Paediatric-HGNN: A Hybrid Heterogeneous Graph Neural Network for Detecting Disfluency in Children's Speech via Multiscale Acoustic Fusion
Pith reviewed 2026-06-27 19:11 UTC · model grok-4.3
The pith
A heterogeneous graph linking word nodes to acoustic frame nodes detects disfluencies in children's speech by modelling hierarchical lexical-acoustic interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
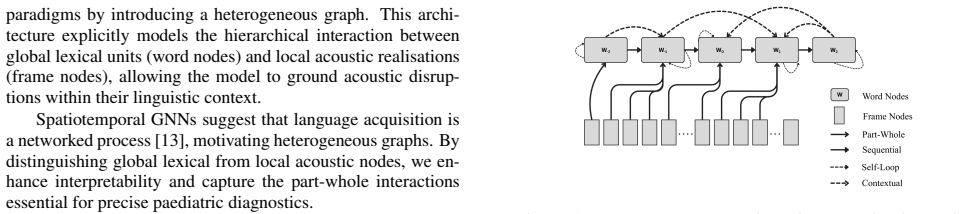
Paediatric-HGNN builds a heterogeneous graph that connects lexical units (word nodes) to fine-grained acoustic segments (frame nodes) and uses the Context-aware Part-whole Interaction Network to model their hierarchical interactions; this structure captures developmental searching behaviour in children's speech and produces 82.4 percent weighted accuracy together with a Typical Disfluency F1-score of 0.386 on the UCLASS and FluencyBank datasets.
What carries the argument
The Context-aware Part-whole Interaction Network (CaPIN) that constructs and reasons over a heterogeneous graph of word nodes and acoustic frame nodes to capture multiscale lexical-acoustic relationships.
If this is right
- The graph representation distinguishes pathological stuttering from typical developmental disfluencies by explicitly modelling part-whole lexical-acoustic hierarchies.
- Performance reaches 82.4 percent weighted accuracy and 0.386 F1 on typical disfluency when trained on the UCLASS and FluencyBank paediatric corpora.
- The resulting model supplies an interpretable account of developmental searching behaviour that supports earlier clinical intervention.
- The same hierarchical construction reduces reliance on hand-crafted acoustic features that are sensitive to age-related voice changes.
Where Pith is reading between the lines
- The same node-and-edge construction could be tested on longitudinal recordings to track how a child's disfluency profile changes with therapy.
- Replacing the current acoustic frame nodes with learned embeddings from self-supervised speech models might further reduce sensitivity to recording conditions.
- Extending the graph to include speaker-identity nodes could allow the model to adapt to individual developmental trajectories without retraining from scratch.
Load-bearing premise
The assumption that a heterogeneous graph of lexical units and acoustic segments will handle high acoustic variability in developing voices better than conventional one-dimensional signal modelling.
What would settle it
An experiment that trains standard one-dimensional convolutional or recurrent models on exactly the same curated UCLASS and FluencyBank splits and obtains equal or higher weighted accuracy and Typical Disfluency F1-score.
Figures

read the original abstract
Automated stuttering detection (ASD) systems struggle with paediatric speech due to high acoustic variability in developing voices and the subtle distinction between pathological stuttering and typical developmental disfluencies. We introduce Paediatric-HGNN, a framework using a Context-aware Part-whole Interaction Network (CaPIN) tailored for paediatric data. Instead of conventional 1D signal modelling, our approach builds a heterogeneous graph capturing hierarchical relationships between lexical units (word nodes) and fine-grained acoustic segments (frame nodes). Trained on curated paediatric corpora (UCLASS and FluencyBank), Paediatric-HGNN achieves 82.4% weighted accuracy and a Typical Disfluency F1-score of 0.386. Modelling hierarchical lexical-acoustic interactions captures developmental "searching" behaviour, offering a more robust and interpretable tool for early clinical intervention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Paediatric-HGNN, a hybrid heterogeneous graph neural network using a Context-aware Part-whole Interaction Network (CaPIN) to detect disfluencies in children's speech. It constructs heterogeneous graphs with word nodes (lexical units) and frame nodes (fine-grained acoustic segments) to model hierarchical lexical-acoustic interactions, trained on UCLASS and FluencyBank corpora, and reports 82.4% weighted accuracy with a Typical Disfluency F1-score of 0.386. The central claim is that this captures developmental 'searching' behaviour more robustly than conventional 1D signal modelling, providing an interpretable tool for early clinical intervention.
Significance. If the empirical results hold under rigorous validation, the work could advance paediatric automated stuttering detection by demonstrating a graph-based multiscale fusion approach that addresses high acoustic variability in developing voices. The explicit modelling of part-whole interactions between lexical and acoustic scales is a plausible hypothesis with potential clinical utility, though its advantage over standard methods remains to be substantiated.
major comments (2)
- [Abstract] Abstract: The performance numbers (82.4% weighted accuracy, 0.386 F1) are presented without any baseline comparisons, ablation studies, or statistical tests against conventional 1D convolutional or recurrent models; this directly undermines the central claim that the heterogeneous graph with CaPIN is superior for handling paediatric variability.
- [Abstract] Abstract: No information is given on train/validation/test splits, cross-validation procedure, error bars, or hyperparameter sensitivity, which are load-bearing for assessing whether the reported metrics reliably support the modelling hypothesis.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight areas where the abstract can be strengthened to better support the manuscript's claims. We will revise the abstract to incorporate key details from the full experimental sections while preserving its conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance numbers (82.4% weighted accuracy, 0.386 F1) are presented without any baseline comparisons, ablation studies, or statistical tests against conventional 1D convolutional or recurrent models; this directly undermines the central claim that the heterogeneous graph with CaPIN is superior for handling paediatric variability.
Authors: The full manuscript contains a dedicated Experiments section with direct comparisons to 1D CNN and BiLSTM baselines, ablation studies isolating the CaPIN components, and paired statistical tests (Wilcoxon signed-rank, p<0.05) demonstrating gains on paediatric data. The abstract, however, does not reference these results. We will revise the abstract to include a single sentence summarizing the relative improvement over conventional models. revision: yes
-
Referee: [Abstract] Abstract: No information is given on train/validation/test splits, cross-validation procedure, error bars, or hyperparameter sensitivity, which are load-bearing for assessing whether the reported metrics reliably support the modelling hypothesis.
Authors: The Methods and Experiments sections detail the 5-fold speaker-independent cross-validation, 70/15/15 stratified splits on the combined UCLASS+FluencyBank corpus, standard deviation across folds as error bars, and grid-search hyperparameter ranges. These details are absent from the abstract. We will add a brief clause to the abstract describing the validation protocol. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical architecture (Paediatric-HGNN with CaPIN) evaluated on public datasets UCLASS and FluencyBank, reporting concrete accuracy and F1 metrics. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described text. The central claim is an architectural hypothesis validated by standard training/testing, with no reduction of outputs to inputs by construction. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
black-box
Introduction Stuttering is a neuro-developmental communication disorder characterised by disruptions in the forward flow of speech, which affects approximately 5% to 8% of children during their preschool years [1]. Early diagnosis is critical, yet current clinical assessments largely rely on subjective manual obser- vations by Speech-Language Pathologists...
-
[2]
Related Work We prioritize paediatric-centric research (e.g., UCLASS), as adult-trained models [3] often neglect child-specific physio- logical and developmental variability [6]. ASD research has transitioned from handcrafted features to deep learning: Stut- terNet [7] (TDNN) captures frame-level data but lacks long- range context, while ACNNs [8] detect ...
Pith/arXiv arXiv 2026
-
[3]
Core” versus “Typical
Methodology 3.1. Paediatric Speech Dataset This study focuses on paediatric speech, using a consolidated corpus from the FluencyBank-CWS [15] and UCLASS [16] datasets. To ensure a strictly child-only training distribution, we selected recordings of 25 children from UCLASS alongside the FluencyBank-CWS subset, encompassing both spontaneous conversational i...
-
[4]
white-box
Results and Discussion Paediatric-HGNN, trained from scratch on paediatric data, achieved a stable overall accuracy of 82.4%±2.7%. Notably (Table 1), the model demonstrated high reliability in identifying Fluent speech (F1 0.904±0.02). The Typical Disfluency class reached a peak F1-score of 0.43 in specific folds (e.g., Fold 1). This confirms that the int...
-
[5]
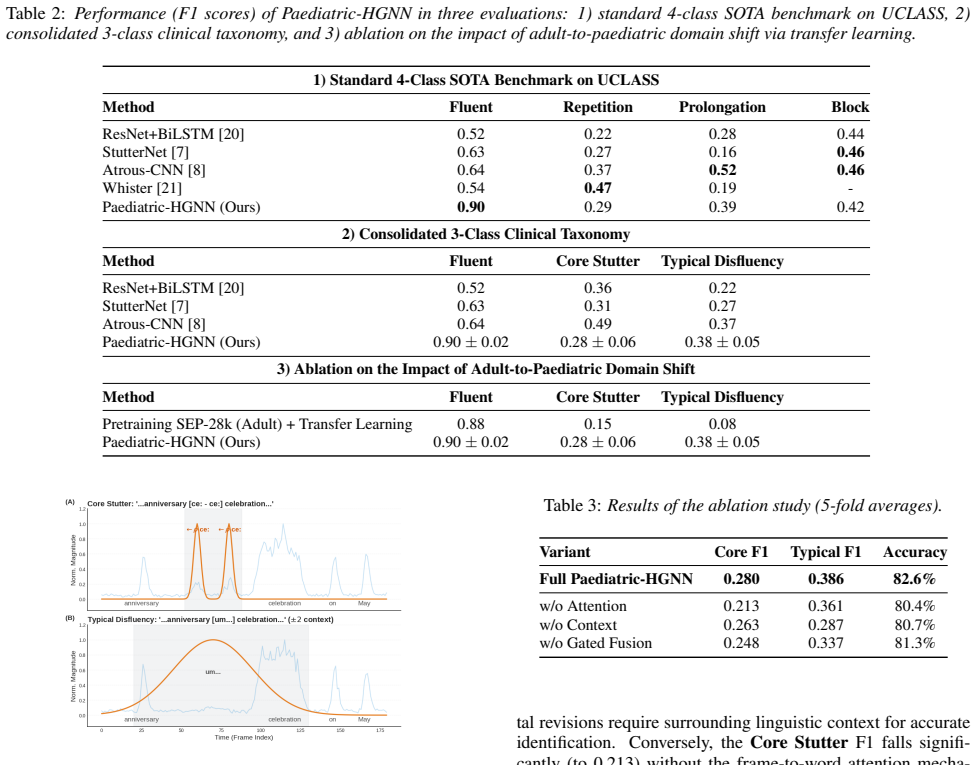
Standard 4-Class SOTA Benchmark on UCLASS Method Fluent Repetition Prolongation Block ResNet+BiLSTM [20] 0.52 0.22 0.28 0.44 StutterNet [7] 0.63 0.27 0.160.46 Atrous-CNN [8] 0.64 0.370.52 0.46 Whister [21] 0.540.470.19 - Paediatric-HGNN (Ours)0.900.29 0.39 0.42
-
[6]
Consolidated 3-Class Clinical Taxonomy Method Fluent Core Stutter Typical Disfluency ResNet+BiLSTM [20] 0.52 0.36 0.22 StutterNet [7] 0.63 0.31 0.27 Atrous-CNN [8] 0.64 0.49 0.37 Paediatric-HGNN (Ours) 0.90±0.02 0.28±0.06 0.38±0.05
-
[7]
anniversary
Ablation on the Impact of Adult-to-Paediatric Domain Shift Method Fluent Core Stutter Typical Disfluency Pretraining SEP-28k (Adult) + Transfer Learning 0.88 0.15 0.08 Paediatric-HGNN (Ours) 0.90±0.02 0.28±0.06 0.38±0.05 Figure 3:Interpretability analysis of hierarchical attention weights (ϕ). (A)Core Stutter: The model exhibits sharp, lo- calised attenti...
-
[8]
Conclusion Paediatric-HGNN is a novel, heterogeneous graph-based frame- work specifically engineered for paediatric ASD. Our find- ings empirically demonstrate that, while SOTA models trained on adult corpora (e.g., SEP-28k) achieve high performance in chronic disfluency tasks, they are fundamentally ill-suited for the unique acoustic and linguistic varia...
-
[9]
No significant part of the technical content, experimental de- sign, or data analysis was produced by generative AI tools
Generative AI Use Disclosure The authors used Generative AI to edit and polish the manuscript to improve grammatical accuracy and readability. No significant part of the technical content, experimental de- sign, or data analysis was produced by generative AI tools. All authors have reviewed the final manuscript and remain fully re- sponsible for its contents
-
[10]
Epidemiology of stuttering: 21st cen- tury advances,
E. Yairi and N. Ambrose, “Epidemiology of stuttering: 21st cen- tury advances,”Journal of Fluency Disorders, vol. 38, no. 2, pp. 66–87, 2013
2013
-
[11]
Variability of stuttering: Behav- ior and impact,
S. E. Tichenor and J. S. Yaruss, “Variability of stuttering: Behav- ior and impact,”American Journal of Speech-Language Pathol- ogy, vol. 30, no. 1, pp. 75–88, 2021
2021
-
[12]
Sep- 28k: A dataset for stuttering event detection from podcasts with people who stutter,
C. Lea, V . Mitra, A. Joshi, S. Kajarekar, and J. P. Bigham, “Sep- 28k: A dataset for stuttering event detection from podcasts with people who stutter,” inIEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2021
2021
-
[13]
Automatic framework to aid therapists to diagnose children who stutter,
S. Alharbi, “Automatic framework to aid therapists to diagnose children who stutter,” PhD Thesis, University of Sheffield, De- partment of Computer Science, Sheffield, UK, 2018
2018
-
[14]
Early childhood stuttering I: Per- sistency and recovery rates,
E. Yairi and N. G. Ambrose, “Early childhood stuttering I: Per- sistency and recovery rates,”Journal of Speech, Language, and Hearing Research, vol. 42, no. 5, pp. 1097–1112, 1999
1999
-
[15]
Robust recognition of chil- dren’s speech,
A. Potamianos and S. Narayanan, “Robust recognition of chil- dren’s speech,”IEEE Transactions on Speech and Audio Process- ing, vol. 11, no. 6, pp. 603–616, 2003
2003
-
[16]
StutterNet: Stuttering detection using time delay neural network,
S. A. Sheikh, M. Sahidullah, F. Hirsch, and S. Ouni, “StutterNet: Stuttering detection using time delay neural network,” inEuro- pean Signal Processing Conference (EUSIPCO), 2021, pp. 426– 430
2021
-
[17]
Stuttering detec- tion using atrous convolutional neural networks,
A.-K. Al-Banna, E. Edirisinghe, and H. Fang, “Stuttering detec- tion using atrous convolutional neural networks,” inInternational Conference on Information and Communication Systems (ICICS), 2022, pp. 252–256
2022
-
[18]
DDSS: Detecting different stuttered speech using various feature extraction tech- niques,
A. Batra, Y . Hema, V . Rao, and P. K. Das, “DDSS: Detecting different stuttered speech using various feature extraction tech- niques,” inMachine Learning, Image Processing, Network Secu- rity and Data Sciences, 2026, pp. 314–325
2026
-
[19]
Controllable time-delay transformer for real-time punctuation prediction and disfluency detection,
Q. Chen, M. Chen, B. Li, and W. Wang, “Controllable time-delay transformer for real-time punctuation prediction and disfluency detection,”arXiv 2003.01309, 2020
arXiv 2003
-
[20]
A lightly supervised approach to detect stuttering in children’s speech,
S. Alharbi, M. Hasan, A. J. H. Simons, S. Brumfitt, and P. Green, “A lightly supervised approach to detect stuttering in children’s speech,” inInterspeech, 2018, pp. 3433–3437
2018
-
[21]
StuD: A multimodal approach for stuttering detection with RAG and fusion strategies,
P. Khanna, P. Kommagouni, V . R. S. Narasinga, and A. Vuppala, “StuD: A multimodal approach for stuttering detection with RAG and fusion strategies,” in14th International Joint Conference on Natural Language Processing and 4th Conference of the Asia- Pacific Chapter of the Association for Computational Linguistics, 2025, pp. 698–707
2025
-
[22]
Longitudinal analysis of early semantic networks: Preferential attachment or preferential acquisition?
T. T. Hills, M. Maouene, J. Maouene, A. Sheya, and L. Smith, “Longitudinal analysis of early semantic networks: Preferential attachment or preferential acquisition?”Psychological Science, vol. 20, no. 6, pp. 729–739, 2009
2009
-
[23]
Stutter- Cut: Uncertainty-guided normalised cut for dysfluency segmenta- tion,
S. Ghosh, M. Jouaiti, J.-O. Perschewski, and S. Stober, “Stutter- Cut: Uncertainty-guided normalised cut for dysfluency segmenta- tion,”arXiv 2508.02255, 2025
arXiv 2025
-
[24]
Fluency Bank: A new resource for fluency research and practice,
N. Bernstein Ratner and B. MacWhinney, “Fluency Bank: A new resource for fluency research and practice,”Journal of Fluency Disorders, vol. 56, pp. 69–80, 2018
2018
-
[25]
The University College Lon- don Archive of Stuttered Speech (UCLASS),
P. Howell, S. Davis, and J. Bartrip, “The University College Lon- don Archive of Stuttered Speech (UCLASS),”Journal of Speech, Language, and Hearing Research, vol. 52, no. 2, pp. 556–569, 2009
2009
-
[26]
YIN, a fundamental fre- quency estimator for speech and music,
A. de Cheveign ´e and H. Kawahara, “YIN, a fundamental fre- quency estimator for speech and music,”Journal of the Acoustical Society of America, vol. 111, pp. 1917–1930, 2002
1917
-
[27]
Decoupled weight decay regulariza- tion,
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,”arXiv 1711.05101, 2019
Pith/arXiv arXiv 2019
-
[28]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. B. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 42, pp. 318–327, 2017
2017
-
[29]
Detecting multi- ple speech disfluencies using a deep residual network with bidi- rectional long short-term memory,
T. Kourkounakis, A. Hajavi, and A. Etemad, “Detecting multi- ple speech disfluencies using a deep residual network with bidi- rectional long short-term memory,” inIEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 6089–6093
2020
-
[30]
Whister: Using whisper’s repre- sentations for stuttering detection,
V . Changawala and F. Rudzicz, “Whister: Using whisper’s repre- sentations for stuttering detection,” inInterspeech, 2024, pp. 897– 901
2024
-
[31]
Normative disfluency data for early childhood stuttering,
N. G. Ambrose and E. Yairi, “Normative disfluency data for early childhood stuttering,”Journal of Speech, Language, and Hearing Research, vol. 42, no. 4, pp. 895–909, 1999
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.