Distilling LLM Reasoning into an Interpretable Policy Tree for Human-AI Collaboration
Pith reviewed 2026-06-27 18:49 UTC · model grok-4.3
The pith
Co-pi-tree distills LLM reasoning into an executable policy tree refined by natural-language interaction feedback for more efficient human-AI collaboration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
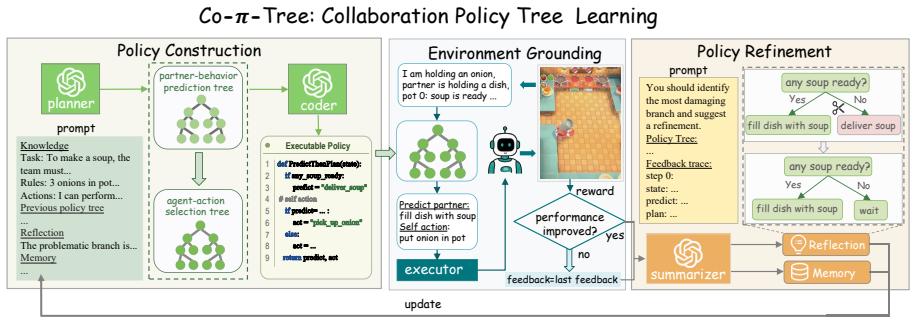
Co-pi-tree constructs an executable policy by first distilling LLM reasoning into code that defines a partner-behavior prediction tree and an agent-action selection tree; the policy is then run in interaction with a human partner, after which natural-language summaries of the observed feedback are used to locate and rewrite problematic branches, yielding a closed-loop improvement process that requires no further LLM queries at execution time.
What carries the argument
Collaboration Policy Tree (Co-pi-tree), an executable structure containing a partner-behavior prediction tree and an agent-action selection tree that is initially distilled from LLM reasoning and subsequently edited via natural-language summaries of interaction feedback.
If this is right
- Once distilled, the policy tree executes without any LLM calls, directly cutting latency and cost at deployment.
- Because the tree is explicit code, a human can inspect or manually edit any branch rather than retraining an opaque model.
- The same distillation-plus-refinement loop can be applied to any multi-agent task where partner behavior is partially predictable from language descriptions.
- Fewer LLM queries during testing translate into lower monetary cost and lower carbon cost per collaboration episode.
Where Pith is reading between the lines
- The approach may generalize to domains outside games if the partner-behavior tree can be seeded with domain-specific language descriptions of typical human actions.
- If the refinement loop succeeds, it offers a practical route to keeping LLM-level reasoning inside a system that must run on low-power edge hardware.
- The separation into prediction and action trees suggests a natural place to insert human overrides: a supervisor could edit only the action tree while leaving the learned partner model untouched.
Load-bearing premise
Natural language summaries of interaction feedback can reliably locate and correct the specific branches that are causing poor performance without introducing new errors.
What would settle it
A controlled trial in Overcooked-AI in which the natural-language refinement step is applied to the distilled tree yet average reward does not rise or LLM-query count does not fall relative to the unrefined tree.
Figures



read the original abstract
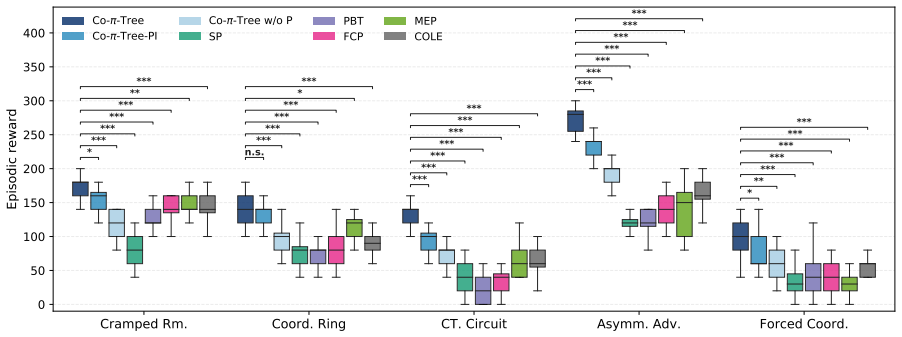
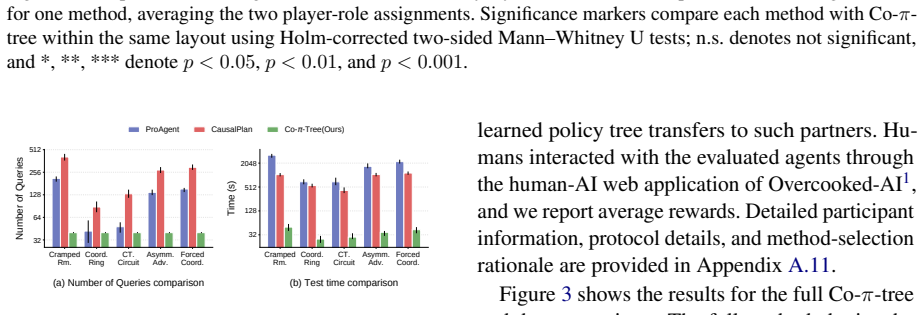
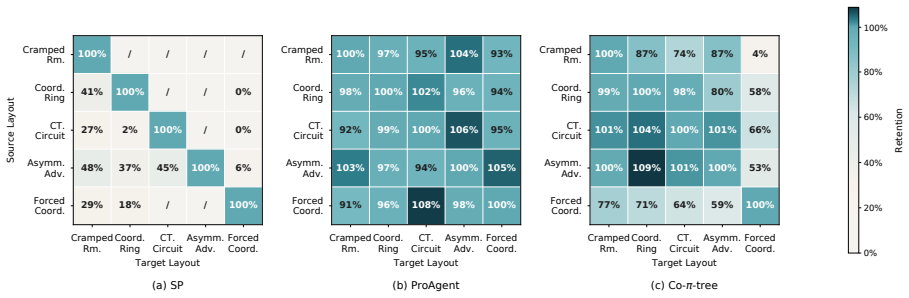
Constructing efficient and reliable policies to assist humans is indispensable for human-AI collaboration. Existing methods mainly follow two lines of work. Most prior work relies on multi-agent reinforcement learning (MARL) to learn black-box policies, which limits interpretability and raises safety concerns. Recent methods query large language models (LLMs) at each decision step, causing slow responses and high inference costs. We propose Collaboration Policy Tree (Co-pi-tree), a closed-loop method that learns an executable policy tree consisting of a partner-behavior prediction tree and an agent-action selection tree. Co-pi-tree constructs a policy by distilling LLM reasoning into policy tree code. It then evaluates the policy through partner interaction, obtains feedback, and uses natural language to summarize the interaction feedback to improve problematic branches. Experiments in Overcooked-AI show that Co-pi-tree improves average reward by 35.4% over the baseline average, while reducing the number of LLM queries by 77.7% and test-time latency by 97.1%. Project page: https://beiwenzhang.github.io/Co-pi-tree/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Co-pi-tree, a closed-loop method that distills LLM reasoning into an executable policy tree consisting of a partner-behavior prediction tree and an agent-action selection tree for human-AI collaboration tasks. The approach constructs the tree via distillation, then uses interaction feedback summarized in natural language to identify and correct problematic branches. Experiments in Overcooked-AI are reported to yield a 35.4% improvement in average reward over baseline, along with 77.7% fewer LLM queries and 97.1% lower test-time latency.
Significance. If the quantitative claims hold under rigorous controls, the work would offer a meaningful contribution by producing interpretable policies that combine the reasoning capacity of LLMs with execution efficiency and feedback-driven refinement, addressing limitations of both black-box MARL and per-step LLM querying in collaborative settings.
major comments (3)
- The abstract and method description provide no ablation isolating the closed-loop natural-language feedback correction step from the initial distillation; without this, the reported 35.4% reward gain, 77.7% query reduction, and 97.1% latency reduction cannot be attributed to the claimed refinement mechanism rather than the base tree alone.
- No mechanism details, error analysis, or consistency checks are supplied for how natural-language summaries of interaction feedback map to specific branch edits in the policy tree, leaving open the possibility that the summarization step introduces new errors or fails to target the branches responsible for measured gains.
- The experimental claims reference Overcooked-AI results but supply no protocol details, baseline definitions, statistical tests, variance measures, or controls in the provided text, rendering the quantitative improvements unverifiable as support for the central claims.
minor comments (1)
- The project page link is mentioned but no supplementary material or code repository is referenced to support reproducibility of the policy tree construction and feedback loop.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that strengthen the manuscript without misrepresenting the current content.
read point-by-point responses
-
Referee: The abstract and method description provide no ablation isolating the closed-loop natural-language feedback correction step from the initial distillation; without this, the reported 35.4% reward gain, 77.7% query reduction, and 97.1% latency reduction cannot be attributed to the claimed refinement mechanism rather than the base tree alone.
Authors: We agree that the current manuscript lacks an explicit ablation isolating the closed-loop feedback correction. The reported gains are for the full Co-pi-tree system, but without this comparison the attribution remains unclear. In revision we will add an ablation study comparing the initial distilled tree to the feedback-refined version on the same Overcooked-AI tasks. revision: yes
-
Referee: No mechanism details, error analysis, or consistency checks are supplied for how natural-language summaries of interaction feedback map to specific branch edits in the policy tree, leaving open the possibility that the summarization step introduces new errors or fails to target the branches responsible for measured gains.
Authors: The manuscript describes the high-level closed-loop process but does not supply the requested low-level mechanism, error analysis, or consistency checks. We will expand the method section with concrete examples of how natural-language feedback summaries are parsed into branch edits, including any safeguards or post-edit validation steps used. revision: yes
-
Referee: The experimental claims reference Overcooked-AI results but supply no protocol details, baseline definitions, statistical tests, variance measures, or controls in the provided text, rendering the quantitative improvements unverifiable as support for the central claims.
Authors: The referee is correct that the text excerpt lacks these details. While the full manuscript contains an experimental section, we will revise to include explicit protocol descriptions, baseline definitions, statistical tests, variance reporting, and control conditions so that the quantitative results can be independently verified. revision: yes
Circularity Check
No circularity: empirical method with no derivations or fitted predictions
full rationale
The paper describes an engineering pipeline (distill LLM reasoning into executable policy tree code, interact to collect feedback, summarize feedback in natural language to edit branches) and reports experimental gains on Overcooked-AI. No equations, parameters fitted to subsets then re-predicted, self-definitional constructs, or load-bearing self-citations appear in the provided text. The central claims rest on measured interaction outcomes rather than any reduction of a result to its own inputs by construction. The method is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LongLLMLingua: Accelerating and enhancing LLMs in long context scenarios via prompt compres- sion. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pages 1658–1677, Bangkok, Thailand. Association for Computational Linguistics. Yang Li, Shao Zhang, Jichen Sun, Yali Du, Ying Wen, Xinbing Wa...
-
[2]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Process- ing: Industry Track, pages 472–491, Suzhou, China
SLOT: Structuring the output of large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Process- ing: Industry Track, pages 472–491, Suzhou, China. Association for Computational Linguistics. Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Re- flexion: Language agents wit...
2025
-
[3]
InAdvances in Neural Information Processing Systems
Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems. Yang Xiao, Jiashuo Wang, Ruifeng Yuan, Chunpu Xu, Kaishuai Xu, Wenjie Li, and Pengfei Liu. 2025. LIMOPro: Reasoning refinement for efficient and effective test-time scaling. InAdvances in Neural Information Processing Systems, volume...
-
[4]
InAdvances in Neural Information Processing Systems
Self-discover: Large language models self- compose reasoning structures. InAdvances in Neural Information Processing Systems. 10 A Additional Details A.1 Layout Descriptions We evaluate Co- π-tree on five standard Overcooked-AI layouts, which cover differ- ent coordination bottlenecks. Cramped Room is a compact kitchen with one pot and one serving locatio...
2026
-
[5]
The inferred current action of <TEAMMATE_PLAYER>, and
-
[6]
<one legal action>
Exactly one legal action for <SELF_PLAYER> now. Required output format: ### FunctionDescription: Name: PredictTeammateThenPlan Inputs: - current_scene: - holdings: {self: empty/onion/dish/soup, teammate: empty/onion/dish/soup} - pots: for each <Pot>: onion_count: {0,1,2,3}, state: {idle,cooking,ready}, timers - derived flags: any_soup_ready, any_pot_not_f...
-
[7]
Causes clear throughput loss across multiple scenes, not just one isolated mistake,
-
[8]
Appears as repeated wasted timesteps, redundant role overlap, premature dish handling, delayed role switching, or legal-but-low-value actions,
-
[9]
PRIORITIZATION RULE: - Prefer a bottleneck that repeatedly reduces soup throughput, even if all actions are technically legal
Can still be attributed to ONE specific branch, priority rule, or missing condition in the decision tree. PRIORITIZATION RULE: - Prefer a bottleneck that repeatedly reduces soup throughput, even if all actions are technically legal. - Do NOT over-prioritize teammate prediction mistakes unless they clearly create repeated downstream time loss. - A valid-bu...
-
[10]
Scan all episode states and identify time-wasting behaviors
-
[11]
Select exactly ONE primary inefficiency with the largest negative impact on efficiency or score
-
[12]
Identify the EXACT target branch or decision condition to modify
-
[13]
Generate a Tree_Reflexion that guides a planner to perform a SINGLE, LOCAL modification: - describe the CURRENT behavior of this branch (BEFORE), - describe the DESIRED behavior after modification (AFTER), using refined conditions, priority changes, or a single added guard condition, - explicitly list assumptions about what logic MUST remain unchanged
-
[14]
Decision_Tree_Summary
The value in Decision_Tree_Summary.Final_Score MUST be exactly <S_k>. OUTPUT REQUIREMENTS: - Output MUST be valid JSON. - Do NOT include markdown, explanations, or extra text. - Be concrete and implementable. - Output must directly contain only these top-level keys: - "Decision_Tree_Summary" - "Tree_Reflexion" Return JSON in the following format: { "Decis...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.