Co-Evolving Skill Generation and Policy Optimization
Pith reviewed 2026-06-27 18:35 UTC · model grok-4.3
The pith
A reward gap from matched rollouts estimates whether a candidate skill adds value beyond those already retrieved.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
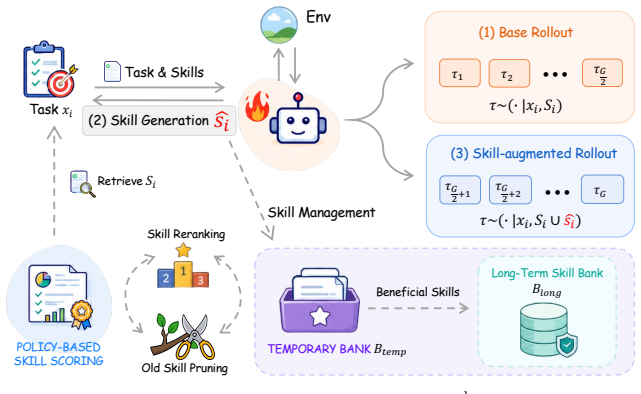
The reward gap between base rollouts conditioned on currently retrieved skills and skill-augmented rollouts conditioned on the same skills plus one candidate skill induced from the base trajectories estimates the candidate skill's context-dependent marginal utility, enabling the framework to promote useful skills while filtering ineffective or harmful ones without additional rollout overhead and to train the policy itself as a skill generator.
What carries the argument
The marginal-utility estimator given by the reward difference between two matched rollout groups that differ only by the presence of one candidate skill.
If this is right
- Skills enter the bank only after their context-dependent value is measured.
- The policy learns to generate higher-utility skills directly from the marginal-utility signal.
- Generation likelihood from the trained policy reranks candidates and prunes outdated skills at retrieval time.
- The entire loop runs inside the standard rollout budget with no extra environment interactions.
Where Pith is reading between the lines
- The same matched-group comparison could be applied to other reusable structures such as plans or tool-use sequences.
- Over many iterations the learned generator may reduce or replace calls to large external models for skill creation.
- The approach supplies an online bandit-style signal for skill selection that could be combined with retrieval methods outside reinforcement learning.
Load-bearing premise
The reward difference between the two rollout groups isolates the marginal contribution of the single added skill rather than being dominated by rollout variance or interactions with the existing skill set.
What would settle it
Run held-out tasks where skills pre-validated by the reward-gap method are added to the bank and measure whether their actual performance lift matches the gap observed during validation; a mismatch would falsify the estimator.
Figures

read the original abstract
Skill-augmented reinforcement learning improves language agents by storing reusable procedural knowledge acquired from past experience. Existing methods typically use strong language models to analyze trajectories, generate skills, and update a retrievable skill bank during online training. However, they rarely assess whether a newly generated skill is useful before it is stored and reused. We find that this assumption is unreliable: even skills generated by proprietary frontier LLMs exhibit highly mixed utility, with many providing little benefit or even degrading performance. Once such skills enter the bank, their effects are difficult to identify, because subsequent rollout feedback is delayed and usually reflects the combined effect of multiple retrieved skills rather than the marginal contribution of any individual skill. We propose an online reinforcement learning framework for pre-storage skill validation. The framework estimates whether a candidate skill contributes useful information beyond the skills already retrieved for the current task. It uses the standard rollout budget to form two matched groups under the same task and retrieval context: base rollouts conditioned on the currently retrieved skills, and skill-augmented rollouts conditioned on the same skills plus one candidate skill induced from the base trajectories. The reward gap between these two groups estimates the candidate skill's context-dependent marginal utility, enabling the framework to promote useful skills while filtering ineffective or harmful ones without additional rollout overhead. The framework further uses this marginal-utility signal to train the policy itself as a skill generator, reducing reliance on repeated calls to proprietary models. The learned skill-generation likelihood serves as a context-dependent score for retrieval-time reranking and outdated-skill pruning as the policy evolves.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing skill-augmented RL methods for language agents suffer from storing mixed-utility skills generated by LLMs, and proposes an online framework that forms matched base and skill-augmented rollout groups under identical task/retrieval context to compute a reward gap estimating each candidate skill's marginal utility; this signal is used both to filter skills before storage and to train the policy itself as a generator, enabling co-evolution without extra rollout cost.
Significance. If the reward-gap construction reliably isolates marginal utility, the method would address a practical bottleneck in online skill banks by enabling pre-storage validation and self-supervised generation, potentially improving long-term agent performance while lowering reliance on proprietary models.
major comments (2)
- [Abstract] Abstract (method description): the construction treats the scalar reward difference between the two matched groups as an estimate of the candidate skill's marginal utility, yet supplies no derivation, concentration bound, or variance analysis showing that this difference converges to the true marginal contribution rather than being dominated by sampling variance across the split budget or by non-additive interactions between the candidate and the already-retrieved skill set.
- [Abstract] Abstract: the central claim that the framework 'enables promotion of useful skills while filtering ineffective or harmful ones without additional rollout overhead' rests on the unverified assumption that the observed gap isolates the single added skill; no empirical results, ablation on rollout variance, or stability analysis of the co-training loop are referenced to support this.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on the abstract's claims. We address each point below, clarifying the support present in the manuscript while agreeing where additional material would strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract (method description): the construction treats the scalar reward difference between the two matched groups as an estimate of the candidate skill's marginal utility, yet supplies no derivation, concentration bound, or variance analysis showing that this difference converges to the true marginal contribution rather than being dominated by sampling variance across the split budget or by non-additive interactions between the candidate and the already-retrieved skill set.
Authors: The abstract is space-constrained and therefore omits the justification given in Section 3.2, where the matched-group construction is presented as yielding an unbiased estimator of marginal utility when skill effects are approximately additive and the two groups share identical task/retrieval context. We agree that an explicit concentration or variance analysis is absent from the current version and will add a short discussion of sampling variance together with a Hoeffding-style bound in the revised manuscript. revision: partial
-
Referee: [Abstract] Abstract: the central claim that the framework 'enables promotion of useful skills while filtering ineffective or harmful ones without additional rollout overhead' rests on the unverified assumption that the observed gap isolates the single added skill; no empirical results, ablation on rollout variance, or stability analysis of the co-training loop are referenced to support this.
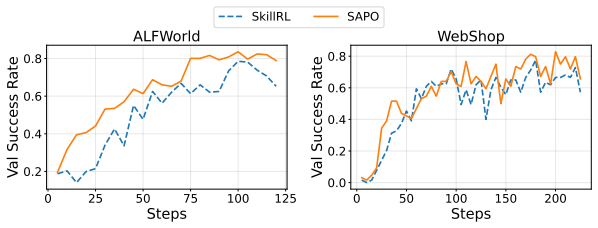
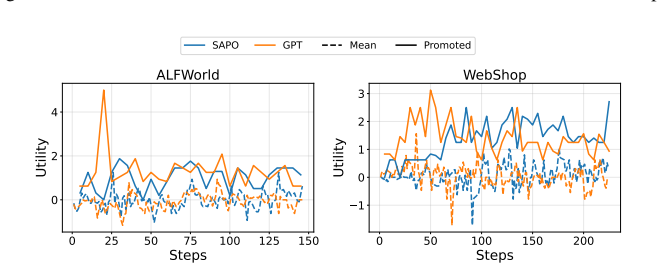
Authors: The abstract does not cite results, but the full manuscript reports the relevant experiments in Section 5 (filtering performance) together with rollout-count ablations in Appendix B and co-training stability analysis in Section 4.3 and Figure 4. We will revise the abstract to include a concise reference to these empirical findings. revision: yes
Circularity Check
No circularity: marginal utility defined directly as observed reward gap from matched rollouts
full rationale
The paper's central mechanism computes a reward difference between two explicitly constructed rollout groups (base vs. base-plus-candidate) under identical task and retrieval context, then treats that scalar difference as the estimate of marginal utility. This is an empirical measurement by construction rather than a derivation that reduces to a fitted parameter, self-citation, or redefinition of its own inputs. No equations or claims in the abstract reduce the utility signal to a prior result from the same authors; the method remains self-contained against external benchmarks because the gap is generated from fresh, budgeted rollouts without invoking uniqueness theorems or ansatzes from prior work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chenyu Zhou, Huacan Chai, Wenteng Chen, Zihan Guo, Rong Shan, Yuanyi Song, Tianyi Xu, Yingxuan Yang, Aofan Yu, Weiming Zhang, et al. Externalization in llm agents: A unified review of memory, skills, protocols and harness engineering.arXiv preprint arXiv:2604.08224, 2026
Pith/arXiv arXiv 2026
-
[2]
Memento-skills: Let agents design agents
Huichi Zhou, Siyuan Guo, Anjie Liu, Zhongwei Yu, Ziqin Gong, Bowen Zhao, Zhixun Chen, Menglong Zhang, Yihang Chen, Jinsong Li, et al. Memento-skills: Let agents design agents. arXiv preprint arXiv:2603.18743, 2026
arXiv 2026
-
[3]
Yi Yu, Liuyi Yao, Yuexiang Xie, Qingquan Tan, Jiaqi Feng, Yaliang Li, and Libing Wu. Agentic memory: Learning unified long-term and short-term memory management for large language model agents.arXiv preprint arXiv:2601.01885, 2026
Pith/arXiv arXiv 2026
-
[4]
Ael: Agent evolving learning for open-ended environments.arXiv preprint arXiv:2604.21725, 2026
Wujiang Xu, Jiaojiao Han, Minghao Guo, Kai Mei, Xi Zhu, Han Zhang, and Dimitris N Metaxas. Ael: Agent evolving learning for open-ended environments.arXiv preprint arXiv:2604.21725, 2026
Pith/arXiv arXiv 2026
-
[5]
Rajkumar Buyya et al. Agentic artificial intelligence (ai): Architectures, taxonomies, and evaluation of large language model agents.arXiv preprint arXiv:2601.12560, 2026
arXiv 2026
-
[6]
Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhongzhi Li, Xiangyuan Xue, Yijiang Li, et al. The landscape of agentic reinforcement learning for llms: A survey.arXiv preprint arXiv:2509.02547, 2025
Pith/arXiv arXiv 2025
-
[7]
Agentic large language models, a survey.Journal of Artificial Intelligence Research, 84, 2025
Aske Plaat, Max van Duijn, Niki Van Stein, Mike Preuss, Peter van der Putten, and Kees Joost Batenburg. Agentic large language models, a survey.Journal of Artificial Intelligence Research, 84, 2025
2025
-
[8]
Agentic reasoning for large language models.arXiv preprint arXiv:2601.12538, 2026
Tianxin Wei, Ting-Wei Li, Zhining Liu, Xuying Ning, Ze Yang, Jiaru Zou, Zhichen Zeng, Ruizhong Qiu, Xiao Lin, Dongqi Fu, et al. Agentic reasoning for large language models.arXiv preprint arXiv:2601.12538, 2026
Pith/arXiv arXiv 2026
-
[9]
Wei-Lin Chen, Liqian Peng, Tian Tan, Chao Zhao, Blake JianHang Chen, Ziqian Lin, Alec Go, and Yu Meng. Think deep, not just long: Measuring llm reasoning effort via deep-thinking tokens.arXiv preprint arXiv:2602.13517, 2026
arXiv 2026
-
[10]
Brain-inspired graph multi-agent systems for llm reasoning.arXiv preprint arXiv:2603.15371, 2026
Guangfu Hao, Yuming Dai, Xianzhe Qin, and Shan Yu. Brain-inspired graph multi-agent systems for llm reasoning.arXiv preprint arXiv:2603.15371, 2026
arXiv 2026
-
[11]
Idrbench: Interactive deep research benchmark.arXiv preprint arXiv:2601.06676, 2026
Yingchaojie Feng, Qiang Huang, Xiaoya Xie, Zhaorui Yang, Jun Yu, Wei Chen, and Anthony KH Tung. Idrbench: Interactive deep research benchmark.arXiv preprint arXiv:2601.06676, 2026
Pith/arXiv arXiv 2026
-
[12]
Benchmark test-time scaling of general llm agents.arXiv preprint arXiv:2602.18998, 2026
Xiaochuan Li, Ryan Ming, Pranav Setlur, Abhijay Paladugu, Andy Tang, Hao Kang, Shuai Shao, Rong Jin, and Chenyan Xiong. Benchmark test-time scaling of general llm agents.arXiv preprint arXiv:2602.18998, 2026
arXiv 2026
-
[13]
Agentic reasoning: A streamlined framework for enhancing llm reasoning with agentic tools
Junde Wu, Jiayuan Zhu, Yuyuan Liu, Min Xu, and Yueming Jin. Agentic reasoning: A streamlined framework for enhancing llm reasoning with agentic tools. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 28489–28503, 2025
2025
-
[14]
Bingxi Zhao, Lin Geng Foo, Ping Hu, Christian Theobalt, Hossein Rahmani, and Jun Liu. Llm-based agentic reasoning frameworks: A survey from methods to scenarios.arXiv preprint arXiv:2508.17692, 2025
arXiv 2025
-
[15]
Renjun Xu and Yang Yan. Agent skills for large language models: Architecture, acquisition, security, and the path forward.arXiv preprint arXiv:2602.12430, 2026
Pith/arXiv arXiv 2026
-
[16]
Sok: Agentic skills–beyond tool use in llm agents.arXiv preprint arXiv:2602.20867, 2026
Yanna Jiang, Delong Li, Haiyu Deng, Baihe Ma, Xu Wang, Qin Wang, and Guangsheng Yu. Sok: Agentic skills–beyond tool use in llm agents.arXiv preprint arXiv:2602.20867, 2026. 11
Pith/arXiv arXiv 2026
-
[17]
Chenxi Wang, Zhuoyun Yu, Xin Xie, Wuguannan Yao, Runnan Fang, Shuofei Qiao, Kexin Cao, Guozhou Zheng, Xiang Qi, Peng Zhang, et al. Skillx: Automatically constructing skill knowledge bases for agents.arXiv preprint arXiv:2604.04804, 2026
Pith/arXiv arXiv 2026
-
[18]
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, et al. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234, 2026
Pith/arXiv arXiv 2026
-
[19]
Shuo Yang, Soyeon Caren Han, Yihao Ding, Shuhe Wang, and Eduard Hoy. Tooltree: Efficient llm agent tool planning via dual-feedback monte carlo tree search and bidirectional pruning. arXiv preprint arXiv:2603.12740, 2026
arXiv 2026
-
[20]
Agentic tool use in large language models.arXiv preprint arXiv:2604.00835, 2026
Jinchao Hu, Meizhi Zhong, Kehai Chen, Xuefeng Bai, and Min Zhang. Agentic tool use in large language models.arXiv preprint arXiv:2604.00835, 2026
arXiv 2026
-
[21]
Xiaoqiang Lin, Jun Hao Liew, Silvio Savarese, and Junnan Li. W&d: Scaling parallel tool calling for efficient deep research agents.arXiv preprint arXiv:2602.07359, 2026
arXiv 2026
-
[22]
Barry Zhang, Keith Lazuka, and Mahesh Murag. Equipping agents for the real world with agent skills, october 2025.URL https://www.anthropic.com/engineering/equipping-agents-for-the- real-world-with-agent-skills.Accessed, pages 01–28, 2026
2025
-
[23]
Cascade: Cumulative agentic skill creation through autonomous development and evolution
Xu Huang, Junwu Chen, Yuxing Fei, Zhuohan Li, Philippe Schwaller, and Gerbrand Ceder. Cascade: Cumulative agentic skill creation through autonomous development and evolution. arXiv preprint arXiv:2512.23880, 2025
arXiv 2025
-
[24]
Boyuan Zheng, Michael Y Fatemi, Xiaolong Jin, Zora Zhiruo Wang, Apurva Gandhi, Yueqi Song, Yu Gu, Jayanth Srinivasa, Gaowen Liu, Graham Neubig, et al. Skillweaver: Web agents can self-improve by discovering and honing skills.arXiv preprint arXiv:2504.07079, 2025
Pith/arXiv arXiv 2025
-
[25]
Yongjin Yang, Sinjae Kang, Juyong Lee, Dongjun Lee, Se-Young Yun, and Kimin Lee. Auto- mated skill discovery for language agents through exploration and iterative feedback.arXiv preprint arXiv:2506.04287, 2025
arXiv 2025
-
[26]
Proposer-agent-evaluator (pae): Autonomous skill discovery for foundation model internet agents
Yifei Zhou, Qianlan Yang, Kaixiang Lin, Min Bai, Xiong Zhou, Yu-Xiong Wang, Sergey Levine, and Li Erran Li. Proposer-agent-evaluator (pae): Autonomous skill discovery for foundation model internet agents. InForty-second International Conference on Machine Learning, 2025
2025
-
[27]
Memp: Exploring agent procedural memory.arXiv preprint arXiv:2508.06433, 2025
Runnan Fang, Yuan Liang, Xiaobin Wang, Jialong Wu, Shuofei Qiao, Pengjun Xie, Fei Huang, Huajun Chen, and Ningyu Zhang. Memp: Exploring agent procedural memory.arXiv preprint arXiv:2508.06433, 2025
Pith/arXiv arXiv 2025
-
[28]
Zouying Cao, Jiaji Deng, Li Yu, Weikang Zhou, Zhaoyang Liu, Bolin Ding, and Hai Zhao. Remember me, refine me: A dynamic procedural memory framework for experience-driven agent evolution.arXiv preprint arXiv:2512.10696, 2025
Pith/arXiv arXiv 2025
-
[29]
Meta context engineer- ing via agentic skill evolution.arXiv preprint arXiv:2601.21557, 2026
Haoran Ye, Xuning He, Vincent Arak, Haonan Dong, and Guojie Song. Meta context engineer- ing via agentic skill evolution.arXiv preprint arXiv:2601.21557, 2026
arXiv 2026
-
[30]
Zhengxi Lu, Zhiyuan Yao, Jinyang Wu, Chengcheng Han, Qi Gu, Xunliang Cai, Weiming Lu, Jun Xiao, Yueting Zhuang, and Yongliang Shen. Skill0: In-context agentic reinforcement learning for skill internalization.arXiv preprint arXiv:2604.02268, 2026
Pith/arXiv arXiv 2026
-
[31]
Dynamic dual-granularity skill bank for agentic rl.arXiv preprint arXiv:2603.28716, 2026
Songjun Tu, Chengdong Xu, Qichao Zhang, Yaocheng Zhang, Xiangyuan Lan, Linjing Li, and Dongbin Zhao. Dynamic dual-granularity skill bank for agentic rl.arXiv preprint arXiv:2603.28716, 2026
Pith/arXiv arXiv 2026
-
[32]
V oyager: An open-ended embodied agent with large language models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
Pith/arXiv arXiv 2023
-
[33]
Skillact: Using skill abstractions improves llm agents
Anthony Zhe Liu, Jongwook Choi, Sungryull Sohn, Yao Fu, Jaekyeom Kim, Dong-Ki Kim, Xinhe Wang, Jaewon Yoo, and Honglak Lee. Skillact: Using skill abstractions improves llm agents. InICML 2024 Workshop on LLMs and Cognition, 2024. 12
2024
-
[34]
Inducing programmatic skills for agentic tasks.arXiv preprint arXiv:2504.06821, 2025
Zora Zhiruo Wang, Apurva Gandhi, Graham Neubig, and Daniel Fried. Inducing programmatic skills for agentic tasks.arXiv preprint arXiv:2504.06821, 2025
arXiv 2025
-
[35]
Agent skills from the perspective of procedural memory: A survey.Authorea Preprints, 2026
Yaxiong Wu and Yongyue Zhang. Agent skills from the perspective of procedural memory: A survey.Authorea Preprints, 2026
2026
-
[36]
Xing Zhang, Guanghui Wang, Yanwei Cui, Wei Qiu, Ziyuan Li, Bing Zhu, and Peiyang He. Experience compression spectrum: Unifying memory, skills, and rules in llm agents.arXiv preprint arXiv:2604.15877, 2026
Pith/arXiv arXiv 2026
-
[37]
Shuzhen Bi, Mengsong Wu, Hao Hao, Keqian Li, Wentao Liu, Siyu Song, Hongbo Zhao, and Aimin Zhou. Automating skill acquisition through large-scale mining of open-source agentic repositories: A framework for multi-agent procedural knowledge extraction.arXiv preprint arXiv:2603.11808, 2026
arXiv 2026
-
[38]
Shuaike Shen, Wenduo Cheng, Mingqian Ma, Alistair Turcan, Martin Jinye Zhang, and Jian Ma. Skillfoundry: Building self-evolving agent skill libraries from heterogeneous scientific resources.arXiv preprint arXiv:2604.03964, 2026
Pith/arXiv arXiv 2026
-
[39]
Autoskill: Experience-driven lifelong learning via skill self-evolution
Yutao Yang, Junsong Li, Qianjun Pan, Bihao Zhan, Yuxuan Cai, Lin Du, Jie Zhou, Kai Chen, Qin Chen, Xin Li, et al. Autoskill: Experience-driven lifelong learning via skill self-evolution. arXiv preprint arXiv:2603.01145, 2026
arXiv 2026
-
[40]
Jingwei Ni, Yihao Liu, Xinpeng Liu, Yutao Sun, Mengyu Zhou, Pengyu Cheng, Dexin Wang, Xiaoxi Jiang, and Guanjun Jiang. Trace2skill: Distill trajectory-local lessons into transferable agent skills.arXiv preprint arXiv:2603.25158, 2026
Pith/arXiv arXiv 2026
-
[41]
Jiongxiao Wang, Qiaojing Yan, Yawei Wang, Yijun Tian, Soumya Smruti Mishra, Zhichao Xu, Megha Gandhi, Panpan Xu, and Lin Lee Cheong. Reinforcement learning for self-improving agent with skill library.arXiv preprint arXiv:2512.17102, 2025
Pith/arXiv arXiv 2025
-
[42]
Yu Li, Rui Miao, Zhengling Qi, and Tian Lan. Arise: Agent reasoning with intrinsic skill evolution in hierarchical reinforcement learning.arXiv preprint arXiv:2603.16060, 2026
arXiv 2026
-
[43]
Hanrong Zhang, Shicheng Fan, Henry Peng Zou, Yankai Chen, Zhenting Wang, Jiayu Zhou, Chengze Li, Wei-Chieh Huang, Yifei Yao, Kening Zheng, et al. Evoskills: Self-evolving agent skills via co-evolutionary verification.arXiv preprint arXiv:2604.01687, 2026
Pith/arXiv arXiv 2026
-
[44]
Skillclaw: Let skills evolve collectively with agentic evolver.arXiv preprint arXiv:2604.08377, 2026
Ziyu Ma, Shidong Yang, Yuxiang Ji, Xucong Wang, Yong Wang, Yiming Hu, Tongwen Huang, and Xiangxiang Chu. Skillclaw: Let skills evolve collectively with agentic evolver.arXiv preprint arXiv:2604.08377, 2026
Pith/arXiv arXiv 2026
-
[45]
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, et al. Skillsbench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint arXiv:2602.12670, 2026
Pith/arXiv arXiv 2026
-
[46]
Shanshan Zhong, Yi Lu, Jingjie Ning, Yibing Wan, Lihan Feng, Yuyi Ao, Leonardo FR Ribeiro, Markus Dreyer, Sean Ammirati, and Chenyan Xiong. Skilllearnbench: Benchmarking continual learning methods for agent skill generation on real-world tasks.arXiv preprint arXiv:2604.20087, 2026
Pith/arXiv arXiv 2026
-
[47]
Yujian Liu, Jiabao Ji, Li An, Tommi Jaakkola, Yang Zhang, and Shiyu Chang. How well do agentic skills work in the wild: Benchmarking llm skill usage in realistic settings.arXiv preprint arXiv:2604.04323, 2026
Pith/arXiv arXiv 2026
-
[48]
Skilltester: Benchmarking utility and security of agent skills.arXiv preprint arXiv:2603.28815, 2026
Leye Wang, Zixing Wang, and Anjie Xu. Skilltester: Benchmarking utility and security of agent skills.arXiv preprint arXiv:2603.28815, 2026
arXiv 2026
-
[49]
Ziao Zhang, Kou Shi, Shiting Huang, Avery Nie, Yu Zeng, Yiming Zhao, Zhen Fang, Qishen Su, Haibo Qiu, Wei Yang, et al. Skillflow: Benchmarking lifelong skill discovery and evolution for autonomous agents.arXiv preprint arXiv:2604.17308, 2026
Pith/arXiv arXiv 2026
-
[50]
Welcome to the era of experience.Google AI, 1:11, 2025
David Silver and Richard S Sutton. Welcome to the era of experience.Google AI, 1:11, 2025. 13
2025
-
[51]
Pengfei Du. Memory for autonomous llm agents: Mechanisms, evaluation, and emerging frontiers.arXiv preprint arXiv:2603.07670, 2026
arXiv 2026
-
[52]
Memento: Fine-tuning llm agents without fine-tuning llms.arXiv preprint arXiv:2508.16153, 2025
Huichi Zhou, Yihang Chen, Siyuan Guo, Xue Yan, Kin Hei Lee, Zihan Wang, Ka Yiu Lee, Guchun Zhang, Kun Shao, Linyi Yang, et al. Memento: Fine-tuning llm agents without fine-tuning llms.arXiv preprint arXiv:2508.16153, 2025
arXiv 2025
-
[53]
Scaling agent learning via experience synthesis.arXiv preprint arXiv:2511.03773, 2025
Zhaorun Chen, Zhuokai Zhao, Kai Zhang, Bo Liu, Qi Qi, Yifan Wu, Tarun Kalluri, Sara Cao, Yuanhao Xiong, Haibo Tong, et al. Scaling agent learning via experience synthesis.arXiv preprint arXiv:2511.03773, 2025
arXiv 2025
-
[54]
Agent learning via early experience.arXiv preprint arXiv:2510.08558, 2025
Kai Zhang, Xiangchao Chen, Bo Liu, Tianci Xue, Zeyi Liao, Zhihan Liu, Xiyao Wang, Yuting Ning, Zhaorun Chen, Xiaohan Fu, et al. Agent learning via early experience.arXiv preprint arXiv:2510.08558, 2025
Pith/arXiv arXiv 2025
-
[55]
Shengtao Zhang, Jiaqian Wang, Ruiwen Zhou, Junwei Liao, Yuchen Feng, Zhuo Li, Yujie Zheng, Weinan Zhang, Ying Wen, Zhiyu Li, et al. Memrl: Self-evolving agents via runtime reinforcement learning on episodic memory.arXiv preprint arXiv:2601.03192, 2026
Pith/arXiv arXiv 2026
-
[56]
Trajectory-informed memory generation for self-improving agent systems
Gaodan Fang, Vatche Isahagian, KR Jayaram, Ritesh Kumar, Vinod Muthusamy, Punleuk Oum, and Gegi Thomas. Trajectory-informed memory generation for self-improving agent systems. arXiv preprint arXiv:2603.10600, 2026
arXiv 2026
-
[57]
Siru Ouyang, Jun Yan, I Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T Le, Samira Daruki, Xiangru Tang, et al. Reasoningbank: Scaling agent self-evolving with reasoning memory.arXiv preprint arXiv:2509.25140, 2025
Pith/arXiv arXiv 2025
-
[58]
R2d2: Remembering, replaying and dynamic decision making with a reflective agentic memory
Tenghao Huang, Kinjal Basu, Ibrahim Abdelaziz, Pavan Kapanipathi, Jonathan May, and Muhao Chen. R2d2: Remembering, replaying and dynamic decision making with a reflective agentic memory. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 30318–30330, 2025
2025
-
[59]
Dynamic cheatsheet: Test-time learning with adaptive memory
Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. Dynamic cheatsheet: Test-time learning with adaptive memory. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7080–7106, 2026
2026
-
[60]
Zhicheng Cai, Xinyuan Guo, Yu Pei, Jiangtao Feng, Jinsong Su, Jiangjie Chen, Ya-Qin Zhang, Wei-Ying Ma, Mingxuan Wang, and Hao Zhou. Flex: Continuous agent evolution via forward learning from experience.arXiv preprint arXiv:2511.06449, 2025
arXiv 2025
-
[61]
Jenny Zhang, Shengran Hu, Cong Lu, Robert Lange, and Jeff Clune. Darwin godel machine: Open-ended evolution of self-improving agents.arXiv preprint arXiv:2505.22954, 2025
Pith/arXiv arXiv 2025
-
[62]
Dongge Han, Camille Couturier, Daniel Madrigal Diaz, Xuchao Zhang, Victor Rühle, and Saravan Rajmohan. Legomem: Modular procedural memory for multi-agent llm systems for workflow automation.arXiv preprint arXiv:2510.04851, 2025
arXiv 2025
-
[63]
Xiangru Tang, Tianrui Qin, Tianhao Peng, Ziyang Zhou, Daniel Shao, Tingting Du, Xinming Wei, Peng Xia, Fang Wu, He Zhu, et al. Agent kb: Leveraging cross-domain experience for agentic problem solving.arXiv preprint arXiv:2507.06229, 2025
arXiv 2025
-
[64]
G-memory: Tracing hierarchical memory for multi-agent systems.arXiv preprint arXiv:2506.07398, 2025
Guibin Zhang, Muxin Fu, Guancheng Wan, Miao Yu, Kun Wang, and Shuicheng Yan. G-memory: Tracing hierarchical memory for multi-agent systems.arXiv preprint arXiv:2506.07398, 2025
arXiv 2025
-
[65]
Rong Wu, Xiaoman Wang, Jianbiao Mei, Pinlong Cai, Daocheng Fu, Cheng Yang, Licheng Wen, Xuemeng Yang, Yufan Shen, Yuxin Wang, et al. Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079, 2025
Pith/arXiv arXiv 2025
-
[66]
Chang Yang, Chuang Zhou, Yilin Xiao, Su Dong, Luyao Zhuang, Yujing Zhang, Zhu Wang, Zijin Hong, Zheng Yuan, Zhishang Xiang, et al. Graph-based agent memory: Taxonomy, techniques, and applications.arXiv preprint arXiv:2602.05665, 2026. 14
arXiv 2026
-
[67]
Memevolve: Meta-evolution of agent memory systems.arXiv preprint arXiv:2512.18746, 2025
Guibin Zhang, Haotian Ren, Chong Zhan, Zhenhong Zhou, Junhao Wang, He Zhu, Wangchun- shu Zhou, and Shuicheng Yan. Memevolve: Meta-evolution of agent memory systems.arXiv preprint arXiv:2512.18746, 2025
Pith/arXiv arXiv 2025
-
[68]
Agentevolver: Towards efficient self-evolving agent system.arXiv preprint arXiv:2511.10395, 2025
Yunpeng Zhai, Shuchang Tao, Cheng Chen, Anni Zou, Ziqian Chen, Qingxu Fu, Shinji Mai, Li Yu, Jiaji Deng, Zouying Cao, et al. Agentevolver: Towards efficient self-evolving agent system.arXiv preprint arXiv:2511.10395, 2025
arXiv 2025
-
[69]
Yuxuan Cai, Yipeng Hao, Jie Zhou, Hang Yan, Zhikai Lei, Rui Zhen, Zhenhua Han, Yutao Yang, Junsong Li, Qianjun Pan, et al. Building self-evolving agents via experience-driven lifelong learning: A framework and benchmark.arXiv preprint arXiv:2508.19005, 2025
arXiv 2025
-
[70]
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z Pan, et al. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.arXiv preprint arXiv:2508.19828, 2025
Pith/arXiv arXiv 2025
-
[71]
Rajat Khanda, Mohammad Baqar Sambuddha Chakrabarti, and Satyasaran Changdar. Adaptive memory crystallization for autonomous ai agent learning in dynamic environments.arXiv preprint arXiv:2604.13085, 2026
Pith/arXiv arXiv 2026
-
[72]
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768, 2020
Pith/arXiv arXiv 2010
-
[73]
Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
2022
-
[74]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[75]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[76]
Xinyu Zhu, Mengzhou Xia, Zhepei Wei, Wei-Lin Chen, Danqi Chen, and Yu Meng. The surpris- ing effectiveness of negative reinforcement in llm reasoning.arXiv preprint arXiv:2506.01347, 2025
arXiv 2025
-
[77]
Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
2019
-
[78]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, 2017
2017
-
[79]
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pages 9802–9822, 2023
2023
-
[80]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.