Beyond Consistency: Preserving Temporal Structure in Zero-Shot Video Editing
Pith reviewed 2026-06-27 18:47 UTC · model grok-4.3
The pith
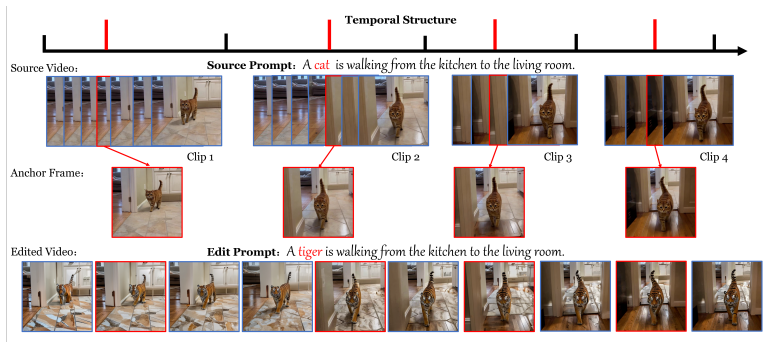
Zero-shot video editing preserves original temporal structure by partitioning into semantic clips and selecting anchor frames.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
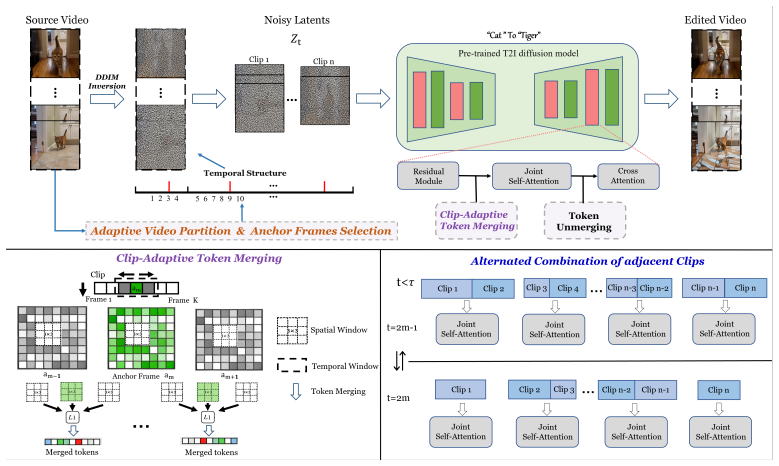
The central claim is that by adaptively partitioning the video into semantically distinct clips based on feature similarity and selecting a representative anchor frame for each clip, enhanced by clip-adaptive token merging leveraging the anchor's semantic dominance and an alternating combination strategy for inter-clip transitions, zero-shot video editing can preserve the source video's temporal structure for the first time.
What carries the argument
Adaptive semantic clip partitioning with anchor frame selection and clip-adaptive token merging, which uses the anchor to stabilize editing within clips.
If this is right
- Long videos with complex semantic variations can be edited while keeping narrative coherence and avoiding semantic ambiguity.
- Edited outputs achieve higher fidelity by balancing intra-clip stability and inter-clip seamless transitions.
- Computational efficiency is improved through the token merging strategy without sacrificing structure preservation.
- State-of-the-art results are set for zero-shot video editing fidelity.
Where Pith is reading between the lines
- This approach might apply to preserving structure in other media like audio or 3D animations edited via diffusion.
- Future work could test if the partitioning method works equally well on videos with gradual vs abrupt semantic changes.
- Integrating this with different pre-trained models could show if the structure preservation is model-agnostic.
Load-bearing premise
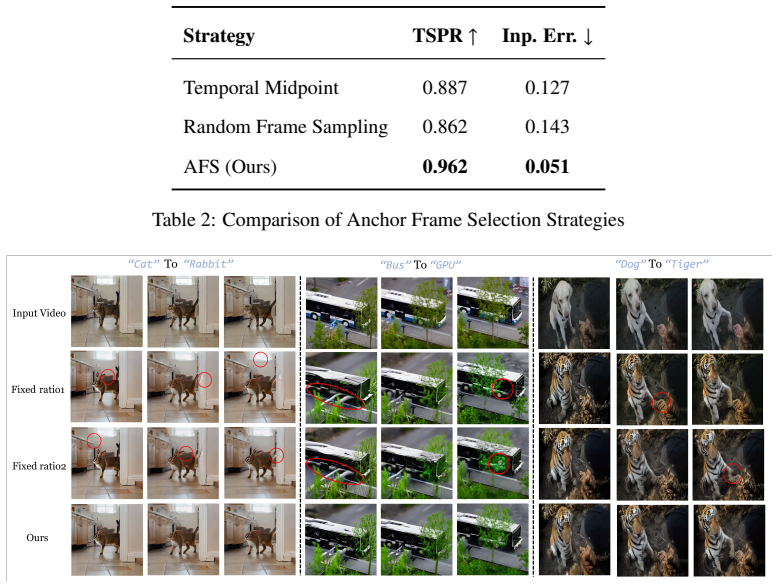
Partitioning the video based on feature similarity and selecting representative anchor frames will accurately capture and preserve the high-level narrative and semantic flow of the original video.
What would settle it
A comparison experiment where edited videos are rated for narrative coherence and semantic flow preservation on a set of long videos with varying complexity, showing no improvement over baseline methods.
Figures




read the original abstract
Existing zero-shot video editing methods rely on pre-trained diffusion models, successfully achieving spatial control and basic temporal consistency but fundamentally fail to preserve the video's original temporal structure.This distinction is critical: temporal consistency ensures visual smoothness, but temporal structure dictates the video's high-level narrative, rhythm, and semantic flow. Without this preservation, the edited output, especially for long videos with complex semantic variations, becomes narratively incoherent and semantically ambiguous. To address this limitation, we introduce a novel zero-shot editing approach that, for the first time, explicitly focuses on preserving the source video's temporal structure. We achieve this by adaptively partitioning the video into semantically distinct clips based on feature similarity and selecting a representative anchor frame for each clip. To enhance both intra-clip fidelity and computational efficiency, we design a clip-adaptive token merging strategy which leverages the anchor's semantic dominance to stabilize the editing. Furthermore, we employ an alternating combination strategy that ensures seamless inter-clip transitions while maintaining semantic distinction. Extensive experiments demonstrate that our method achieves state-of-the-art results, successfully balancing the preservation of original temporal structure with computational efficiency, and setting a new benchmark for zero-shot video editing fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that prior zero-shot video editing methods achieve spatial control and temporal consistency but fail to preserve temporal structure (high-level narrative, rhythm, and semantic flow), leading to incoherent outputs on long videos. It introduces an approach that adaptively partitions the input video into clips via feature similarity, selects representative anchor frames per clip, applies clip-adaptive token merging that exploits anchor dominance, and uses an alternating combination strategy for inter-clip transitions. The authors assert that this yields state-of-the-art fidelity while remaining computationally efficient.
Significance. If the central claim holds, the work would usefully distinguish temporal consistency from structure preservation and supply a practical zero-shot pipeline for semantically complex videos. The efficiency focus via token merging is a concrete engineering contribution. However, the significance is limited by the absence of any reported validation that the feature-similarity partitions align with narrative boundaries rather than low-level appearance.
major comments (2)
- [Abstract] Abstract: the central claim that 'adaptively partitioning the video into semantically distinct clips based on feature similarity' preserves high-level narrative and semantic flow is load-bearing yet unsupported. No ablation, correlation with ground-truth narrative boundaries, or human study is described to show that standard embeddings (CLIP, DINO, etc.) produce partitions that respect story-level semantics rather than visual similarity; without this, the distinction from prior consistency-only methods cannot be verified.
- [Abstract] Abstract and experimental claims: the assertion of 'state-of-the-art results' and 'setting a new benchmark' is made without any reported metrics, baselines, datasets, or quantitative tables. This absence prevents assessment of whether the method actually balances structure preservation against efficiency or outperforms existing approaches on the claimed dimensions.
minor comments (1)
- [Abstract] The abstract contains a run-on sentence in the second paragraph that reduces readability; consider splitting for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, acknowledging where additional validation is needed and outlining planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'adaptively partitioning the video into semantically distinct clips based on feature similarity' preserves high-level narrative and semantic flow is load-bearing yet unsupported. No ablation, correlation with ground-truth narrative boundaries, or human study is described to show that standard embeddings (CLIP, DINO, etc.) produce partitions that respect story-level semantics rather than visual similarity; without this, the distinction from prior consistency-only methods cannot be verified.
Authors: We agree that validating the semantic alignment of feature-similarity partitions is essential to support the central claim. The manuscript provides qualitative demonstrations and efficiency comparisons, but lacks the requested ablations and human evaluation. We will add an ablation study evaluating CLIP, DINO, and other embeddings on partition quality, plus a human study assessing narrative alignment. Ground-truth narrative boundary annotations are unavailable in standard datasets, precluding direct correlation metrics, but the human study will provide perceptual validation of the distinction from consistency-only methods. revision: yes
-
Referee: [Abstract] Abstract and experimental claims: the assertion of 'state-of-the-art results' and 'setting a new benchmark' is made without any reported metrics, baselines, datasets, or quantitative tables. This absence prevents assessment of whether the method actually balances structure preservation against efficiency or outperforms existing approaches on the claimed dimensions.
Authors: The abstract summarizes the outcomes, while the experiments section of the manuscript reports quantitative metrics, baseline comparisons against prior zero-shot methods, datasets used, and tables demonstrating SOTA fidelity and efficiency. To address the concern, we will revise the abstract to explicitly reference the key metrics, baselines, and datasets supporting the SOTA claim, allowing readers to evaluate the balance between structure preservation and efficiency directly from the abstract. revision: yes
Circularity Check
No circularity; method components are independently defined
full rationale
The paper introduces a new zero-shot video editing pipeline consisting of adaptive partitioning by feature similarity, anchor-frame selection per clip, clip-adaptive token merging, and an alternating inter-clip combination strategy. None of these steps are shown to reduce by construction to the inputs via self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. The abstract and described approach present the techniques as novel design choices whose claimed benefit (preservation of temporal structure) is asserted on the basis of the design itself rather than tautological equivalence. No equations or derivation steps are provided that equate outputs to inputs by construction. This is the normal case of an independent methodological contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sohl-Dickstein, E
J. Sohl-Dickstein, E. A. Weiss, N. Maheswaranathan, S. Ganguli, Deep unsupervised learning using nonequilibrium thermodynamics, in: ICML, 2015, pp. 2256–2265
2015
-
[2]
J. Ho, A. Jain, P. Abbeel, Denoising diffusion probabilistic models, in: NeurIPS, 2020, pp. 6840–6851
2020
-
[3]
A. Q. Nichol, P. Dhariwal, Improved denoising diffusion probabilistic mod- els, in: ICML, 2021, pp. 8162–8171
2021
-
[4]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B. Ommer, High- resolution image synthesis with latent diffusion models, in: CVPR, 2022, pp. 10674–10685
2022
-
[5]
T. Zhen, J. Cao, X. Sun, J. Pan, Z. Ji, Y . Pang, Token-aware and step-aware acceleration for stable diffusion, Pattern Recognition (2025) 111479. 29
2025
-
[6]
Dhariwal, A
P. Dhariwal, A. Q. Nichol, Diffusion models beat gans on image synthesis, in: NeurIPS, 2021, pp. 8780–8794
2021
-
[7]
Z. Chen, Z. Zhao, Y . Luo, Y . Li, X. Tao, Z. Huang, Fastedit: fast text- guided single-image editing via semantic-aware diffusion fine-tuning, Pat- tern Recognition (2026) 112583
2026
-
[8]
Q. Liu, X. Fu, H. Zhang, C. Long, J. Han, C. Moreira, X. Ning, X. Bai, Hy- brideditdif: Text and exemplar guided image editing with diffusion models, Pattern Recognition (2026) 112510
2026
-
[9]
C. Xiao, Q. Yang, X. Xu, J. Zhang, F. Zhou, C. Zhang, Where you edit is what you get: Text-guided image editing with region-based attention, Pattern Recognition (2023) 109458
2023
-
[10]
Ian Chan, H
W. Ian Chan, H. Santo, Y . Matsushita, F. Okura, Instance-wise distribu- tion control of text-to-image diffusion models, Pattern Recognition (2026) 112614
2026
-
[11]
Croitoru, V
F. Croitoru, V . Hondru, R. T. Ionescu, M. Shah, Diffusion models in vision: A survey, IEEE Trans. Pattern Anal. Mach. Intell. (2023) 10850–10869
2023
-
[12]
J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, D. J. Fleet, Video diffusion models, in: NeurIPS, 2022, pp. 8633–8646
2022
-
[13]
J. Ho, W. Chan, C. Saharia, J. Whang, R. Gao, A. Gritsenko, D. P. Kingma, B. Poole, M. Norouzi, D. J. Fleet, et al., Imagen video: High definition video generation with diffusion models, arXiv preprint arXiv:2210.02303 (2022). 30
Pith/arXiv arXiv 2022
-
[14]
Saharia, W
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, S. K. S. Ghasemipour, R. G. Lopes, B. K. Ayan, T. Salimans, J. Ho, D. J. Fleet, M. Norouzi, Photorealistic text-to-image diffusion models with deep lan- guage understanding, in: NeurIPS, 2022, pp. 36479–36494
2022
-
[15]
J. Z. Wu, Y . Ge, X. Wang, S. W. Lei, Y . Gu, Y . Shi, W. Hsu, Y . Shan, X. Qie, M. Z. Shou, Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation, in: ICCV, 2023, pp. 7589–7599
2023
-
[16]
S. Liu, Y . Zhang, W. Li, Z. Lin, J. Jia, Video-p2p: Video editing with cross- attention control, in: CVPR, 2024, pp. 8599–8608
2024
-
[17]
Zhang, B
Z. Zhang, B. Li, X. Nie, C. Han, T. Guo, L. Liu, Towards consistent video editing with text-to-image diffusion models, in: NeurIPS, 2023, pp. 58508– 58519
2023
-
[18]
C. Qi, X. Cun, Y . Zhang, C. Lei, X. Wang, Y . Shan, Q. Chen, Fatezero: Fusing attentions for zero-shot text-based video editing, in: ICCV, 2023, pp. 15886–15896
2023
-
[19]
Ceylan, C
D. Ceylan, C. P. Huang, N. J. Mitra, Pix2video: Video editing using image diffusion, in: ICCV, 2023, pp. 23149–23160
2023
-
[20]
Tumanyan, M
N. Tumanyan, M. Geyer, S. Bagon, T. Dekel, Plug-and-play diffusion features for text-driven image-to-image translation, in: CVPR, 2023, pp. 1921–1930
2023
-
[21]
Zhang, A
L. Zhang, A. Rao, M. Agrawala, Adding conditional control to text-to- image diffusion models, in: ICCV, 2023, pp. 3813–3824. 31
2023
-
[22]
Geyer, O
M. Geyer, O. Bar-Tal, S. Bagon, T. Dekel, Tokenflow: Consistent diffusion features for consistent video editing, in: ICLR, 2024, pp. 20637–20650
2024
-
[23]
X. Li, C. Ma, X. Yang, M. Yang, Vidtome: Video token merging for zero- shot video editing, in: CVPR, 2024, pp. 7486–7495
2024
-
[24]
L. Tang, M. Jia, Q. Wang, C. P. Phoo, B. Hariharan, Emergent correspon- dence from image diffusion, in: NeurIPS, 2023, pp. 1363–1389
2023
-
[25]
Bolya, C
D. Bolya, C. Fu, X. Dai, P. Zhang, C. Feichtenhofer, J. Hoffman, Token merging: Your vit but faster, in: ICLR, 2023, pp. 1498–1518
2023
-
[26]
Hertz, R
A. Hertz, R. Mokady, J. Tenenbaum, K. Aberman, Y . Pritch, D. Cohen-Or, Prompt-to-prompt image editing with cross-attention control, in: ICLR, 2023, pp. 14369–14388
2023
-
[27]
Epstein, A
D. Epstein, A. Jabri, B. Poole, A. A. Efros, A. Holynski, Diffusion self- guidance for controllable image generation, in: NeurIPS, 2023, pp. 16222– 16239
2023
-
[28]
Parmar, K
G. Parmar, K. K. Singh, R. Zhang, Y . Li, J. Lu, J. Zhu, Zero-shot image-to- image translation, in: ACM SIGGRAPH, 2023, pp. 11:1–11:11
2023
-
[29]
Mokady, A
R. Mokady, A. Hertz, K. Aberman, Y . Pritch, D. Cohen-Or, Null-text in- version for editing real images using guided diffusion models, in: CVPR, 2023, pp. 6038–6047
2023
-
[30]
Khachatryan, A
L. Khachatryan, A. Movsisyan, V . Tadevosyan, R. Henschel, Z. Wang, S. Navasardyan, H. Shi, Text2video-zero: Text-to-image diffusion models are zero-shot video generators, in: ICCV, 2023, pp. 15908–15918. 32
2023
-
[31]
S. Yang, Y . Zhou, Z. Liu, C. C. Loy, Rerender A video: Zero-shot text- guided video-to-video translation, in: ACM SIGGRAPH, 2023, pp. 95:1– 95:11
2023
-
[32]
S. Yang, Y . Zhou, Z. Liu, C. C. Loy, Fresco: Spatial-temporal correspon- dence for zero-shot video translation, in: CVPR, 2024, pp. 8703–8712
2024
-
[33]
Y . Cong, M. Xu, C. Simon, S. Chen, J. Ren, Y . Xie, J. Pérez-Rúa, B. Rosen- hahn, T. Xiang, S. He, FLATTEN: optical flow-guided attention for consis- tent text-to-video editing, in: ICLR, 2024, pp. 8826–8847
2024
-
[34]
Cohen, V
N. Cohen, V . Kulikov, M. Kleiner, I. Huberman-Spiegelglas, T. Michaeli, Slicedit: Zero-shot video editing with text-to-image diffusion models using spatio-temporal slices, in: ICML, 2024, pp. 9109–9137
2024
-
[35]
Blattmann, R
A. Blattmann, R. Rombach, H. Ling, T. Dockhorn, S. W. Kim, S. Fidler, K. Kreis, Align your latents: High-resolution video synthesis with latent diffusion models, in: CVPR, 2023, pp. 22563–22575
2023
-
[36]
D. P. Kingma, M. Welling, Auto-encoding variational bayes, arXiv preprint arXiv:1312.6114 (2013)
Pith/arXiv arXiv 2013
-
[37]
J. Song, C. Meng, S. Ermon, Denoising diffusion implicit models, in: ICLR, 2021, pp. 14205–14225
2021
-
[38]
A. Q. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. McGrew, I. Sutskever, M. Chen, GLIDE: towards photorealistic image generation and editing with text-guided diffusion models, in: ICML, 2022, pp. 16784– 16804. 33
2022
- [39]
-
[40]
W. Wang, Y . Jiang, K. Xie, Z. Liu, H. Chen, Y . Cao, X. Wang, C. Shen, Zero-shot video editing using off-the-shelf image diffusion models, arXiv preprint arXiv:2303.17599 (2023)
arXiv 2023
-
[41]
X. Ju, Y . Gao, Z. Zhang, Z. Yuan, X. Wang, A. Zeng, Y . Xiong, Q. Xu, Y . Shan, Miradata: A large-scale video dataset with long durations and structured captions, in: NeurIPS, 2024, pp. 48955–48970
2024
-
[42]
P. P. Ray, Chatgpt: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope, Internet of Things and Cyber-Physical Systems (2023) 121–154
2023
-
[43]
Jiang, D
H. Jiang, D. Sun, V . Jampani, M. Yang, E. G. Learned-Miller, J. Kautz, Super slomo: High quality estimation of multiple intermediate frames for video interpolation, in: CVPR, 2018, pp. 9000–9008
2018
-
[44]
Z. Wang, A. C. Bovik, H. R. Sheikh, E. P. Simoncelli, Image quality as- sessment: from error visibility to structural similarity, IEEE Trans. Image Process. (2004) 600–612
2004
-
[45]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, O. Wang, The unreasonable effectiveness of deep features as a perceptual metric, in: CVPR, 2018, pp. 586–595
2018
-
[46]
Huang, Y
Z. Huang, Y . He, J. Yu, F. Zhang, C. Si, Y . Jiang, Y . Zhang, T. Wu, Q. Jin, N. Chanpaisit, Y . Wang, X. Chen, L. Wang, D. Lin, Y . Qiao, Z. Liu, 34 Vbench: Comprehensive benchmark suite for video generative models, in: CVPR, 2024, pp. 21807–21818
2024
-
[47]
Zhang, Y
Y . Zhang, Y . Wei, D. Jiang, X. Zhang, W. Zuo, Q. Tian, Controlvideo: Training-free controllable text-to-video generation, in: ICLR, 2024, pp. 27266–27287
2024
-
[48]
O. Kara, B. Kurtkaya, H. Yesiltepe, J. M. Rehg, P. Yanardag, RA VE: ran- domized noise shuffling for fast and consistent video editing with diffusion models, in: CVPR, 2024, pp. 6507–6516
2024
-
[49]
X. Yang, L. Zhu, H. Fan, Y . Yang, Videograin: Modulating space-time at- tention for multi-grained video editing, in: ICLR, 2025, pp. 79063–79082. 35
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.