DifferSeg: Towards Diverse Multimodal Binary Segmentation via Differential Perception and Frequency Guidance
Pith reviewed 2026-06-27 17:29 UTC · model grok-4.3
The pith
DifferSeg uses differential operators to align multimodal features and frequency guidance to balance representations for improved binary segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
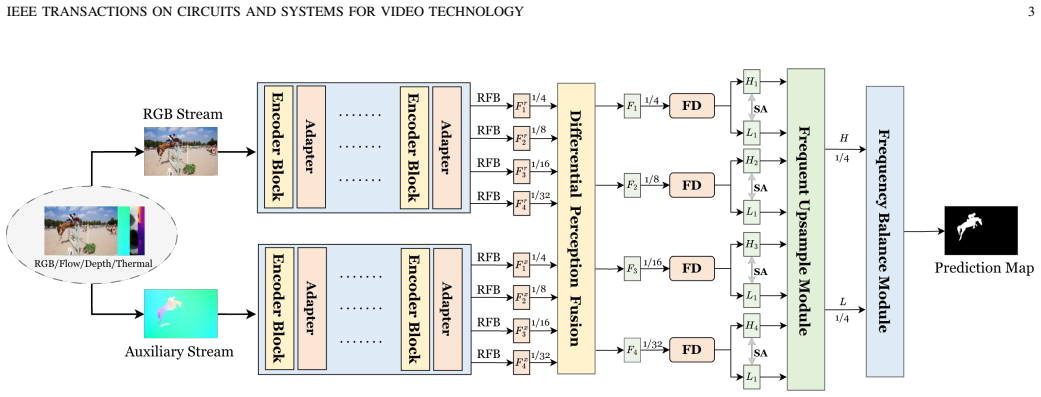
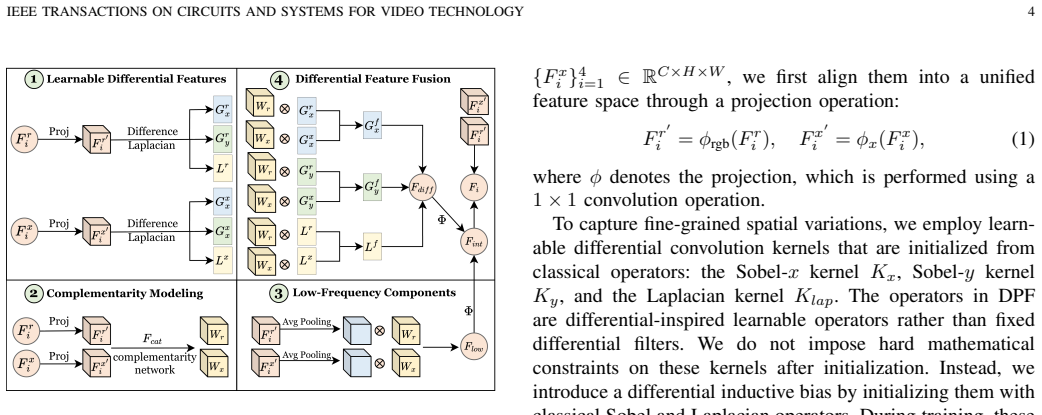
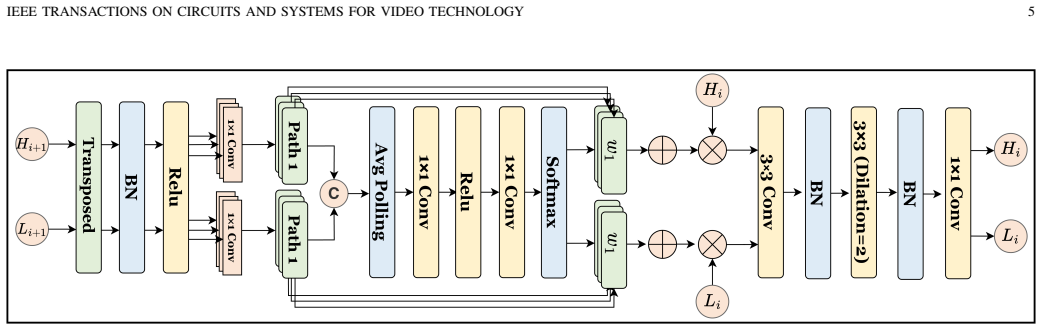
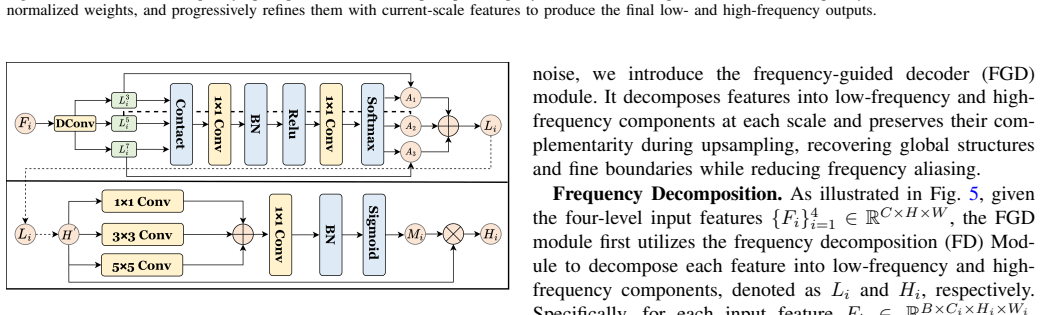
DifferSeg addresses the lack of adaptive mechanisms for modality discrepancies and the absence of efficient decoding for high- and low-frequency balance by employing learnable differential operators in the DPF module for adaptive alignment and residual fusion, and a FGD that builds cross-frequency interactions and multi-path upsampling for consistency in detailed structures and semantics.
What carries the argument
The differential perception fusion (DPF) module using learnable differential operators for adaptive multimodal feature alignment and residual fusion, combined with the frequency-guided decoder (FGD) for cross-frequency interactions and multi-path upsampling.
If this is right
- DifferSeg generalizes to 18 downstream tasks in both natural and medical modalities without task-specific changes.
- It surpasses 67 state-of-the-art methods across 29 public datasets.
- Binary segmentation benefits from reduced modality mismatch and better boundary recovery with noise suppression.
- The approach mitigates fusion redundancy in multimodal feature integration.
Where Pith is reading between the lines
- The designs may apply to other vision tasks involving multiple data sources, such as video segmentation.
- Frequency balancing could improve performance in single-modality segmentation where high-frequency details are lost.
- Adaptive alignment might reduce reliance on extensive data augmentation for modality differences.
Load-bearing premise
The differential perception fusion module and frequency-guided decoder provide adaptive alignment and balanced frequency representations that generalize beyond the specific training setups and datasets used.
What would settle it
Observing that DifferSeg does not surpass existing methods on a held-out multimodal dataset from an unseen domain like satellite imagery would challenge the generalization claim.
Figures






read the original abstract
In many binary segmentation tasks, most multimodal methods rely on fixed feature concatenation for cross-modal interaction and straightforward decoder designs dominated by low-frequency semantics. %ToDO: % However, they ignore two key challenges: one is the lack of an adaptive mechanism to handle modality discrepancies and complementarity, and the other is the absence of an efficient decoding strategy to balance both high- and low-frequency representations. % In this work, we propose a simple yet general multimodal binary segmentation framework, termed DifferSeg, to address both problems simultaneously. With the help of the differential perception fusion (DPF) module, DifferSeg employs learnable differential operators to adaptively align multimodal features and enhance their complementarity through residual fusion, effectively mitigating modality mismatch and fusion redundancy. % In addition, we design a frequency-guided decoder (FGD) that builds cross-frequency interactions and multi-path upsampling to maintain consistency between detailed high-frequency structures and semantic low-frequency representations, ensuring fine-grained boundary recovery and noise suppression. % Benefiting from these designs, DifferSeg can be easily generalized to diverse binary segmentation tasks, including both natural and medical modalities. Without bells and whistles, it consistently surpasses 67 state-of-the-art methods across 29 public datasets involving 18 downstream tasks, demonstrating superior generalization and segmentation accuracy.Code and pretrained models will be available at the Link.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DifferSeg, a multimodal binary segmentation framework featuring a Differential Perception Fusion (DPF) module that uses learnable differential operators for adaptive cross-modal alignment and residual fusion, plus a Frequency-Guided Decoder (FGD) that performs cross-frequency interactions and multi-path upsampling to balance high- and low-frequency content. It claims easy generalization across natural and medical modalities and consistent outperformance of 67 SOTA methods on 29 public datasets spanning 18 downstream tasks, with code and pretrained models to be released.
Significance. If the reported results hold under the stated evaluation protocol, the work supplies a compact, general-purpose architecture that directly targets modality mismatch and frequency imbalance in binary segmentation. The explicit promise of code and model release is a concrete strength that would aid reproducibility and follow-on work.
minor comments (3)
- [Abstract] Abstract: the headline claim of surpassing 67 methods across 29 datasets is stated without any mention of evaluation metrics, statistical testing, or dataset characteristics; adding one sentence summarizing the primary metric and protocol would improve clarity.
- [Method] The description of the DPF module refers to 'learnable differential operators' without an explicit equation or pseudocode for the operator definition; a short equation block would remove ambiguity for readers attempting re-implementation.
- [Experiments] Figure captions and axis labels in the qualitative results could be expanded to indicate which modality pair and task each row corresponds to, aiding quick cross-reference with the quantitative tables.
Simulated Author's Rebuttal
We thank the referee for the thorough review and the positive recommendation for minor revision. We appreciate the recognition of the framework's potential for generalization across modalities and the value of the promised code release. Since no specific major comments were raised, we have no points requiring detailed rebuttal at this stage.
Circularity Check
No significant circularity
full rationale
The paper presents an empirical neural architecture (DifferSeg with DPF and FGD modules) whose central claims rest on experimental outperformance across 29 datasets rather than any mathematical derivation, fitted parameters renamed as predictions, or self-citation chains. No equations or load-bearing steps reduce to inputs by construction; the work is self-contained as a standard CV method proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Towards complex backgrounds: A unified difference-aware decoder for binary segmentation,
J. Li, W. He, F. Lu, and H. Zhang, “Towards complex backgrounds: A unified difference-aware decoder for binary segmentation,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[2]
Towards diverse binary segmentation via a simple yet general gated network,
X. Zhao, Y . Pang, L. Zhang, H. Lu, and L. Zhang, “Towards diverse binary segmentation via a simple yet general gated network,”Interna- tional Journal of Computer Vision, vol. 132, no. 10, pp. 4157–4234, 2024
2024
-
[3]
Deep fourier- embedded network for rgb and thermal salient object detection,
P. Lyu, X. Yu, P.-H. Yeung, C. Wu, and J. C. Rajapakse, “Deep fourier- embedded network for rgb and thermal salient object detection,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[4]
Towards unifying saliency transformer for video saliency prediction and detection,
J. Xiong, C. Li, T. Liu, P. Zhang, Y . Huo, W. Huang, and Y . Zha, “Towards unifying saliency transformer for video saliency prediction and detection,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[5]
Camouflaged object detection with adaptive partition and background retrieval,
B. Yin, X. Zhang, L. Liu, M.-M. Cheng, Y . Liu, and Q. Hou, “Camouflaged object detection with adaptive partition and background retrieval,”International Journal of Computer Vision, vol. 133, no. 7, pp. 4877–4893, 2025
2025
-
[6]
Tanet: Tri-aspects network for camouflaged object detection,
J. Jeong, J. Shim, and H. Yoon, “Tanet: Tri-aspects network for camouflaged object detection,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[7]
Enhanced boundary learning for glass-like object segmen- tation,
H. He, X. Li, G. Cheng, J. Shi, Y . Tong, G. Meng, V . Prinet, and L. Weng, “Enhanced boundary learning for glass-like object segmen- tation,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 15 859–15 868
2021
-
[8]
Defocus blur detection via depth distillation,
X. Cun and C.-M. Pun, “Defocus blur detection via depth distillation,” inEuropean conference on computer vision. Springer, 2020, pp. 747– 763
2020
-
[9]
Noise-consistent siamese-diffusion for medical image synthesis and segmentation,
K. Qiu, Z. Gao, Z. Zhou, M. Sun, and Y . Guo, “Noise-consistent siamese-diffusion for medical image synthesis and segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 15 672–15 681
2025
-
[10]
Flownet 2.0: Evolution of optical flow estimation with deep networks,
E. Ilg, N. Mayer, T. Saikia, M. Keuper, A. Dosovitskiy, and T. Brox, “Flownet 2.0: Evolution of optical flow estimation with deep networks,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 2462–2470
2017
-
[11]
Explicit visual prompting for low-level structure segmentations,
W. Liu, X. Shen, C.-M. Pun, and X. Cun, “Explicit visual prompting for low-level structure segmentations,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 434–19 445
2023
-
[12]
Spi- der: A unified framework for context-dependent concept segmentation,
X. Zhao, Y . Pang, W. Ji, B. Sheng, J. Zuo, L. Zhang, and H. Lu, “Spi- der: A unified framework for context-dependent concept segmentation,” arXiv preprint arXiv:2405.01002, 2024
arXiv 2024
-
[13]
Focus: Towards universal foreground segmentation,
Z. You, L. Kong, L. Meng, and Z. Wu, “Focus: Towards universal foreground segmentation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 9, 2025, pp. 9580–9588
2025
-
[14]
Sam2-unet: Segment anything 2 makes strong encoder for natu- ral and medical image segmentation,
X. Xiong, Z. Wu, S. Tan, W. Li, F. Tang, Y . Chen, S. Li, J. Ma, and G. Li, “Sam2-unet: Segment anything 2 makes strong encoder for natu- ral and medical image segmentation,”arXiv preprint arXiv:2408.08870, 2024. IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY 13
arXiv 2024
-
[15]
Tp-seg: Task- prototype framework for unified medical lesion segmentation,
J. Xu, Q. Zhou, D. Zhu, Y . Chen, Y . Yi, and X. Zhao, “Tp-seg: Task- prototype framework for unified medical lesion segmentation,”arXiv preprint arXiv:2604.00684, 2026
arXiv 2026
-
[16]
Samba: A unified mamba-based framework for general salient object detection,
J. He, K. Fu, X. Liu, and Q. Zhao, “Samba: A unified mamba-based framework for general salient object detection,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 25 314–25 324
2025
-
[17]
Hvpnet: A unified bio- inspired network for general salient and camouflaged object detection,
J. Xu, Q. Zhou, Z. Li, Y . Shi, Y . Yi, and J. Yu, “Hvpnet: A unified bio- inspired network for general salient and camouflaged object detection,” Available at SSRN 5637952
-
[18]
Vscode: General visual salient and camouflaged object detection with 2d prompt learning,
Z. Luo, N. Liu, W. Zhao, X. Yang, D. Zhang, D.-P. Fan, F. Khan, and J. Han, “Vscode: General visual salient and camouflaged object detection with 2d prompt learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 17 169–17 180
2024
-
[19]
Detect any mirrors: Boosting learning reliability on large- scale unlabeled data with an iterative data engine,
Z. Xing, L. Liu, Y . Yang, H. Wang, T. Ye, S. Chen, W. Li, G. Liu, and L. Zhu, “Detect any mirrors: Boosting learning reliability on large- scale unlabeled data with an iterative data engine,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 25 476–25 486
2025
-
[20]
Revisiting weak- to-strong consistency in semi-supervised semantic segmentation,
L. Yang, L. Qi, L. Feng, W. Zhang, and Y . Shi, “Revisiting weak- to-strong consistency in semi-supervised semantic segmentation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 7236–7246
2023
-
[21]
Endow sam with keen eyes: Temporal-spatial prompt learning for video camouflaged object detection,
W. Hui, Z. Zhu, S. Zheng, and Y . Zhao, “Endow sam with keen eyes: Temporal-spatial prompt learning for video camouflaged object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 19 058–19 067
2024
-
[22]
Frequency-spatial entanglement learning for camouflaged object detection,
Y . Sun, C. Xu, J. Yang, H. Xuan, and L. Luo, “Frequency-spatial entanglement learning for camouflaged object detection,” pp. 343–360, 2024
2024
-
[23]
Depth-aware concealed crop detection in dense agricultural scenes,
L. Wang, J. Yang, Y . Zhang, F. Wang, and F. Zheng, “Depth-aware concealed crop detection in dense agricultural scenes,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), June 2024, pp. 17 201–17 211
2024
-
[24]
Improving sam for camouflaged object detection via dual stream adapters,
J. Liu, L. Kong, and G. Chen, “Improving sam for camouflaged object detection via dual stream adapters,”arXiv preprint arXiv:2503.06042, 2025
arXiv 2025
-
[25]
Differential feature awareness network within antagonistic learning for infrared-visible object detection,
R. Zhang, L. Li, Q. Zhang, J. Zhang, L. Xu, B. Zhang, and B. Wang, “Differential feature awareness network within antagonistic learning for infrared-visible object detection,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 8, pp. 6735–6748, 2023
2023
-
[26]
Rcnet: Dual-network resonance collaboration via mutual learning for rgb-d road defect detection,
W. Zhou, Z. Ju, R. Cong, and W. Yan, “Rcnet: Dual-network resonance collaboration via mutual learning for rgb-d road defect detection,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[27]
Fmtrack: Frequency-aware interaction and multi-expert fusion for rgb- t tracking,
Y . Xue, G. Jin, B. Zhong, T. Shen, L. Tan, C. Xue, and Y . Zheng, “Fmtrack: Frequency-aware interaction and multi-expert fusion for rgb- t tracking,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[28]
Semantic-orthogonal multi-modal attention network for rgb-d salient object detection,
J. Xu, Q. Zhou, J. Yu, C. Liao, and D. Zhu, “Semantic-orthogonal multi-modal attention network for rgb-d salient object detection,”The Visual Computer, pp. 1–13, 2025
2025
-
[29]
Mas-sam: Segment any marine animal with aggregated features,
T. Yan, Z. Wan, X. Deng, P. Zhang, Y . Liu, and H. Lu, “Mas-sam: Segment any marine animal with aggregated features,”arXiv preprint arXiv:2404.15700, 2024
arXiv 2024
-
[30]
Adaptive illumination mapping for shadow detection in raw images,
J. Sun, K. Xu, Y . Pang, L. Zhang, H. Lu, G. Hancke, and R. Lau, “Adaptive illumination mapping for shadow detection in raw images,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 12 709–12 718
2023
-
[31]
Msu-mamba: multi-scale defocus blur detection using cross- scale fusion and state-space models,
X. Wang, X. Zhou, Y . Wang, S. Zeng, X. Liu, H. Shen, S. Fei, and L. Zhu, “Msu-mamba: multi-scale defocus blur detection using cross- scale fusion and state-space models,”The Visual Computer, pp. 1–13, 2025
2025
-
[32]
Rfenet: Towards reciprocal feature evolution for glass segmentation,
K. Fan, C. Wang, Y . Wang, C. Wang, R. Yi, and L. Ma, “Rfenet: Towards reciprocal feature evolution for glass segmentation,”arXiv preprint arXiv:2307.06099, 2023
arXiv 2023
-
[33]
Decor- net: a covid-19 lung infection segmentation network improved by emphasizing low-level features and decorrelating features,
J. Hu, Y . Yang, X. Guo, B. Peng, H. Huang, and T. Ma, “Decor- net: a covid-19 lung infection segmentation network improved by emphasizing low-level features and decorrelating features,” in2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI). IEEE, 2023, pp. 1–5
2023
-
[34]
A dual-branch network for ultrasound image segmentation,
Z. Zhu, Z. Zhang, G. Qi, Y . Li, Y . Li, and L. Mu, “A dual-branch network for ultrasound image segmentation,”Biomedical Signal Pro- cessing and Control, vol. 103, p. 107368, 2025
2025
-
[35]
Flowsdf: Flow matching for medical image segmentation using dis- tance transforms,
L. Bogensperger, D. Narnhofer, A. Falk, K. Schindler, and T. Pock, “Flowsdf: Flow matching for medical image segmentation using dis- tance transforms,”International Journal of Computer Vision, pp. 1–13, 2025
2025
-
[36]
Controllable-lpmoe: Adapting to challenging object segmentation via dynamic local priors from mixture- of-experts,
Y . Sun, J. Lian, J. Yang, and L. Luo, “Controllable-lpmoe: Adapting to challenging object segmentation via dynamic local priors from mixture- of-experts,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 22 327–22 337
2025
-
[37]
De-lightsam: Modality- decoupled lightweight sam for generalizable medical segmentation,
Q. Xu, J. Li, X. He, C. Li, F. B. Tesema, W. Duan, Z. Chen, R. Qu, J. M. Garibaldi, and C. W. Chen, “De-lightsam: Modality- decoupled lightweight sam for generalizable medical segmentation,” IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[38]
Depth anything: Unleashing the power of large-scale unlabeled data,
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao, “Depth anything: Unleashing the power of large-scale unlabeled data,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 10 371–10 381
2024
-
[39]
Vst++: Efficient and stronger visual saliency transformer,
N. Liu, Z. Luo, N. Zhang, and J. Han, “Vst++: Efficient and stronger visual saliency transformer,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[40]
Effective video mirror detection with inconsistent motion cues,
A. Warren, K. Xu, J. Lin, G. K. Tam, and R. W. Lau, “Effective video mirror detection with inconsistent motion cues,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 17 244–17 252
2024
-
[41]
Modality-induced transfer-fusion network for rgb-d and rgb-t salient object detection,
G. Chen, F. Shao, X. Chai, H. Chen, Q. Jiang, X. Meng, and Y .-S. Ho, “Modality-induced transfer-fusion network for rgb-d and rgb-t salient object detection,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 4, pp. 1787–1801, 2022
2022
-
[42]
Unified-modal salient object detection via adaptive prompt learning,
K. Wang, Z. Tu, C. Li, Z. Liu, and B. Luo, “Unified-modal salient object detection via adaptive prompt learning,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[43]
Improving sam for camouflaged object detection via dual stream adapters,
J. Liu, L. Kong, and G. Chen, “Improving sam for camouflaged object detection via dual stream adapters,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2025, pp. 21 906–21 916
2025
-
[44]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026
2023
-
[45]
Sam 2: Segment anything in images and videos,
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafsonet al., “Sam 2: Segment anything in images and videos,”arXiv preprint arXiv:2408.00714, 2024
Pith/arXiv arXiv 2024
-
[46]
Dino: Detr with improved denoising anchor boxes for end-to- end object detection,
H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. M. Ni, and H.-Y . Shum, “Dino: Detr with improved denoising anchor boxes for end-to- end object detection,”arXiv preprint arXiv:2203.03605, 2022
Pith/arXiv arXiv 2022
-
[47]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[48]
T. Chen, A. Lu, L. Zhu, C. Ding, C. Yu, D. Ji, Z. Li, L. Sun, P. Mao, and Y . Zang, “Sam2-adapter: Evaluating & adapting segment anything 2 in downstream tasks: Camouflage, shadow, medical image segmentation, and more,”arXiv preprint arXiv:2408.04579, 2024
arXiv 2024
-
[49]
Edge- aware feature aggregation network for polyp segmentation,
T. Zhou, Y . Zhang, G. Chen, Y . Zhou, Y . Wu, and D.-P. Fan, “Edge- aware feature aggregation network for polyp segmentation,”Machine Intelligence Research, vol. 22, no. 1, pp. 101–116, 2025
2025
-
[50]
Generalized intersection over union: A metric and a loss for bounding box regression,
H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid, and S. Savarese, “Generalized intersection over union: A metric and a loss for bounding box regression,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
2019
-
[51]
Generalized cross entropy loss for training deep neural networks with noisy labels,
Z. Zhang and M. Sabuncu, “Generalized cross entropy loss for training deep neural networks with noisy labels,”Advances in neural informa- tion processing systems, vol. 31, 2018
2018
-
[52]
Learning to detect salient objects with image-level supervision,
L. Wang, H. Lu, Y . Wang, M. Feng, D. Wang, B. Yin, and X. Ruan, “Learning to detect salient objects with image-level supervision,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 136–145
2017
-
[53]
Saliency detection via graph-based manifold ranking,
C. Yang, L. Zhang, H. Lu, X. Ruan, and M.-H. Yang, “Saliency detection via graph-based manifold ranking,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2013, pp. 3166–3173
2013
-
[54]
Visual saliency based on multiscale deep features,
G. Li and Y . Yu, “Visual saliency based on multiscale deep features,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 5455–5463
2015
-
[55]
Leveraging stereopsis for saliency analysis,
Y . Niu, Y . Geng, X. Li, and F. Liu, “Leveraging stereopsis for saliency analysis,” in2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012, pp. 454–461. IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY 14
2012
-
[56]
Rgbd salient object detection: A benchmark and algorithms,
H. Peng, B. Li, W. Xiong, W. Hu, and R. Ji, “Rgbd salient object detection: A benchmark and algorithms,” inComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part III 13. Springer, 2014, pp. 92–109
2014
-
[57]
Depth-induced multi-scale recurrent attention network for saliency detection,
Y . Piao, W. Ji, J. Li, M. Zhang, and H. Lu, “Depth-induced multi-scale recurrent attention network for saliency detection,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 7254–7263
2019
-
[58]
Vscode-v2: Dynamic prompt learning for general visual salient and camouflaged object detection with two-stage optimization,
Z. Luo, N. Liu, X. Yang, D. Zhang, D.-P. Fan, F. S. Khan, and J. Han, “Vscode-v2: Dynamic prompt learning for general visual salient and camouflaged object detection with two-stage optimization,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[59]
Rgb-t saliency detection benchmark: Dataset, baselines, analysis and a novel approach,
G. Wang, C. Li, Y . Ma, A. Zheng, J. Tang, and B. Luo, “Rgb-t saliency detection benchmark: Dataset, baselines, analysis and a novel approach,” inImage and graphics technologies and applications: 13th conference on image and graphics technologies and applications, IGTA 2018, Beijing, China, April 8–10, 2018, revised selected papers 13. Springer, 2018, pp. 359–369
2018
-
[60]
Rgb-t image saliency detection via collaborative graph learning,
Z. Tu, T. Xia, C. Li, X. Wang, Y . Ma, and J. Tang, “Rgb-t image saliency detection via collaborative graph learning,”IEEE Transactions on Multimedia, vol. 22, no. 1, pp. 160–173, 2019
2019
-
[61]
Rgbt salient object detection: A large-scale dataset and benchmark,
Z. Tu, Y . Ma, Z. Li, C. Li, J. Xu, and Y . Liu, “Rgbt salient object detection: A large-scale dataset and benchmark,”IEEE Transactions on Multimedia, vol. 25, pp. 4163–4176, 2022
2022
-
[62]
Segmentation of moving objects by long term video analysis,
P. Ochs, J. Malik, and T. Brox, “Segmentation of moving objects by long term video analysis,”IEEE transactions on pattern analysis and machine intelligence, vol. 36, no. 6, pp. 1187–1200, 2013
2013
-
[63]
A benchmark dataset and evaluation method- ology for video object segmentation,
F. Perazzi, J. Pont-Tuset, B. McWilliams, L. Van Gool, M. Gross, and A. Sorkine-Hornung, “A benchmark dataset and evaluation method- ology for video object segmentation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 724– 732
2016
-
[64]
Shifting more attention to video salient object detection,
D.-P. Fan, W. Wang, M.-M. Cheng, and J. Shen, “Shifting more attention to video salient object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 8554–8564
2019
-
[65]
Learning complemen- tary spatial–temporal transformer for video salient object detection,
N. Liu, K. Nan, W. Zhao, X. Yao, and J. Han, “Learning complemen- tary spatial–temporal transformer for video salient object detection,” IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 8, pp. 10 663–10 673, 2023
2023
-
[66]
Dimsod: A diffusion-based framework for multi-modal salient ob- ject detection,
S. Zhang, J. Huang, W. Tang, Y . Wu, T. Hu, X. Xu, and J. Liu, “Dimsod: A diffusion-based framework for multi-modal salient ob- ject detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 10. AAAI, 2025, pp. 10 103–10 111
2025
-
[67]
Alignment-free rgb-t salient object detection: A large-scale dataset and progressive corre- lation network,
K. Wang, K. Chen, C. Li, Z. Tu, and B. Luo, “Alignment-free rgb-t salient object detection: A large-scale dataset and progressive corre- lation network,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 7, 2025, pp. 7780–7788
2025
-
[68]
Anabranch network for camouflaged object segmentation,
T.-N. Le, T. V . Nguyen, Z. Nie, M.-T. Tran, and A. Sugimoto, “Anabranch network for camouflaged object segmentation,”Computer vision and image understanding, vol. 184, pp. 45–56, 2019
2019
-
[69]
Camouflaged object detection,
D.-P. Fan, G.-P. Ji, G. Sun, M.-M. Cheng, J. Shen, and L. Shao, “Camouflaged object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2777–2787
2020
-
[70]
Simultaneously localize, segment and rank the camouflaged objects,
Y . Lv, J. Zhang, Y . Dai, A. Li, B. Liu, N. Barnes, and D.-P. Fan, “Simultaneously localize, segment and rank the camouflaged objects,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11 591–11 601
2021
-
[71]
Implicit motion handling for video camouflaged object detection,
X. Cheng, H. Xiong, D.-P. Fan, Y . Zhong, M. Harandi, T. Drummond, and Z. Ge, “Implicit motion handling for video camouflaged object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 13 864–13 873
2022
-
[72]
It’s moving! a probabilistic model for causal motion segmentation in moving camera videos,
P. Bideau and E. Learned-Miller, “It’s moving! a probabilistic model for causal motion segmentation in moving camera videos,” inCom- puter Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part VIII 14. Springer, 2016, pp. 433–449
2016
-
[73]
Source-free depth for object pop-out,
Z. Wu, D. P. Paudel, D.-P. Fan, J. Wang, S. Wang, C. Demonceaux, R. Timofte, and L. Van Gool, “Source-free depth for object pop-out,” inICCV, 2023
2023
-
[74]
Implicit-explicit motion learning for video camouflaged object detection,
W. Hui, Z. Zhu, G. Gu, M. Liu, and Y . Zhao, “Implicit-explicit motion learning for video camouflaged object detection,”IEEE Transactions on Multimedia, vol. 26, pp. 7188–7196, 2024
2024
-
[75]
Depth alignment interaction network for camouflaged object detection,
H. Bi, Y . Tong, J. Zhang, C. Zhang, J. Tong, and W. Jin, “Depth alignment interaction network for camouflaged object detection,”Mul- timedia Systems, vol. 30, no. 1, p. 51, 2024
2024
-
[76]
Sam-pm: Enhancing video camouflaged object detection using spatio-temporal attention,
M. N. Meeran, B. P. Manthaet al., “Sam-pm: Enhancing video camouflaged object detection using spatio-temporal attention,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 1857–1866
2024
-
[77]
Explicit motion handling and interactive prompting for video camouflaged object detection,
X. Zhang, T. Xiao, G.-P. Ji, X. Wu, K. Fu, and Q. Zhao, “Explicit motion handling and interactive prompting for video camouflaged object detection,”IEEE Transactions on Image Processing, 2025
2025
-
[78]
Where is my mirror?
X. Yang, H. Mei, K. Xu, X. Wei, B. Yin, and R. W. Lau, “Where is my mirror?” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 8809–8818
2019
-
[79]
Progressive mirror detection,
J. Lin, G. Wang, and R. W. Lau, “Progressive mirror detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 3697–3705
2020
-
[80]
Depth-aware mirror segmentation,
H. Mei, B. Dong, W. Dong, P. Peers, X. Yang, Q. Zhang, and X. Wei, “Depth-aware mirror segmentation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 3044–3053
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.