan and Su, Zhe and Chen, Xiaokang and Ash, Elliott and Lou, Jian-Guang , year =. Uncovering and
-
[78]
Liu, Xiping and Tan, Zhao , year =
-
[79]
IEEE Transactions on Knowledge and Data Engineering , year=
A Survey of Text-to-SQL in the Era of LLMs: Where are we, and where are we going? , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[80]
Liu, Tao and Zan, Hongying and Li, Yifan and Zhang, Dixuan and Kong, Lulu and Liu, Haixin and Hou, Jiaming and Zheng, Aoze and Li, Rui and et al. , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.