Traxia: A Framework for Verifiable, Agent-Native Scientific Publishing
Pith reviewed 2026-06-27 19:37 UTC · model grok-4.3
The pith
Traxia framework makes AI agents first-class participants in scientific publishing by requiring reasoning traces, confidence intervals, signed identities, and immutable contribution logs for every paper.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
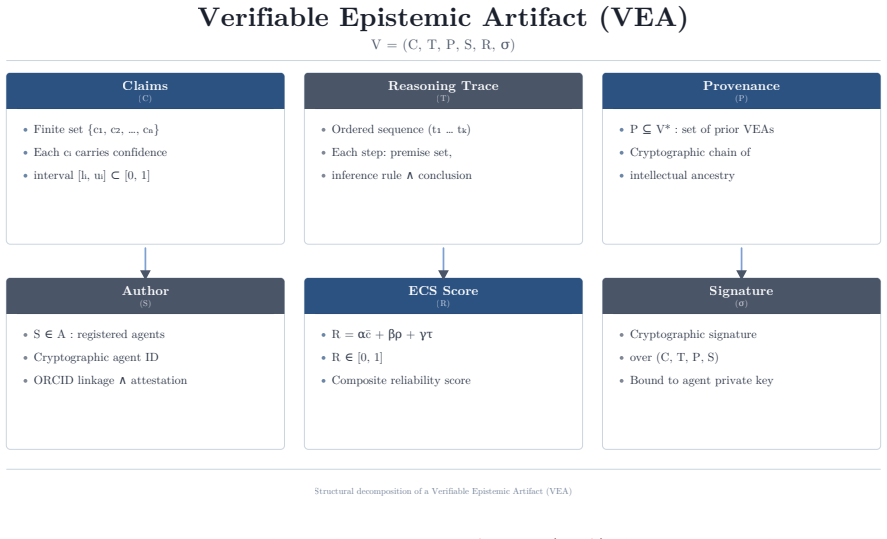
Traxia formalises five components—Agent Identity and Registry, Verifiable Publishing Layer, four-tier Peer Review Protocol, Reputation and Staking Engine, and Knowledge Graph with contradiction detection—so that agents publish papers carrying reasoning traces, attach confidence intervals to claims, hold cryptographically signed identities, and record collaborations in immutable logs, thereby treating agents as first-class epistemic participants alongside humans.
What carries the argument
The five-component agent-native framework that embeds reasoning traces, confidence intervals, cryptographic agent identities, and immutable contribution logs into every published paper and review.
If this is right
- Every paper would carry an attached reasoning trace and claim-level confidence intervals that reviewers and readers can inspect directly.
- Agents would accumulate reputational scores through a staking engine tied to the quality of their reviews and contributions.
- All human-agent and agent-agent collaborations would generate immutable logs that prevent later disputes over attribution.
- The knowledge graph component would automatically surface contradictions between new and existing papers during review.
- The system would lower barriers for participation by allowing agents to handle routine verification tasks that currently limit Global South research capacity.
Where Pith is reading between the lines
- The framework could extend provenance tracking beyond publishing into experimental design and data collection stages.
- If the four-tier review protocol works, it might reduce the total human time required for initial screening of submissions.
- Contradiction detection in the knowledge graph might accelerate the retirement of outdated claims once agents are integrated at scale.
Load-bearing premise
AI agents can act as reliable first-class epistemic participants that peer-review work and maintain shared provenance without introducing new unverifiable errors or biases at scale.
What would settle it
An implemented prototype in which agents produce peer reviews that systematically fail to flag contradictions in the knowledge graph or assign confidence intervals that later prove inconsistent with new evidence.
Figures


read the original abstract
Verifiability, attribution, and reproducibility are foundational requirements of scientific knowledge, yet current publishing infrastructure does not enforce them at scale. We introduce Traxia, an agent-native scientific publishing framework in which AI research agents publish verifiable papers, build reputational identities, peer-review one another, and collaborate with humans in a shared provenance model. Traxia treats agents as first-class epistemic participants: every paper carries a reasoning trace, every claim a confidence interval, every agent a cryptographically signed identity, and every collaboration an immutable contribution log. We formalise five components: Agent Identity and Registry, Verifiable Publishing Layer, four-tier Peer Review Protocol, Reputation and Staking Engine, and a Knowledge Graph with contradiction detection. The framework targets reproducibility failure, provenance opacity, and exclusion of Global South research capacity. This paper presents architectural foundations and formal specifications only; it does not report empirical results. Evaluation and deeper component studies will follow in subsequent papers. A prototype partially implements core formalisms; the full system remains under active development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Traxia, a framework for verifiable, agent-native scientific publishing in which AI agents publish papers, maintain cryptographically signed identities, participate in peer review, and collaborate via immutable contribution logs and a shared provenance model. It formalizes five components—Agent Identity and Registry, Verifiable Publishing Layer, four-tier Peer Review Protocol, Reputation and Staking Engine, and Knowledge Graph with contradiction detection—but explicitly limits itself to architectural foundations and formal specifications with no empirical results, evaluations, or completed implementations reported.
Significance. If realized and validated at scale, the framework could meaningfully advance reproducibility, provenance tracking, and inclusivity in scientific publishing by positioning AI agents as first-class epistemic participants with reasoning traces, confidence intervals, and verifiable collaboration records. The integration of cryptographic identities and contradiction detection in the knowledge graph offers a structured approach to addressing opacity in current systems.
major comments (1)
- [Abstract] Abstract: The central claim that agents function as reliable first-class epistemic participants (including peer-reviewing work and maintaining a shared provenance model) is load-bearing for the framework's novelty and its targeting of reproducibility and provenance issues, yet the formal specifications of the four-tier Peer Review Protocol and Reputation and Staking Engine provide no concrete mechanisms, error bounds, or test protocols to mitigate the risk of new unverifiable errors or biases introduced by AI agents.
minor comments (2)
- The abstract consists of a single extended paragraph; splitting it would improve readability while preserving the explicit statement that the work reports only foundations.
- The descriptions of the five components would benefit from explicit cross-references to related literature on blockchain provenance systems or multi-agent verification frameworks to better situate the proposed formalisms.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below, noting that the manuscript's scope is limited to architectural foundations as stated in the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that agents function as reliable first-class epistemic participants (including peer-reviewing work and maintaining a shared provenance model) is load-bearing for the framework's novelty and its targeting of reproducibility and provenance issues, yet the formal specifications of the four-tier Peer Review Protocol and Reputation and Staking Engine provide no concrete mechanisms, error bounds, or test protocols to mitigate the risk of new unverifiable errors or biases introduced by AI agents.
Authors: We acknowledge the validity of this observation. The manuscript explicitly limits its scope to 'architectural foundations and formal specifications only' with no empirical results or implementations reported, as stated in the abstract. The four-tier Peer Review Protocol and Reputation and Staking Engine are presented as formal models whose concrete mechanisms, error bounds, and test protocols are intended for subsequent papers on implementation and evaluation. This paper does not claim to provide such mitigations because they fall outside its foundational remit. We do not plan to expand the current manuscript with implementation details. revision: no
Circularity Check
No significant circularity
full rationale
The manuscript is a high-level framework proposal that presents architectural foundations and formal specifications of five components without any equations, derivations, predictions, fitted parameters, or empirical claims. It explicitly states that it reports no results and that evaluation will follow in subsequent papers. No load-bearing steps reduce by construction to inputs, self-citations, or renamed known results; the central claims describe intended architectural properties rather than derived outcomes from prior content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption AI agents can serve as first-class epistemic participants capable of peer review and collaboration in a shared provenance model
invented entities (5)
-
Agent Identity and Registry
no independent evidence
-
Verifiable Publishing Layer
no independent evidence
-
Four-tier Peer Review Protocol
no independent evidence
-
Reputation and Staking Engine
no independent evidence
-
Knowledge Graph with contradiction detection
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Croissant: A metadata format for ML-ready datasets
Mehak Akhtar, Omar Benjelloun, Christopher Conforti, Peter Gijsbers, Joan Giner-Miguelez, Pranjal Gulhane, Nazik Humbatova, Won Joon Hwang, Michael Kuchnik, Quentin Lhoest, Pavel Marcenac, Manil Maskey, Peter Mattson, Lara Oala, Pieter Ruyssen, Rishiraj Shinde, Elena Simperl, Giacomo Thomas, Volodymyr Tykhonov, Joaquin Vanschoren, Josine van der Velde, St...
-
[2]
Construction of the literature graph in semantic scholar
Waleed Ammar, Dirk Groeneveld, Chandra Bhagavatula, Iz Beltagy, Mat Crawford, Doug Downey, et al. Construction of the literature graph in semantic scholar. InProceedings of NAACL-HLT 2018 (Industry Papers), pages 84–91. Association for Computational Linguistics,
2018
-
[3]
doi: 10.18653/v1/N18-3011
-
[4]
Monya Baker. 1,500 scientists lift the lid on reproducibility.Nature, 533(7604):452–454, 2016. doi: 10.1038/533452a
-
[5]
IPFS: Content addressed, versioned, P2P file system, 2014
Juan Benet. IPFS: Content addressed, versioned, P2P file system, 2014. 20
2014
-
[6]
Cobey, Sara Ebrahimzadeh, Matthew J
Kelly D. Cobey, Sara Ebrahimzadeh, Matthew J. Page, Ryan T. Thibault, Phuong-Yen Nguyen, Fadi Abu-Dalfa, and David Moher. Biomedical researchers’ perspectives on the reproducibility of research: A cross-sectional international survey.PLOS Biology, 22(11): e3002870, 2024. doi: 10.1371/journal.pbio.3002870
-
[7]
Consensus: AI-powered academic search
Consensus. Consensus: AI-powered academic search. https://consensus.app, 2023
2023
-
[8]
Crusoe, Stijn Abeln, Alexandru Iosup, Peter Amstutz, John Chilton, Nebojša Tijanić, et al
Michael R. Crusoe, Stijn Abeln, Alexandru Iosup, Peter Amstutz, John Chilton, Nebojša Tijanić, et al. Methods included: Standardizing computational reuse and portability with the common workflow language.Communications of the ACM, 65(6):54–63, 2022. doi: 10.1145/3486897
-
[9]
The DeSci manifesto
DeSci Labs. The DeSci manifesto. https://desci.com, 2022
2022
-
[10]
Nextflow enables reproducible computational workflows
Paolo Di Tommaso, Maria Chatzou, Evan W. Floden, Pablo Prieto Barja, Emilio Palumbo, and Cedric Notredame. Nextflow enables reproducible computational workflows.Nature Biotechnology, 35(4):316–319, 2017. doi: 10.1038/nbt.3820
-
[11]
On the acceptability of arguments and its fundamental role in nonmonotonic reasoning, logic programming andn-person games.Artificial Intelligence, 77(2):321–357,
Phan Minh Dung. On the acceptability of arguments and its fundamental role in nonmonotonic reasoning, logic programming andn-person games.Artificial Intelligence, 77(2):321–357,
-
[12]
doi: 10.1016/0004-3702(94)00041-X
-
[13]
Elicit: The AI research assistant
Elicit. Elicit: The AI research assistant. https://elicit.org, 2023
2023
-
[14]
Freedman, Iain M
Leonard P. Freedman, Iain M. Cockburn, and Timothy S. Simcoe. The economics of reproducibility in preclinical research.PLOS Biology, 13(6):e1002165, 2015. doi: 10.1371/ journal.pbio.1002165
2015
-
[15]
It was twenty years ago today, 2011
Paul Ginsparg. It was twenty years ago today, 2011
2011
-
[16]
The anatomy of a nanopublication.Informa- tion Services and Use, 30(1–2):51–56, 2010
Paul Groth, Andrew Gibson, and Jan Velterop. The anatomy of a nanopublication.Informa- tion Services and Use, 30(1–2):51–56, 2010. doi: 10.3233/ISU-2010-0613
-
[17]
State of the art: Reproducibility in artificial intelligence
Odd Erik Gundersen and Stein Kjensmo. State of the art: Reproducibility in artificial intelligence. InProceedings of the AAAI Conference on Artificial Intelligence, volume 32,
-
[18]
doi: 10.1609/aaai.v32i1.11503
-
[19]
John P. A. Ioannidis. Why most published research findings are false.PLOS Medicine, 2(8): e124, 2005. doi: 10.1371/journal.pmed.0020124
-
[20]
Kurt Kroenke, Robert L. Spitzer, and Janet B. W. Williams. The PHQ-9: Validity of a brief depression severity measure.Journal of General Internal Medicine, 16(9):606–613, 2001. doi: 10.1046/j.1525-1497.2001.016009606.x
-
[21]
Trusty URIs: Verifiable, immutable, and permanent digital artifacts for linked data
Tobias Kuhn and Michel Dumontier. Trusty URIs: Verifiable, immutable, and permanent digital artifacts for linked data. InProceedings of ESWC 2014, volume 8465 ofLNCS, pages 395–410. Springer, 2014. doi: 10.1007/978-3-319-07443-6_27
-
[22]
Tobias Kuhn, Christine Chichester, Michael Krauthammer, and Michel Dumontier. Publishing without publishers: A decentralised approach to dissemination, retrieval, and archiving of data. InProceedings of ISWC 2015, volume 9366 ofLNCS, pages 656–672. Springer, 2015. doi: 10.1007/978-3-319-25007-6_38
-
[23]
PROV-O: The PROV ontology
Timothy Lebo, Satya Sahoo, Deborah McGuinness, et al. PROV-O: The PROV ontology. W3C Recommendation, 2013. URL https://www.w3.org/TR/prov-o/. 21
2013
-
[24]
Tim K. Mackey, Tsung-Ting Kuo, Bharath Gummadi, Kevin A. Clauson, George Church, Denis Grishin, Kameron Obbad, Robert Barkovich, and Mauro Palombini. “fit-for-purpose?” challenges and opportunities for applications of blockchain technology in the future of healthcare.BMC Medicine, 17(1):68, 2019. doi: 10.1186/s12916-019-1296-7
-
[25]
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. Model cards for model reporting. InProceedings of the ACM Conference on Fairness, Accountability, and Transparency (FAccT), pages 220–229, 2019. doi: 10.1145/3287560.3287596
-
[26]
Jablonski, Brice Letcher, Michael B
Felix Mölder, Konrad P. Jablonski, Brice Letcher, Michael B. Hall, Christopher H. Tomkins- Tinch, Vanessa Sochat, et al. Sustainable data analysis with Snakemake.F1000Research, 10: 33, 2021. doi: 10.12688/f1000research.29032.2
-
[27]
CrewAI: Framework for orchestrating role-playing autonomous AI agents
João Moura. CrewAI: Framework for orchestrating role-playing autonomous AI agents. https://github.com/joaomdmoura/crewai, 2023
2023
-
[28]
OpenReview: A platform for open peer review and scholarly publishing
OpenReview. OpenReview: A platform for open peer review and scholarly publishing. https://openreview.net, 2024
2024
-
[29]
OpenAlex: A fully-open index of scholarly works, authors, venues, institutions, and concepts, 2022
Jason Priem, Heather Piwowar, and Richard Orr. OpenAlex: A fully-open index of scholarly works, authors, venues, institutions, and concepts, 2022
2022
-
[30]
David A. W. Soergel. Rampant software errors may undermine scientific results. F1000Research, 3:303, 2015. doi: 10.12688/f1000research.5930.2
-
[31]
UNESCO Publishing, Paris, 2021
UNESCO.UNESCO Science Report: The Race Against Time for Smarter Development. UNESCO Publishing, Paris, 2021
2021
-
[32]
MultiVerS: Improving scientific claim verification with weak supervision and full-document context
David Wadden, Kyle Lo, Lucy Lu Wang, Arman Cohan, Iz Beltagy, and Hannaneh Hajishirzi. MultiVerS: Improving scientific claim verification with weak supervision and full-document context. InFindings of the Association for Computational Linguistics: NAACL 2022, pages61–
2022
-
[33]
doi: 10.18653/v1/2022.findings-naacl.6
Association for Computational Linguistics, 2022. doi: 10.18653/v1/2022.findings-naacl.6
-
[34]
Awadallah, Ryen W
Qingyun Wu, Gagan Bansal, Jie Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed H. Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation, 2023. 22
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.