Light-WAM: Efficient World Action Models with State-Fusion Action Decoding
Pith reviewed 2026-06-27 19:54 UTC · model grok-4.3
The pith
A lightweight world action model achieves competitive robot manipulation performance with 0.44B parameters by supervising future video only in downsampled latent space and using state-fusion action decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
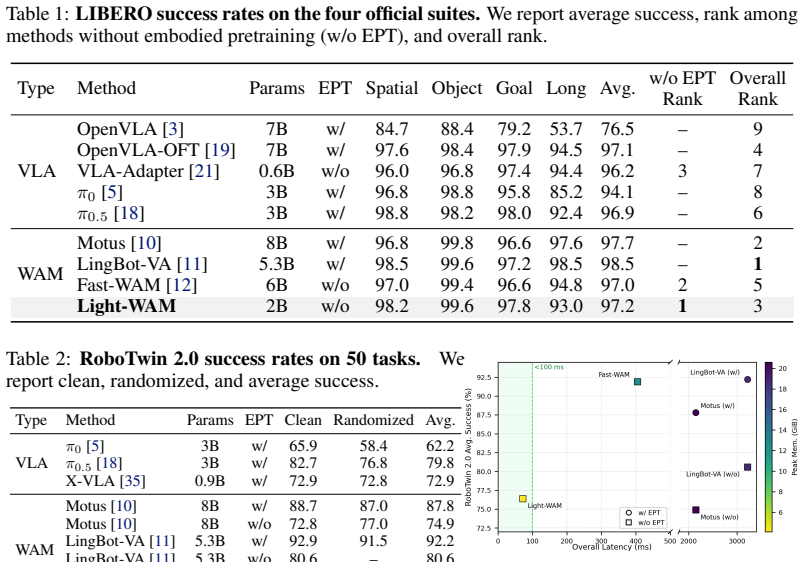
Light-WAM demonstrates that future-video supervision performed in a downsampled latent space, paired with a StateFusionActionExpert that fuses multi-layer states via learned-query pooling, allows a 0.44B-parameter model to retain strong performance on LIBERO and deliver usable multi-task results on RoboTwin 2.0, while reaching 72.03 ms inference latency and 4.1 GiB peak GPU memory.
What carries the argument
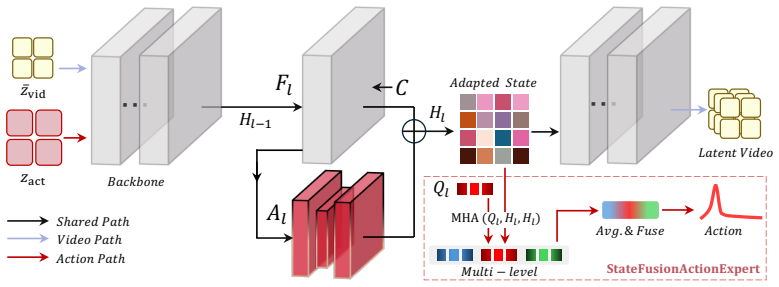
The StateFusionActionExpert, which reads adapted states from multiple layers of a compact video backbone, fuses them through learned-query pooling, and directly outputs action chunks in a single forward pass.
If this is right
- Maintains strong performance on the LIBERO benchmark.
- Achieves usable multi-task performance on RoboTwin 2.0.
- Requires only 0.44B trainable parameters.
- Reaches 72.03 ms inference latency with 4.1 GiB peak GPU memory.
- Improves training throughput relative to prior heavy generative WAMs.
Where Pith is reading between the lines
- The separation of video representation learning from direct action prediction could let the same backbone serve multiple robot embodiments without retraining the full model.
- Downsampling the supervision signal may permit longer prediction horizons or higher frame rates without proportional growth in compute.
- If the latent-space objective generalizes, similar efficiency gains might appear in other vision-based control domains that currently rely on full generative video models.
Load-bearing premise
That performing future-video supervision only in a downsampled latent space retains the representation-learning benefits of full video co-training without introducing new failure modes on manipulation tasks.
What would settle it
A controlled experiment in which the identical backbone trained with full-resolution pixel-space video prediction produces markedly higher success rates on LIBERO or RoboTwin 2.0 than the downsampled-latent version would falsify the claim that the efficiency trade-off preserves task performance.
Figures


read the original abstract
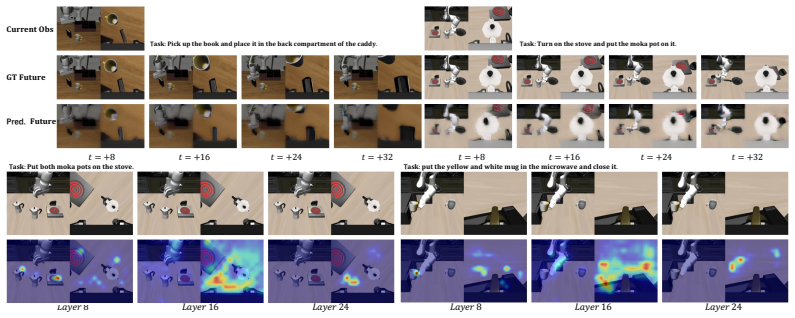
World Action Models (WAMs) extend robot policy learning by incorporating future prediction as an additional training objective, encouraging the policy to encode task-relevant temporal structure in its representations. Current WAMs often rely on large-scale generative architectures that incur high training costs and inference latency, making them difficult to deploy as efficient closed-loop policies. We propose Light-WAM, a lightweight World Action Model for efficient robot manipulation. Specifically, it is built with a compact video backbone and performs future-video supervision in a downsampled latent space, reducing the cost of video co-training while retaining its benefits for representation learning. For action prediction, Light-WAM introduces the StateFusionActionExpert, which reads adapted states from multiple backbone layers, fuses them through learned-query pooling, and directly predicts action chunks in a single forward pass. This design provides an efficient interface between video backbone representations and robot actions, avoiding the need for heavy generative action experts. Experiments demonstrate that Light-WAM maintains strong performance on LIBERO and achieves usable multi-task performance on RoboTwin 2.0, while using only 0.44B trainable parameters. It also achieves 72.03ms inference latency with 4.1GiB peak GPU memory and improved training throughput.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Light-WAM, a lightweight World Action Model for robot manipulation. It uses a compact video backbone with future-video supervision performed exclusively in a downsampled latent space to reduce co-training costs while aiming to retain representation-learning benefits. Action prediction is handled by the StateFusionActionExpert, which reads adapted states from multiple backbone layers, fuses them via learned-query pooling, and predicts action chunks in a single forward pass. Experiments claim that this yields strong performance on LIBERO, usable multi-task results on RoboTwin 2.0, using only 0.44B trainable parameters, with 72.03 ms inference latency and 4.1 GiB peak GPU memory.
Significance. If the performance and efficiency claims hold under scrutiny, the work could meaningfully advance deployable closed-loop policies by lowering the computational overhead of world-action models, particularly through the single-pass StateFusionActionExpert design. The explicit identification of the downsampling factor and backbone-layer count as free parameters is a positive step toward transparency.
major comments (3)
- [§3] §3 (downsampling for latent video space): the central efficiency claim rests on future-video supervision in the downsampled latent space preserving task-relevant temporal and spatial structure. No ablation or sensitivity analysis is reported on the downsampling factor (listed as a free parameter), leaving open whether fine-grained cues required for contact-rich manipulation are lost.
- [Results] Results section (LIBERO and RoboTwin tables): performance is reported as 'strong' and 'usable' without error bars, number of seeds, or explicit baseline comparisons and data-exclusion details. This makes it impossible to assess whether the 0.44B-parameter model reliably matches or exceeds prior WAMs.
- [StateFusionActionExpert] StateFusionActionExpert description: the learned-query pooling is presented as the efficient interface, yet no controlled comparison to simpler concatenation or attention baselines is given to establish that this component is necessary for the reported latency and memory figures.
minor comments (2)
- [Abstract] Abstract: 'improved training throughput' is stated without a quantitative comparison or reference to a specific baseline.
- [Abstract] Notation: the term 'StateFusionActionExpert' appears in the abstract before its definition, which may reduce readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (downsampling for latent video space): the central efficiency claim rests on future-video supervision in the downsampled latent space preserving task-relevant temporal and spatial structure. No ablation or sensitivity analysis is reported on the downsampling factor (listed as a free parameter), leaving open whether fine-grained cues required for contact-rich manipulation are lost.
Authors: We agree that an explicit sensitivity analysis on the downsampling factor would better substantiate the claim that task-relevant structure is retained for contact-rich tasks. Although the factor is identified as a free parameter, we will add an ablation study in the revised manuscript varying this factor and reporting effects on LIBERO and RoboTwin performance. revision: yes
-
Referee: [Results] Results section (LIBERO and RoboTwin tables): performance is reported as 'strong' and 'usable' without error bars, number of seeds, or explicit baseline comparisons and data-exclusion details. This makes it impossible to assess whether the 0.44B-parameter model reliably matches or exceeds prior WAMs.
Authors: We acknowledge that statistical reporting with error bars and seed counts is necessary for assessing reliability. The experiments used multiple seeds; we will revise the results section to include error bars, specify the number of seeds, add explicit baseline comparisons, and clarify data-exclusion details. revision: yes
-
Referee: [StateFusionActionExpert] StateFusionActionExpert description: the learned-query pooling is presented as the efficient interface, yet no controlled comparison to simpler concatenation or attention baselines is given to establish that this component is necessary for the reported latency and memory figures.
Authors: The learned-query pooling in StateFusionActionExpert is intended to provide an efficient interface. We did not include direct comparisons in the original submission. We will add controlled ablations against concatenation and attention baselines in the revision to demonstrate its contribution to the reported latency and memory figures. revision: yes
Circularity Check
No significant circularity; performance claims rest on empirical benchmarks
full rationale
The paper describes an architectural proposal (compact video backbone + downsampled latent supervision + StateFusionActionExpert) whose central claims are validated through training and evaluation on LIBERO and RoboTwin 2.0. No equations, fitted parameters, or self-citations are presented as deriving the reported metrics (0.44B parameters, latency, success rates) by construction. Design choices are justified by efficiency arguments and experimental outcomes rather than definitional equivalence or load-bearing self-citation chains. This is the expected outcome for an empirical systems paper.
Axiom & Free-Parameter Ledger
free parameters (2)
- downsampling factor for latent video space
- number of backbone layers read by StateFusionActionExpert
axioms (1)
- domain assumption Standard supervised learning with video prediction auxiliary loss improves policy representations
invented entities (1)
-
StateFusionActionExpert
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[2]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[3]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[4]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[5]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[6]
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, et al. Smolvla: A vision-language-action model for afford- able and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
Pith/arXiv arXiv 2025
-
[7]
J. Liang, P. Tokmakov, R. Liu, S. Sudhakar, P. Shah, R. Ambrus, and C. V ondrick. Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
Pith/arXiv arXiv 2025
-
[8]
S. Li, Y . Gao, D. Sadigh, and S. Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025
Pith/arXiv arXiv 2025
-
[9]
C. Zhu, R. Yu, S. Feng, B. Burchfiel, P. Shah, and A. Gupta. Unified world models: Cou- pling video and action diffusion for pretraining on large robotic datasets.arXiv preprint arXiv:2504.02792, 2025
Pith/arXiv arXiv 2025
-
[10]
H. Bi, H. Tan, S. Xie, Z. Wang, S. Huang, H. Liu, R. Zhao, Y . Feng, C. Xiang, Y . Rong, et al. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
Pith/arXiv arXiv 2025
-
[11]
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Pith/arXiv arXiv 2026
-
[12]
T. Yuan, Z. Dong, Y . Liu, and H. Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
Pith/arXiv arXiv 2026
-
[13]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[14]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[15]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
Pith/arXiv arXiv 2025
-
[16]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025. 9
Pith/arXiv arXiv 2025
-
[17]
G. R. Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Armstrong, A. Balakr- ishna, R. Baruch, M. Bauza, M. Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
Pith/arXiv arXiv 2025
-
[18]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[19]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[20]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffu- sion foundation model for bimanual manipulation. InInternational Conference on Learning Representations, volume 2025, pages 29982–30009, 2025
2025
-
[21]
Y . Wang, P. Ding, L. Li, C. Cui, Z. Ge, X. Tong, W. Song, H. Zhao, W. Zhao, P. Hou, et al. Vla- adapter: An effective paradigm for tiny-scale vision-language-action model. InProceedings of the AAAI conference on artificial intelligence, volume 40, pages 18638–18646, 2026
2026
-
[22]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023
2023
-
[23]
H. Wu, Y . Jing, C. Cheang, G. Chen, J. Xu, X. Li, M. Liu, H. Li, and T. Kong. Unleashing large- scale video generative pre-training for visual robot manipulation. InInternational Conference on Learning Representations, volume 2024, pages 10641–10662, 2024
2024
-
[24]
H. Bharadhwaj, D. Dwibedi, A. Gupta, S. Tulsiani, C. Doersch, T. Xiao, D. Shah, F. Xia, D. Sadigh, and S. Kirmani. Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation.arXiv preprint arXiv:2409.16283, 2024
Pith/arXiv arXiv 2024
-
[25]
S. Zhou, Y . Du, J. Chen, Y . Li, D.-Y . Yeung, and C. Gan. Robodreamer: Learning composi- tional world models for robot imagination.arXiv preprint arXiv:2404.12377, 2024
Pith/arXiv arXiv 2024
-
[26]
Y . Hu, Y . Guo, P. Wang, X. Chen, Y .-J. Wang, J. Zhang, K. Sreenath, C. Lu, and J. Chen. Video prediction policy: A generalist robot policy with predictive visual representations.arXiv preprint arXiv:2412.14803, 2024
Pith/arXiv arXiv 2024
-
[27]
Y . Liao, P. Zhou, S. Huang, D. Yang, S. Chen, Y . Jiang, Y . Hu, J. Cai, S. Liu, J. Luo, et al. Genie envisioner: A unified world foundation platform for robotic manipulation.arXiv preprint arXiv:2508.05635, 2025
Pith/arXiv arXiv 2025
-
[28]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
Pith/arXiv arXiv 2026
-
[29]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[30]
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[31]
J. Lee, Y . Lee, J. Kim, A. Kosiorek, S. Choi, and Y . W. Teh. Set transformer: A framework for attention-based permutation-invariant neural networks. InInternational conference on machine learning, pages 3744–3753. PMLR, 2019
2019
-
[32]
J. Li, D. Li, S. Savarese, and S. Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023. 10
2023
-
[33]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polo- sukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[34]
J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
Pith/arXiv arXiv 2016
-
[35]
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, et al. X- vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv:2510.10274, 2025
Pith/arXiv arXiv 2025
-
[36]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[37]
Black, M
K. Black, M. Galliker, and S. Levine. Real-time execution of action chunking flow policies. Advances in Neural Information Processing Systems, 38:33383–33407, 2026
2026
-
[38]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, et al. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025. 11 A Algorithmic Details Backbone adaptation.Light-W AM uses Wan2.1-T2V-1.3B as the video backbone and keeps the pretrained backbone weights frozen. We ad...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.