PROBE-Web: An Interactive System for Probing Evaluation Landscapes of Knowledge Graph Completion Models
Pith reviewed 2026-06-27 17:12 UTC · model grok-4.3
The pith
PROBE-Web lets users adjust two perspectives to evaluate knowledge graph completion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
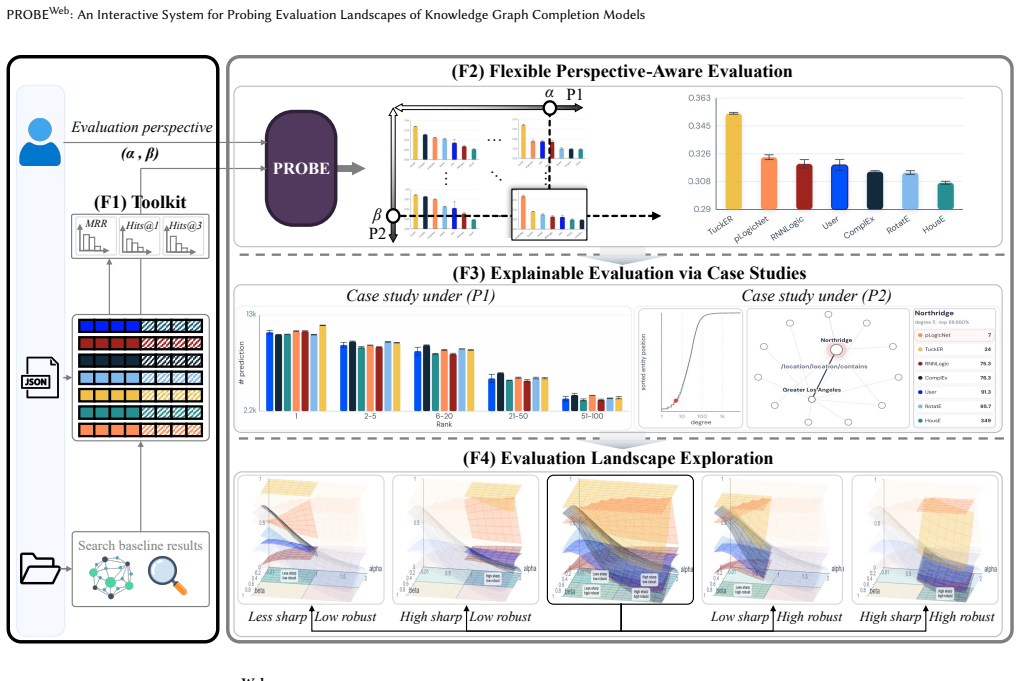
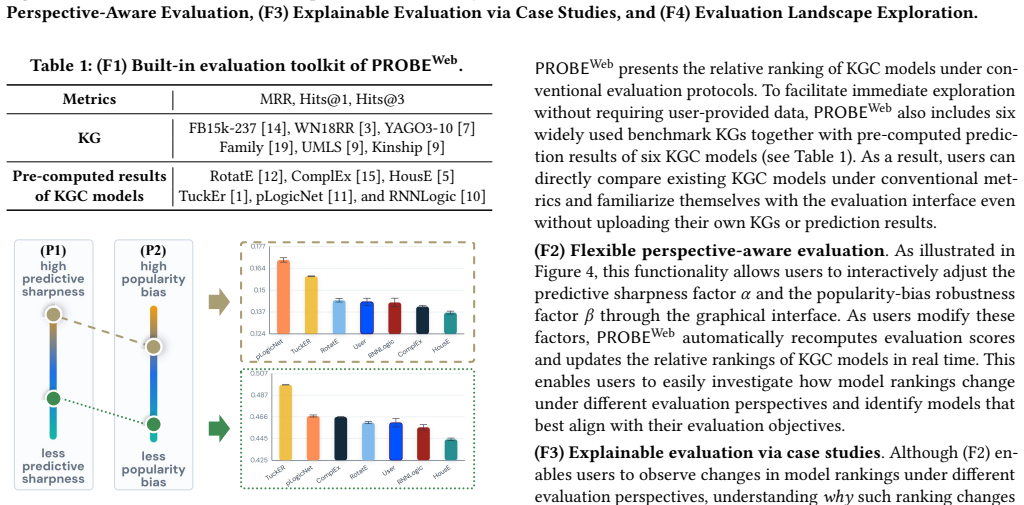
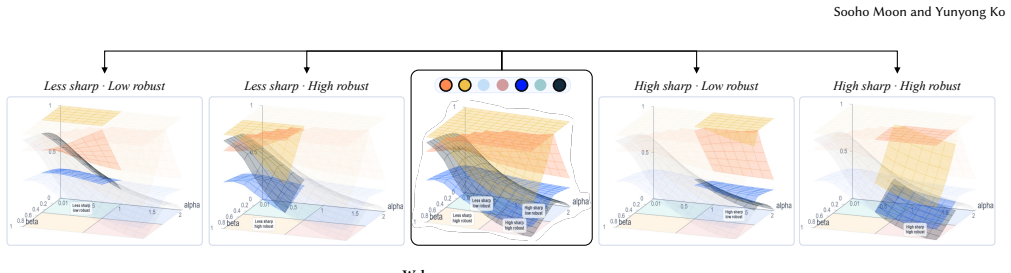
PROBE-Web provides an interactive GUI for probing evaluation landscapes of KGC models by letting users adjust predictive sharpness and popularity-bias robustness, delivering four functionalities: a conventional evaluation toolkit, flexible perspective-aware evaluation, explainable case studies, and evaluation landscape exploration to help users understand model strengths and weaknesses in line with their objectives.
What carries the argument
Two adjustable perspectives—predictive sharpness and popularity-bias robustness—implemented inside a user-friendly GUI that supports simultaneous model comparison and landscape navigation.
If this is right
- Users can run and compare multiple KGC models under customized evaluation settings instead of fixed metrics.
- Explainable case studies make it possible to see why a model performs well or poorly on particular triples.
- Landscape exploration lets users identify regions where one model outperforms others visually.
- Evaluations become aligned with individual objectives rather than a single universal ranking.
Where Pith is reading between the lines
- The same GUI pattern could support additional perspectives such as temporal robustness or domain-specific bias.
- Researchers might use the system as a shared platform to benchmark new KGC models under varied criteria.
- Similar adjustable-evaluation interfaces could be built for related tasks like link prediction in other graph domains.
Load-bearing premise
The two chosen perspectives capture the main evaluation needs of users and the GUI surfaces differences that are meaningful for decision making.
What would settle it
A user study in which participants report that varying the two perspective sliders produces no change in model rankings or insights beyond what standard MRR and Hits@K already show.
Figures

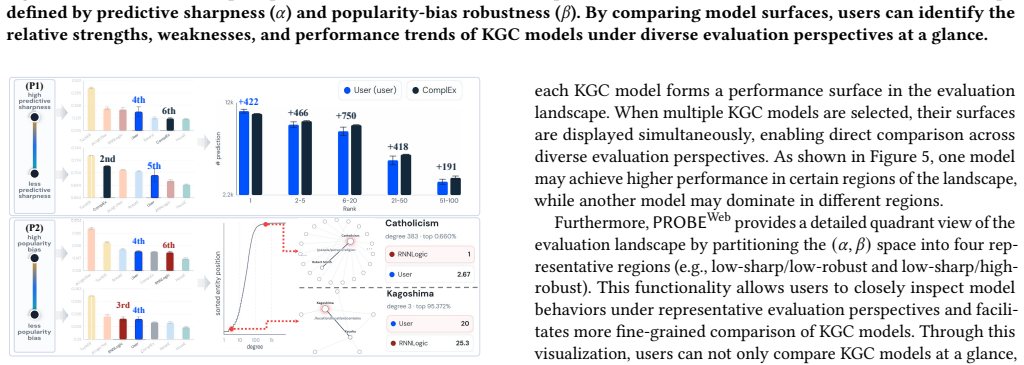
read the original abstract
Knowledge graph completion (KGC) models are commonly evaluated using rank-based metrics such as MRR and Hits@K, despite different users often requiring different evaluation perspectives. In this demo, we present PROBE-Web, an interactive system for probing diverse evaluation landscapes for KGC models. PROBE-Web enables users to flexibly evaluate KGC models by adjusting two critical perspectives: (P1) predictive sharpness and (P2) popularity-bias robustness. Through a user-friendly GUI, users easily evaluate multiple KGC models and analyze their strengths and weaknesses. PROBE-Web provides four key functionalities: (1) conventional evaluation toolkit, (2) flexible perspective-aware evaluation, (3) explainable case studies, and (4) evaluation landscape exploration. We believe that PROBE-Web can help users better understand KGC models aligning with their objectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents PROBE-Web, an interactive web-based system for evaluating knowledge graph completion (KGC) models. It allows users to adjust two perspectives—(P1) predictive sharpness and (P2) popularity-bias robustness—via a GUI that supports conventional rank-based metrics, perspective-aware evaluation, explainable case studies, and exploration of evaluation landscapes, with the goal of helping users align assessments with their objectives beyond standard MRR and Hits@K.
Significance. If the system is fully implemented as described and the chosen perspectives surface actionable model differences, PROBE-Web could provide a usable tool for KGC practitioners seeking customizable evaluations. The interactive, GUI-driven approach is a practical strength for accessibility.
major comments (2)
- [Abstract] Abstract: The assertion that predictive sharpness and popularity-bias robustness constitute the 'two critical perspectives' is presented without any supporting justification, such as citations to prior KGC evaluation literature, a practitioner survey, or empirical comparison against other axes (e.g., calibration error or long-tail entity performance). This choice is load-bearing for the system's design and claimed utility.
- [Abstract] Abstract: No implementation details, validation experiments, or evidence are supplied that adjusting the P1/P2 sliders produces meaningful, reproducible differences across models that align with real user objectives. The four listed functionalities are described at a high level only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that predictive sharpness and popularity-bias robustness constitute the 'two critical perspectives' is presented without any supporting justification, such as citations to prior KGC evaluation literature, a practitioner survey, or empirical comparison against other axes (e.g., calibration error or long-tail entity performance). This choice is load-bearing for the system's design and claimed utility.
Authors: We agree that the abstract asserts these perspectives without explicit supporting citations or justification in the current text. The full manuscript draws on related KGC evaluation literature concerning bias and ranking sharpness, but we will revise the abstract and add a short paragraph in the introduction with targeted citations to prior work on these specific axes. We will not add a new practitioner survey or broad empirical comparison, as those fall outside the demo scope, but the added references will clarify the rationale for the design choice. revision: yes
-
Referee: [Abstract] Abstract: No implementation details, validation experiments, or evidence are supplied that adjusting the P1/P2 sliders produces meaningful, reproducible differences across models that align with real user objectives. The four listed functionalities are described at a high level only.
Authors: The paper is a system demonstration, so the abstract and main text prioritize high-level description of the GUI and functionalities. We acknowledge the absence of concrete implementation details and example outputs in the abstract. In revision we will expand the abstract slightly and add a new subsection with implementation notes, reproducible slider-adjustment examples, and qualitative evidence of model differentiation. Full quantitative validation experiments across many models are not present and would require substantial additional work; we will therefore provide illustrative case studies instead. revision: partial
Circularity Check
No circularity: system description with no derivations or fitted quantities
full rationale
The paper is a demo/system description of PROBE-Web with no equations, parameters, predictions, or derivations of any kind. The two perspectives (P1 predictive sharpness, P2 popularity-bias robustness) are presented as design choices in the abstract and functionalities list, not derived from prior results or self-citations. No load-bearing steps reduce to inputs by construction, self-citation chains, or renaming. The absence of any mathematical content makes circularity impossible; the work is self-contained as an interactive toolkit description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ivana Balazevic, Carl Allen, and Timothy Hospedales. 2019. TuckER: Tensor Factorization for Knowledge Graph Completion. InProceedings of the 2019 Con- ference on Empirical Methods in Natural Language Processing and the 9th In- ternational Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Linguistics, Hong Kong, ...
-
[2]
Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. InAdvances in Neural Information Processing Systems, Vol. 26
2013
-
[3]
Tim Dettmers, Pasquale Minervini, Pontus Stenetorp, and Sebastian Riedel. 2018. Convolutional 2D knowledge graph embeddings. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 32
2018
-
[4]
Xiao Huang, Jingyuan Zhang, Dingcheng Li, and Ping Li. 2019. Knowledge graph embedding based question answering. InProceedings of the twelfth ACM international conference on web search and data mining. 105–113
2019
-
[5]
Rui Li, Jianan Zhao, Chaozhuo Li, Di He, Yiqi Wang, Yuming Liu, Hao Sun, Senzhang Wang, Weiwei Deng, Yanming Shen, et al. 2022. House: Knowledge graph embedding with householder parameterization. InInternational Conference on Machine Learning. PMLR, 13209–13224. PROBEWeb: An Interactive System for Probing Evaluation Landscapes of Knowledge Graph Completion Models
2022
-
[6]
Xuan Lin, Zhe Quan, Zhi-Jie Wang, Tengfei Ma, and Xiangxiang Zeng. 2020. KGNN: Knowledge graph neural network for drug-drug interaction prediction.. InIJCAI, Vol. 380. 2739–2745
2020
-
[7]
Farzaneh Mahdisoltani, Joanna Biega, and Fabian M Suchanek. 2013. YAGO3: A knowledge base from multilingual Wikipedias. InCIDR
2013
-
[8]
Sooho Moon and Yunyong Ko. 2026. How Sharp and Bias-Robust is a Model? Dual Evaluation Perspectives on Knowledge Graph Completion. InProceedings of the nineteenth ACM international conference on web search and data mining
2026
-
[9]
Maximilian Nickel, Volker Tresp, Hans-Peter Kriegel, et al. 2011. A three-way model for collective learning on multi-relational data.. InIcml, Vol. 11. 3104482– 3104584
2011
-
[10]
Meng Qu, Junkun Chen, Louis-Pascal Xhonneux, Yoshua Bengio, and Jian Tang
-
[11]
In International Conference on Learning Representations (ICLR)
RNNLogic: Learning Logic Rules for Reasoning on Knowledge Graphs. In International Conference on Learning Representations (ICLR). https://openreview .net/forum?id=tGZu6DlbreV
-
[12]
Meng Qu and Jian Tang. 2019. Probabilistic logic neural networks for reasoning. InAdvances in Neural Information Processing Systems, Vol. 32
2019
-
[13]
Zhiqing Sun, Zhi-Hong Deng, Jian-Yun Nie, and Jian Tang. 2019. RotatE: Knowl- edge Graph Embedding by Relational Rotation in Complex Space. InInternational Conference on Learning Representations (ICLR). https://openreview.net/forum?i d=HkgEQnRqYQ
2019
-
[14]
Zhiqing Sun, Shikhar Vashishth, Soumya Sanyal, Partha Talukdar, and Yiming Yang. 2020. A Re-evaluation of Knowledge Graph Completion Methods. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Online, 5516–5522. doi:10 .18653/v1/2020.acl-main.489
2020
-
[15]
Kristina Toutanova and Danqi Chen. 2015. Observed versus latent features for knowledge base and text inference. InProceedings of the 3rd Workshop on Continuous Vector Space Models and Their Compositionality. 57–66
2015
-
[16]
Théo Trouillon, Johannes Welbl, Sebastian Riedel, Éric Gaussier, and Guillaume Bouchard. 2016. Complex embeddings for simple link prediction. InProceedings of International Conference on Machine Learning. PMLR, 2071–2080
2016
-
[17]
Daniel Vella and Jean-Paul Ebejer. 2022. Few-shot learning for low-data drug discovery.Journal of Chemical Information and Modeling63, 1 (2022), 27–42
2022
-
[18]
Hongwei Wang, Fuzheng Zhang, Xing Xie, and Minyi Guo. 2018. DKN: Deep knowledge-aware network for news recommendation. InProceedings of the Web Conference (WWW). 1835–1844
2018
-
[19]
Hongwei Wang, Miao Zhao, Xing Xie, Wenjie Li, and Minyi Guo. 2019. Knowl- edge graph convolutional networks for recommender systems. InThe world wide web conference. 3307–3313
2019
-
[20]
Fan Yang, Zhilin Yang, and William W Cohen. 2017. Differentiable learning of logical rules for knowledge base reasoning. InAdvances in Neural Information Processing Systems, Vol. 30
2017
-
[21]
Michihiro Yasunaga, Hongyu Ren, Antoine Bosselut, Percy Liang, and Jure Leskovec. 2021. QA-GNN: Reasoning with Language Models and Knowledge Graphs for Question Answering. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 535–546
2021
-
[22]
Xiangxiang Zeng, Xinqi Tu, Yuansheng Liu, Xiangzheng Fu, and Yansen Su
-
[23]
Toward better drug discovery with knowledge graph.Current Opinion in Structural Biology72 (2022), 114–126
2022
-
[24]
Rui Zhang, Dimitar Hristovski, Dalton Schutte, Andrej Kastrin, Marcelo Fiszman, and Halil Kilicoglu. 2021. Drug repurposing for COVID-19 via knowledge graph completion.Journal of Biomedical Informatics115 (2021), 103696
2021
-
[25]
Yongqi Zhang and Quanming Yao. 2022. Knowledge graph reasoning with relational digraph. InProceedings of the ACM web conference 2022. 912–924
2022
-
[26]
Sijin Zhou, Xinyi Dai, Haokun Chen, Weinan Zhang, Kan Ren, Ruiming Tang, Xiuqiang He, and Yong Yu. 2020. Interactive recommender system via knowledge graph-enhanced reinforcement learning. InProceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval. 179– 188
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.