Speaker-Invariant Representation Learning for Spoofing Detection via Gradient Reversal and A Variational Information Bottleneck
Pith reviewed 2026-06-27 17:50 UTC · model grok-4.3
The pith
A teacher-student setup with gradient reversal and a variational information bottleneck produces speaker-invariant features for spoofing detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that guiding a spoofing detector with gradient reversal against a speaker-recognition teacher, combined with a variational information bottleneck to balance identity suppression against task-relevant cue preservation, yields representations that are invariant to speaker identity while remaining useful for detecting spoofed speech, and that this yields measurable gains in out-of-domain generalization without requiring speaker annotations.
What carries the argument
Teacher-student framework in which gradient reversal against a pre-trained speaker recognizer suppresses identity cues and a variational information bottleneck controls retention of spoofing cues.
If this is right
- The detector achieves a 25.7 percent relative reduction in equal error rate versus the MHFA baseline on nine datasets.
- Speaker-invariant representations can be learned for spoofing detection without access to speaker labels.
- The variational information bottleneck allows explicit control over the trade-off between identity suppression and spoofing-cue retention.
- Out-of-domain generalization improves when identity cues are actively removed during training.
Where Pith is reading between the lines
- The same disentanglement pattern could be tested on other audio classification tasks where speaker variability acts as a confounding factor.
- If the bottleneck successfully isolates spoofing cues, the method might reduce reliance on large speaker-labeled corpora for anti-spoofing systems.
- The framework offers a template for applying gradient reversal and information bottlenecks to other domain-adaptation problems in speech processing.
Load-bearing premise
Speaker bias is the dominant cause of poor generalization, and the gradient-reversal plus bottleneck combination can remove identity information without also discarding the cues needed for spoofing detection.
What would settle it
An experiment that measures whether spoofing detection accuracy collapses on held-out data once speaker identity is fully decorrelated from the spoofing labels.
Figures

read the original abstract
Sophisticated generative speech technology can undermined the reliability of voice biometrics. While spoofing detection systems excel when assessed under in-domain conditions, generalisation to out-of-domain settings is often poor. In this paper, we show that such issues could be caused by speaker bias, where models learn individual voice traits rather than markers of manipulation or generation. We propose a teacher-student framework for speaker-invariant spoofing detection that disentangles identity without requiring speaker labels. We leverage a pre-trained speaker recognition teacher to guide a student model via a gradient reversal layer. To control the balance between suppressing cues related to voice identity with the preservation of those related to spoofing detection, we integrate a Variational Information Bottleneck. Evaluations across nine datasets show our model achieves a 25.7% relative reduction to the EER compared to the MHFA baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that speaker bias is a primary cause of poor out-of-domain generalization in spoofing detectors and proposes a teacher-student architecture that uses gradient reversal against a fixed pre-trained speaker recognition model together with a variational information bottleneck (VIB) to produce speaker-invariant embeddings; the resulting system is reported to deliver a 25.7% relative EER reduction versus the MHFA baseline when evaluated across nine datasets.
Significance. If the reported EER reduction proves robust and the information-partitioning mechanism can be verified, the approach would offer a practical route to improved generalization in spoofing detection without requiring speaker labels during training. The breadth of the nine-dataset evaluation is a clear strength; however, the current absence of mechanistic probes and hyper-parameter ablations substantially reduces the immediate significance of the empirical claim.
major comments (2)
- [Abstract] Abstract: the central performance claim of a 25.7% relative EER reduction is presented without statistical significance tests, standard deviations across multiple runs, or any ablation on the VIB β parameter and gradient-reversal strength; these omissions make it impossible to determine whether the gain is attributable to speaker-bias removal or to generic regularization.
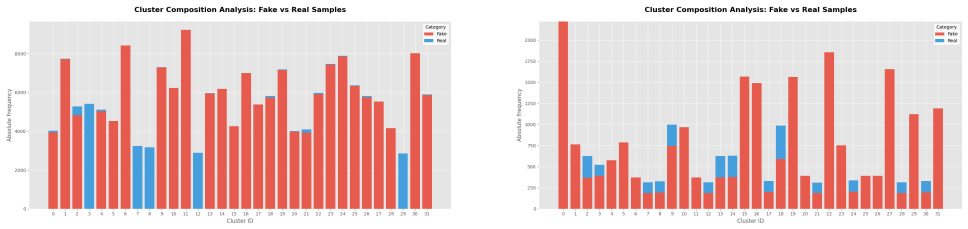
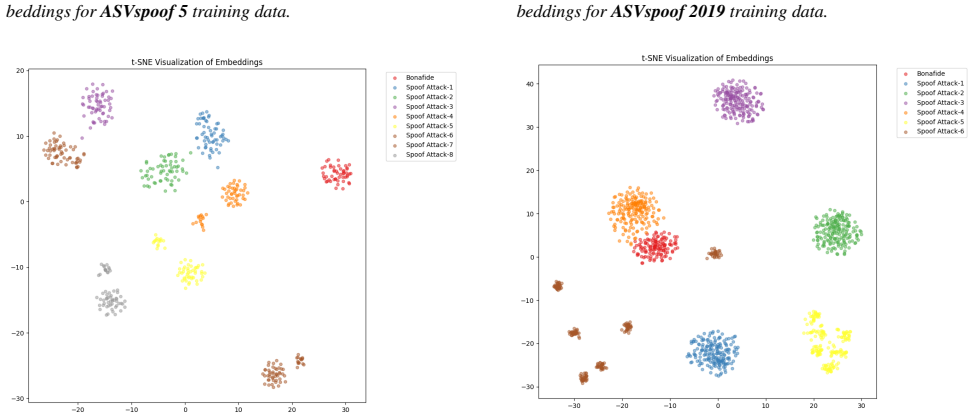
- [Proposed Method] Proposed Method (teacher-student + VIB section): no post-hoc measurements (speaker classification accuracy, mutual-information estimates, or t-SNE visualizations of the final embeddings) are supplied to confirm that speaker identity information has been suppressed while spoofing-discriminative cues remain; without such verification the causal attribution of the EER improvement to the gradient-reversal/VIB objectives remains untested.
minor comments (2)
- [Abstract] Abstract: grammatical error 'can undermined' should read 'can undermine'.
- The manuscript does not state the precise training protocol for the student branch (learning-rate schedule, batch size, or how the fixed teacher embeddings are obtained), which hinders reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim of a 25.7% relative EER reduction is presented without statistical significance tests, standard deviations across multiple runs, or any ablation on the VIB β parameter and gradient-reversal strength; these omissions make it impossible to determine whether the gain is attributable to speaker-bias removal or to generic regularization.
Authors: We agree that the abstract would benefit from additional statistical context. In the revised manuscript we will report mean EER and standard deviation across at least five independent runs with different random seeds for both the proposed method and the MHFA baseline. We will also include paired statistical significance tests (e.g., Wilcoxon signed-rank) across the nine datasets. Furthermore, we will add a dedicated ablation subsection that varies the VIB β coefficient and the gradient-reversal strength (λ) while keeping all other factors fixed, thereby clarifying the contribution of each component beyond generic regularization. revision: yes
-
Referee: [Proposed Method] Proposed Method (teacher-student + VIB section): no post-hoc measurements (speaker classification accuracy, mutual-information estimates, or t-SNE visualizations of the final embeddings) are supplied to confirm that speaker identity information has been suppressed while spoofing-discriminative cues remain; without such verification the causal attribution of the EER improvement to the gradient-reversal/VIB objectives remains untested.
Authors: We concur that direct verification of the information-partitioning effect would strengthen the causal interpretation. In the revised version we will include: (i) speaker classification accuracy of a linear probe trained on the learned embeddings (lower accuracy indicates successful suppression), (ii) t-SNE visualizations of embeddings produced with and without the gradient-reversal and VIB terms, and (iii) where computationally feasible, a mutual-information estimate between the embeddings and speaker labels. These analyses will be placed in a new “Analysis of Speaker Invariance” subsection and will be performed on at least two of the evaluation datasets. revision: yes
Circularity Check
Empirical evaluation of proposed architecture; no derivations or self-referential predictions
full rationale
The paper advances a teacher-student framework that applies gradient reversal from a fixed speaker-recognition teacher plus a variational information bottleneck on the student representation. Its central claim is an observed 25.7 % relative EER reduction across nine external datasets versus the MHFA baseline. No equations, uniqueness theorems, or parameter-fitting steps are presented whose outputs are then re-labeled as predictions; the reported metric is measured on held-out data after training and is therefore independent of any definitional loop. Standard techniques (gradient reversal, VIB) are invoked without self-citation chains that would render the result tautological. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction V oice biometric systems remain vulnerable to increasingly so- phisticated spoofing attacks generated by modern text-to-speech (TTS) and voice conversion (VC). As a result, spoofing de- tection systems have become an essential security component to safeguard voice biometric deployments. By providing stan- dardized datasets and evaluation prot...
Pith/arXiv arXiv 2026
-
[2]
Speaker Bias Analysis A primary challenge in synthetic speech detection is the preva- lence of speaker bias, where speaker identities are not indepen- dent of class labels. When a training distribution exhibits a disjoint speaker set between bona fide and spoofed partitions, classifiers are prone to learning spurious correlations between specific vocal id...
2019
-
[3]
The proposed approach enforces speaker invari- ance at the representation level via GRL guided by a pretrained speaker recognition teacher
Proposed Method We introduce a teacher-student learning framework augmented with a VIB to suppress speaker identity information in spoof- ing detection. The proposed approach enforces speaker invari- ance at the representation level via GRL guided by a pretrained speaker recognition teacher. 3.1. Speaker Recognition Teacher Model To model speaker identity...
-
[4]
Speaker Recognition Dataset The speaker recognition teacher model is trained on the V ox- Celeb corpus, a widely adopted benchmark in speaker recog- nition community
Experimental Setup 4.1. Speaker Recognition Dataset The speaker recognition teacher model is trained on the V ox- Celeb corpus, a widely adopted benchmark in speaker recog- nition community. V oxCeleb contains over one million speech recordings from 5,994 speakers, covering diverse acoustic con- ditions and speaking styles. 4.2. Spoofing Detection Dataset...
2019
-
[5]
Results 5.1. Baseline Spoofing Detection Performance The performance of the baseline architectures (i.e., AASIST, Conformer, and MHFA) varies significantly across the evalu- ated datasets, underscoring the persistent generalization gap in audio anti-spoofing (see Table 1). While the models perform competently on the ASVspoof 2021 DF task (achieving EERs n...
2021
-
[6]
Conclusion In this paper, we address a critical yet unexplored limitation of spoofing detection systems: speaker bias. We demonstrate that, for the ASVspoof 5 dataset, mismatches between the voice traits of spoofed and bona fide utterances are a potential learn- ing shortcut which can undermine model generalisation. To ad- dress this weakness, we propose ...
-
[7]
This work was financially supported by ANR BRUEL (ANR-22-CE39-0009)
Acknowledgements This work was performed using HPC resources from GENCI- IDRIS. This work was financially supported by ANR BRUEL (ANR-22-CE39-0009)
-
[8]
ASVspoof 5: crowd- sourced speech data, deepfakes, and adversarial attacks at scale,
X. Wang, H. Delgado, H. Tak, J. weon Jung, H. jin Shim, M. Todisco, I. Kukanov, X. Liu, M. Sahidullah, T. H. Kinnunen, N. Evans, K. A. Lee, and J. Yamagishi, “ASVspoof 5: crowd- sourced speech data, deepfakes, and adversarial attacks at scale,” inASVspoof, 2024
2024
-
[9]
ADD 2022: the first audio deep synthesis detection challenge,
J. Yi, R. Fu, J. Tao, S. Nie, H. Ma, C. Wang, T. Wang, Z. Tian, Y . Bai, C. Fan, S. Liang, S. Wang, S. Zhang, X. Yan, L. Xu, Z. Wen, and H. Li, “ADD 2022: the first audio deep synthesis detection challenge,” inICASSP, 2022
2022
-
[10]
AASIST: audio anti-spoofing using integrated spectro- temporal graph attention networks,
J. Jung, H. Heo, H. Tak, H. Shim, J. S. Chung, B. Lee, H. Yu, and N. Evans, “AASIST: audio anti-spoofing using integrated spectro- temporal graph attention networks,” inICASSP, 2022
2022
-
[11]
A conformer-based classifier for variable-length utterance process- ing in anti-spoofing,
E. Rosello, A. G. Alan ´ıs, A. M. Gomez, and A. M. Peinado, “A conformer-based classifier for variable-length utterance process- ing in anti-spoofing,” inInterspeech, 2023
2023
-
[12]
Exploring WavLM back-ends for speech spoofing and deepfake detection,
T. Stourbe, V . Miara, T. Lepage, and R. Dehak, “Exploring WavLM back-ends for speech spoofing and deepfake detection,” inASVspoof, 2024
2024
-
[13]
Audio deepfake detection with self- supervised xls-r and sls classifier
Q. Zhang, S. Wen, and T. Hu, “Audio deepfake detection with self- supervised xls-r and sls classifier.” Association for Computing Machinery, 2024
2024
-
[14]
Xlsr-mamba: A dual-column bidirec- tional state space model for spoofing attack detection,
Y . Xiao and R. K. Das, “Xlsr-mamba: A dual-column bidirec- tional state space model for spoofing attack detection,”IEEE Sig- nal Processing Letters, 2025
2025
-
[15]
Aasist: Audio anti-spoofing using in- tegrated spectro-temporal graph attention networks,
J.-w. Jung, H.-S. Heo, H. Tak, H.-j. Shim, J. S. Chung, B.-J. Lee, H.-J. Yu, and N. Evans, “Aasist: Audio anti-spoofing using in- tegrated spectro-temporal graph attention networks,” inICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022
2022
-
[16]
End-to-end anti-spoofing with rawnet2,
H. Tak, J. Patino, M. Todisco, A. Nautsch, N. Evans, and A. Larcher, “End-to-end anti-spoofing with rawnet2,” inICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021
2021
-
[17]
ASVspoof 5 challenge: advanced resnet architectures for robust voice spoofing detection,
A.-T. Dao, M. Rouvier, and D. Matrouf, “ASVspoof 5 challenge: advanced resnet architectures for robust voice spoofing detection,” inASVspoof 2024, 2024
2024
-
[18]
Speech is silver, silence is golden: What do ASVspoof-trained models really learn?
N. M. M ¨uller, F. Dieckmann, P. Czempin, R. Canals, and K. B ¨ottinger, “Speech is silver, silence is golden: What do ASVspoof-trained models really learn?”ArXiv, 2021
2021
-
[19]
Assessing the impact of speaker identity in speech spoofing detection,
A.-T. Dao, D. Matrouf, and N. Evans, “Assessing the impact of speaker identity in speech spoofing detection,” 2026
2026
-
[20]
V oxceleb: A large- scale speaker identification dataset,
A. Nagrani, J. S. Chung, and A. Zisserman, “V oxceleb: A large- scale speaker identification dataset,” inInterspeech, 2017
2017
-
[21]
Unsupervised domain adaptation by backpropagation,
Y . Ganin and V . Lempitsky, “Unsupervised domain adaptation by backpropagation,” inICML, 2015
2015
-
[22]
Deep vari- ational information bottleneck,
A. A. Alemi, I. Fischer, J. V . Dillon, and K. Murphy, “Deep vari- ational information bottleneck,”ICLR, 2017
2017
-
[23]
XLS-R: self-supervised cross-lingual speech representation learning at scale,
A. Babu, C. Wang, A. Tjandra, K. Lakhotia, Q. Xu, N. Goyal, K. Singh, P. von Platen, Y . Saraf, J. Pino, A. Baevski, A. Con- neau, and M. Auli, “XLS-R: self-supervised cross-lingual speech representation learning at scale,” inInterspeech, 2022
2022
-
[24]
Speech df arena: A leaderboard for speech deepfake detection models,
S. Dowerah, A. Kulkarni, A. Kulkarni, H. M. Tran, J. Kalda, A. Fedorchenko, B. Fauve, D. Lolive, T. Alum¨ae, and M. M. Doss, “Speech df arena: A leaderboard for speech deepfake detection models,” 2025
2025
-
[25]
Does audio deepfake detection generalize?
N. M. M ¨uller, P. Czempin, F. Dieckmann, A. Froghyar, and K. B¨ottinger, “Does audio deepfake detection generalize?” inIn- terspeech, 2022
2022
-
[26]
ASVspoof 2019: Future horizons in spoofed and fake audio detection,
M. Todisco, X. Wang, V . Vestman, M. Sahidullah, H. Delgado, A. Nautsch, J. Yamagishi, N. Evans, T. H. Kinnunen, and K. A. Lee, “ASVspoof 2019: Future horizons in spoofed and fake audio detection,” inInterspeech, 2019
2019
-
[27]
ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection,
J. Yamagishi, X. Wang, M. Todisco, M. Sahidullah, J. Patino, A. Nautsch, X. Liu, K. A. Lee, T. Kinnunen, N. Evans, and H. Delgado, “ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection,” inASVspoof 2021, 2021
2021
-
[28]
For: A dataset for synthetic speech detection,
R. Reimao and V . Tzerpos, “For: A dataset for synthetic speech detection,” in2019 International Conference on Speech Technol- ogy and Human-Computer Dialogue, SpeD 2019, Timisoara, Ro- mania, October 10-12, C. Burileanu and H. Teodorescu, Eds., 2019
2019
-
[29]
The codecfake dataset and countermeasures for the universally detection of deepfake audio,
Y . Xie, Y . Lu, R. Fu, Z. Wen, Z. Wang, J. Tao, X. Qi, X. Wang, Y . Liu, H. Cheng, L. Ye, and Y . Sun, “The codecfake dataset and countermeasures for the universally detection of deepfake audio,” IEEE Transactions on Audio, Speech and Language Processing, 2025
2025
-
[30]
Dfadd: The diffusion and flow- matching based audio deepfake dataset,
J. Du, I.-M. Lin, I.-H. Chiu, X. Chen, H. Wu, W. Ren, Y . Tsao, H.-Y . Lee, and J.-S. R. Jang, “Dfadd: The diffusion and flow- matching based audio deepfake dataset,” in2024 IEEE Spoken Language Technology Workshop (SLT), 2024
2024
-
[31]
Ai-synthesized voice detection using neural vocoder artifacts,
C. Sun, S. Jia, S. Hou, and S. Lyu, “Ai-synthesized voice detection using neural vocoder artifacts,” in2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2023
2023
-
[32]
Where are we in audio deep- fake detection? a systematic analysis over generative and detec- tion models,
X. Li, P.-Y . Chen, and W. Wei, “Where are we in audio deep- fake detection? a systematic analysis over generative and detec- tion models,”ACM Transactions on Internet Technology, 2025
2025
-
[33]
MUSAN: A music, speech, and noise corpus,
D. Snyder, G. Chen, and D. Povey, “MUSAN: A music, speech, and noise corpus,”ArXiv, 2015
2015
-
[34]
A study on data augmentation of reverberant speech for robust speech recognition,
T. Ko, V . Peddinti, D. Povey, M. L. Seltzer, and S. Khudanpur, “A study on data augmentation of reverberant speech for robust speech recognition,” inICASSP, 2017
2017
-
[35]
Adam: A method for stochastic opti- mization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic opti- mization,” inICLR, Y . Bengio and Y . LeCun, Eds., 2015
2015
-
[36]
Asvspoof 5: Evaluation of spoofing, deepfake, and adver- sarial attack detection using crowdsourced speech,
X. Wang, H. Delgado, N. Evans, X. Liu, T. Kinnunen, H. Tak, K. A. Lee, I. Kukanov, M. Sahidullah, M. Todisco, and J. Yam- agishi, “Asvspoof 5: Evaluation of spoofing, deepfake, and adver- sarial attack detection using crowdsourced speech,” 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.