InA-Probe: Instruction-Aware Active Probing for Time Series Forecasting with LLMs
Pith reviewed 2026-06-27 18:47 UTC · model grok-4.3
The pith
InA-Probe lets LLMs forecast time series by actively generating instruction-modulated probes instead of relying on passive alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
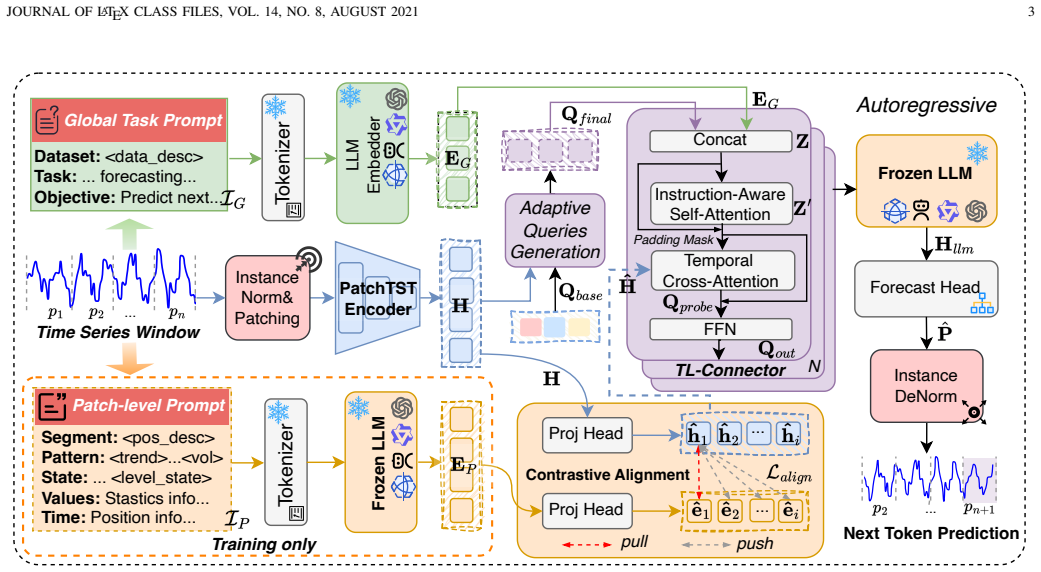
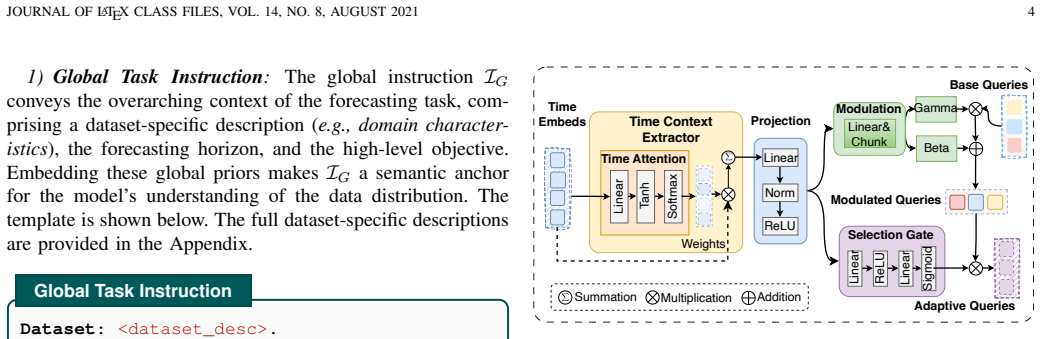
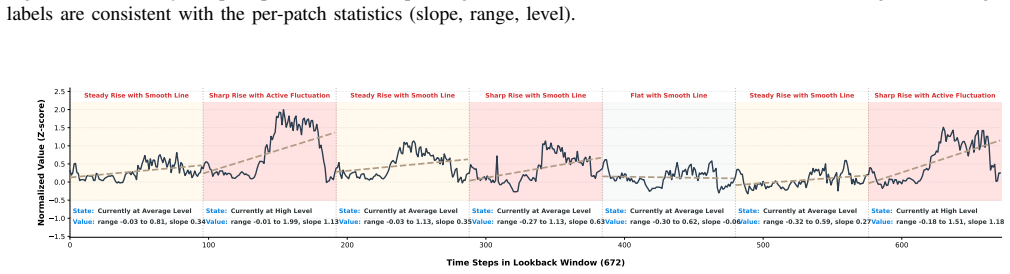
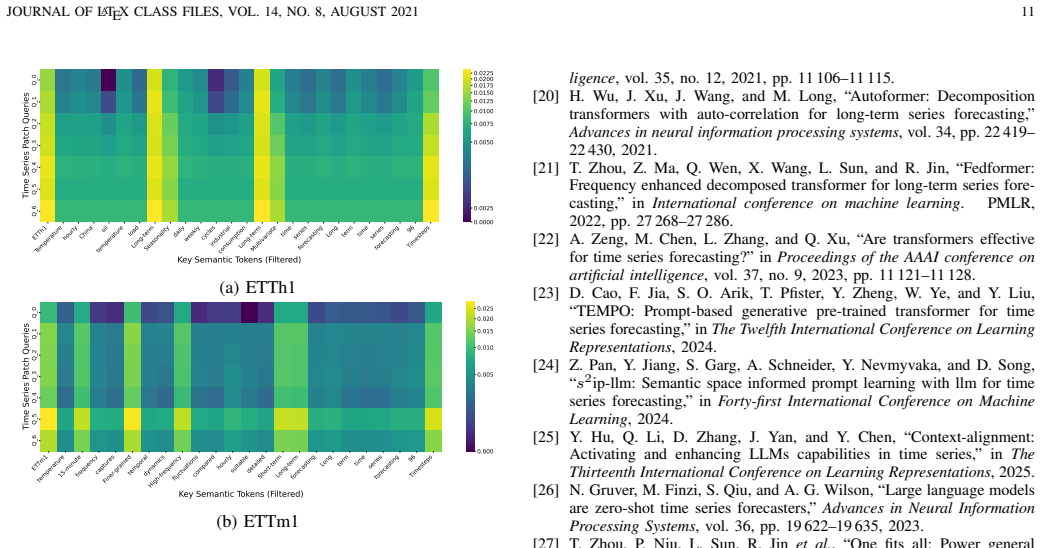
InA-Probe shifts from passive alignment to an active, instruction-driven probing mechanism. A Multi-Level Instruction Injection enriches the model with global task objectives and fine-grained patch-level semantic priors. An Adaptive Query Generation module then produces sample-specific probes dynamically modulated by temporal context. These probes undergo Instruction-Aware Self-Attention to internalize task intents and Temporal Cross-Attention to interrogate projected temporal representations, extracting salient patterns and enabling superior one-for-all generalization and zero-shot transfer.
What carries the argument
Multi-Level Instruction Injection paired with Adaptive Query Generation, refined through Instruction-Aware Self-Attention and Temporal Cross-Attention, which together produce dynamic, context- and intent-modulated probes of temporal data.
If this is right
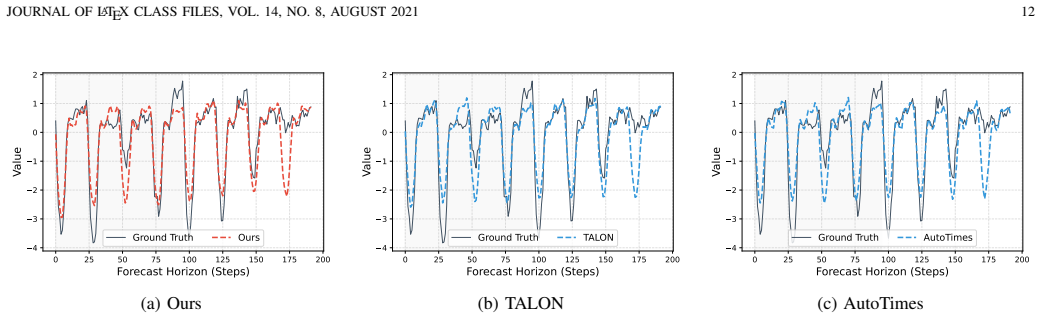
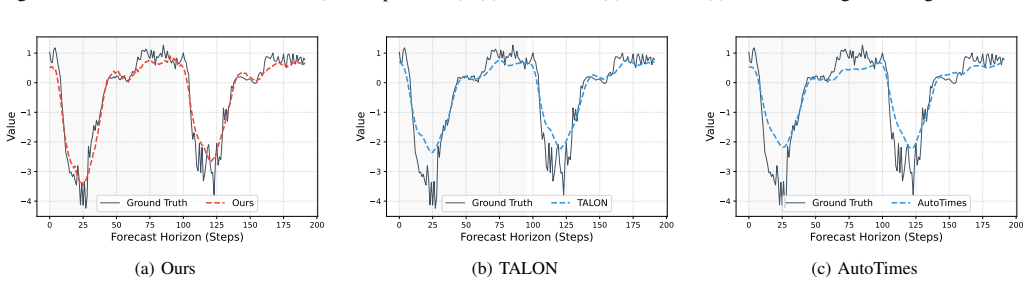
- InA-Probe outperforms state-of-the-art deep learning and LLM-based baselines on seven real-world benchmarks.
- It excels in both one-for-all generalization and zero-shot transfer settings.
- Forecasting error drops by up to 37 percent in challenging cross-domain scenarios.
- The combination of adaptive querying and fine-grained instructions unlocks LLM reasoning for complex time series tasks.
Where Pith is reading between the lines
- The active probing design could extend to other sequential data domains where task intent varies, such as multivariate sensor streams or event sequences.
- Testing the same modules on larger or differently pretrained language models would reveal whether the gains scale with model capacity.
- The emphasis on explicit instruction modulation suggests a general strategy for making LLMs more controllable in specialized prediction tasks without full fine-tuning.
Load-bearing premise
The performance gains come from the synergy of multi-level instruction injection and adaptive query generation rather than from unstated differences in architecture, training, or benchmark choices.
What would settle it
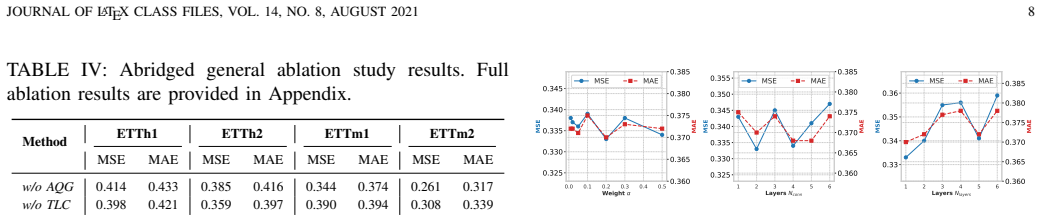
Ablation experiments on the same seven benchmarks that disable the multi-level injection and adaptive query modules and measure whether the error reduction and generalization advantages disappear.
Figures





read the original abstract
Large Language Models (LLMs) have recently demonstrated impressive potential for time series forecasting. However, existing methods predominantly rely on passive modality alignment or static task reprogramming, which often fail to capture fine-grained, non-stationary temporal patterns or to adapt to nuanced task intents. In this paper, we propose Instruction-aware Active Probing (InA-Probe), which shifts the paradigm from passive alignment toward an active, instruction-driven probing mechanism. Specifically, we design a Multi-Level Instruction Injection mechanism that enriches the model with both global task objectives and fine-grained, patch-level semantic priors. Building on this, an Adaptive Query Generation module produces sample-specific probes that are dynamically modulated by the temporal context. These probes are then refined through a dual-stage attention process: they first internalize task-specific intents via Instruction-Aware Self-Attention, and subsequently interrogate the projected temporal representations through Temporal Cross-Attention to extract salient patterns. Comprehensive experiments on seven real-world benchmarks show that InA-Probe consistently outperforms state-of-the-art deep learning and LLM-based baselines, excelling in both one-for-all generalization and zero-shot transfer while reducing forecasting error by up to 37\% in challenging cross-domain scenarios. Ablation studies further confirm that the synergy between adaptive querying and fine-grained instructions is key to unlocking the reasoning power of LLMs for complex time series.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Instruction-aware Active Probing (InA-Probe) for LLM-based time series forecasting. It introduces a Multi-Level Instruction Injection mechanism to supply global task objectives and patch-level semantic priors, paired with an Adaptive Query Generation module that creates sample-specific probes refined via Instruction-Aware Self-Attention followed by Temporal Cross-Attention. The central claim is that this active, instruction-driven approach outperforms state-of-the-art deep learning and LLM baselines on seven real-world benchmarks in both one-for-all and zero-shot settings, with up to 37% error reduction in cross-domain cases; ablations are said to confirm that the synergy of adaptive querying and fine-grained instructions is responsible.
Significance. If the reported gains prove robust under controlled conditions, the shift from passive alignment to active instruction-driven probing could meaningfully improve LLM applicability to non-stationary time series tasks and enhance generalization.
major comments (2)
- [Abstract] Abstract: the claim of consistent outperformance and up to 37% error reduction is load-bearing for the paper's contribution, yet the text provides no information on experimental controls, statistical significance testing, data splits, or potential confounds such as benchmark selection or training procedures.
- [Abstract] Abstract: the attribution of gains specifically to the synergy between Multi-Level Instruction Injection and Adaptive Query Generation (rather than other architectural or procedural factors) cannot be evaluated, as no ablation results, baseline variants, or quantitative breakdowns are described.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the abstract regarding experimental details and component contributions. We agree that the abstract, as currently written, is too high-level on these points. We will revise the abstract in the next version to briefly incorporate key experimental context and explicit references to ablation evidence, while preserving conciseness. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of consistent outperformance and up to 37% error reduction is load-bearing for the paper's contribution, yet the text provides no information on experimental controls, statistical significance testing, data splits, or potential confounds such as benchmark selection or training procedures.
Authors: The referee is correct that the abstract omits these specifics. The full manuscript details the seven benchmarks, one-for-all and zero-shot protocols, data splits, training procedures, and statistical significance testing in the Experiments section. To address the concern directly, we will revise the abstract to include a concise statement on the evaluation settings (seven real-world benchmarks, both one-for-all and zero-shot) and note that results include statistical controls. revision: yes
-
Referee: [Abstract] Abstract: the attribution of gains specifically to the synergy between Multi-Level Instruction Injection and Adaptive Query Generation (rather than other architectural or procedural factors) cannot be evaluated, as no ablation results, baseline variants, or quantitative breakdowns are described.
Authors: We agree the abstract does not supply quantitative ablation numbers or breakdowns. The manuscript already states that ablation studies confirm the synergy, with results and baseline variants reported in the dedicated ablation subsection. We will revise the abstract to more explicitly tie the reported gains to the ablation evidence supporting the two core modules. revision: yes
Circularity Check
No significant circularity detected
full rationale
The manuscript describes an architectural proposal (Multi-Level Instruction Injection, Adaptive Query Generation, dual-stage attention) and reports empirical benchmark results. No equations, derivations, fitted parameters presented as independent predictions, or self-citation chains appear in the supplied text. The central claims rest on experimental comparisons rather than any first-principles reduction that could be circular by construction. This is the expected outcome for an empirical methods paper without a mathematical derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep learning for time series forecasting: The electric load case,
A. Gasparin, S. Lukovic, and C. Alippi, “Deep learning for time series forecasting: The electric load case,”CAAI Transactions on Intelligence Technology, vol. 7, no. 1, pp. 1–25, 2022
2022
-
[2]
Bidirectional spatial-temporal adaptive transformer for urban traffic flow forecasting,
C. Chen, Y . Liu, L. Chen, and C. Zhang, “Bidirectional spatial-temporal adaptive transformer for urban traffic flow forecasting,”IEEE Transac- tions on Neural Networks and Learning Systems, vol. 34, no. 10, pp. 6913–6925, 2022
2022
-
[3]
itrans- former: Inverted transformers are effective for time series forecasting,
Y . Liu, T. Hu, H. Zhang, H. Wu, S. Wang, L. Ma, and M. Long, “itrans- former: Inverted transformers are effective for time series forecasting,” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024, 2024
2024
-
[4]
A time series is worth 64 words: Long-term forecasting with transformers,
Y . Nie, N. H. Nguyen, P. Sinthong, and J. Kalagnanam, “A time series is worth 64 words: Long-term forecasting with transformers,” inThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023, 2023
2023
-
[5]
Timesnet: Temporal 2d-variation modeling for general time series analysis,
H. Wu, T. Hu, Y . Liu, H. Zhou, J. Wang, and M. Long, “Timesnet: Temporal 2d-variation modeling for general time series analysis,” inThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023, 2023
2023
-
[6]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskeveret al., “Language models are unsupervised multitask learners,”OpenAI blog, vol. 1, no. 8, p. 9, 2019
2019
-
[7]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Time-llm: Time series forecasting by reprogramming large language models,
M. Jin, S. Wang, L. Ma, Z. Chu, J. Y . Zhang, X. Shi, P. Chen, Y . Liang, Y . Li, S. Pan, and Q. Wen, “Time-llm: Time series forecasting by reprogramming large language models,” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024, 2024
2024
-
[9]
Autotimes: Autore- gressive time series forecasters via large language models,
Y . Liu, G. Qin, X. Huang, J. Wang, and M. Long, “Autotimes: Autore- gressive time series forecasters via large language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 122 154–122 184, 2024
2024
-
[10]
Y . Sun, E. Eldele, Z. Xie, Y . Wang, W. Niu, Q. Hu, C. K. Kwoh, and M. Wu, “Adapting llms to time series forecasting via tempo- ral heterogeneity modeling and semantic alignment,”arXiv preprint arXiv:2508.07195, 2025
-
[11]
Deep learning for time series forecasting: a survey,
X. Kong, Z. Chen, W. Liu, K. Ning, L. Zhang, S. Muhammad Marier, Y . Liu, Y . Chen, and F. Xia, “Deep learning for time series forecasting: a survey,”International Journal of Machine Learning and Cybernetics, pp. 1–34, 2025
2025
-
[12]
Deep Time Series Models: A Comprehensive Survey and Benchmark
Y . Wang, H. Wu, J. Dong, Y . Liu, C. Wang, M. Long, and J. Wang, “Deep time series models: A comprehensive survey and benchmark,” arXiv preprint arXiv:2407.13278, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Time-series forecasting with deep learning: a survey,
B. Lim and S. Zohren, “Time-series forecasting with deep learning: a survey,”Philosophical transactions of the royal society a: mathematical, physical and engineering sciences, vol. 379, no. 2194, 2021
2021
-
[14]
A review of deep learning models for time series prediction,
Z. Han, J. Zhao, H. Leung, K. F. Ma, and W. Wang, “A review of deep learning models for time series prediction,”IEEE Sensors Journal, vol. 21, no. 6, pp. 7833–7848, 2019
2019
-
[15]
Modeling long-and short-term temporal patterns with deep neural networks,
G. Lai, W.-C. Chang, Y . Yang, and H. Liu, “Modeling long-and short-term temporal patterns with deep neural networks,” inThe 41st international ACM SIGIR conference on research & development in information retrieval, 2018, pp. 95–104. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11 ETTh1 T emperature hourlyChina oil temperature load Long-term...
2018
-
[16]
Deepar: Probabilistic forecasting with autoregressive recurrent networks,
D. Salinas, V . Flunkert, J. Gasthaus, and T. Januschowski, “Deepar: Probabilistic forecasting with autoregressive recurrent networks,”Inter- national journal of forecasting, vol. 36, no. 3, pp. 1181–1191, 2020
2020
-
[17]
Tslanet: Rethinking transformers for time series representation learning,
E. Eldele, M. Ragab, Z. Chen, M. Wu, and X. Li, “Tslanet: Rethinking transformers for time series representation learning,” inForty-first Inter- national Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, 2024
2024
-
[18]
En- hancing the locality and breaking the memory bottleneck of transformer on time series forecasting,
S. Li, X. Jin, Y . Xuan, X. Zhou, W. Chen, Y .-X. Wang, and X. Yan, “En- hancing the locality and breaking the memory bottleneck of transformer on time series forecasting,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[19]
Informer: Beyond efficient transformer for long sequence time-series forecasting,
H. Zhou, S. Zhang, J. Peng, S. Zhang, J. Li, H. Xiong, and W. Zhang, “Informer: Beyond efficient transformer for long sequence time-series forecasting,” inProceedings of the AAAI conference on artificial intel- ligence, vol. 35, no. 12, 2021, pp. 11 106–11 115
2021
-
[20]
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting,
H. Wu, J. Xu, J. Wang, and M. Long, “Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting,” Advances in neural information processing systems, vol. 34, pp. 22 419– 22 430, 2021
2021
-
[21]
Fedformer: Frequency enhanced decomposed transformer for long-term series fore- casting,
T. Zhou, Z. Ma, Q. Wen, X. Wang, L. Sun, and R. Jin, “Fedformer: Frequency enhanced decomposed transformer for long-term series fore- casting,” inInternational conference on machine learning. PMLR, 2022, pp. 27 268–27 286
2022
-
[22]
Are transformers effective for time series forecasting?
A. Zeng, M. Chen, L. Zhang, and Q. Xu, “Are transformers effective for time series forecasting?” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 9, 2023, pp. 11 121–11 128
2023
-
[23]
TEMPO: Prompt-based generative pre-trained transformer for time series forecasting,
D. Cao, F. Jia, S. O. Arik, T. Pfister, Y . Zheng, W. Ye, and Y . Liu, “TEMPO: Prompt-based generative pre-trained transformer for time series forecasting,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[24]
s2ip-llm: Semantic space informed prompt learning with llm for time series forecasting,
Z. Pan, Y . Jiang, S. Garg, A. Schneider, Y . Nevmyvaka, and D. Song, “s2ip-llm: Semantic space informed prompt learning with llm for time series forecasting,” inForty-first International Conference on Machine Learning, 2024
2024
-
[25]
Context-alignment: Activating and enhancing LLMs capabilities in time series,
Y . Hu, Q. Li, D. Zhang, J. Yan, and Y . Chen, “Context-alignment: Activating and enhancing LLMs capabilities in time series,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[26]
Large language models are zero-shot time series forecasters,
N. Gruver, M. Finzi, S. Qiu, and A. G. Wilson, “Large language models are zero-shot time series forecasters,”Advances in Neural Information Processing Systems, vol. 36, pp. 19 622–19 635, 2023
2023
-
[27]
One fits all: Power general time series analysis by pretrained lm,
T. Zhou, P. Niu, L. Sun, R. Jinet al., “One fits all: Power general time series analysis by pretrained lm,”Advances in neural information processing systems, vol. 36, pp. 43 322–43 355, 2023
2023
-
[28]
Timer: Generative pre-trained transformers are large time series models,
Y . Liu, H. Zhang, C. Li, X. Huang, J. Wang, and M. Long, “Timer: Generative pre-trained transformers are large time series models,” in Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, 2024
2024
-
[29]
Position: What can large language models tell us about time series analysis,
M. Jin, Y . Zhang, W. Chen, K. Zhang, Y . Liang, B. Yang, J. Wang, S. Pan, and Q. Wen, “Position: What can large language models tell us about time series analysis,” inForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, 2024
2024
-
[30]
Large language models for time series: A survey,
X. Zhang, R. R. Chowdhury, R. K. Gupta, and J. Shang, “Large language models for time series: A survey,”arXiv preprint arXiv:2402.01801, 2024
-
[31]
Calf: Aligning llms for time series forecasting via cross- modal fine-tuning,
P. Liu, H. Guo, T. Dai, N. Li, J. Bao, X. Ren, Y . Jiang, and S.- T. Xia, “Calf: Aligning llms for time series forecasting via cross- modal fine-tuning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 18, 2025, pp. 18 915–18 923
2025
-
[32]
Timecma: Towards llm-empowered multivariate time series forecasting via cross-modality alignment,
C. Liu, Q. Xu, H. Miao, S. Yang, L. Zhang, C. Long, Z. Li, and R. Zhao, “Timecma: Towards llm-empowered multivariate time series forecasting via cross-modality alignment,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 18, 2025, pp. 18 780–18 788
2025
-
[33]
A decoder-only foundation model for time-series forecasting,
A. Das, W. Kong, R. Sen, and Y . Zhou, “A decoder-only foundation model for time-series forecasting,” inProceedings of the 41st Interna- tional Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[34]
Unified training of universal time series forecasting transformers,
G. Woo, C. Liu, A. Kumar, C. Xiong, S. Savarese, and D. Sahoo, “Unified training of universal time series forecasting transformers,” in Forty-first International Conference on Machine Learning, 2024
2024
-
[35]
Chronos: Learning the language of time series,
A. F. Ansari, L. Stella, A. C. T ¨urkmen, X. Zhang, P. Mercado, H. Shen, O. Shchur, S. S. Rangapuram, S. Pineda-Arango, S. Kapoor, J. Zschieg- ner, D. C. Maddix, H. Wang, M. W. Mahoney, K. Torkkola, A. G. Wilson, M. Bohlke-Schneider, and B. Wang, “Chronos: Learning the language of time series,”Trans. Mach. Learn. Res., vol. 2024, 2024
2024
-
[36]
Reversible instance normalization for accurate time-series forecasting against dis- tribution shift,
T. Kim, J. Kim, Y . Tae, C. Park, J. Choi, and J. Choo, “Reversible instance normalization for accurate time-series forecasting against dis- tribution shift,” inThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022, 2022
2022
-
[37]
Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 19 730–19 742
2023
-
[38]
Instructblip: Towards general-purpose vision-language models with instruction tuning,
W. Dai, J. Li, D. Li, A. Tiong, J. Zhao, W. Wang, B. Li, P. N. Fung, and S. Hoi, “Instructblip: Towards general-purpose vision-language models with instruction tuning,”Advances in neural information processing systems, vol. 36, pp. 49 250–49 267, 2023
2023
-
[39]
Simpletm: A simple baseline for multivariate time series forecasting,
H. Chen, V . Luong, L. Mukherjee, and V . Singh, “Simpletm: A simple baseline for multivariate time series forecasting,” inThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025, 2025. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12 0 25 50 75 100 125 150 175 200 Forecast Horizon (Steps) 4...
2025
-
[40]
Timer-xl: Long- context transformers for unified time series forecasting,
Y . Liu, G. Qin, X. Huang, J. Wang, and M. Long, “Timer-xl: Long- context transformers for unified time series forecasting,” inThe Thir- teenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025, 2025
2025
-
[41]
Timemixer: Decomposable multiscale mixing for time series forecasting,
S. Wang, H. Wu, X. Shi, T. Hu, H. Luo, L. Ma, J. Y . Zhang, and J. Zhou, “Timemixer: Decomposable multiscale mixing for time series forecasting,” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024, 2024
2024
-
[42]
Representation Learning with Contrastive Predictive Coding
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[43]
Q. Teamet al., “Qwen2 technical report,”arXiv preprint arXiv:2407.10671, vol. 2, no. 3, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.